

单v100 GPU,4小时搜索到一个鲁棒的网络结构
电子说
描述
NAS最近也很火,正好看到了这篇论文,解读一下,这篇论文是基于DAG(directed acyclic graph)的,DAG包含了上亿的 sub-graphs, 为了防止全部遍历这些模型,这篇论文设计了一种全新的采样器,这种采样器叫做Gradient-based search suing differential Architecture Sampler(GDAS),该采样器可以自行学习和优化,在这个的基础上,在CIFAR-10上通过4 GPU hours就能找到一个最优的网络结构。

目前主流的NAS一般是基于进化算法(EA)和强化学习(RL)来做的。EA通过权衡validation accuracy来决定是否需要移除一个模型,RL则是validation accuracy作为奖励来优化模型生成。作者认为这两种方法都很消耗计算资源。作者这篇论文中设计的GDAS方法可以在一个单v100 GPU上,用四小时搜索到一个优秀模型。
GDAS
这个采用了搜索robust neural cell来替代搜索整个网络。如下图,不同的操作(操作用箭头表示)会计算出不同的中间结果(中间结果用cycle表示),前面的中间结果会加起来闯到后面。
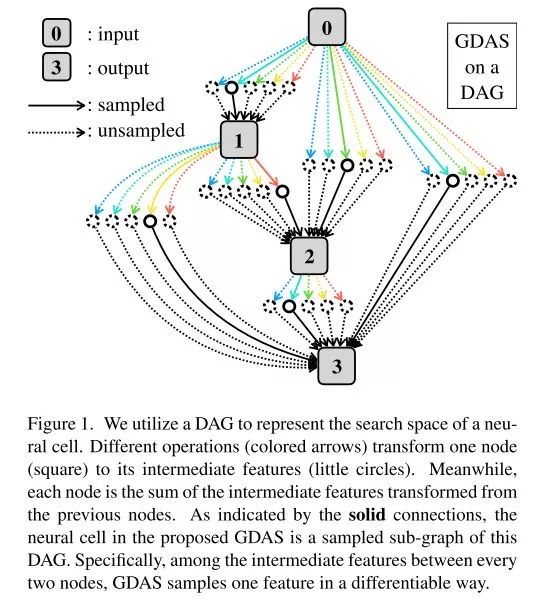
在优化速度上,传统的DAG存在一些问题:基于RL和EA的方法,需要获得反馈都需要很长一段时间。而这篇论文提出的GDAS方法能够利用梯度下降去做优化,具体怎么梯的下面会说到。此外,使用GDAS的方法可以sample出sub-graph,这意味着计算量要比DAG的方法小很多。
绝大多数的NAS方法可以归为两类:Macro search和micro search
Macro search
顾名思义,实际上算法的目的是想要发现一个完整的网络结构。因此多会采用强化学习的方式。现有的方法很多都是使用Q-learning的方法来学习的。那么会存在的问题是,需要搜索的网络数量会呈指数级增长。最后导致的结果就是网络会更浅。
Micro Search
这种不是搜索整个神经网络,而是搜索neural cells的方式。找到指定的neural cells后,再去堆叠。这种设计方式虽然能够设计更深的网络,但是依旧要消耗很长时间,比如100GPU days,超长。这篇文章就是在消耗上面做优化。
算法原理
DAG的搜索空间
前面也说了DAG是通过搜索所谓的neural cell而不是搜索整个网络。每个cell由多个节点和节点间的激活函数构成。节点我们用 来表示,节点的计算如下图。每个节点有其余两个节点(下面公式中的节点i和节点j)来生成,而中间会从一个函数集合 中去sample函数出来, 这个F数据集的组成是1)恒等映射 2)归零 3)3x3 depthwise分离卷积 4)3x3 dilated depthwise 分离卷积 5)5x5 depthwise分离卷积 6)5x5 dilated depthwise 分离卷积。7)3x3平均池化 8) 3 x 3 最大池化。
那么生成节点I后,再去生成对应的cell。我们将cell的节点数记为B,以B=4为例,该cell实际上会包括7个节点, 是前面两层的cell的输出(实际上也就是上面公式中的k和j),而 则是我们(1)中计算出来的结果。 也就是该cell的output tensor实际上是 四个节点的output的联结。
将cell组装为网络
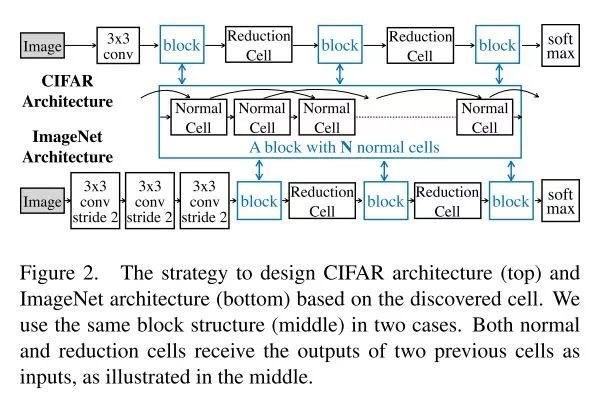
刚刚上面的这种叫做normal cell,作者还设计了一个reduction cell, 用于下采样。这个reduction cell就是手动设计的了,没有像normal cell那样复杂。normal cell 的步长为1,reduction cell步长为2, 最后的网络实际上就是由这些cell组装起来的。如下图:
搜索模型参数
搭建的工作如上面所示,好像也还好,就像搭积木,这篇论文我觉得创新的地方在于它的搜索方法,特别是通过梯度下降的方式来更新参数,很棒。具体的搜索参数环节,它是这么做的:
首先我们的优化目标和手工设计的网络别无二致,都是最大释然估计:
而上式中的Pr,实际上可写成:
这个 实际上是node i和node j的函数分布,k则是F的基数。而Node可以表示为:
是从 中sample出来的,而
这个 实际上是node i和node j的函数分布,k则是F的基数。而Node可以表示为:
其中 是从离散分布 中间sample出来的函数。这里问题来了,如果直接去优化Pr,这里由于I是来自于一个离散分布,没法对离散分布使用梯度下降方法。这里,作者使用了Gumbel-Max trick来解决离散分布中采样不可微的问题,具体可以看这个问题下的回答
如何理解Gumbel-Max trick?
TL;DR: Gumbel Trick 是一种从离散分布取样的方法,它的形式可以允许我们定义一种可微分的,离散分布的近似取样,这种取样方式不像「干脆以各类概率值的概率向量替代取样」这么粗糙,也不像直接取样一样不可导(因此没办法应对可能的 bp )。
于是这里将这个离散分布不可微的问题做了转移,同时对应的优化目标变为:
这里有个 的参数,可以控制 的相似程度。注意在前向传播中我们使用的是等式(5), 而在反向传播中,使用的是等式(7)。结合以上内容,我们模型的loss是:
我们将最后学习到的网络结构称为A,每一个节点由前面T个节点连接而来,在CNN中,我们把T设为2, 在RNN中,T设为1
在参数上,作者使用了SGD,学习率从0.025逐渐降到1e-3,使用的是cosine schedule。具体的参数和function F 设计上,可以去看看原论文。
总的来说,我觉得这篇论文最大的创新点是使用Gumbel-Max trick来使得搜索过程可微分,当然它中间也使用了一些手动设计的模块(如reduction cell),所以速度会比其余的NAS更快,之前我也没有接触过NAS, 看完这篇论文后对现在的NAS常用的方法以及未来NAS发展的趋势还是有了更深的理解,推荐看看原文。
-
DVB-H网络结构2009-07-17 0
-
特斯拉V100 Nvlink是否支持v100卡的nvlink变种的GPU直通?2018-09-12 0
-
神经网络结构搜索有什么优势?2019-09-11 0
-
备货Hi3519A V100 4K智能IP摄像头SoC使用手册分享2020-09-25 0
-
网络结构与IP分组交换技术2021-12-23 0
-
TD-SCDMA R4网络结构和技术要求2009-07-30 442
-
环形网络,环形网络结构是什么?2010-03-22 6187
-
4G网络结构及关键技术2011-11-10 1484
-
一种改进的深度神经网络结构搜索方法2021-03-16 811
-
基于YOLO-V5的网络结构及实现行人社交距离风险提示2022-07-06 3608
-
物联网行业通用主板—卓越V1002023-06-02 2152
-
英伟达v100与A100的差距有哪些?2023-08-22 23206
全部0条评论

快来发表一下你的评论吧 !
