

世上最好的共享内存(Linux共享内存最透彻的一篇)上集
描述
共享单车、共享充电宝、共享雨伞,世间的共享有千万种,而我独爱共享内存。
早期的共享内存,着重于强调把同一片内存,map到多个进程的虚拟地址空间(在相应进程找到一个VMA区域),以便于CPU可以在各个进程访问到这片内存。
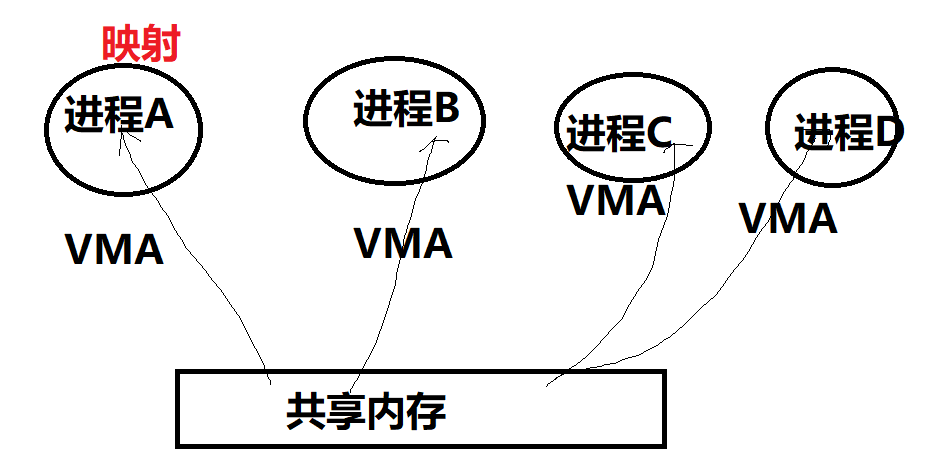
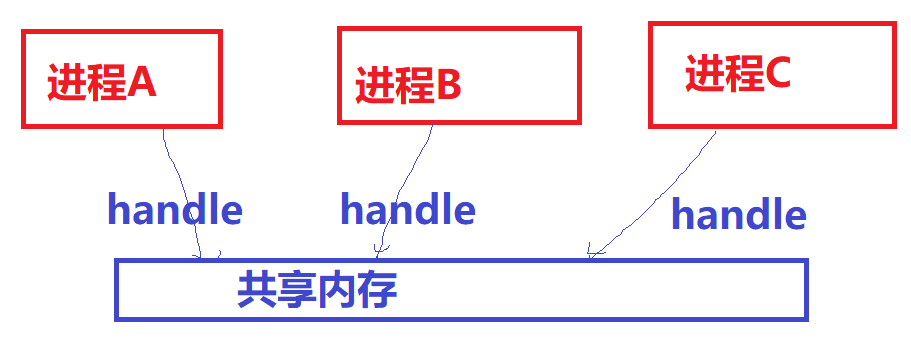
现阶段广泛应用于多媒体、Graphics领域的共享内存方式,某种意义上不再强调映射到进程虚拟地址空间的概念(那无非是为了让CPU访问),而更强调以某种“句柄”的形式,让大家知道某一片视频、图形图像数据的存在并可以借助此“句柄”来跨进程引用这片内存,让视频encoder、decoder、GPU等可以跨进程访问内存。所以不同进程用的加速硬件其实是不同的,他们更在乎的是可以通过一个handle拿到这片内存,而不再特别在乎CPU访问它的虚拟地址(当然仍然可以映射到进程的虚拟地址空间供CPU访问)。
只要内存的拷贝(memcpy)仍然是一个占据内存带宽、CPU利用率的消耗大户存在,共享内存作为Linux进程间通信、计算机系统里各个不同硬件组件通信的最高效方法,都将持续繁荣。关于内存拷贝会大多程度地占据CPU利用率,这个可以最简单地尝试拷贝1080P,帧率每秒60的电影画面,我保证你的系统的CPU,蛋会疼地不行。
我早就想系统地写一篇综述Linux里面各种共享内存方式的文章了,但是一直被带娃这个事业牵绊,今日我决定顶着娃娃们的山呼海啸,也要写一篇文章不吐不快。
共享内存的方式有很多种,目前主流的方式仍然有:
共享内存的方式
1.基于传统SYS V的共享内存;
2.基于POSIX mmap文件映射实现共享内存;
3.通过memfd_create()和fd跨进程共享实现共享内存;
4.多媒体、图形领域广泛使用的基于dma-buf的共享内存。
共享内存
SYS V共享内存
历史悠久、年代久远、API怪异,对应内核代码linux/ipc/shm.c,当你编译内核的时候不选择CONFIG_SYSVIPC,则不再具备此能力。
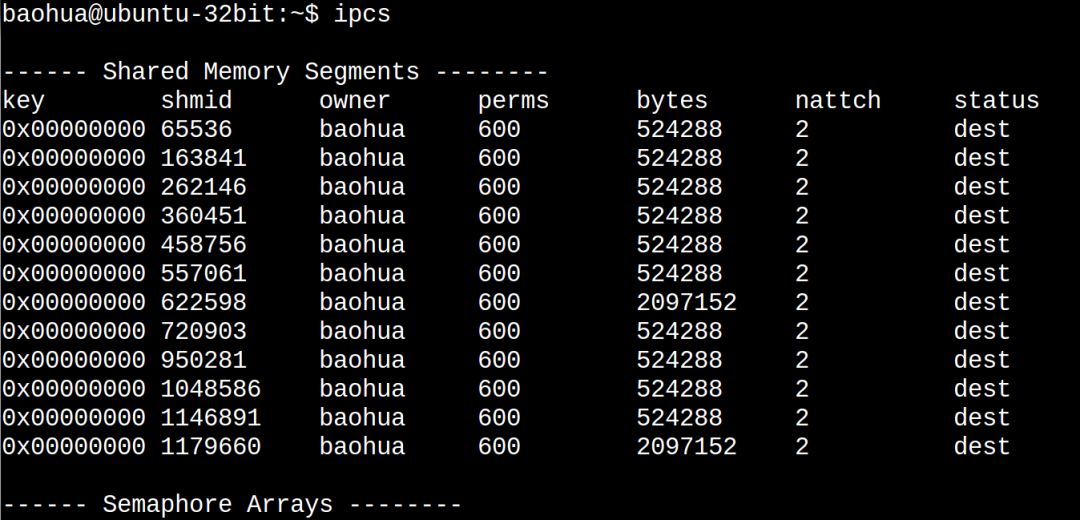
你在Linux敲ipcs命令看到的share memory就是这种共享内存:
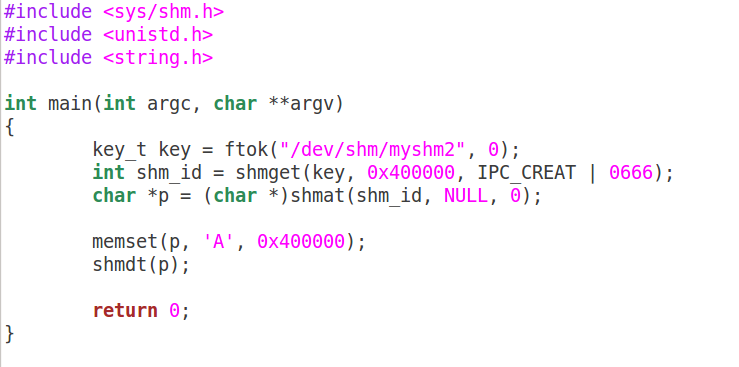
下面写一个最简单的程序来看共享内存的写端sw.c:
以及共享内存的读端sr.c:

编译和准备运行:

在此之前我们看一下系统的free:

下面运行sw和sr:

我们发现sr打印出来的和sw写进去的是一致的。这个时候我们再看下free:

可以看到used显著增大了(711632 -> 715908), shared显著地增大了(2264 -> 6360),而cached这一列也显著地增大326604->330716。
我们都知道cached这一列统计的是file-backed的文件的page cache的大小。理论上,共享内存属于匿名页,但是由于这里面有个非常特殊的tmpfs(/dev/shm指向/run/shm,/run/shm则mount为tmpfs):

所以可以看出tmpfs的东西其实真的是有点含混:我们可以理解它为file-backed的匿名页(anonymous page),有点类似女声中的周深。前面我们反复强调,匿名页是没有文件背景的,这样当进行内存交换的时候,是与swap分区交换。磁盘文件系统里面的东西在内存的副本是file-backed的页面,所以不存在与swap分区交换的问题。但是tmpfs里面的东西,真的是在统计意义上统计到page cache了,但是它并没有真实的磁盘背景,这又和你访问磁盘文件系统里面的文件产生的page cache有本质的区别。所以,它是真地有那么一点misc的感觉,凡事都没有绝对,唯有变化本身是不变的。
也可以通过ipcs找到新创建的SYS V共享内存:

POSIX共享内存
我对POSIX shm_open()、mmap () API系列的共享内存的喜爱,远远超过SYS V 100倍。原谅我就是一个懒惰的人,我就是讨厌ftok、shmget、shmat、shmdt这样的API。
上面的程序如果用POSIX的写法,可以简化成写端psw.c:
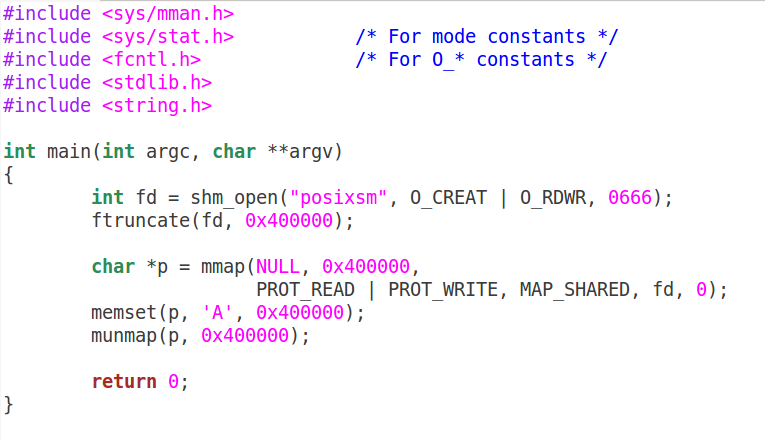
读端:
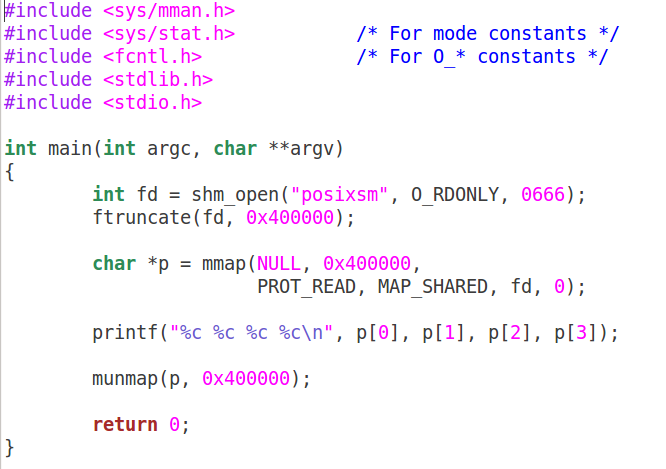
编译和执行:

这样我们会在/dev/shm/、/run/shm下面看到一个文件:

坦白讲,mmap、munmap这样的API让我找到了回家的感觉,刚入行做Linux的时候,写好framebuffer驱动后,就是把/dev/fb0 mmap到用户空间来操作,所以mmap这样的 API,真的是特别亲切,像亲人一样。
当然,如果你不喜欢shm_open()这个API,你也可以用常规的open来打开文件,然后进行mmap。关键的是mmap,wikipedia如是说:
mmap
In computing, mmap(2) is a POSIX-compliant Unix system call that maps files or devices into memory. It is a method of memory-mapped file I/O. It implements demand paging, because file contents are not read from disk directly and initially do not use physical RAM at all. The actual reads from disk are performed in a "lazy" manner, after a specific location is accessed. After the memory is no longer needed, it is important to munmap(2) the pointers to it. Protection information can be managed using mprotect(2), and special treatment can be enforced using madvise(2).
POSIX的共享内存,仍然符合我们前面说的tmpfs的特点,在运行了sw,sr后,再运行psw和psr,我们发现free命令再次戏剧性变化:

请将这个free命令的结果与前2次的free结果的各个字段进行对照:
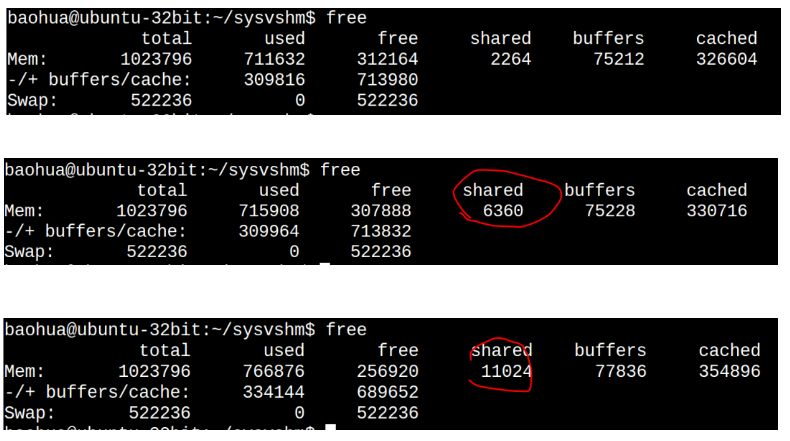
第3次比第2次的cached大了这么多?是因为我编写这篇文章边在访问磁盘里面的文件,当然POSIX的这个共享内存本身也导致cached增大了。
memfd_create
如果说POSIX的mmap让我找到回家的感觉,那么memfd_create()则是万般惊艳。见过这种API,才知道什么叫天生尤物——而且是尤物中的尤物,它完全属于那种让码农第一眼看到就会两眼充血,恨不得眼珠子夺眶而出贴到它身上去的那种API;一般人见到它第一次,都会忽略了它的长相,因为它的身材实在太火辣太抢眼了。
先不要浮想联翩,在所有的所有开始之前,我们要先提一下跨进程分享fd(文件描述符,对应我们很多时候说的“句柄”)这个重要的概念。
众所周知,Linux的fd属于一个进程级别的东西。进入每个进程的/proc/pid/fd可以看到它的fd的列表:

这个进程的0,1,2和那个进程的0,1,2不是一回事。
某年某月的某一天,人们发现,一个进程其实想访问另外一个进程的fd。当然,这只是目的不是手段。比如进程A有2个fd指向2片内存,如果进程B可以拿到这2个fd,其实就可以透过这2个fd访问到这2片内存。这个fd某种意义上充当了一个中间媒介的作用。有人说,那还不简单吗,如果进程A:
fd = open();
open()如果返回100,把这个100告诉进程B不就可以了吗,进程B访问这个100就可以了。这说明你还是没搞明白fd是一个进程内部的东西,是不能跨进程的概念。你的100和我的100,不是一个东西。这些基本的东西你搞不明白,你搞别的都是白搭。
Linux提供一个特殊的方法,可以把一个进程的fd甩锅、踢皮球给另外一个进程(其实“甩锅”这个词用在这里不合适,因为“甩锅”是一种推卸,而fd的传递是一种分享)。我特码一直想把我的bug甩(分)锅(享)出去,却发现总是被人把bug甩锅过来。
那么如何甩(分)锅(享)fd呢?
-
关于共享内存的函数shmget()2016-09-24 0
-
Linux进程间通信——使用共享内存2017-11-21 0
-
请问IPC安装完后的共享内存是谁给划定的?,LINUX和SYS/BISO的messageQ是怎样实现共享内存的同步的?2018-07-24 0
-
linux如何共享内存实验2020-06-08 0
-
linux中的共享内存是指什么?共享内存有哪些优缺点2022-02-28 0
-
共享内存IPC原理,Linux进程间如何共享内存?2018-07-16 8640
-
你知道Linux的共享内存与tmpfs文件系统是什么样?2019-05-04 2145
-
Linux IPC System V 共享内存2019-04-02 278
-
深入剖析Linux共享内存原理2021-10-30 2287
-
通过使用CUDA GPU共享内存2022-04-11 7413
-
Linux系统的共享内存的使用2022-11-14 1320
-
Linux下进程间如何实现共享内存通信2023-04-26 697
-
CUDA编程共享内存2023-05-19 1150
-
Linux进程间如何实现共享内存通信2023-06-19 640
-
内存共享原理解析2024-02-19 1301
全部0条评论

快来发表一下你的评论吧 !
