

实用的排序算法 - 交换排序
描述
写在前面 Ⅰ
前面写了关于ADC采集电压的文章,大家除了求平均的方式来处理采样值,还有没有使用到其他的方式来处理采集值呢?
在某些情况下就需要对一组数据进行排序,并提取头特定的数据出来使用。
排序的应用场合很多,我这里就不再一一举例说明,掌握排序的基本算法,到时候遇到就有用武之地。
排序算法分类 Ⅱ
1.按存储分类:内部排序和外部排序
内部排序:是数据记录在内存中进行排序;
外部排序:是因排序的数据很大,一般一次不能容纳全部的排序记录,在排序过程中需要访问外存。
内部排序高速、有效,是我们比较常用的排序方法。外部排序速度慢,效率低,一般不建议使用外部排序,比较实用的排序还是只有内部排序。
2.内部排序分类:插入排序、选择排序、交换排序、归并排序、基数排序。
排序的分类大致为如下图:
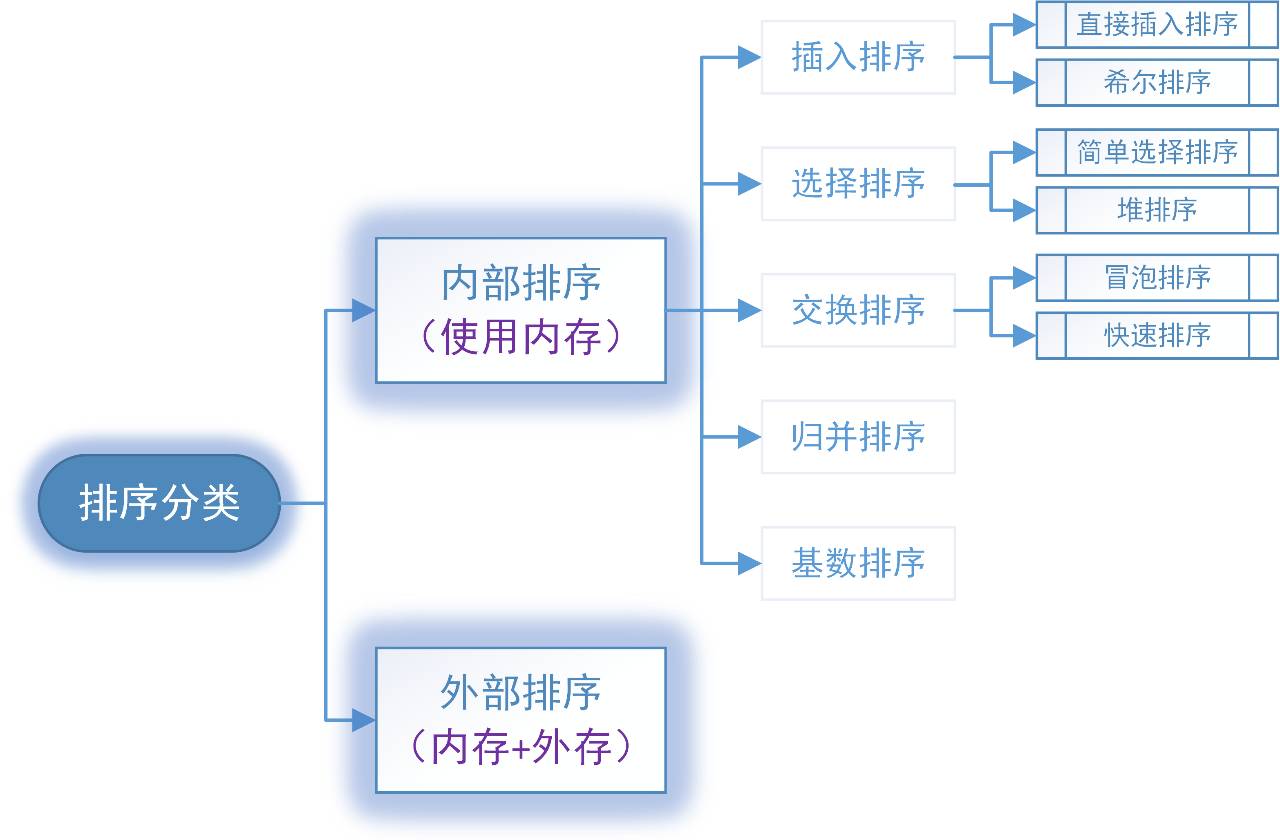
在内部排序中,最常见、有效且实用的排序算是交换排序,本文将在下面章节重点讲述交换排序中的冒泡排序和快速排序。
交换排序 Ⅲ
1.冒泡排序
冒牌排序是我们读书时最先接触的一种排序算法,也是比较经典的排序算法。
冒泡排序就是在要排序的一组数中,对当前还未排好序范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
原始的冒泡排序函数:
void bubbleSort(int a[], int n)
{
for(int i =0 ; i< n-1; ++i)
{
for(int j = 0; j < n-i-1; ++j)
{
if(a[j] > a[j+1])
{
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
}
}
}
}
其实,原始的冒泡排序不是最后的算法,如果进行某一趟排序时并没有进行数据交换,则说明数据已经按要求排列好,可立即结束排序,避免不必要的比较过程。
对冒泡排序常见的改进方法是加入标志性变量,用于标志某一趟排序过程中是否有数据交换。
第1种改进法:设置一标志性变量pos,用于记录每趟排序中最后一次进行交换的位置。由于pos位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。
void Bubble_1( int r[], int n)
{
int pos = 0;
int i;
int j;
int tmp;
i = n - 1;
while(i > 0)
{
for(j=0; j
{
if(r[j] > r[j+1])
{
pos = j; //记录交换的位置
tmp = r[j];
r[j] = r[j+1];
r[j+1] = tmp;
}
}
i= pos;
}
}
第2种改进法:传统冒泡排序中每一趟排序操作只能找到一个最大值或最小值,我们考虑利用在每趟排序中进行正向和反向两遍冒泡的方法一次可以得到两个最终值(最大者和最小者) , 从而使排序趟数几乎减少了一半。
void Bubble_2(int r[], int n)
{
int low = 0;
int high= n -1;
int tmp,j;
while(low < high)
{
for(j=low; j//正向冒泡,找到最大者
{
if(r[j]> r[j+1])
{
tmp = r[j];
r[j]=r[j+1];
r[j+1]=tmp;
}
--high;
for(j=high; j>low; --j) //反向冒泡,找到最小者
{
if(r[j]
{
tmp = r[j];
r[j]=r[j-1];
r[j-1]=tmp;
}
++low;
}
}
}
}
2.快速排序
大致步骤如下:
1)选择一个基准元素,通常选择第一个元素或者最后一个元素。
2)通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的元素值比基准值大。
3)此时基准元素在其排好序后的正确位置。
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
举例:
对无序数组[6 2 4 1 5 9]排序:
a),先把第一项[6]取出来,
用[6]依次与其余项进行比较:
如果比[6]小就放[6]前边,2 4 1 5都比[6]小,所以全部放到[6]前边;
如果比[6]大就放[6]后边,9比[6]大,放到[6]后边;
一趟排完后变成下边这样:
排序前62 4 1 5 9
排序后 2 4 1 569
b),对前半边[2 4 1 5]继续进行快速排序
重复步骤a)后变成下边这样:
排序前24 1 5
排序后 124 5
前半边排序完成,总的排序也完成:
排序前:[6 2 4 1 5 9]
排序后:[1 2 4 5 6 9]
排序结束
代码
将前后分开函数:
int partition(int unsorted[], int low, int high)
{
int pivot = unsorted[low];
while(low < high)
{
while((low < high) && (unsorted[high] >= pivot))
--high;
unsorted[low] = unsorted[high];
while((low < high) && (unsorted[low] <= pivot))
++low;
unsorted[high] = unsorted[low];
}
unsorted[low] = pivot;
return low;
}
快速排序函数:
void quickSort(int unsorted[], int low, int high)
{
int loc = 0;
if(low < high)
{
loc = partition(unsorted, low, high);
quickSort(unsorted, low, loc -1);
quickSort(unsorted, loc + 1, high);
}
}
举例测试:
void Main(void)
{
int i;
int a[6] = {6, 2, 4, 1, 5, 9};
quickSort(a, 0, 5);
for(i=0; i<6; i++)
printf("a[%d] = a[%d]\n", i, a[i]);
}
在排序算法中,这两种是较重要的排序算法,其他算法在特定场合也有用武之地,本文暂时讲述到这里。
-
嵌入式stm32实用的排序算法 - 交换排序2018-04-12 0
-
C语言教程之几种排序算法2017-11-16 1760
-
一文了解冒泡排序2018-01-17 3031
-
常用的排序算法总览2018-06-13 2829
-
常用的非比较排序算法:计数排序,基数排序,桶排序的详细资料概述2018-06-18 7131
-
快速排序是一种交换排序2018-07-27 2915
-
冒泡排序算法原理2019-03-29 14282
-
排序算法分享:归并排序说明2020-12-24 771
-
揭秘冒泡排序、交换排序和插入排序2021-06-18 1548
-
浅谈希尔排序算法思想以及如何实现2021-06-30 2026
-
冒泡排序的基本思想2023-01-20 5892
-
php版冒泡排序是如何实现的?2023-01-20 934
-
常见排序算法分类2023-06-22 910
-
FPGA排序-冒泡排序介绍2023-07-17 1083
-
十大排序算法总结2023-12-20 1123
全部0条评论

快来发表一下你的评论吧 !
