

实操RT-Thread系统CPU利用率功能添加
描述
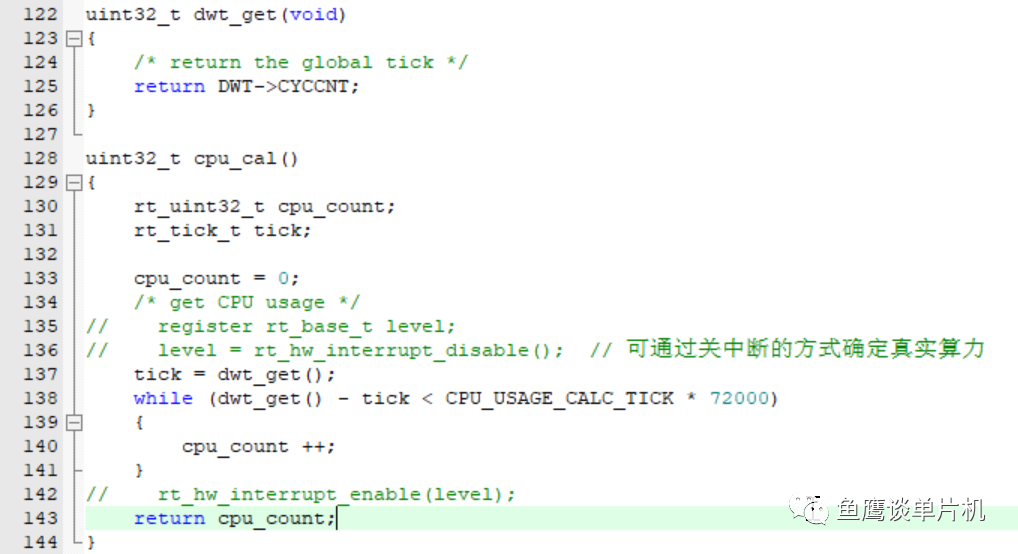
我之前的文章提到了为什么我们需要关注CPU利用率的问题,总结一句话就是,利用率越低,你的系统效率越高、响应越快,实时性越高。但是并没有具体说该如何计算CPU利用率。 今天,借助国产操作系统RT-Thread,我们开始实操一番。 在实操之前,需要简单了解几个概念。钩子函数,即以hook命名的那些函数。那么什么是钩子函数呢?说白了,就是一个函数指针,只是这个函数比较特殊一点。 特殊在哪?操作系统某些指定位置才会设置钩子函数,比如程序运行到空闲任务了,为了不修改系统源码(没事别修改源码,很危险的事情,除非你是真大佬),系统会提供一个设置钩子函数的函数接口给你,当你需要在空闲任务中执行某些功能时,用这个函数设置你的需要功能函数就可以了,等系统运行到空闲任务,他就会帮你调用这个函数了。 这个功能看着是不是有点眼熟,对的,和所谓的回调函数是一个道理(我也不明白为啥叫钩子函数,可能是因为和系统有关,和通用的回调函数又有点区别,所以就称之为钩子函数吧,不过你不要管名称,只要知道意思就行了)。 除了在空闲任务可以设置钩子函数,还有可能在任务切换、系统启动、任务创建等等关键的地方设置,当然了,这里的每一个钩子函数都是一个单独的函数指针。 前面也说了,设置钩子函数的目的只有一个,那就是可以让你在不修改系统源码的情况下达到私人目的,让系统的扩展性更强,比如今天说的内容(还有下次介绍的线程CPU使用率问题),如果系统没有空闲钩子函数的存在,你只能去修改系统源码才能达到目的啦。 还有文章所说的线程(task)、任务(thread),其实在RTOS中都是一样的。在 uCOS、FreeRTOS 中,叫任务,RT-Thread 叫线程,只是叫的名称不一样,内容都是差不多的。 然后再大概说说怎么计算的问题。也就是在空闲钩子函数里面,我们需要干什么事情才能到达CPU计算的目的。 首先,第一步肯定是设置钩子函数,其次就是钩子函数该怎么写的问题。这个网上一搜就出现了(鱼鹰也是网上搜的代码),然后就要分析为什么这么写。 前面说过,CPU利用率其实是首先计算一段时间内空闲任务执行时间,然后反推其他任务的执行时间。 这里有两个问题,一段时间是多少?空闲任务的执行时间怎么计算?先说第二个问题。用定时器时间掐?好像不好,因为你不知道什么时候程序就离开了空闲任务跑去执行其他任务了,而即使你可以知道它什么时候离开空闲任务的,那也会增加计算难度,不是好的方式。 那怎么办?还记得刚学单片机时你是怎么进行软件延时的吗?对,就是用这个方法,软件延时! 只要程序执行到空闲任务了,就用一个变量不停自加。这样就可以根据变量值来大概计算空闲任务的执行时间。 但是这里又存在一个问题:如果这个变量一直自加,肯定会溢出,该怎么解决。 加大变量的大小,比如原先使用一个字节、两个字节的,那么如果溢出,就用四个字节、八个字节。 但32位系统最大能支持的也就8个字节了,如果还是溢出了咋办?再套一个循环,一个循环的数加完了,再加另一数就行了。 但是还有一个问题,如果说自加的时间不做限制,那么再多的变量也不行,而且还会影响CPU计算的实时性,也就不能实时反映CPU利用率了;而如果时间太短,如果刚好有任务的执行时间在这个范围,那么很可能你计算CPU利用率就直接是100%了。 比如说你一个任务需要执行10毫秒,然后你计算CPU的周期也是10毫秒,那么可能刚好开始计算时跳到了那个任务执行,那么你的变量就没有自加了,也就会显示100%利用率了。 这里其实说的是前面的第一个问题,一段时间是多少? 对于这个时间,因为鱼鹰看的书籍比较少,所以也没有理论支撑(如果有道友知道的,不如留言)。 但是肯定既要考虑变量溢出(这个可以通过加循环方式解决),又要考虑实时性,还要考虑其他任务的最大执行时间,否则本来系统没有问题的,但是因为你追求实时性,导致CPU利用率80%、90%的,那就很尴尬了。 以上讨论如果没有经验可能比较难理解,所以建议大家在看完后面内容,实操过后,再回头重新看一遍,这样才有更深的理解。 现在再看CPU计算公式:
cpu_usage = (total_count – count)/ total_count × 100 %(滑动查看) cpu_usage: CPU利用率; total_count:单位时间内全速运行下的变量值; count:单位时间内空闲任务自加的变量值。 total_count这个值表现了单片机全速运行下,所能达到的最大值。所谓全速运行,即不响应中断,也不去执行其他任务,就单纯让它在一个地方持续运行一段时间,这个值可以体现CPU的算力有多大。 比如,51单片机,可能这个值自加10毫秒之后只有100,STM32F1单片机自加能到1000,而STM32F4单片机能到2000,这样就能体现他们之间的算力差别了。 这个值可以是动态的,也可以是静态的。静态有静态的好处,动态有动态的好处。 所谓的静态是指,在系统没有运行任务时,关闭所有的中断,自加这个值。这样,这个值比较准确,但是如果一开始这个值计算错了,那么后面的计算肯定也是有问题的,而且如果系统启动后长时间既不启动任务,也不响应中断,肯定对系统有一定的影响。但是好处是,系统消耗更少,因为他只计算一次。 而动态计算,则是在空闲任务中,当这个值为零时,计算一次,之后只会在空闲任务自加的变量值超过这个数时,才会更新这个值,这样一来,最终还是能准确反映CPU利用率的。好处是,不需要在开机时关闭所有中断,当然坏处是,前期可能不是很准,因为可能由于中断原因导致计算的值较小(中断处理时消耗了算力)。 废话太多了一些,直接开始干吧。新建一个文件,拷贝如下代码:
#include
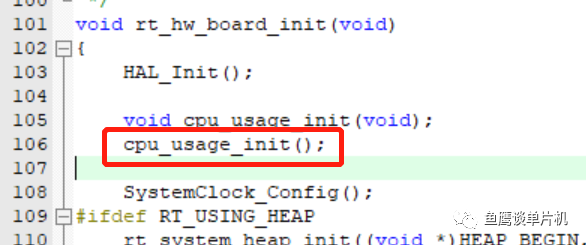
然后,就没有然后了。 对的,设置完之后就可以了,但为了让我们能观察到,可以打印出来。
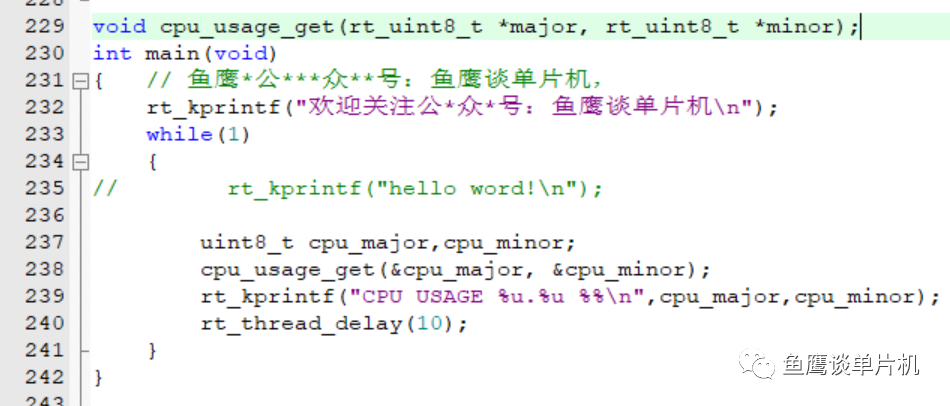
我们可以观察效果如何,开始设置计算周期和任务延时函数一样,10毫秒。 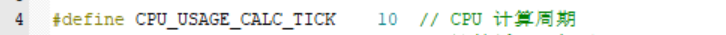 测试结果:
测试结果:
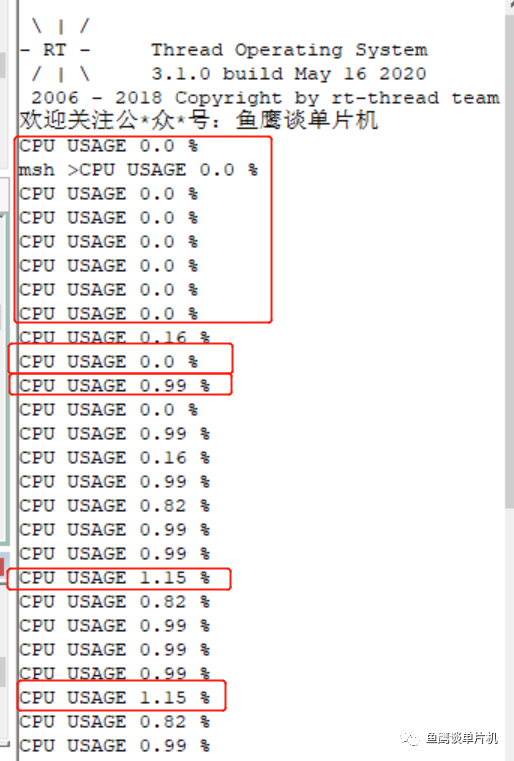
可以看到,因为是动态计算的,所以开始为0,因为系统首先运行其他任务,只有其它任务不运行时,才会开始运行空闲任务,所以CPU利用率为0。 但是即使后面有值了,你也会发现CPU利用率变化很大,0.82%~1.5%。而且你会发现除了开始的0.0%,后面又再次出现了,这又是怎么回事? 通过设置断点分析,发现,这是因为计算值超出了开始的值,重新设置了:
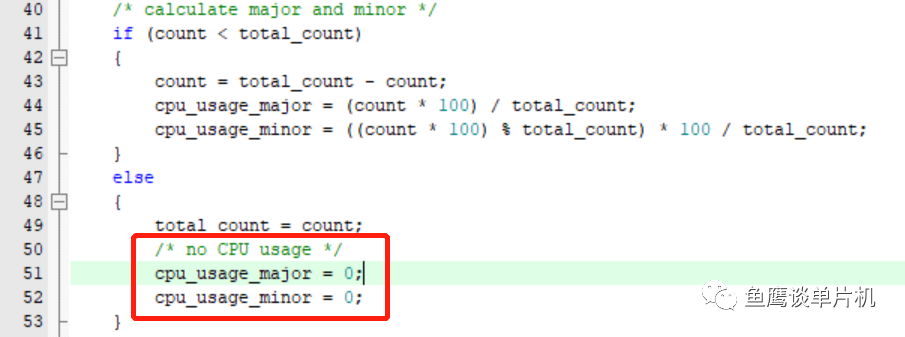
这就是动态计算的一些问题了,它在一开始的一段时间里,因为无法完全表现算力,只能通过后面不停的修正该值才能达到稳定。 现在修改计算周期 20 毫秒:
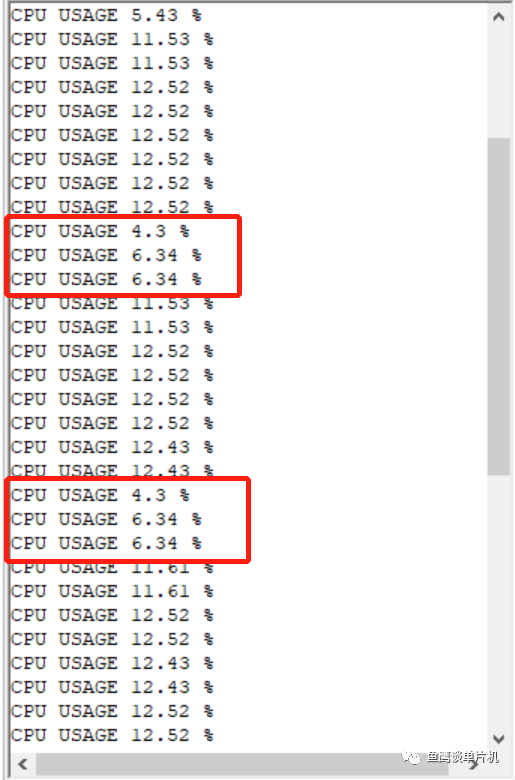
发现它的表现更差劲,4.3%~11.61%,而且会周期性出现低利用率的情况。 再改,100毫秒:
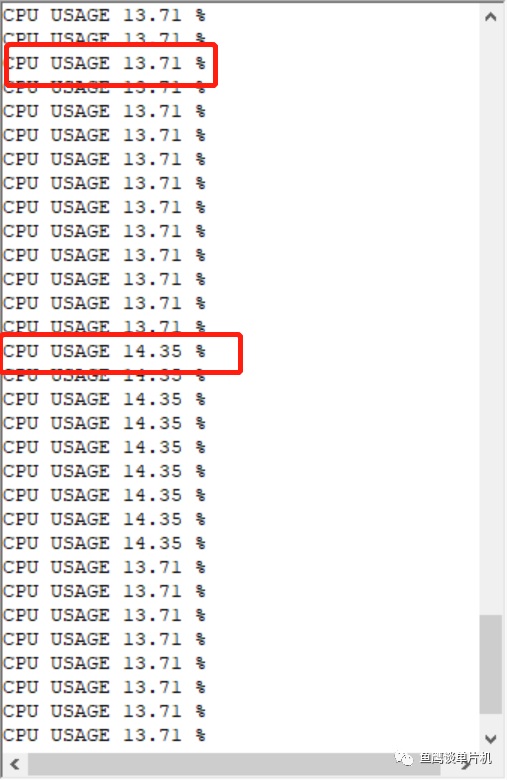
可以看到这个比较稳定了,13.71%~14.35%。 那么这个测试代码实际情况的CPU利用率是多少呢? 我们可以通过前面的笔记《KEIL 下如何准确测量代码执行时间?》大概计算线程执行时间:
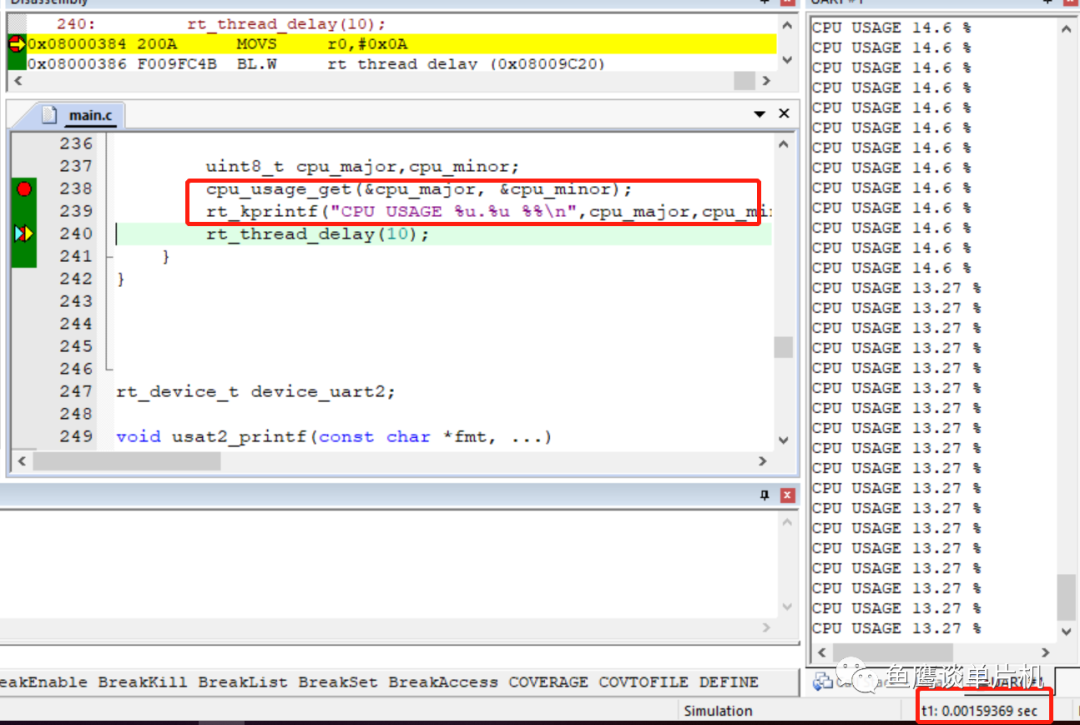
1.59毫秒,10毫秒执行周期,如果只有这个任务执行,大概1.59/10=15.9%(准确计算应该是 1.59/(10 + 1.59) =13.7%)。 和前面的100毫秒类似。 我们先不管前面的结果,先理解一下里面的计算方法。 首先,如果total_count开始为0,那么开始第一次计算。这次计算会关闭调度器。
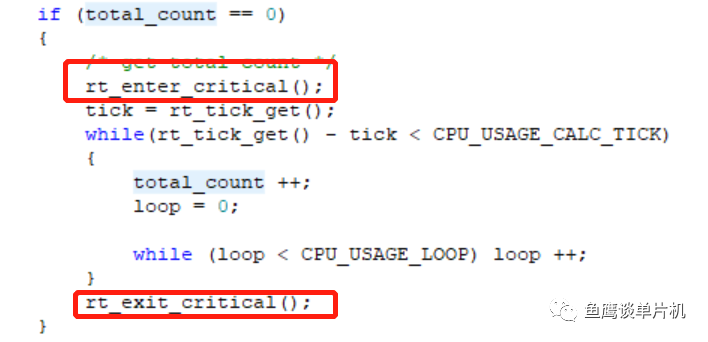
计算过后,就不再进入。 之后就是动态计算过程:
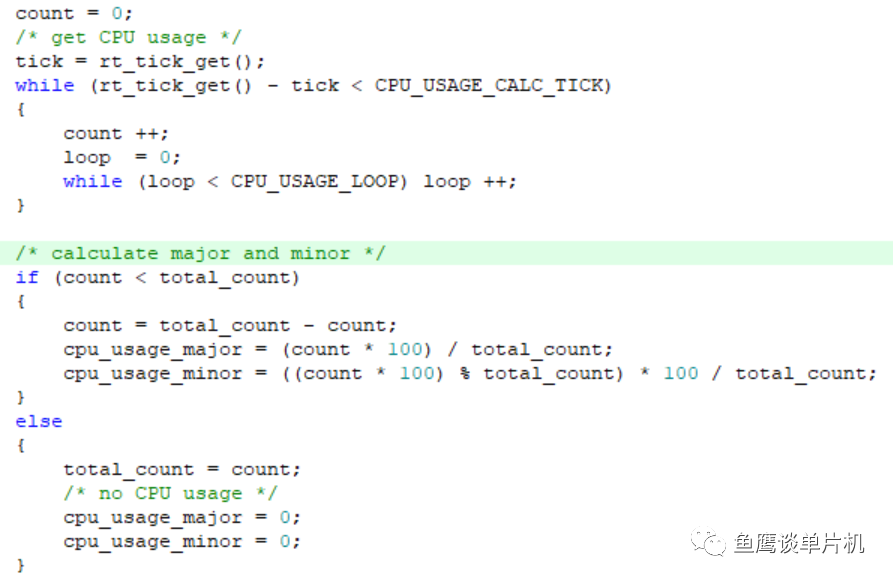
和第一次计算一样,都是在一定时间内自加计数器,不同的是,这次不会关闭调度器,也就是说,如果有高优先级任务就绪,那么是可以执行其他任务的。 并且计时时间使用的是系统函数rt_tick_get(),单位为系统调度时间。测试环境中,系统调度时间为 1 毫秒。 有意思的是,在进行最终的计算时,采用了分步计算,首先计算整数,再计算小数。 为什么要这样做?效率! 这样的计算方法,可以将浮点运算转化成整型运算,这在没有浮点运算单元的单片机中,能大大减少计算时间。 另外,为了防止溢出,还使用了一个循环结构。 理解了以上内容,现在开始进行鱼鹰式深度思考:
上面的分步计算是否存在问题?
关调度器只关闭了任务调度,但还是会响应中断,这能够体现单片机最大算力吗?
使用rt_tick_get() 函数进行计时,精度是多少,会影响最终的计时吗?
有必要使用循环体吗?如果单位时间内不溢出,是否不用循环体会更好?
前面的CPU使用率为什么会跳动,按理说任务的执行时间应该是确定的,也只有一个任务在运行,不应该跳动才对?
10毫秒的计算和100毫秒的计算差别在哪?
7. 终极问题,如何精确计算CPU使用率? 上面的问题,如果只是粗略计算,其实都可以不用考虑,本着对技术的热爱,还是聊一聊好了。 1、分步计算,不知道你想到了什么BUG?这个问题其实在以往的笔记都提过,这次再说一次。 当你在获取CPU使用率时,如果刚好在更新这两个值,那么可能整数部分是上一次计算的值,而小数部分却是这次计算的值,那么肯定有问题。 这就涉及到数据完整性获取的问题。怎么解决。关调度器、关中断都可以。 但是因为是粗略计算,那么小数部分即使是错误的,也没事。 2、因为只关调度器,所以对于中断还是会响应,比如说你设定计算周期为100毫秒,那么1毫秒一次的systick中断肯定会执行,那么在100毫秒中,有100次进入中断执行,而这些算力在上述算法中是无法体现的。 3、rt_tick_get() 函数精度问题,因为这个是系统的软件计时器,所以在测试环境中为1毫秒递增一次,也就是说它的精度在1毫秒。因此,在100毫秒的计算周期里面,有1% 的误差存在,在10毫秒的计算周期里面,误差10%! 4、有没有必要用循环体?在1秒计算一次的情况下,即使不用循环体,也不会导致溢出问题。而且使用了循环体,还会导致精度降低,毕竟样本少了。比如使用循环体最大值为100,不使用时为10000,哪个精度高? 5、CPU使用率跳动问题。因为是测试,所以只有一个任务在运行,而且任务很简单。
这个任务的执行时间应该是固定的才对,但即使是使用了后面的高精度计算方式,CPU使用率还是会跳动,这是为什么? 第一,rt_kprintf函数执行时间是不固定的,不固定在哪,比如要显示的变量开始是1,后面是1000,因此它输出的字符串不一样,并且打印时间也不一样,因为是查询方式打印,所以差别很大!这就是我为什么推荐DMA打印的原因,未使用前是10%,使用后可能就是1%,甚至更低。 第二点,也是非常容易忽视的一点,插入的中断执行时间。 系统每隔1毫秒需要进入systick执行一次(或者其他中断执行时间),如果说任务的执行时间超过1毫秒,那么中间必然会先执行中断,再执行任务,这样一来,因为中断的插入,导致时间不再那么准确了。而当你把打印的时间控制在 1 毫秒以内,那么CPU使用率会变的非常稳定。 第三:延时rt_thread_delay()函数本身的误差,受到系统精度的影响,这个延时时间其实也不是固定的,会有一定的浮动。 6、10毫秒和100毫秒计算的差别? 如果说你的任务执行时间小于1毫秒,那么在10毫秒和100毫秒的计算差别不是很大,但是如果说计算周期变成了5毫秒,即使任务执行时间小于1毫秒的情况下,计算值也是会在最大和最小之间来回跳动的。而执行时间一旦超过1毫秒,那么10毫秒和100毫秒的计算就有较大的差别。 并且测试的时候,因为系统延时时间是10毫秒,而计算的时候也是10毫秒的周期,所以出现了比较诡异的事情,因为按理说延时10毫秒,任务执行时间2.56毫秒,任务运行周期为12 毫秒(还记得前面所说的延时误差吗),CPU 使用率按理应该是 21.3 左右,实际上却是 6.5% 左右,相差太大了,这就非常奇怪了。而且如果更改执行时间为1.5毫秒时(通过修改代码修改执行时间),发现计算值又正常了;而即使不修改执行时间,修改计算时间为100毫秒,又正常了,这是怎么回事? 通过深入分析发现,刚好在主任务延时10毫秒的时候,切换到了空闲任务进行空闲时间计算,执行了9.4毫秒的时候,又切回到了主任务,所以计算时,得到了6.5%的计算值。 粗略表示如下所示:
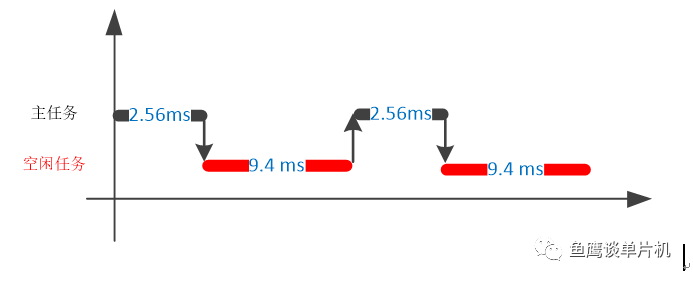
通过这个分析,你应该知道,计算CPU的时候,尽量不要使用和任务延时时间一样的计算周期,否则会出现莫名其妙的事情;还有一点就是,任务的执行周期 = 任务执行时间 + 系统延时,而前面所介绍的计算方法只是粗略的表示,严格来说是有问题的。 7、终极问题,如何提高计算精度?通过以上分析,我们其实已经知道了计算时的一些问题点。首先,计算周期问题,这个可以根据系统来确定,但是千万要注意前面的提到的问题。如果说500毫秒计算周期可以满足要求的话,就没必要使用50毫秒,不然你会发现计算值跳动很大。 其次,时间精度问题,这个问题老生常谈了,鱼鹰建议是DWT,如果没有,找一个定时器代替也是可以的。 最后是单位时间算力问题,为了保证精确,可以关闭中断进行第一次计算,或者用短一点的时间,比如1毫秒得到一个算力,如果计算周期为100毫秒,那这个算力乘以100就行了。当然如果系统时钟不经常变的话,也可以通过静态方式先得到单位时间的算力,之后就以它为标准就可以了。这样就不会有长时间关中断的情况出现了。 但是计算算力的时候,千万千万要注意一点的是,C语言转化为汇编代码时,可能一样的代码,在不同的地方执行时间是不一样的(比如前面代码的第一次计算和后面的计算,看似一样,但实际上有较大差别,原因就在于执行效率不一样),这个涉及到寄存器比内存效率更高的问题,所以计算算力时,可以把它封装成一个函数,这样,只要优化等级不变,那么函数的执行时间就可以认为是确定的。
-
灵动微课堂 (第138讲) | 基于MM32 MCU的OS移植与应用——RT-Thread CPU利用率统计2020-09-24 0
-
RT-Thread CPU利用率的统计与测试步骤2022-05-13 0
-
RT-Thread编程指南2015-11-26 2009
-
RT-Thread用户手册2015-11-26 1506
-
RT-Thread软件包定义和使用2018-05-21 10401
-
RT-Thread Studio 主要亮点功能2020-06-19 5901
-
RT-Thread STM32 配置系统时钟(使用外部晶振)2021-12-14 1546
-
栈利用率的获取2021-12-20 448
-
RT-Thread全球技术大会:RT-Thread构建配置系统2022-05-27 1235
-
RT-Thread全球技术大会:RT-Thread测试用例集合案例2022-05-27 2102
-
RT-Thread学习笔记 RT-Thread的架构概述2022-07-09 4557
-
RT-Thread文档_RT-Thread 简介2023-02-22 609
-
RT-Thread文档_RT-Thread 潘多拉 STM32L475 上手指南2023-02-22 644
-
RT-Thread文档_RT-Thread SMP 介绍与移植2023-02-22 608
-
基于RT-Thread Studio学习2023-05-15 3968
全部0条评论

快来发表一下你的评论吧 !
