

关于云主机驱散相关知识点的详细说明
今日头条
描述
1 驱散目的
当云主机所在节点宕机或者节点网络异常时可以触发驱散操作,可以将宕机节点上的云主机驱散到其他节点,从而可以继续访问这些云主机。
这里有必要说明一点,驱散和迁移的关联与区别,关联在于驱散操作可以使用迁移命令来查看驱散的信息,而区别在于迁移时源节点和目标节点都是正常的,节点上的nova-compute服务也是正常的,这说明在没有共享存储的情况下也是可以进行迁移的;而驱散时源节点是宕机的状态或者nova-compute服务不正常,所以驱散无法访问源节点必须访问共享存储获取云主机磁盘数据。这是二者的本质区别。
2 简要流程
1、nova-api接受驱散操作,校验云主机所在节点状态为down,并且云主机状态为active,stopped,error才能执行 evacuate并创建该云主机的迁移任务,这里的迁移类型为evacuation,可以通过nova migration-list命令查看驱散执行情况。
2、之后nova-api发送rpc到nova-condu ctor进行云主机重建rebuild_instance。
3、然后nova-conductor接收到rebuild_i nstance的rpc请求后,调用nova-scheduler选择资源足够的可用节点,并获取该云主机的迁移任务,从该任务中,获取云主机相关的配置信息。
4、nova-conductor使用被选中的可用节点进行rebuild_instance
5、可用节点的nova-compute接收到rebuild_instance的rpc消息后重新设置该云主机对应的网络端口,直接使用云主机的云硬盘,最终启动云主机。
6、宕机节点恢复后,nova-compute服务会自动检测执行驱散操作成功的云主机,并对应云主机在本机的信息,而对于驱散操作失败的云主机不做任何操作。
3 代码分析
3.1 驱散api接口代码,nova-api接收驱散操作请求,代码位于nova/api/compute/evacuate.py
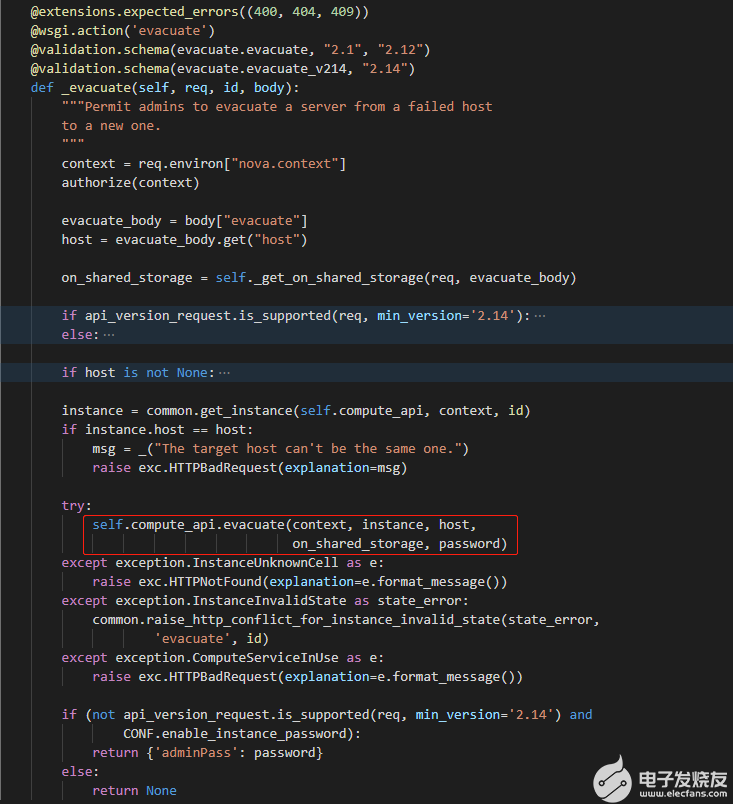
之后会调用nova/compute/api.py,并在调用时校验云主机状态,处于ACTIVE,STOPPED以及ERROR状态的云主机才能进行驱散操作。

这里调用了rebuild_instance函数,并且没有指定镜像,而是根据原有信息重建云主机。一般对于重建云主机功能是指定镜像进行重建,而驱散是利用原云主机的数据进行重建,这是驱散功能和重建功能的区别。
3.2 驱散conductor部分代码
之后调用到nova/conductor/api.py

然后nova/conductor/rpcapi.py
这里的cast调用是异步的,是在nova-api进程里面调用的,实际在此之前的调用都是在nova-api的进程里面,而将rebuild_instance调用发送到nova-conductor后,此时nova-api的处理才告一段落,nova-conductor服务才真正接手处理。最后会调用到nova/conductor/manager.py

这里的cast调用是异步的,是在nova-api进程里面调用的,实际在此之前的调用都是在nova-api的进程里面,而将rebuild_instance调用发送到nova-conductor后,此时nova-api的处理才告一段落,nova-conductor服务才真正接手处理。最后会调用到nova/conductor/manager.py

这里没有将涉及nova-scheduler部分代码列出,实际这里的调度主要是通过过滤filter来实现的,检查节点是否有可用的CPU和内存等。
需要注意的是,若是没有指定目标节点则scheduler会自动选择一个合适的节点进行驱散,若没有找到合适的节点则驱散失败,云主机状态会出错;注意这里还有一个异常,不支持的策略异常UnsupportedPolicyException,这个异常一般是出现亲和性策略时的异常,也就是若云主机设置了某些亲和性策略则有可能导致驱散失败。
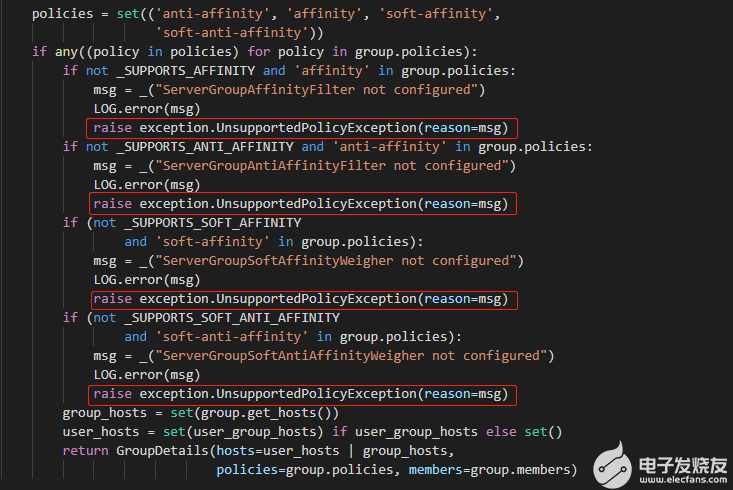
上述在调度节点出现的两个异常无效主机和不支持策略,从而导致驱散失败后,在节点恢复后,不会做任何操作,重置云主机状态之后,是可以在恢复后的节点启动云主机的。
3.3 驱散compute部分代码
之后调用nova/compute/rpcapi.py

然后就会调用到nova/compute/manager.py的rebuild_instance函数,最终会调用_do_rebu ild_instance函数,
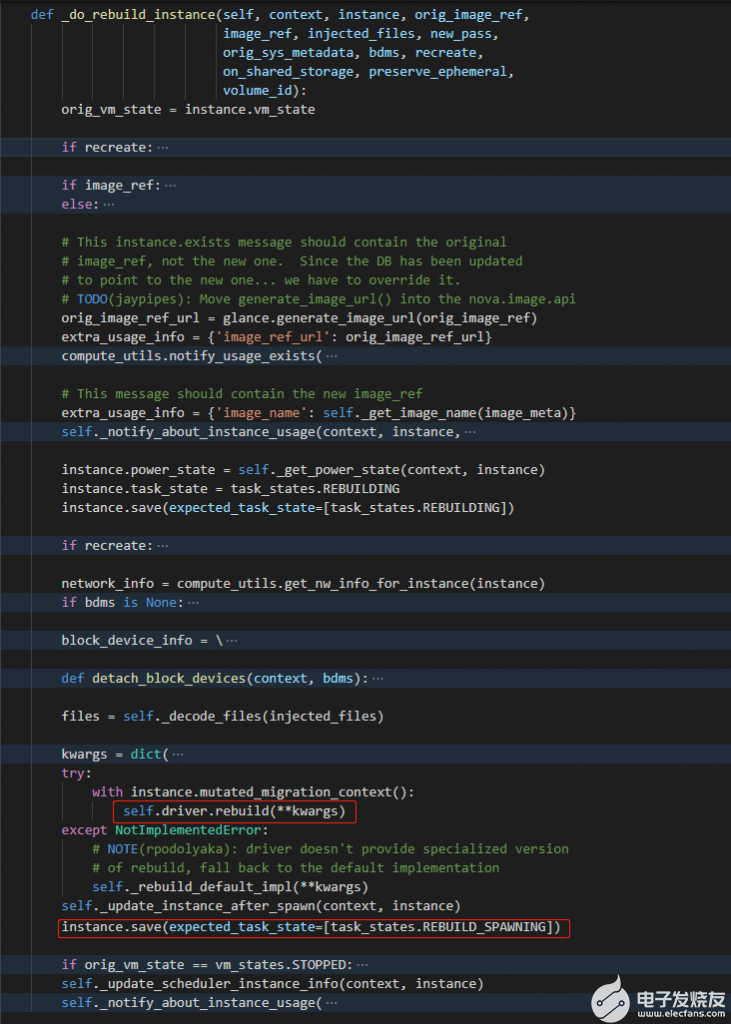
一般到了nova-compute这一侧,云主机开始重建了,但不能说完全没有问题了,这里在云主机保存数据时,有可能会出错,原因就是发送消息到nova-conductor出错了,从而数据库里面的该云主机的数据没有更新,从而导致云主机出现错误状态。
需要注意的是,从代码看如果云主机已经在其他节点上启动了,但是其显示为错误状态,查看驱散为失败状态,若要恢复云主机,这个时候是不能直接重置云主机的,需要修改数据库instances表,将对应云主机的host和node字段值为启动节点的名称,宕机节点恢复后nova-compute服务启动后会自动删除本机节点上云主机信息。
4 故障
4.1 故障说明
对于云主机驱散操作失败的,一般存在以下几个原因。1.在nova-scheduler调度时没有找到可用的节点导致驱散失败。2.在nova-scheduler调度时若云主机存在亲和性策略可能导致驱散失败。3.发送消息给nova-conductor保存云主机数据时出错,也即发送消息时出现异常,导致驱散出错。
4.2 故障恢复
出现的故障如何进行修复,这里有一个重要的区分条件,就是云主机是否在其他节点上对应的信息,对于前面两点,云主机在其他节点没有对应信息,待宕机节点恢复后重置云主机状态即可;对于后面一点,如果云主机在其他节点上也有对应信息了,就不能直接重置状态操作了,目前对于这样的问题没有对应具体的处理命令,所以需要修改数据库。这里重申一遍在操作数据库时请先保存数据库,也请慎重操作数据库。
4.3 重置云主机
如何重置云主机状态,在终端使用如下命令,nova reset-state –active

4.4 修改数据库
对于驱散出错的云主机,先找到云主机的ID,nova list |grep vm_name,记录返回的云主机ID,在修改数据库时需要用到这个ID值。修改数据库前,请先备份数据库。
mysqldump -u nova -p nova > nova.sql
之后会提示输入密码,完成备份后,再修改数据库表。登陆nova数据库,修改instances表,具体sql语句如下,update instances set host=’node-name’, node=’node-name.node.consul’ where uuid=’ID’。修改后退出数据库,然后重置云主机状态。
fqj
-
关于RTC时钟的知识点2021-08-11 0
-
关于工业相机相关知识点总结的太棒了2021-09-29 0
-
关于蓝牙模块基础知识点介绍的太详细了2021-10-08 0
-
关于AUTOSAR架构的知识点看完你就懂了2021-10-18 0
-
萌新求助,求大佬分享关于云计算发展历程的知识点2021-10-28 0
-
关于红外通信的一些问题知识点2016-05-05 935
-
UART中的硬件流控RTS与CTS的知识点详细资料说明2019-05-31 3316
-
光电的知识点和单位运用等详细资料说明2019-10-08 1067
-
机器学习的基础知识详细说明2020-03-24 1046
-
Python的知识点总结详细说明2020-09-29 1152
-
FPGA的入门基础知识详细说明2020-12-20 9526
-
学好模电的必备知识点2021-06-03 1346
-
机智云入门知识点2021-12-07 537
-
数字威廉希尔官方网站 知识点总结2023-05-30 4873
-
电阻的相关知识点2023-09-13 1736
全部0条评论

快来发表一下你的评论吧 !
