

复杂应用中运用人工智能核心 强化学习
人工智能
描述
近期,有不少报道强化学习算法在 GO、Dota 2 和 Starcraft 2 等一系列游戏中打败了专业玩家的新闻。强化学习是一种机器学习类型,能够在电子游戏、机器人、自动驾驶等复杂应用中运用人工智能。在状态和动作空间较大、环境信息不完善并且短期动作的长期回报不确定的游戏中,这些程序可以找出最佳动作。
不只是游戏王者,强化学习作为机器学习的一个分支,在真实系统设计中,它能帮助您针对复杂系统(如机器人和自主系统)实现控制器和决策系统。借助深度强化学习,您可以实现深度神经网络,这类网络运用通过仿真模型动态生成的数据进行训练,从而学习复杂行为。您只需准备一个仿真模型来表示您正在与之交互并尝试控制的环境,而无需提供标注或者未标注的预定义训练数据集。
MATLAB 和 Simulink 支持设计和部署基于强化学习的控制器的整套工作流。您可以:
通过简单的控制系统、自主系统和机器人示例,初步了解强化学习
在常见强化学习算法间快速切换并加以评估和比较,只需对代码稍加改动即可实现
使用深度神经网络,根据图像、视频和传感器数据定义复杂强化学习策略
使用本地核心或云并行运行多个仿真,加速完成策略训练
将强化学习控制器部署到嵌入式设备
强化学习智能体(agent)
强化学习智能体由策略和算法构成,策略用于执行从输入状态到输出动作的映射,算法负责更新策略。常见算法包括深度 Q 网络、Actor-Critic 和深度确定性策略梯度。算法会更新策略,使之最大化环境提供的长期奖励信号。策略可通过深度神经网络、多项式或查找表进行表达。然后,您可以将内置智能体和自定义智能体作为 MATLAB 对象或 Simulink 模块加以实现。
在 MATLAB 和 Simulink 中进行环境建模
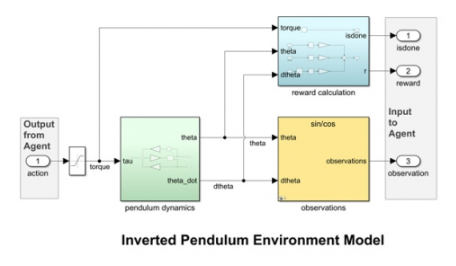
强化学习算法训练是一个动态过程,因为智能体需要与周边环境进行交互。对于机器人和自主系统等应用形式,在真实环境中使用实际硬件开展此类训练不仅代价高昂,还可能面临危险。正因如此,人们倾向于采用通过仿真生成数据的虚拟环境模型来开展强化学习。您可以在 MATLAB 和 Simulink 中构建环境模型,以此描述系统动态、智能体的行动对系统动态产生的影响,以及用于评估所采取行动优度的奖励。这些模型在本质上可以是连续的或者离散的,可以采用不同的保真度来表示系统。此外,您也可以通过并行仿真来加快训练。在某些情况下,您还可以重用现有的 MATLAB 和 Simulink 系统模型,只需稍加改动即可将其用于强化学习。
-
人工智能在汽车中有什么应用?2019-08-06 0
-
通用人工智能啥时候能实现2020-12-17 0
-
深度强化学习实战2021-01-10 0
-
人工智能芯片是人工智能发展的2021-07-27 0
-
人工智能汽车标定方案2021-09-09 0
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 0
-
利用人工智能进行SoC预测性布局2022-11-22 0
-
【书籍评测活动NO.16】 通用人工智能:初心与未来2023-06-21 0
-
《通用人工智能:初心与未来》-试读报告2023-09-18 0
-
如何深度强化学习 人工智能和深度学习的进阶2018-03-03 4214
-
人工智能机器学习之强化学习2018-05-30 1414
-
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?2018-07-15 17582
-
强化学习泡沫之后,人工智能的终极答案是什么?2018-08-09 6172
-
人工智能的强化学习要点2020-05-04 3499
-
人工智能强化学习开源分享2023-06-20 311
全部0条评论

快来发表一下你的评论吧 !
