

深层神经网络模型的训练:过拟合优化
描述
·过拟合(Overfitting)
深层神经网络模型的训练过程,就是寻找一个模型能够很好的拟合现有的数据(训练集),同时能够很好的预测未来的数据。
在训练过程中由于模型建立的不恰当,往往所训练得到的模型能够对训练集的数据非常好的拟合,但是却在预测未来的数据上表现得非常差,这种情况就叫做过拟合(Overfitting)。
为了训练出高效可用的深层神经网络模型,在训练时必须要避免过拟合的现象。过拟合现象的优化方法通常有三种,分别是:正则化(Regulation),扩增训练集(Data augmentation)以及提前停止迭代(Early stopping) 。
·正则化(Regulation)
正则化方法是指在进行损失函数(cost function)优化时,在损失函数后面加上一个正则项。
正则化方法中目前常用的有两种方法:L2 正则化和 Dropout 正则化。
L2 正则
L2 正则是基于 L2 范数,即在函数后面加上参数的 L2 范数的平方,即:
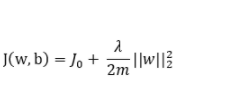
其中J0是原损失函数,m 表示数据集的大小。使用下式对参数进行更新:
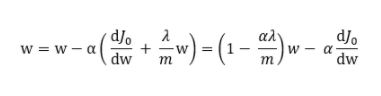
其中 ,因此知道 w 在进行权重衰减。在神经网络中,当一个神经元的权重越小时,那么该神经元在神经网络中起到的作用就越小,当权重为 0 时,那么该神经元就可以被神经网络剔除。而过拟合现象出现的原因之一就是,模型复杂度过高。那么,也就是说 L2 正则化后,权重会衰减,从而降低了模型的复杂度,从而一定程度上避免对数据过拟合。
,因此知道 w 在进行权重衰减。在神经网络中,当一个神经元的权重越小时,那么该神经元在神经网络中起到的作用就越小,当权重为 0 时,那么该神经元就可以被神经网络剔除。而过拟合现象出现的原因之一就是,模型复杂度过高。那么,也就是说 L2 正则化后,权重会衰减,从而降低了模型的复杂度,从而一定程度上避免对数据过拟合。
随机失活(Dropout)正则
其实 Dropout 的思路与 L2 的思路是一致的,都是降低模型的复杂度,从而避免过拟合。只是实现的方法有所不同。
Dropout 的做法是,在训练过程中,按照一定的概率随机的忽略掉一些神经元,使其失活,从而就降低了模型的复杂度,提高了泛化的能力,一定程度上避免了过拟合。

常用的实现方法是 Inverted Dropout。
使用 Dropout 的小技巧
·1、通常丢弃率控制在 20%~50%比较好,可以从 20%开始尝试。如果比例太低则起不到效果,比例太高则会导致模型的欠学习。
·2、在大的网络模型上应用。当 dropout 用在较大的网络模型时更有可能得到效果的提升,模型有更多的机会学习到多种独立的表征。
·3、在输入层(可见层)和隐藏层都使用 dropout。在每层都应用 dropout 被证明会取得好的效果。
·4、增加学习率和冲量。把学习率扩大 10~100 倍,冲量值调高到 0.9~0.99.
·5、限制网络模型的权重。大的学习率往往导致大的权重值。对网络的权重值做最大范数正则化等方法被证明会提升效果。
·扩增训练集(Data augmentation)
“有时候不是因为算法好赢了,而是因为拥有更多的数据才赢了。”
特别在深度学习中,更多的训练数据,意味着可以训练更深的网络,训练出更好的模型。
然而很多时候,收集更多的数据并不那么容易,要付出很大的代价。那么,为了得到更多的训练数据,我们可以在原有的数据上做一些改动产生新的可用数据,以图片数据为例,将图片水平翻转,放大或者选择一个小角度都可以得到新的图片数据用于训练。
虽然这样的效果没有全新的数据更加好,但是付出的代价却是接近于零的。所以,很多情况下,这是一个非常好的数据扩增方法。
·提前停止迭代(Early stopping)
在训练过程中绘制训练集误差函数的同时也绘制交叉验证集的误差。从下面的图可以看出,训练集误差随着迭代次数增加而不断降低,而验证集误差却是先降低后上升。很明显,在这个模型中,我们希望验证集误差和训练集误差都尽量的小,那么最优点就是在验证集误差的最低点,训练应该在该点处停止,也就是选取该点处的权重值作为神经网络的参数。
但是这种优化方法有很大的缺点。因为提前停止训练,也就是停止优化训练集的误差,通常情况下,在验证集误差达到最小值时,训练集误差还未处于一个足够小的值。从而使得该模型虽然没有出现过拟合现象,却是出现了欠拟合的情况。当然,这种优化方法还是有着表现优异的使用场景的。
编辑:hfy
- 相关推荐
- 神经网络
-
粒子群优化模糊神经网络在语音识别中的应用2010-05-06 0
-
神经网络教程(李亚非)2012-03-20 0
-
请问Labveiw如何调用matlab训练好的神经网络模型呢?2018-07-05 0
-
改善深层神经网络--超参数优化、batch正则化和程序框架 学习总结2020-06-16 0
-
如何构建神经网络?2021-07-12 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
优化神经网络训练方法有哪些?2022-09-06 0
-
基于过拟合神经网络的混沌伪随机序列2009-12-22 686
-
训练神经网络的五大算法2017-11-16 13420
-
卷积神经网络模型训练步骤2023-08-21 1713
-
如何训练这些神经网络来解决问题?2023-11-24 714
-
Kaggle知识点:训练神经网络的7个技巧2023-12-30 655
-
如何训练和优化神经网络2024-07-01 461
-
神经网络拟合的误差怎么分析2024-07-03 580
-
如何使用经过训练的神经网络模型2024-07-12 973
全部0条评论

快来发表一下你的评论吧 !
