

利用神经网络寻找超新星
描述
简介
天文学是研究天体的学科,其研究对象包含恒星、星系、黑洞等。研究天体有点像在自然物理实验室做实验。在这个实验室里,会发生自然界中最为极端的变化过程,而这些过程中的绝大部分都无法在地球上重现。通过比较我们对物理学的了解和在宇宙中发现的事实,观察宇宙中的极端事件可以检验并深化我们对物理的认知。
在天文学家眼中,发生在大质量恒星生命末期的特殊类型事件就非常有趣。恒星由氢通过引力作用聚集而成,当氢的密度足够高时,氢原子开始聚变,继而发出光,并产生氦、碳、氧、氖等元素。聚变过程会产生向外的压力,而引力则会产生向内的压力,二者相互作用,使恒星在燃烧燃料时保持稳定。当恒星试图融合铁原子时,这种稳定的状态就会发生变化。由于融合过程不会产生能量,而是必须从恒星中提取能量,从而导致恒星的核心坍塌并发生超新星爆炸。
蟹状星云,超新星遗迹(图片来自 hubblesite.org)
这个过程对天文学家而言极具意义。借助爆炸过程中出现的极端条件,天文学家可以观察重元素的合成、测试物质在高压和高温下的行为,也可以观察爆炸的产物,即中子星或黑洞。
超新星也可以用作标准烛光。如何测量天体的距离是天文学中的一个典型问题。因为恒星距离地球太远,所以我们很难判断所看到的恒星是离我们很近但是很暗的恒星,还是离我们很远但是很亮的恒星。宇宙中大多数的超新星爆炸过程都非常相似;因此,天文学家选择使用超新星来测量距离,而距离对宇宙学家研究宇宙膨胀和暗能量等都非常重要。
尽管超新星爆炸时非常亮(与其宿主星系的亮度相比),但由于它们距离地球太远、爆炸的发生率太低(每个星系每个世纪大约只有一颗超新星)并且爆炸的持续时间太短(可能持续数天到数周),因此这类事件很难被发现。
此外,要从超新星中获得有用的信息就必须进行跟进,也就是使用一种称为光谱仪的仪器来观察目标超新星,并测量爆炸时在不同频率下释放的能量。由于许多有趣的物理过程发生在爆炸开始后的数小时内,因此,最好尽早开始跟进。
那么,我们如何才能在宇宙中观测到的所有天体中快速找到这些超新星爆炸事件呢?
当今的天文学
几十年前,天文学家必须选择并对准天空中的某个特定天体才能研究该天体。而目前的现代望远镜(例如正在投入使用的兹威基瞬变设施 (ZTF) 或薇拉·鲁宾天文台)能以非常高的速度拍摄天空的大幅图像,每三天观察一次可视范围内的天空,还能制作一段南半球天空的影片。如今,ZTF 望远镜每晚会生成1.4TB的数据,实时识别天空中有趣的变化物体并传送相关信息。
当某个物体的亮度发生变化时,这些望远镜能够探测到这种变化并发出警报。这些警报通过数据流发送,每个警报由三张 63x63 像素的裁剪图像组成。这三张图像分别被称为科学图像、参照图像和差值图像。
科学图像是对特定观察位置的最新观察结果。通常会在探测开始时拍摄模板,然后将该模板与科学图像进行比较。科学图像与模板之间的任何不同之处都会出现在差值图像中。在对图像进行一些处理后,用科学图像减去参照图像,计算得到的便是差值。
目前,ZTF 望远镜平均每晚发送 10 万次警报,最多可发送 100 万次。如果有人想手动检查每一个警报,我们不妨假设检查每一个警报需要 3 秒钟,那么对于一个普通的夜晚(发送 10 万次警报),检查一晚上所有的警报则需要大约 3.5 天时间。
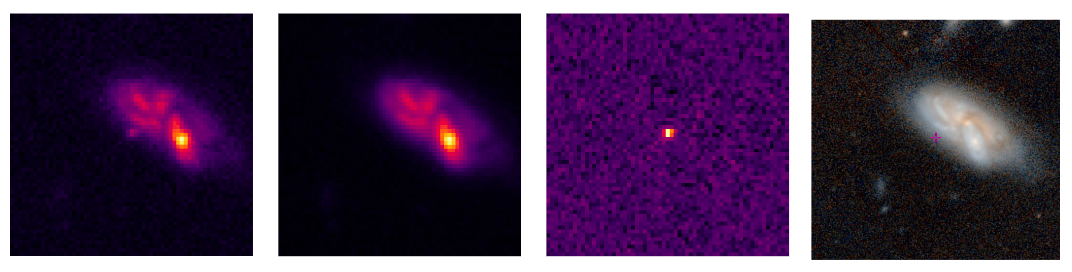
从左至右分别是科学图像、参照图像和差值图像:这三张图像加上其他的重要数据,如观测条件和有关物体的信息。第四张图像来自 PanSTARRS,经 Aladin Sky Atlas 上色。您可以在 ALeRCE 前端看到超新星的亮度在不同时间的完整变化过程
整理这些接收到警报是一项繁重的任务。当收到新的警报时,产生该警报的天体类型可能是未知的。因此,我们首先需确认是否已在其他观测中了解到这个天体(交叉匹配)。我们还需要确认是哪一种天体产生的警报(分类)。最后,我们需要整理数据并将其提供给社区。这项任务需要 ALeRCE、Lasair、Antares 等天文分类系统来完成。
由于这些警报基本上包含天空中发生的一切变化,因此我们应该能够在 ZTF 望远镜发出的所有警报中找到超新星。但问题在于,其他天体也会发出警报,例如会发生亮度变化的恒星(变星)、活动星系核 (AGN) 和小行星,而且有时也会出现测量误差(误报)。幸运的是,科学图像、参照图像和差值图像中的一些可区分特征,能够帮助我们确定警报来自超新星还是其他天体。我们需要有效地区分以下五类天体。
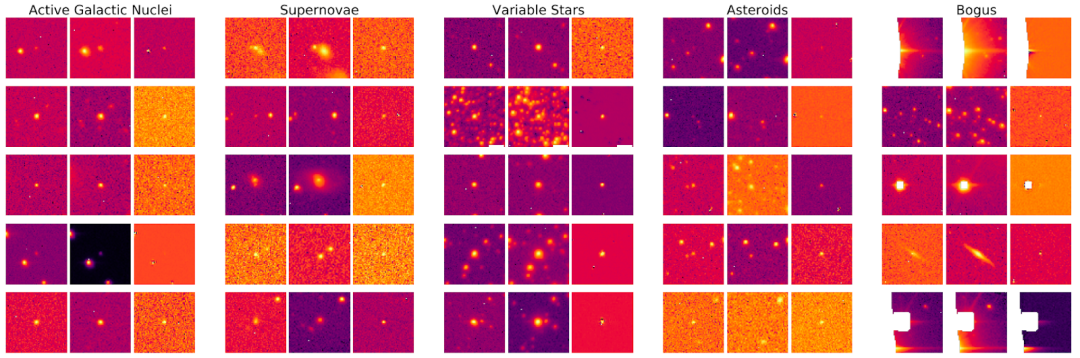
只需使用第一个警报就能区分这五类天体:这些分别是每一类天体的五个示例警报,每个警报都包含科学图像、参照图像和差值图像
简而言之,活动星系核往往出现在星系中心。超新星通常出现在宿主星系附近。我们会在太阳系平面附近观测到小行星,并且,它们不会出现在模板图像中。变星大多会在银河系中观测到,因此其图像中还可以看到其他恒星。出现误报的原因有很多种,包括相机中有坏的像素点、用于生成差值图像的减法出错、宇宙射线(警报图像中心非常明亮、密集且锐利的区域)等。
如上文所述,人们不可能手动检查每一个警报,所以我们需要一种自动分类的方法,这样天文学家就可以查看更有可能是超新星的最有意义的来源。
利用神经网络寻找超新星
由于我们已大致了解上述五类天体的警报图像之间的差异,因此原则上我们可以计算特定特征以正确对这些图像进行分类。但是,手动设计特征通常非常难,并且需要长时间的反复试验。正因如此,我们决定通过训练卷积神经网络 (CNN) 来解决分类问题(Carrasco-Davis 等人,2020 年)。在本研究中,我们仅使用第一个警报来快速找出超新星。
Carrasco-Davis 等人,2020 年
https://arxiv.org/abs/2008.03309
我们通过在训练集中加入每个图像旋转 90° 后的副本来提供具有旋转不变性的架构,然后对图像的每个旋转后版本的密集表示应用平均池化。在此问题上加上旋转不变性非常有用,因为警报图像中的结构没有固定的显示方向(Cabrera-Vives 等人,2017 年、E. Reyes 等人,2018 年)。我们还添加了警报中包含的部分元数据,例如,天空坐标上的位置、到其他已知物体的距离,以及大气状况指标等。在使用交叉熵训练模型后,即使出现分类器预测错类别的情况,分类结果的概率也高度集中在 0 或 1 附近。如果专家要在模型给出预测后,进一步筛选出超新星,那么这个方法就不太方便。饱和值 0 或 1 无法提供与模型错误分类的概率,以及做出的第二或第三可能的类别预测有关的数据分析。
Cabrera-Vives 等人,2017 年
https://doi.org/10.3847/1538-4357/836/1/97
E. Reyes 等人,2018 年
https://doi.org/10.1109/IJCNN.2018.8489627
因此,除损失函数中的交叉熵项之外,我们还添加了额外的项来尽可能地提高预测的熵,以分散输出概率的值(Pereyra 等人,2017 年)。此举改善了预测的细粒度或定义,模型输出的概率不再聚集,而是分散在 0 到 1 的整个范围内,因此模型做出的预测更易理解,进而能够帮助天文学家选择符合条件的超新星候选者进行报告跟进。
Pereyra 等人,2017 年
https://arxiv.org/abs/1701.06548
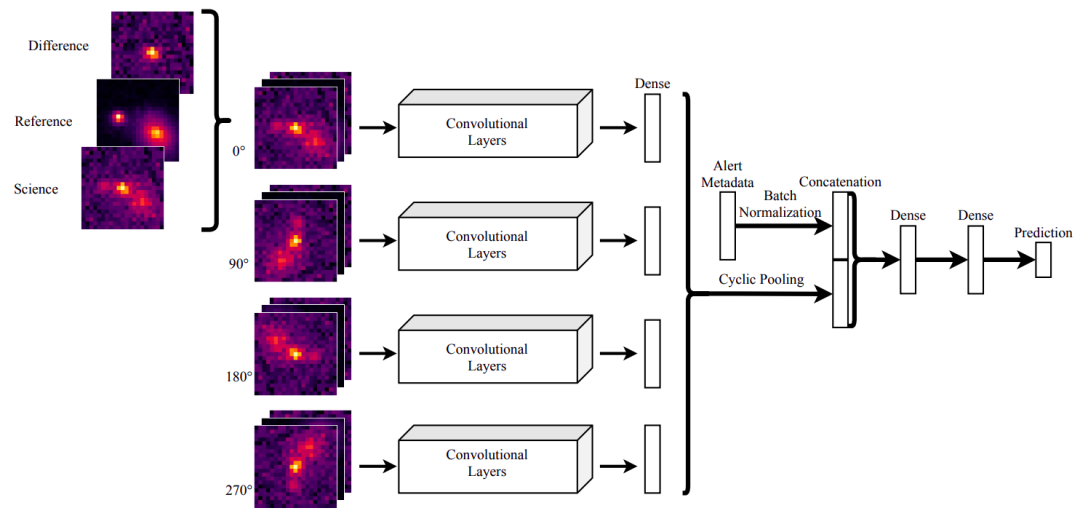
具有增强的旋转不变性的卷积神经网络:为每个输入图像创建旋转副本并将其馈送到相同的 CNN 架构,然后在将其与元数据串联之前,在密集层中应用平均池化。最后,应用另外两个完全连接的层和 softmax 以获得预测结果
我们对 ZTF 整个覆盖范围内均匀分布在太空中的 40 万个物体进行了推断,以对模型预测结果进行合理性检查。检查结果证明,CNN 预测的每个天体类别的空间分布均符合预期(基于每个天体的性质)。
例如,AGN 和超新星 (SNe) 大多会在银河平面之外(即河外天体)找到,因为有其他天体的遮挡,所以不太可能透过银河平面看到更远位置上的天体。模型正确预测了靠近银道面(银道纬度接近 0)的天体数量较少。在银道内正确发现了具有较高密度的变星。和预期的一样,在太阳系平面(也称为黄道,用黄线标出)附近发现了小行星,而误报也随处可见。在大型未标记数据集中进行推断,可为我们提供有关训练集内偏差的重要线索,还可帮助我们确定 CNN 所使用的重要元数据。
我们发现,虽然图像(科学图像、参照图像和差值图像)内的信息足以让我们在训练集中获得良好的分类结果,但是整合来自元数据的信息对获得预测结果的正确空间分布至关重要。
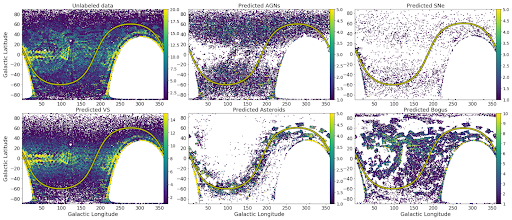
未标记天体集的空间分布:每张图均采用银道坐标。银道的纬度中心位于银河系,因此,维度接近 0 也意味着更接近银道面。银道经度表示我们在银道面内看到的是银盘的哪一部分。黄线表示太阳系平面(黄道)
Supernova Hunter
此项目的重要组成部分是网络界面,通过此界面,天文学家可浏览由我们的神经网络按照该候选者属于超新星的置信度排序的候选天体名单。Supernova Hunter 是一款可视化工具,可用于展示与警报相关的重要信息,天文学家可利用此工具选择应将哪些天体报告为超新星。此工具还设有一个按钮,可用来报告模型做出的错误分类。我们收到报告的错误分类后,会将其添加到训练集中,并会在稍后手动标记这些错误示例来改进模型。
Supernova Hunter
https://snhunter.alerce.online/
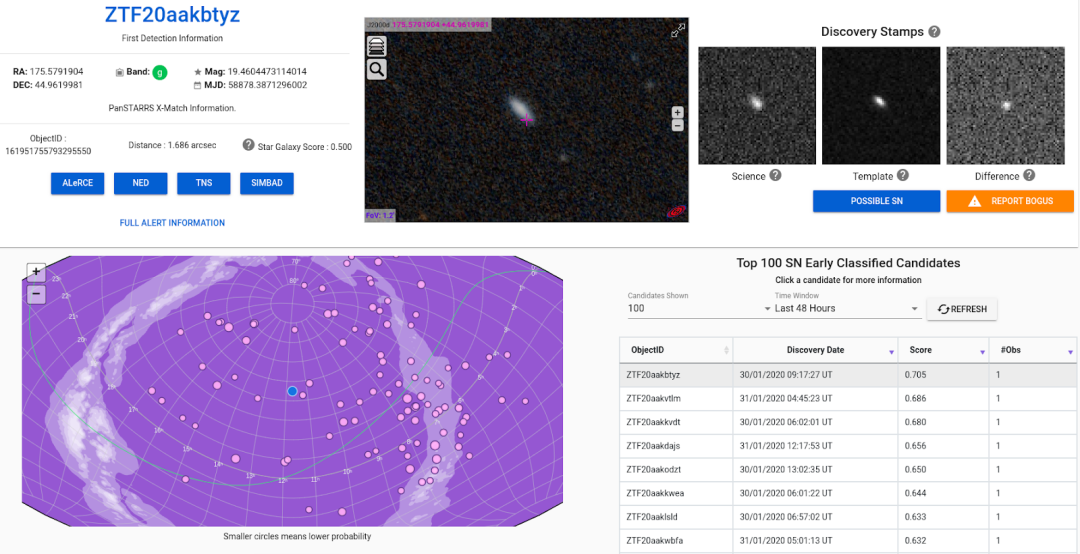
Supernova Hunter:浏览超新星候选者的用户界面。此界面显示一串警报列表,而这些警报有很大的可能性是超新星。对于每个警报,警报的图像、天体的位置和元数据均会显示在网页上
通过使用神经网络分类器和 Supernova Hunter,我们已利用光谱方法确认出 394 个超新星,并在 2019 年 6 月 26 日至 2020 年 7 月 21 日期间向 Transient Name Server 报告了 3060 个超新星候选者,平均每天报告 9.2 个。这样的发现速度可极大提高在爆炸早期找到的超新星数量。
展望未来
目前,我们正在努力改善模型的分类性能,以获得更符合条件的超新星候选者,并减少报告过程中所需的专家助手人数。理想情况下,我们希望拥有一个能够自动报告每个可能的超新星候选者的系统。
此外,我们还希望扩展我们模型的功能,让其能够使用多个时间戳。我们开发了一个神经网络模型,此模型能够接收一系列的图像而不是单个时间戳的图像,因此,每当特定物体有新图像可用时,此模型就能够整合新收取的信息,从而可以提高其对每个类别的预测结果的置信度。
使用多个时间戳
https://doi.org/10.1088/1538-3873/aaef12
我们研究工作的另一大重点是使用异常检测技术发现稀有物体。这项任务非常重要,因为得益于新型望远镜空前庞大的采样率和每次观测的空间深度,我们很可能能够发现新的天体类型。
我们认为这种分析大量天文数据的新方法不仅有用,而且很有必要。为科学界提供数据的管理、分类和再分发是利用天文数据进行科学研究的重要一环。这项任务需要整合来自不同领域的专业知识,例如计算机科学、天文学、工程学和数学。随着新型现代望远镜的建成(如薇拉·鲁宾天文台),势必会极大地改变天文学家研究天体的方式,而作为 ALeRCE 代理,我们将做好一切准备来实现这一点。如需了解详细信息,请访问我们的网站,或浏览我们的论文:ALeRCE 演示论文,文中描述了完整的处理流水线;时间戳分类器(本文中描述的研究项目);以及光曲线分类器,该分类器通过使用称为光曲线的时间序列,提供了更复杂的分类和更大的分类学。
责任编辑:lq
-
神经网络教程(李亚非)2012-03-20 0
-
神经网络简介2012-08-05 0
-
求利用LABVIEW 实现bp神经网络的程序2012-11-26 0
-
神经网络基本介绍2018-01-04 0
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 0
-
全连接神经网络和卷积神经网络有什么区别2019-06-06 0
-
卷积神经网络如何使用2019-07-17 0
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 0
-
如何设计BP神经网络图像压缩算法?2019-08-08 0
-
什么是LSTM神经网络2021-01-28 0
-
如何构建神经网络?2021-07-12 0
-
基于BP神经网络的PID控制2021-09-07 0
-
如何利用卷积神经网络去更好地控制巡线智能车呢2021-12-21 0
-
神经网络移植到STM32的方法2022-01-11 0
-
卷积神经网络模型发展及应用2022-08-02 0
全部0条评论

快来发表一下你的评论吧 !
