

半监督学习最基础的3个概念
描述
导读
今天给大家介绍半监督学习中的3个最基础的概念:一致性正则化,熵最小化和伪标签,并介绍了两个经典的半监督学习方法。
没看一的点这里哈:半监督学习入门基础(一)
半监督学习 (SSL) 是一种非常有趣的方法,用来解决机器学习中缺少标签数据的问题。SSL利用未标记的数据和标记的数据集来学习任务。SSL的目标是得到比单独使用标记数据训练的监督学习模型更好的结果。这是关于半监督学习的系列文章的第2部分,详细介绍了一些基本的SSL技术。
一致性正则化,熵最小化,伪标签
SSL的流行方法是在训练期间往典型的监督学习中添加一个新的损失项。通常使用三个概念来实现半监督学习,即一致性正则化、熵最小化和伪标签。在进一步讨论之前,让我们先理解这些概念。
一致性正则化强制数据点的实际扰动不应显著改变预测器的输出。简单地说,模型应该为输入及其实际扰动变量给出一致的输出。我们人类对于小的干扰是相当鲁棒的。例如,给图像添加小的噪声(例如改变一些像素值)对我们来说是察觉不到的。机器学习模型也应该对这种扰动具有鲁棒性。这通常通过最小化对原始输入的预测与对该输入的扰动版本的预测之间的差异来实现。
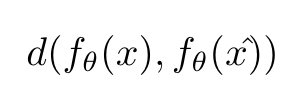
模型对输入x及其扰动x^的一致性度量
d(.,.) 可以是均方误差或KL散度或任何其他距离度量。
一致性正则化是利用未标记数据找到数据集所在的平滑流形的一种方法。这种方法的例子包括π模型、Temporal Ensembling,Mean Teacher,Virtual Adversarial Training等。
熵最小化鼓励对未标记数据进行更有信心的预测,即预测应该具有低熵,而与ground truth无关(因为ground truth对于未标记数据是未知的)。让我们从数学上理解下这个。
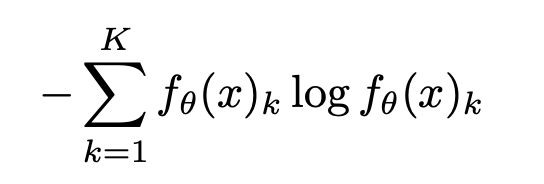
熵的计算
这里,K是类别的数量,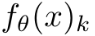 是模型对x预测是否属于类别k的置信度。
是模型对x预测是否属于类别k的置信度。
此外,输入示例中所有类的置信度之和应该为1。这意味着,当某个类的预测值接近1,而其他所有类的预测值接近0时,熵将最小化。因此,这个目标鼓励模型给出高可信度的预测。
理想情况下,熵的最小化将阻止决策边界通过附近的数据点,否则它将被迫产生一个低可信的预测。请参阅下图以更好地理解此概念。
由不同的半监督学习方法生成的决策边界
伪标签是实现半监督学习最简单的方法。一个模型一开始在有标记的数据集上进行训练,然后用来对没有标记的数据进行预测。它从未标记的数据集中选择那些具有高置信度(高于预定义的阈值)的样本,并将其预测视为伪标签。然后将这个伪标签数据集添加到标记数据集,然后在扩展的标记数据集上再次训练模型。这些步骤可以执行多次。这和自训练很相关。
在现实中视觉和语言上扰动的例子
视觉:
翻转,旋转,裁剪,镜像等是图像常用的扰动。
语言
反向翻译是语言中最常见的扰动方式。在这里,输入被翻译成不同的语言,然后再翻译成相同的语言。这样就获得了具有相同语义属性的新输入。
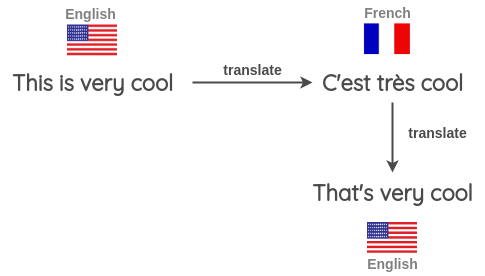
NLP中的反向翻译
半监督学习方法
π model:
这里的目标是一致性正则化。
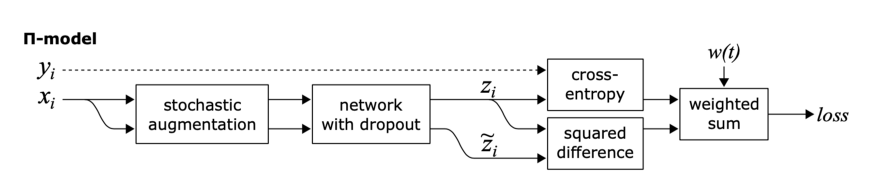
π模型鼓励模型对两个相同的输入(即同一个输入的两个扰动变量)输出之间的一致性。
π模型有几个缺点,首先,训练计算量大,因为每个epoch中单个输入需要送到网络中两次。第二,训练目标zĩ是有噪声的。
Temporal Ensembling:
这个方法的目标也是一致性正则化,但是实现方法有点不一样。
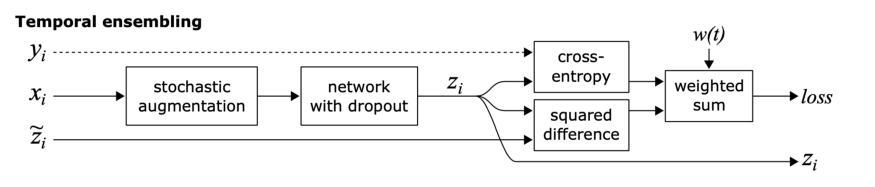
众所周知,与单一模型相比,模型集成通常能提供更好的预测。通过在训练期间使用单个模型在不同训练时期的输出来形成集成预测,这一思想得到了扩展。
简单来说,不是比较模型的相同输入的两个扰动的预测(如π模型),模型的预测与之前的epoch中模型对该输入的预测的加权平均进行比较。
这种方法克服了π模型的两个缺点。它在每个epoch中,单个输入只进入一次,而且训练目标zĩ 的噪声更小,因为会进行滑动平均。
这种方法的缺点是需要存储数据集中所有的zĩ 。
英文原文:https://medium.com/analytics-vidhya/a-primer-on-semi-supervised-learning-part-2-803f45edac2
责任编辑:xj
原文标题:半监督学习入门基础(二):最基础的3个概念
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
【阿里云大学免费精品课】机器学习入门:概念原理及常用算法2017-06-23 0
-
人工智能基本概念机器学习算法2021-09-06 0
-
基于半监督学习的跌倒检测系统设计_李仲年2017-03-19 827
-
基于半监督学习框架的识别算法2018-01-21 810
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 551
-
谷歌:半监督学习其实正在悄然的进化2019-05-25 2946
-
聚焦 | 新技术“红”不过十年?半监督学习却成例外?2019-06-18 2543
-
Google AI最新研究用无监督数据增强推进半监督学习,取得令人瞩目的成果2019-07-13 3554
-
机器学习算法中有监督和无监督学习的区别2020-07-07 5759
-
最基础的半监督学习2020-11-02 2650
-
为什么半监督学习是机器学习的未来?2020-11-27 3903
-
半监督学习:比监督学习做的更好2020-12-08 1409
-
机器学习中的无监督学习应用在哪些领域2022-01-20 4962
-
半监督学习代码库存在的问题与挑战2022-10-18 1293
-
跨解剖域自适应对比半监督学习方法解析2023-04-14 1306
全部0条评论

快来发表一下你的评论吧 !
