

一种无监督下利用多模态文档结构信息帮助图片-句子匹配的采样方法
描述
引 言
本文介绍了复旦大学数据智能与社会计算实验室 (Fudan DISC) 在AAAI 2021上录用的一篇关于多模态匹配的工作:An Unsupervised Sampling Approach for Image-Sentence Matching UsingDocument-Level Structural Information,提出了一种无监督设定下,更有效地利用多模态文档的共现结构信息帮助采样完成句子-图片匹配的方法。本文的合作单位是杭州之江实验室。
文章摘要
文章针对无监督的句子图片匹配任务。现存的方法主要通过利用多模态文档的图片句子共现信息来无监督地采样正负样本对,但是其在获得负样本时只考虑了跨文档的图片句子对,在一定程度上引入了采样的偏差,使得模型无法分辨同一文档内语义较为近似的图片和句子。
在本文中,我们提出了一种新的采样的方法,通过引入同一文档内的图片句子对作为额外的正负样本来减小采样的偏差;进一步,我们提出了一个基于Transformer的模型来识别更为复杂的语义关联,该模型为每个多模态文档隐式地构建了一个图的结构,构建了同一篇文档内句子和图片的表征学习间的桥梁。实验的结果证明了我们提出的方法有效的减小偏差并且进一步获得了更好的跨模态表征。
研究背景
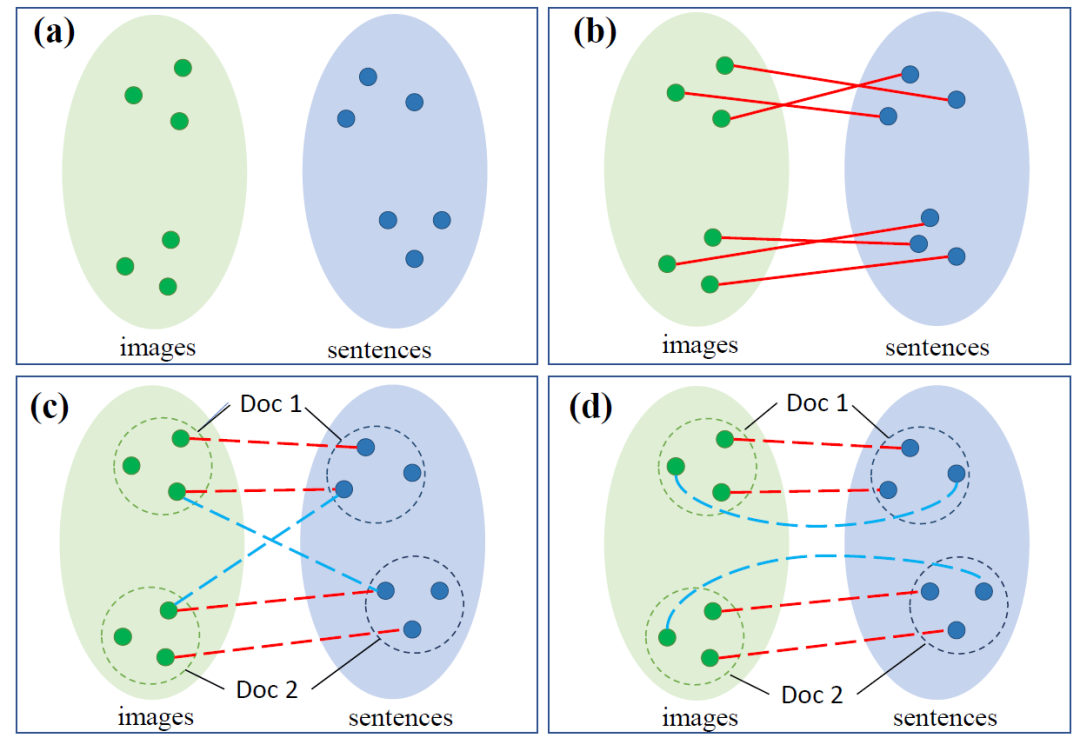
图1. 句子-图片匹配任务说明
(绿色/蓝色点代表图片/句子,红色实线代表匹配关系的标签,红色/蓝色虚线代表无监督方法选出的(伪)正/负样本对)
图片-句子的匹配一直是跨模态领域的基础任务,其根本的目的是对其视觉和文本的语义空间。如(a)所示,两个模态之间本身存在着语义空间上的差异,对其的常见方法是通过有监督的标签拉近匹配的样本对,如(b)所示。在无监督的环境下,最大的挑战即为如何选择出想要拉近的正样本对和远离的负样本对。
如(c)所示,最近的无监督的方法通过文档的图片句子共现信息,通过拉近句子集合和图片集合的方式来进行训练,其中,同文档内语义近似的句子-图片对被看作正样本,而跨文档间的句子-图片对被看作负样本,如(c)所示,这样的方法没有考虑到文档内部语义相似度更高的负样本,其选出的负样本与真实的负样本分布存在着偏差。
于是本文提出了新的采样策略,如(d)所示,我们引入了更多同一文档内部的正负样本对来帮助训练。进一步,为了更好地识别同一文档内更加复杂的句子图片语义匹配模式,我们考虑使用更加细粒度的表征学习方法,提出了一个新的基于Transformer的模型,在其中为每个文档的句子图片间隐性建模了一个图,来帮助获得更好的跨模态表征。
方法描述
采样方法
本文的方法基于三个部分的采样,通过3个训练目标实现,如图2所示。
图2. 三个部分的采样和训练目标示意
第一个部分为之前的工作提出的跨文档训练目标(cross-document objective)。其假设为同一文档内的句子集合和图片集合间的相似度要整体高于来自两个不同文档的句子集合和图片集合间的相似度,背后通过一定的方式来选出几个句子图片对之间的相似度来代表句子集合和图片集合间的相似度。其采样得到的正样本为来自同一文档的语义较为近似的句子-图片对;负样本为来自不同文档的语义较为近似的图片句子对。
第二个部分为文档内部的训练目标(intra-document objective)。其假设为同一篇文档内部的语义近似的图片句子对之间的相似度也要高于内部语义相差较远的图片句子对间的相似度,高于一定的值,在此目标下采样出的正样本为来自同一文档的语义较为近似的句子-图片对;负样本为来自同一文档的语义相差较远的图片句子对。
第三个部分为次跨文档训练目标(dropout sub-document objective)。其假设为即使一篇文档我们将其随机的遮盖住部分的句子/图片,剩下的残缺文档内的句子集合和图片集合间的相似度也要高于跨文档间的图片集合-句子集合间的相似度。在此目标下采样出的正样本为来自同一“残次”文档的语义较为近似的句子-图片对;负样本为来自不同文档的语义近似的图片句子对。
跨模态表征模型
图3. 总的模型结构示意
由于引入了更多的同一文档内的图片句子对,我们需要得到包含更细粒度信息的多模态表征,所以我们将图片分割为区域,将句子分割为token,Transformer可以看作是带有attention机制的图网络,我们通过两个视觉/文本的Transformer对各模态内的(区域/token)节点进行编码,与此同时我们引入了视觉的概念,这里我们将图片区域预测出的标签作为图片包括的概念,将它们作为中间的桥梁将两个模态的图桥接起来。概念会直接加入到视觉的图中,作为节点存在,而概念和文本端的关系通过共享的embedding层来实现。这样的模型里,当句子里直接提到了区域里对应的概念时,我们的模型就能很快地捕捉到这样的匹配关系。
实验
我们在无监督的多句子多图片文档内的跨模态链接预测任务上进行了实验,其中包括了基于MSCOCO, VIST构建出的三个文档数据集。对于每一个文档,其内部有多个句子和多个图片,需要去预测其中句子和图片间是否存在着链接的边(匹配关系),使用AUC/P@1/P@5进行评估。相较于之前只使用cross-document objective的方法(表内MulLink),我们的方法有了明显的提高。
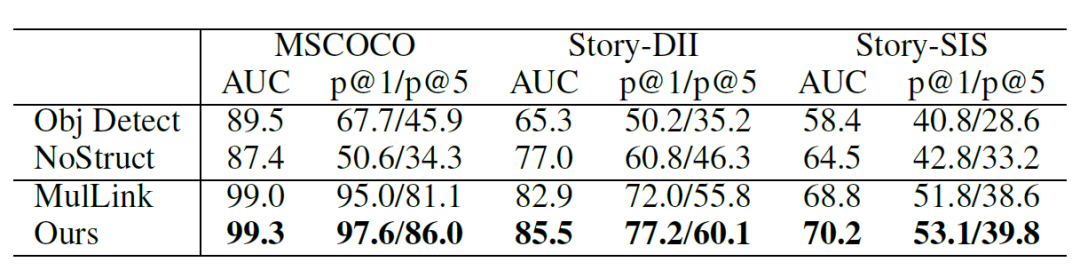
表1. 总的实验结果
同时我们对我们提出的模型的结构,和三个部分的训练目标进行了消融实验:
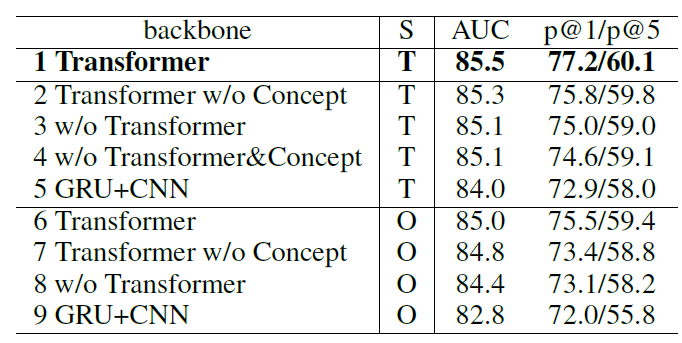
表2. 部分消融实验的结果
(S列代表采样方法,T代表同时使用三种目标训练,O代表只使用跨文档训练目标,w/o代表without,w/o Transformer的方法里我们使用GRU对句子进行表征,对图片的各个区域进行softmax pooling进行表征。)
可以看到整体上同时使用三种目标可以采样到更多的信息,帮助训练,我们也对三个目标进行了更加细致的消融实验,详情可以参考原文。同时我们提出的模型更好地利用了细粒度的信息,也获得了更好地跨模态表征。
同时,我们进行了有监督、无监督和迁移学习的比较。有监督的方法直接使用文档内的匹配的图片句子对作为训练,如图4,迁移学习则尝试迁移从MSCOCO上进行有监督训练的信息到DII测试集上,如表3。
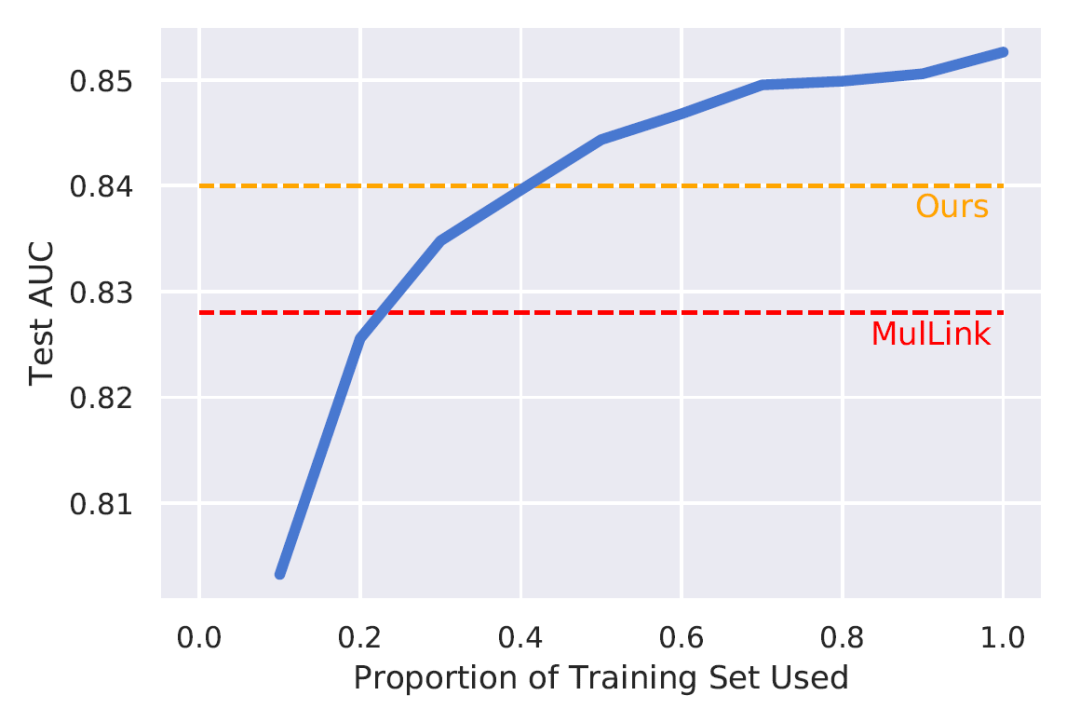
图4. 有监督-无监督比较
蓝色代表有监督学习下,随着使用的数据增加在测试集上的表现

表3. 迁移学习和无监督学习的比较
可以看到相较于只使用跨文档训练目标,同时使用三种目标得到的更多样本对里包括了更多的信息,我们无监督的方法可以利用训练集内更多的信息(~40%),相较于迁移自其他数据集的信息,也更加有效。
除此之外,我们通过错误分析的方法验证我们的方法对于偏差的修正效果。该偏差的表现为同一文档内的句子和图片更加近似,跨文档内的图片和句子差异更大,所以我们使用文档内的句子/图片表征的发散程度来代表这个差异,同一文档内越发散,训练和测试之间的差异越小。在DII上,我们使用每个文档内句子/图片的发散程度来拟合该文档链接预测的AUC,原来的方法得到的线性模型的R方为42%,也就是说差异能很大程度解释错误的原因,而我们的方法得到的R方为23%,这意味着该差异对于结果的作用减弱了,加上我们模型整体上更好地表现,我们可以认为我们减弱了采样的偏差,使得偏差引起的错误减少了。
结论
在本文里,我们对于无监督的句子-图片匹配任务,针对之前方法存在的采样偏差问题提出了新的采样策略,希望更高效地利用多模态文档内句子和图片共现的结构信息,引入了更多的来自同一文档内的正/负图片-句子对。同时提出了可以利用更细粒度信息的模型,建立了跨模态表征学习的关系桥梁。最终的实验证明了我们方法的有效性。
责任编辑:xj
原文标题:【Fudan DISC】一种无监督下利用多模态文档结构信息帮助图片-句子匹配的采样方法
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
分享一种利用stm32 OLED显示一张图片的方法2022-01-21 0
-
基于自适应并行结构的多模态生物特征识别2012-11-09 774
-
一种基于极坐标变换的点模式匹配算法2017-12-05 734
-
一种多属性匹配决策方法2017-12-14 895
-
基于远距离监督和模式匹配的属性抽取方法2017-12-23 1151
-
基于信息元的模式匹配方法2018-01-23 921
-
一种自监督同变注意力机制,利用自监督方法来弥补监督信号差异2020-05-12 7830
-
基于布谷鸟搜索算法与多目标函数的多文档摘要方法2021-03-30 652
-
一种上下文感知与层级注意力网络的文档分类方法2021-04-02 627
-
一种基于光滑表示的半监督分类算法2021-04-08 608
-
联合多流行结构和自表示的无监督特征选择方法2021-04-28 603
-
一种有效的无监督深度表示器(Mix2Vec)2022-03-24 1647
-
一种简单而有效的转换方法来降低预测情感标签的难度2022-09-20 1113
-
一种利用几何信息的自监督单目深度估计框架2023-11-06 431
-
大模型+多模态的3种实现方法2023-12-13 1702
全部0条评论

快来发表一下你的评论吧 !
