

全球人工智能技术创新大赛短文本语义匹配方案技巧
描述
好久不打比赛,周末看到“全球人工智能技术创新大赛”已经开打了一段时间,前排分数冲的有点凶,技痒的我看到了一道熟悉的赛题——小布助手对话短文本语义匹配,由于在搜索推荐系统的一些任重中,文本语义匹配子任务也是经常会遇到的一个问题,于是乎掏出那根...咳咳..沉睡了很久的GPU,翻出了祖传代码,跑了一波Baseline...
赛题题型不新鲜,在Baseline的的基础上参考了一些思路做些炼丹技巧上的操作,3次提交之后顺利冲进排行榜英国威廉希尔公司网站 。针对短文本语义匹配,本文帮大家梳理一波方案技巧。
P.S. 发稿之前,看了一眼排行榜,分数已经被大家刷上去了,参加人数还蛮多,有兴趣的同学可以去战一波...
赛题背景
意图识别是对话系统中的一个核心任务,而对话短文本语义匹配是意图识别的主流算法方案之一。本赛题要求参赛队伍根据脱敏后的短文本query-pair,预测它们是否属于同一语义,提交的结果按照指定的评价指标使用在线评测数据进行评测和排名,得分最优者获胜。
数据及评估指标
数据
训练数据包含输入query-pair,以及对应的真值。初赛训练样本10万,复赛训练样本30万,这份数据主要用于参赛队伍训练模型,为确保数据的高质量,每一个样本的真值都有进行人工标注校验。每行为一个训练样本,由query-pair和真值组成,每行格式如下:
query-pair格式:query以中文为主,中间可能带有少量英文单词(如英文缩写、品牌词、设备型号等),采用UTF-8编码,未分词,两个query之间使用 分割。
真值:真值可为0或1,其中1代表query-pair语义相匹配,0则代表不匹配,真值与query-pair之间也用 分割。
评估标准
比赛的评估标准由性能标准和效果标准两部分组成,初赛采用效果标准,AUC 指标,具体定义如下:
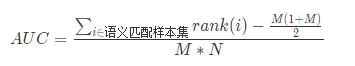
其中:
rank(i):表示i这个样本的预测得分在测试集中的排序;
M:测试集中语义匹配的样本的个数;
N:测试集中语义不匹配的样本的个数。
解决方案与技巧
在BERT横行的时代,解决方案大同小异,直接梭哈BERT的性价比是很高的,当所有人都会使用这套操作时,你又该怎么办呢?首先针对此类问题,分享一波炼丹小技巧。由于本赛题开赛前,将文本替换成了加密形式,有些技巧可能无法使用,但不影响学习。
数据增强
1. 标签传递
根据IF A=B and A =C THEN B=C 的规则,对正样本做了扩充增强。
根据IF A=B and A!=C THEN B!=C的规则,对负样本做了扩充增强。
2. 随机删除,随机替换, 随机交换
Query比较短,大约有10-20个字的长度,随机删除部分。
很多query仅仅相差一个单词, 随机替换部分。
多数属于问句, 随机交换部分。
3. 同义词替换
建模思路
第一个Baseline我沿用了之前计算相似度的方式对问题就行了求解,也做了模型线上的第一次提交,线上0.88的水平。具体思路如下:
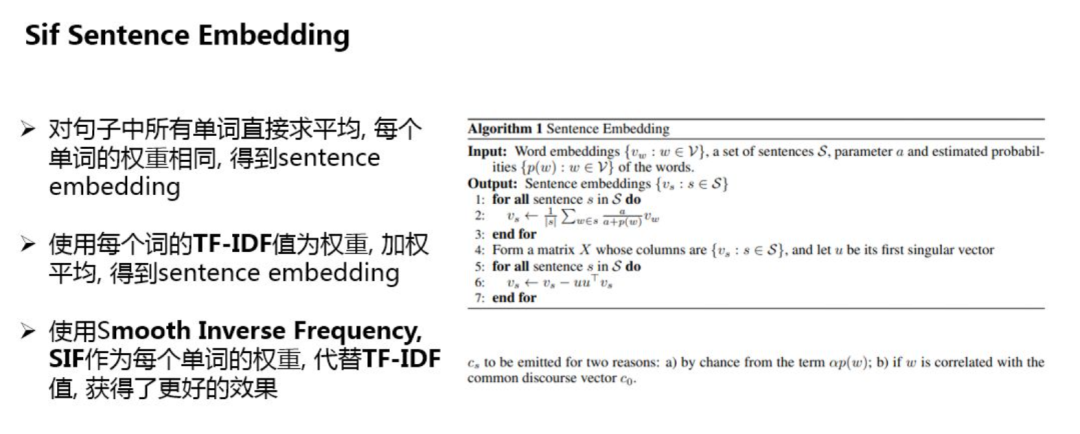
1. SIF Sentence Embedding
SIF Sentence Embedding 使用预训练好的词向量,使用加权平均的方法,对句子中所有词对应的词向量进行计算,得到整个句子的embedding向量。
SIF的计算分为两步:
对句子中的每个词向量,乘以一个独特的权重b,权重b是一个常数 a除以a与该词频率的和,这种做法的会对出现频率高词进行降权,也就是说出现频次越高,其权重也就越小;
计算句向量矩阵的第一主成分u,让每个Sentence Embedding减去它在u上的投影;
这里,利用该方法做召回,在验证集上的准确性要比其他两种方式效果好。
对句子中所有单词求平均得到sentence embedding;
对句子中所有单词利用IDF值加权后求平均得到sentence embedding。
2. InferSent
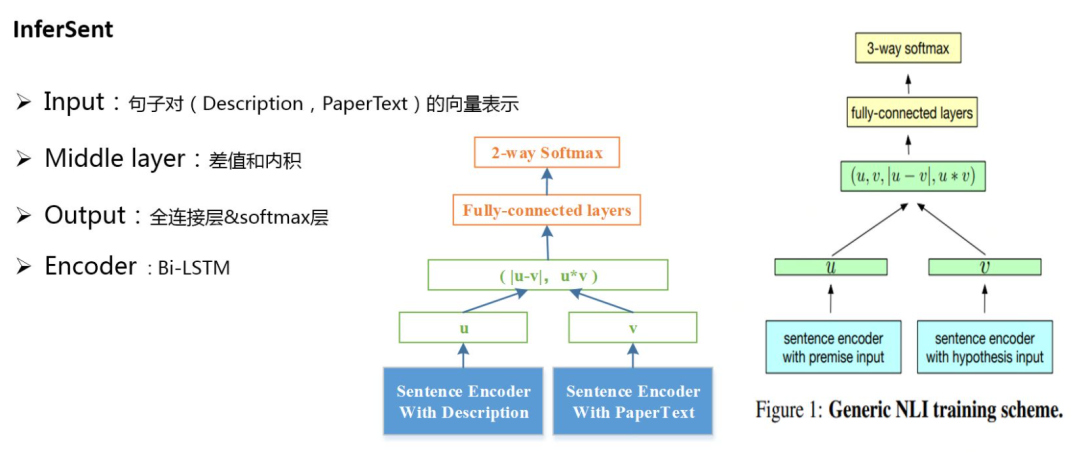
InferSent相似度模型是Facebook提出了一种通过不同的encoder得到Sentence Embedding,然后计算两个Sentence Embedding的差值、点乘得到交互向量,计算两者之间的相似度。
这里,对原始论文方法做了两处修改:其一是针对这个问题对3-way softmax层(entailment,contradiction,neutral)做了相应的修改变为2-way softmax;其二是中间层去掉了u和v,只使用差值和内积两种特征表征方式;同时在7中编码器:1)LSTM, 2)GRU, 3)bi-GRU, 4)bi-LSTM(mean pooling), 5)bi-LSTM(max pooling), 6)self-attention, 7)CNN 中选用了Bi-LSTM MaxPooling的方式。
开源方案
本赛题苏剑林开源了一套方案,这套方案让脱敏数据,也能使用BERT。脱敏数据对于BERT来说,其实就是Embedding层不一样而已,其他层还是很有价值的。所以重用BERT主要还是通过预训练重新对齐Embedding层。
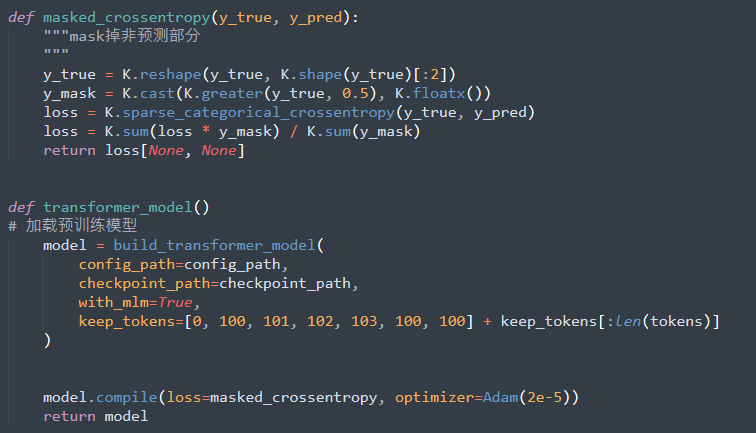
在这个过程中,初始化很重要。首先,我们把BERT的Embedding层中的[UNK]、[CLS]、[SEP]等特殊标记拿出来,这部分不变;然后,我们分别统计密文数据和明文数据的字频,明文数据指的是任意的开源通用语料,不一定要密文数据对应的明文数据;接着按照频率简单对齐明文字表和密文字表。这样一来,我们就可以按照明文的字来取出BERT的Embedding层来作为相应的初始化。
简单来说,就是苏剑林用最高频的明文字对应的BERT Embedding,来初始化最高频的密文字,依此类推来做一个基本的字表对齐。对比实验表明,这个操作可以明显加快模型的收敛速度。
我的第2次提交是对该方案增加了FGM部分进行了提交测试,因为FGM带了百一的得分收益,线上0.87+的水平,跟苏兄开源时公布的0.86+得分相对一致。
FGM对抗训练
上面提到了FGM的对抗训练,其实也算是一个炼丹小技巧,这里做一下见到介绍。
对抗训练(Adversarial Training),顾名思义,就是在训练过程中产生一些攻击样本,早期是FGSM和I-FGSM攻击,目前当前最优的攻击手段是PGD。对抗训练,相当于是加了一层正则化,给神经网络的随机梯度优化限制了一个李普希茨的约束。
传统上认为,这个训练方式会牺牲掉一定的测试精度,因为卷积模型关注局部特性,会学到一些敏感于扰动的特征,对抗训练是一种去伪存真的过程,这是目前像素识别的视觉算法的局限性。这里苏建林在kexue.fm里实现是很简单的,详情参看引用链接。
总结
最后,第3次提交将前两次的提交的结果,做了一个简单的线性融合,线上到了当时排行榜的英国威廉希尔公司网站 ,Ensemble的方式其实很多,由于时间的关系并没去堆很多模型,对此感兴趣的同学,可以去看一下《Kaggle竞赛宝典》的系列文章。
比赛结束还有一段时间,感兴趣的同学可以去尝试一波。数据竞赛作为一种保持竞技状态(战斗状态)的一种方式,在工作中直接应用的层面的可能很少,但是它能带给选手的更多是一种对问题的深层次思考,一种解决问题的实战训练能力,如果你有时间,不妨一试。这次全球人工智能技术创新大赛是清华大学刘强老师负责跟的,刘老师的负责态度和对选手的正面鼓励,我想很多接触过的人都会印象深刻。哈哈哈,依稀的记得2017年首次参赛,刘老师送的清华大学百年纪念邮票。
工作之后,时间会过很快,考虑更多的可能是做一件事是否能有结果,考虑的事情多了,也就没有了当年肝肝肝的勇气。偶尔回到赛场提醒一下自己,怀念一下过去....ALL in BERT,便是这份高效利用自己时间的体现,简单、有效、奥卡姆剃刀...
原文标题:【比赛经验】ALL in BERT:一套操作冲进排行榜英国威廉希尔公司网站
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
- 相关推荐
- 人工智能
-
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得2024-10-14 0
-
人工智能是什么?2015-09-16 0
-
人工智能技术—AI2015-10-21 0
-
人工智能技术及算法设计指南2019-02-12 0
-
2019年人工智能技术峰会落幕,大咖演讲PPT火热出炉!2019-07-02 0
-
新一代人工智能领域十大最具成长性技术展望具体有哪些?2019-09-11 0
-
中国大学生服务外包创新创业大赛-基于FPGA的车牌识别应用系统”赛题2021-01-07 0
-
AI全球格局之人工智能即将变革的三大领域 相关资料分享2021-07-06 0
-
路径规划用到的人工智能技术2021-07-20 0
-
目前人工智能教育研究最深入最经典的白皮书:德勤《全球人工智能发展白皮书2019》精选资料分享2021-07-27 0
-
嵌入式人工智能技术是什么?2021-12-27 0
-
【开源硬件系列04期】AI人工智能技术带给EDA的机遇和挑战(文中含回放+课件)2023-01-17 0
-
轮胎配方研发怎样用得上人工智能技术2019-11-25 961
-
面向搜索的微博短文本语义建模方法综述2021-06-24 594
-
深度学习—基于军事知识图谱的作战预案语义匹配方法研究2021-11-11 1729
全部0条评论

快来发表一下你的评论吧 !
