

一款基于ESP32的对讲机传输音频介绍
描述
这是一款基于ESP32的对讲机。它使用UDP广播或ESP-NOW传输音频。

硬件部件
Adafruit I2S 3W D类放大器突破-MAX98357A × 1个
I2S MEMS麦克风突破无聊× 1个
通用4ohm或8ohm扬声器 × 1个
通用ESP32开发板× 1个
按钮开关(可选)× 1个
描述
我们使用ESP32制作了一个Walkie-Talkie。音频数据通过UDP广播或ESP-NOW传输。因此,对讲机甚至可以在没有WiFi网络的情况下工作!我以I2S麦克风和I2S放大器为基础-只需稍作改动,它就可以与模拟麦克风和头戴式耳机同样工作。
细节
下方录像带,概述了该项目详情。
您可以在以下位置访问Fusion360项目:https ://a360.co/2PXgAUS-因此,如果需要,可以随时打印自己的版本。
对于视频中的麦克风,我使用的是我自己的ICS-43434麦克风板,但它可以与INMP441麦克风板同样良好地工作。
这两个都是直接与ESP32交互的I2S麦克风。
I2S 3W放大器板来自Adafruit,并为扬声器供电。这也直接与ESP32交互。对于ESP32开发板,我使用的是TinyPICO,但是可以使用任何通用开发板,因为我们在此项目中未使用任何特殊功能。
我使用的是定制PCB-(由PCBWay的优秀人才制作),与往常一样,他们做得很好,而且我对这些板的外观感到非常满意。我有很多音频项目,能够将所有东西连接在一起而不用担心电线到处都是很好,这真是太好了。我所做的仅有的一点遗漏是不会断开其余的GPIO引脚-因此,我认为我将尽快开发该板的版本2。

这是指向EasyEDA上的原理图和PCB 的链接,如果需要,可以直接从PCBWay订购该板的链接。
话虽如此,您实际上不需要PCB,您可以轻松地将所有东西连接到面包板上,而这正是我制作原型时所做的。

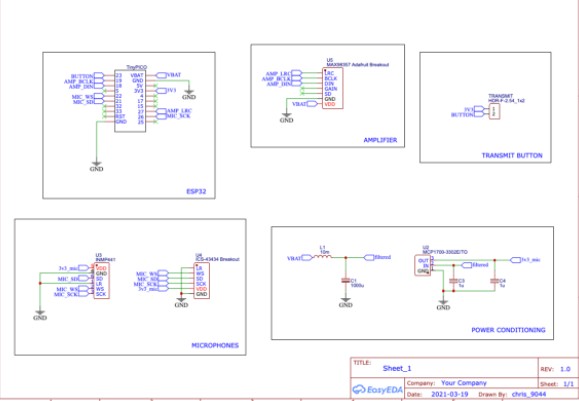
原理图非常简单-麦克风和扬声器都使用I2S板,这使它们与ESP32的接线非常简单。
当然,您可以修改代码以将内置ADC用于输入,将内置DAC用于输出。如果要使用模拟麦克风板和耳机插孔进行输出,则非常方便。
我在板上添加了一些额外的威廉希尔官方网站 ,以为麦克风创建干净的电源。如果您观看了我以前的一些视频,那么您会想起来,使用WiFi时,我们在麦克风上会听到很多噪音。
为解决此噪声问题,我们通过从电池直接馈电为麦克风创建干净的3.3v电源,我们使用LC滤波器对其进行滤波,然后将其传递至低压降稳压器。这为我们提供了一个非常好的,干净的麦克风电源,从而消除了很多噪音问题。
所有的代码都在GitHub上-它应该是不言自明的,但是我将在这里给出高层次的概述。
这个项目的主要挑战是如何将音频从一个对讲机广播到所有其他对讲机。
我已经以两种不同的方式实现了这一点。您可以使用简单的哈希定义轻松地在代码之间切换。
第一种方法是使用UDP广播。UDP广播是一种非常简单的机制。您将UDP数据包发送到一个特殊的IP地址,并且您的路由器将该数据包广播到网络上的所有其他设备。
我们可以安全地在UDP数据包中发送多达1436个字节,因此,如果我们以16KHz采样并使用大约90ms音频数据的8位采样。因此,我们需要每秒发送大约11个数据包。这完全在ESP32的功能范围内。
使用广播UDP的最大优点是,我们不需要了解对等方,我们只需广播一条消息,任何正在监听它的人都会收到它。我们也不需要所有都连接到的集中式服务器。所有繁重的工作都由路由器完成。
但是,我们应该意识到UDP的一些缺点:
UDP数据包的传递仅是最大的努力-无法保证有人会收到您发送的数据包。
也无法保证数据包的顺序-有人可能会完全随机地接收您发送的数据包。
对于这个项目,我选择忽略这两个问题。对于广播数据包,我们通常会停留在同一网络中,因此我们可能不会丢失太多数据包,并且我们的数据包也可能会以正确的顺序出现。如果他们不这样做,那么我们只会在音频上产生一点噪音和失真。
UDP广播的另一个主要优点是您可以在台式计算机或电话上接收数据包-因此创建不基于ESP32的其他客户端非常容易。
我实现传输的第二种方法是使用ESP-NOW。ESP-NOW是Esppresif开发的协议,它使多个ESP设备无需WiFi即可相互通信。
这给我们提供了一个比UDP选项更大的优势,因为我们不需要WiFi网络就可以使Walkie-Talkie正常工作。ESP-NOW的缺点是它具有250字节的小得多的数据包大小。这意味着我们需要每秒发送64次数据包。我们还具有与UDP相同的缺点-尽最大努力发送数据包,并且不能保证数据包将以什么顺序到达。
但是,在我的测试中,它的表现还算不错。运输问题解决后,我们只需要挂接所有物品即可。我们有I2S输入-它从麦克风读取样本并将它们传递到我们的运输工具。一旦传输积累了足够的数据以填充数据包,它将通过UDP或ESP-NOW发送数据。
另一方面,我们有相同的传输监听数据包。每次接收到数据包时,它都会通过我们的I2S输出将数据排队等待播放。I2S输出只是将采样输出到I2S放大器。
为了允许数据包花费更长的时间到达,我们在传输和I2S输出之间有一个缓冲区。在开始播放样本之前,我们花了少量时间-这给了我们一些空闲时间以允许数据包抖动。确实要付出一些音频延迟的代价-考虑到所有因素,音频在制作后大约半秒钟就会播放。
总而言之,尽管该项目可行。质量并不令人惊奇,但是对于一个业余项目来说肯定足够了。
与往常一样,代码全部在GitHub上。让我知道您在评论中的想法。如果您有任何改进,请打开请求。
可以看一下的一些想法:
压缩音频以减少带宽。
自动增益控制
消除回声
如上分享可能还有很多不完善,请随时留言交流~
附:
源代码:https://github.com/atomic14/esp32-walkie-talkie
原理图:
责任编辑:pj
-
使用ESP-32的内置ADC采集对讲机的音频,有严重干扰怎么解决?2024-06-28 0
-
对讲机模块/对讲机方案/对讲机2012-09-08 0
-
分享一款不错的多功能对讲机通信系统设计方案2021-05-20 0
-
构建一个基于ESP32的对讲机2022-07-15 0
-
[图文]一款对讲机威廉希尔官方网站2006-04-15 1875
-
如何选购对讲机?2010-02-07 4686
-
谈谈对讲机耳机的类别2010-02-08 2566
-
警用无线对讲机介绍2010-02-08 3616
-
对讲机是怎么分类的_对讲机分类大全_对讲机的工作原理介绍2018-01-15 15282
-
新买的对讲机怎么用_怎么知道对讲机的频率_对讲机频率设置2018-01-15 81608
-
什么是全国对讲机_全国对讲机的原理_全国对讲机怎么用2018-01-15 52180
-
防爆对讲机与普通对讲机如何区别?2018-09-03 13254
-
ESP32对讲机音频板2022-07-18 812
-
ESP32业余无线电板可实现语音和数据通信2022-08-17 2871
-
在ESP32上传输您的音频2022-12-09 1865
全部0条评论

快来发表一下你的评论吧 !
