

开发加速程序前如何正确设计程序架构?
电子说
描述
在开发一个加速程序的之前,有一个很重要的步骤:正确设计程序架构。开发人员需要明确软件应用程序中哪一部分是需要硬件加速的,并且它多少的并行量,以保证硬件加速器件(FPGA)能完美发挥其作用。
本文将分为5个步骤来介绍:
1. 基准和建立目标
2. 确定加速部分
3. 确定FPGA硬件加速并行量
4. 确定软件部分并行量
5. 微调架构细节。
1.
基准和建立目标
首先要测试应用程序的运行时间和吞吐量,来确定当前应用程序在现有平台的的基准性能。这些数据应涵盖整个应用程序(起始到结束)的性能和各个主要函数的性能。通常使用valgrind,callgrind和GNU gprof这些测试软件来获得应用程序的性能数据,它们会显示应用程序中所有的函数数量以及各个函数的执行时间。通过这些数据,我们可以找到耗时最长的部分,然后放到FPGA上进行加速。
评估运行时间
测试运行时间是软件开发的基本流程,可以使用一些常用的测试软件,或者插入计时器和性能计数器来完成此项操作。
评估吞吐量
这里的吞吐量是指数据被处理的速率。对于计算给定函数的吞吐量,具体公式为函数处理的数据除以函数处理的时间,如下:
TSW= max (VINPUT, VOUTPUT) / Running Time
如果是处理固定的数据量,只要简单的检查代码就能知道吞吐量的大小。但在一些情况下,数据是可变的,那么插入计数器来测量吞吐量的大小是比较实用的。
确定最大可实现的吞吐量
在大多数加速系统中,最大可实现吞吐量受PCIe总线的限制。PCIe总线受很多因素的影响,例如母板,驱动,目标板卡和发送数据大小等等。运行DMA测试能够测试PCIe发送的有效吞吐量,从而确定加速性能潜力的上限。在安装Alveo板卡后,我们可以使用xbutil dmatest命令来测试板卡的PCIe性能。
建立总体加速目标
在开发过程中尽早确定加速目标是非常有必要的,基于基准性能的加速目标会决定分析和决策的走向。加速目标可以是硬性的也可以是软性的。例如,实时视频应用程序有每秒处理60帧的严格硬性目标,而数据科学应用程序的软性目标是比其他可代替实现方法快10倍。所以无论哪种方式,领域专业知识对于设置可实现的加速目标都很重要。
2.
确定加速部分
评估基准性能后,下一步就是确定哪一个函数需要在FPGA上加速。当选择哪个函数用于加速时,有两个方面需要考虑到:
性能瓶颈:应用程序中有哪些函数需要着重关注
加速潜力:这些函数是否有加速的潜力
确定性能瓶颈
在一个纯粹的顺序进行的应用程序中,可以通过解析报告很容易甄别到性能瓶颈。然而,大多数现实中的应用程序都是多进程,因此在寻找性能瓶颈的时候考虑并行性很重要。一个很简单的例子:
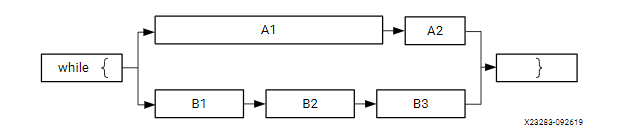
如上图中是一个应用程序中两条并行的路径,长度表示它们运行消耗时间。从这里我们看出,仅仅加速A,B进程的某一个并不能提高应用程序的整体性能。即使你将A2加速100倍,该应用程序的性能还是被A1和B进程钳制。所以考虑加速对象时,要考虑整个应用程序的性能,而不是单个函数的性能。
确定加速潜力
作为软件程序中的瓶颈函数不一定具有加速的潜力,通常需要进行详细分析才能准确判断给定函数的实际加速潜力。但是,有时候一些简单的指导方法也能确定一个函数是否有加速潜力:
1. 选择运算复杂度比较大的,相比于顺序计算来说,它可以在FPGA上可以使用并行,流水线来提高效率。
2. 相对于输入输出来说的,选择运算强度比较大的,因为这样数据搬移时间开销占用整个加速时间比率来说会低一些。
3. 选择那些能够数据重用,对内存访问比较少的,因为这可以是数据更容易在加速器中缓存,减少对全局内存的访问。
4. 对比函数吞吐量和FPGA吞吐量的比值,以确定最大可加速的倍数。
3.
确定FPGA硬件加速并行量
在前面的步骤中确定哪个函数用于加速之后,接下来就要确定使用多少的并行量来达到这一目标。内核(kernel)的并行性可以分为大致两种,一种是流水线形式,即是输入和处理数据同时进行;另一种是同时处理多个任务,即是拥有多个输入,多个任务并行处理。
评估硬件吞吐量(非并行)
没有进行并行化的内核(kernel)吞吐量可以近似为:
THW = Frequency(频率) / Computational Intensity(计算强度) = Frequency * max(VINPUT,VOUTPUT) / VOPS
频率就是kernel的时钟频率。这个值是由特定的平台决定,比如,Alveo U200的最大kernel时钟是300Mhz。VINPUT,VOUTPUT是输入输出数据,VOPS是操作总数。由此可以看出,大量的操作数和少量的数据的函数更适合加速。
确定所需的并行量
经过上述计算后,可以估算出初始的HW/SW性能比:
Speed-up = THW/TSW = Fmax * Running Time /VOPS
没有使用并行运算,则初始的加速(speed-up)通常会小于1。
接下来就要计算多少并行量可以满足性能目标:
Parallelism Needed = TGoal / THW = TGoal * Vops / (Fmax * max(VINPUT, VOUTPUT))
并行方式可以通过多种方式实现:拓展数据路径,使用多个计算引擎,使用多个kernel实例,开发人员应根据他们的需求和应用程序的特点确定最佳组合方式。
确定数据路径应并行处理多少个样本
一种可能性是通过创建更宽的数据路径(数据的输入和输出的过程)然后并行处理更多数据以便加快计算速度。有些算法很适合这种方法,而有些则不适用。重要的是要了解这个算法的本质,确定这种方法是否可运用。如果可运用,那么并行处理多少数据才能满足性能目标也是需要考虑的。
运用更宽的数据路径、并行处理更多数据这些方法,本质是通过减少加速函数等待时间(运行时间)来实现提高性能的。
确定在FPGA中可以(应该)实例化多少个kernel
如果数据路径无法并行化(或不够充分),则请考虑添加更多kernel实例,这通常被称为使用多个计算单元(CU)。添加更多的kernel实例的本质是允许加速函数更多的调用,从而提高应用程序的性能,如下所示。多个数据集由不同的实例并发处理。只要主机应用程序可以保持kernel繁忙,应用程序的性能就会随着实例数的增加而线性增加。
在Vitis中,很容易通过添加额外的kernel实例来提高加速性能,不需要过多的代码调整。在这一点上,开发人员应该充分了解硬件中满足性能目标所需的并行度,结合数据路径宽度和kernel实例来达到预期的目标。
4.
确定软件部分并行量
虽然FPGA及其kernel旨在提供潜在的并行性,但是必须对软件应用程序进行设计以便利用这种潜在的并行性。
软件应用程序中的并行性主要是以下几方面:
•最大限度地减少空闲时间,并在kernel运行时执行其他任务。
•保持kernel处于活动状态,以便尽早并经常执行新的计算。
•优化与FPGA之间的数据传输。
host程序总是处于繁忙状态并且计划执行下一步的操作,而kernel端是处理当前的任务。所以,host程序必须统筹与kernel的数据传输,并且向kernel端发送请求,不然再多的kernel也是没有效果的。
在kernel运行时最大程度地减少CPU空闲时间
FPGA加速是将某些计算从主机处理器转移到FPGA的kernel中,在纯顺序模型中,应用程序将闲置地等待结果,准备并回复处理。设计软件应用程序以避免此类空闲周期,首先是确定不依赖kernel结果的应用程序部分,然后重新设计,以便这些函数可以在主机处理器上与FPGA中运行的kernel同时运行处理。
保持kernel利用率
Kernel是在FPGA中的,仅在应用程序请求它们时才运行。为了最大程度地提高性能,应使kernel一致处于繁忙(工作)状态。从概念上讲,这是通过在当前请求完成之前发出下一个请求来实现的。这可以实现流水线式执行和重复执行,使kernel得到最佳利用。
原始的应用程序重复的调用 func1,func2和func3。针对这个应用程序对应创建了三个kernel是K1,K2和K3。最平庸的实现是将三个kernel按顺序运行,就像原始的应用程序一样。但是,这意味着每个kernel只有三分之一的时间处于工作状态。更好的方法是重构软件应用程序,以便它可以向kernel发出流水线请求。这允许K1在K2处理K1的输出的同时开始处理新的数据集。通过这个方法,三个kernel以最大化的利用率不断运行。
优化与FPGA之间的数据传输
在加速的应用程序中,必须将数据从主机传输到FPGA,尤其是基于PCIe的应用程序中。这就引入了延迟,对于应用程序的整体性能而言,可能是非常昂贵的。数据需要在正确的时间被传输,如果kernel的运行需要等待数据,那么应用程序的性能会收到负面影响。因此,重要的是在kernel需要数据时提前传输数据。这可以通过重复数据传输、kernel执行来实现,这可以隐藏数据传输的等待时间开销,并避免kernel等待数据的情况。
优化数据传输的另一种方法是传输最佳大小的缓冲区。如下图所示,有效的PCIe吞吐量根据传输的缓冲区大小而有很大的差异。缓冲区越大,吞吐量越好,从而确保加速器始终具有可操作的数据而不会浪费时间。通常来说,最好进行1MB或更大的数据传输。预先运行DMA测试对于找到最佳缓冲区大小可能很有用。同样,在确定最佳缓冲区大小时,请考虑大缓冲区对资源利用率和传输延迟的影响。
Xilinx建议在一个公共缓冲区内对多组数据进行分组,以实现最大可能的吞吐量。
概念化应用程序时间线
开发人员现在应该对哪些函数需要加速,需要什么并行性才能达到性能目标以及如何交付应用程序有很好的了解。在这一点上,以应用程序时间表的形式总结信息是非常有用的。应用程序时间轴序列(例如“保持Kernels使用率”中所示的序列)是应用程序在运行时表现性能和并行化非常有效的方法。它们可以展示应用程序如何调动体系结构中潜在的并行性。
Vitis软件平台会从实际应用程序运行中生成时间轴视图。如果开发人员设计了预期的时间表,则可以将其与实际结果进行比较,从而确定潜在的问题,然后迭代并收敛到最佳结果,如上图所示。
5.
微调架构细节
在正式编写应用程序及其kernel之前,还有最后一步:从顶层决策中细化和提炼次级体系架构的细节。
确定最终kernel边界
之前已经有过讨论,通过创建多个kernel的示例可以提高性能。然而,增加CU(compute unit)会对IO端口,带宽和资源有额外地消耗。
在Vitis软件平台流程中,kernel端口的最大宽度为512,并且FPGA在资源方面也具有固定的成本,并不是无限消耗。重要的是,目标平台也对可使用的最大端口设置了限制。所以我们要注意这些限制,以最佳方式充分使用这些端口及其带宽。
使用多个CU进行扩展的另一种方法是通过在内核中添加多个引擎(engine)进行扩展。与添加更多CU的方式来提高性能一样,此方法就是用在内核中的不同engine同时处理多个数据集。
将多个engine放置在同一kernel中可充分利用kernel I / O端口的带宽。如果数据路径engine不需要端口的全部宽度,则在kernel中添加其他engine比在其中创建具有单个engine的多个CU效率更高。
在kernel中放置多个engine还可以减少端口数量和事务数量到需要仲裁的全局内存中,从而提高了有效带宽。另一方面,采用这种方法需要在开发kernel时考虑I / O多路复用行为,尽可能地减少全局内存的访问。这是开发人员需要做出的权衡。
确定kernel的位置和连接性
确定kernel边界后,开发人员要明确实例kernel的数量和连接到全局内存资源的端口数量。在这一点上,了解目标平台的功能以及哪些全局内存资源可用很重要。例如,AlveoU200数据中心加速卡具有分布在三个超级逻辑区域(SLR)中的4 x 16 GB DDR4存储区和3 x 128 KB的PLRAM存储区。有关更多信息,请参阅《 Vitis Software Platform Release Notes》。
如果kernel是工厂,则全局内存是货物往返工厂的仓库。SLR就像独特的工业区,可以在其中建立仓库和工厂。虽然可以将货物从一个区域的仓库转移到另一个区域的工厂,但这会增加延迟和复杂性。
使用多个DDR有助于平衡数据传输负载并提高性能。但是,这也会带来成本,因为每个DDR控制器都会消耗FPGA资源。在决定如何将kernel端口连接到内存库时,请均衡这些考虑因素。
在完善了这些架构细节之后,开发人员就应该已经掌握kernel以及整个应用程序所需的所有信息了。
原文标题:开发者分享 | 如何确定一个硬件加速应用
文章出处:【微信公众号:FPGA开发圈】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
时钟设计程序【C语言】2015-12-28 574
-
DSP之频率计程序设计与仿真2016-04-15 346
-
数字温度计程序2016-05-04 440
-
频率计程序代码2016-06-29 842
-
51单片机设计程序30例资料2016-08-22 1750
-
智能小车的设计程序和测试程序免费下载2019-06-12 952
-
发电机调速系统设计程序及其波形2020-04-01 718
-
汇编语言结构化设计程序教程2021-03-26 598
-
单片机设计程序30例资料2021-05-30 1224
-
如何去确定一个硬件加速器件?有哪些步骤?2021-06-11 1353
-
SYNOPSYS光学设计程序教程手册2022-01-05 555
-
ds18b20数字温度计程序2022-03-11 719
-
如何确定一个硬件加速应用2022-08-02 587
-
ADI与战略合作伙伴共同开发全面的集成式电机控制设计程序2023-11-29 275
-
TPS54120的设计程序2024-10-10 63
全部0条评论

快来发表一下你的评论吧 !
