

文本纠错是自然语言处理的第一道坎
描述
文本纠错是自然语言处理的一个重要任务,也是文本处理的第一道坎,一个错误的文本表述可能会引起后续语义的错误表达,并对后续的效果产生影响。
例如,以常见的输入错误为例,十分丰富多彩,常见错误类型包括:
1、少字:微信跳一 -> 微信跳一跳
2、多字:微信跳一跳跳 -> 微信跳一跳
3、错字:微信 挑一挑 -> 微信跳一跳
4、拼音:tiaoyitiao -> 跳一跳
5、中英文混拼:held住 -> hold住
6、中文拼音混拼:跳yi跳 -> 跳一跳
7、知识错误:南山平安金融中心 -> 福田平安金融中心
8、音转:灰机 -> 飞机
9、谐音字词,如 配副眼睛-配副眼镜
10、混淆音字词,如 流浪织女-牛郎织女
11、字词顺序颠倒,如 伍迪艾伦-艾伦伍迪
12、字词补全,如 爱有天意-假如爱有天意
13、形似字错误,如 高梁-高粱
14、中文拼音全拼,如 xingfu-幸福
15、中文拼音缩写,如 sz-深圳
而这些错误又可以进一步区分为有意或者无意两种,无有意的错误可能是为了反识别或者恶意营销等灰色产业服务。
因此,文本纠错这块就有诸多应用场景。
例如,写作辅助上,在内容写作平台上内嵌纠错模块,可在作者写作时自动检查并提示错别字情况。从而降低因疏忽导致的错误表述,有效提升作者的文章写作质量,同时给用户更好的阅读体验。
又如,搜索纠错上,用户经常在搜索时输入错误,通过分析搜索query的形式和特征,可自动纠正搜索query并提示用户,进而给出更符合用户需求的搜索结果,有效屏蔽错别字对用户真实需求的影响。
再如,语音识别对话纠错上,将文本纠错嵌入对话系统中,可自动修正语音识别转文本过程中的错别字,向对话理解系统传递纠错后的正确query,能明显提高语音识别准确率,使产品整体体验更佳。
而就技术而言,实际上可以对应的变成变体或者错误体的生成以及还原两者,前者研究如何快速生成尽可能丰富的变体,后者研究如何返回正确的文本,十分有趣。
因此,本文主要围绕NLP纠错技术,做第一篇论述,从工业场景中的文本纠错、鲁棒性过滤以及恶意短信变体字还原大赛三个比赛进行介绍,并使用最简单的编辑距离操作生成变体,供大家一起参考。
一、自然语言处理技术创新大赛—中文文本纠错比赛
赛题背景: 文本校对任务主要是针对文本中出现的错误进行检测和纠正,属于综合性的自然语言处理研究子方向,能够比较全面体现了自然语言处理的技术水平。过往文本校对相关评测使用的都是外国语言学习者撰写的文本,这些文本的错误大多数都是一些中文母语写作者不会犯的一些错误。
对于政务公文、新闻出版等行业来说,一款针对以中文为母语的用户所使用的校对系统将会有更大的帮助。因此,本赛题主要选择互联网上中文母语写作者撰写的网络文本作为校对评测数据,从拼写错误、语法错误、语病错误等多个方面考察机器的认知智能能力。
赛题任务: 赛题选择网络文本作为校对数据,从中检测并纠正错误,实现中文文本校对系统。即给定一段文本,校对系统从中检测出错误字词、错误类型,并进行纠正。具体的输入、输出及错误类型为:
输入:输入文件包含若干行文本,每行文本对应句子ID和相应的待校对句。
输出:输出文件每行对应句子ID及相应的校对结果。校对结果中每处错误需包含错误位置、错误类型、错误字词及正确字词,每处错误及多处错误间均以英文逗号分隔。
错误类型:拼写错误,包括别字及别词;语法错误,包括冗余、缺失、乱序;语病错误,包括语义重复及句式杂糅。
举例如下:

地址:https://2021aichina.caai.cn/track?id=5
二、中国人工智能大赛鲁棒性过滤算法
第三届中国人工智能大赛,重点聚焦算法治理、深度伪造音视频检测、网络安全等方向,希望以竞赛方式解决现实场景中需求问题。
赛题背景:构建鲁棒的过滤算法在网络空间内容治理领域具有重要的实际价值。信息产生、获取、消费等环节的算法鲁棒性欠缺,会严重影响正常的社会秩序。因此,算法鲁棒性在算法安全治理中属于非常重要的指标。
在信息生成和获取的环节,过滤算法扮演着安全护卫的作用,把守网络信息安全的第一关。过滤算法是指将用户产生的特定信息进行自动识别和过滤的算法。目前,特定信息变换各种形式出现在互联网中,这对于现有的过滤算法无疑是一个挑战。
例如,中国人工智能大赛鲁棒性过滤算法赛道过滤出了这样一道赛题:

赛题任务:主办方将收集上千条含特定信息和同比例正常信息的短文本,用以评价选手的过滤模型。测试文本根据所包含特定信息的变种难度不同设置相应的难度分数。本赛题将以参赛选手过滤模型识别出的特定信息样本以及该样本对应难度的积作为主要评价指标。
地址:https://ai.xm.gov.cn/competition/project-detail.html?id=e813904b755a439da1a6c5749bcf9b60&competeId=a8e0c40dbb2347fba8b3c9a6294efa5b
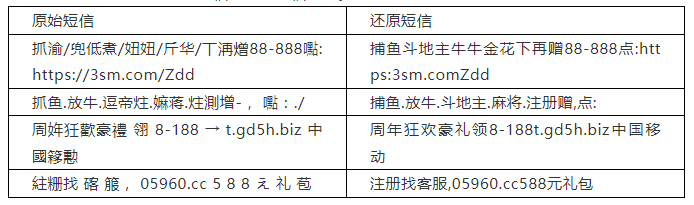
三、面向黑灰产治理的恶意短信变体字还原
赛题背景: 恶意短信一直是黑灰产引流的重要渠道,信息中携带的微信号、QQ号、网址更是非法信息传播的主要入口,业界通常做法是利用违法或不良信息检测引擎在手机终端实现自动拦截。然而不法分子为逃避检测,通过使用变体字发送恶意短信绕过拦截规则的情况越来越多。
由于变体字变换方式多,变换速度快,单纯通过规则进行变体词发现的效果有限,配套人工审核成本高且具有滞后性。如何精准和高效地还原变体字文本,提高非法信息的抽取能力,以及新型变体字还原的泛化性和时效性,就成为了解决这一难题的“关键之钥”。
赛题任务: 参赛团队通过设计算法,实现对恶意短信中变体字的还原。参赛团队需要对训练集中的短信样本进行分析,采用深度学习建模的方法将测试集中新出现的短信变体字还原为正常信息文本,即不含有变体字、干扰字符,所有变体字部分应使用常见简体汉字、字符来表示,同时需要保证不包含变体字的正常文本不受影响。
例子如下;
变体句子: 噂儆的碦戸:其鎃祝册茺贈镐888葒笣!禛朲对弈佰捆任你選!嶺:http://url.cn/5aLeqP2
还原后: 尊敬的客户:棋牌注册充赠高888红包!真人对弈百款任你选!领:url.cn5aLeqP2
地址:https://beta-www.datafountain.cn/competitions/508
四、基于编辑距离生成变体小测试
实际上,基于编辑距离来生成的变体是最快速且简单的方式,下面做了一个快速实现:
# 词典库
vocab = set([line.rstrip() for line in open('vocab.txt')])
# print(vocab)
# 生成所有的候选集合
def generate_edit_one(word):
"""
# 假设使用26个字符
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i],word[i:]) for i in range(len(word)+1)]
# inserts操作
inserts = [L+c+R for L,R in splits for c in letters]
# delete操作
deletes = [L+R[1:]for L,R in splits if R]
# replace操作
replaces = [L+c+R[1:]for L,R in splits if R for c in letters]
candidates = set(inserts + deletes + replaces)
# 过滤掉不存在词典库里的单词
return [word for word in candidates if word in vocab]
def generate_edit_two(str):
"""
给定一个字符串,生成编辑距离不大于2的字符串
"""
return [e2 for e1 in generate_edit_one(str) for e2 in generate_edit_one(e1) if e2 in vocab]
print('给定一个字符串,生成编辑距离为1的字符串','
',generate_edit_one('apple'))
print ('给定一个字符串,生成编辑距离不大于2的字符串','
',generate_edit_two("apple"))
执行后,我们可以产生如下变体结果:

审核编辑 :李倩
-
python自然语言2018-05-02 0
-
自然语言处理怎么最快入门?2018-11-28 0
-
【推荐体验】腾讯云自然语言处理2019-10-09 0
-
自然语言处理的语言模型2020-04-16 0
-
什么是自然语言处理2021-09-08 0
-
自然语言处理怎么最快入门_自然语言处理知识了解2017-12-28 5311
-
文本数据分析:文本挖掘还是自然语言处理?2018-04-10 17956
-
自然语言处理(NLP)的学习方向2020-07-06 13175
-
自然语言处理包括哪些内容 自然语言处理技术包括哪些2023-08-03 7305
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 1595
-
自然语言处理和人工智能的区别2023-08-28 1555
-
自然语言处理是什么技术的一种应用2024-07-03 848
-
自然语言处理技术有哪些2024-07-03 1118
-
ASR与自然语言处理的结合2024-11-18 405
-
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤2024-12-05 464
全部0条评论

快来发表一下你的评论吧 !
