

Jetson Nano开发者套件面向所有人的人工智能
描述
NVIDIA 在 2019 年 NVIDIA GPU 技术大会 (GTC) 上宣布推出Jetson Nano开发者套件 ,这是一款售价 99 美元的计算机,现已面向嵌入式设计师、研究人员和 DIY 制造商提供,在紧凑、易于使用的平台中提供现代 AI 的强大功能完全的软件可编程性。Jetson Nano 通过四核 64 位 ARM CPU 和 128 核集成 NVIDIA GPU 提供 472 GFLOPS 的计算性能。它还包括采用高效、低功耗封装的 4GB LPDDR4 内存,具有 5W/10W 电源模式和 5V DC 输入,如图 1 所示。
新发布的JetPack 4.2 SDK 为基于 Ubuntu 18.04 的 Jetson Nano 提供了完整的桌面 Linux 环境,具有加速图形,支持 NVIDIA CUDA Toolkit 10.0,以及 cuDNN 7.3 和 TensorRT 5 等库。SDK 还包括本地安装流行的能力TensorFlow、PyTorch、Caffe、Keras 和 MXNet 等开源机器学习 (ML) 框架,以及 OpenCV 和 ROS 等计算机视觉和机器人开发框架。
与这些框架和 NVIDIA 领先的 AI 平台的完全兼容性使得将基于 AI 的推理工作负载部署到 Jetson 比以往任何时候都更加容易。Jetson Nano 为各种复杂的深度神经网络 (DNN) 模型带来实时计算机视觉和推理。这些功能支持多传感器自主机器人、具有智能边缘分析的物联网设备和先进的人工智能系统。甚至迁移学习也可以使用 ML 框架在 Jetson Nano 上本地重新训练网络。
Jetson Nano 开发套件的尺寸仅为 80x100mm,具有四个高速 USB 3.0 端口、MIPI CSI-2 摄像头连接器、HDMI 2.0 和 DisplayPort 1.3、千兆以太网、M.2 Key-E 模块、MicroSD 卡插槽、和 40 针 GPIO 接头。端口和 GPIO 接头开箱即用,可与各种流行的外围设备、传感器和即用型项目配合使用,例如 NVIDIA 在 GitHub 上开源的 3D 打印深度学习JetBot 。
开发套件从可移动的 MicroSD 卡启动,该卡可以通过任何带有 SD 卡适配器的 PC 进行格式化和映像。该开发套件可通过 Micro USB 端口或 5V DC 筒形插孔适配器方便地供电。摄像头连接器与经济实惠的 MIPI CSI 传感器兼容,包括基于 8MP IMX219 的模块,可从 Jetson 生态系统合作伙伴处获得。还支持 Raspberry Pi 摄像头模块 v2,其中包括 JetPack 中的驱动程序支持。表 1 显示了关键规格。
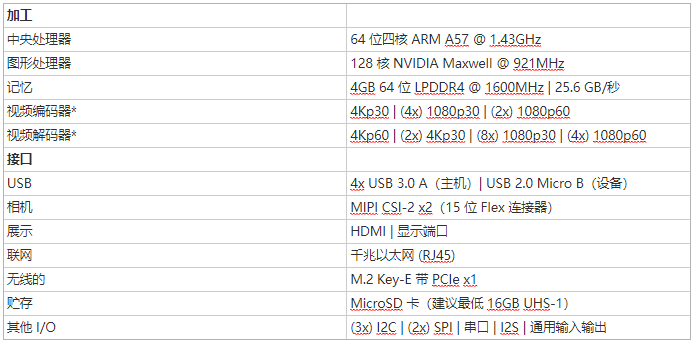
该开发套件围绕 260 针 SODIMM 式系统级模块 (SoM) 构建,如图 2 所示。SoM 包含处理器、内存和电源管理威廉希尔官方网站 。Jetson Nano 计算模块尺寸为 45x70mm,将于 2019 年 6 月开始发货,售价为 129 美元(以 1000 单位为单位),供嵌入式设计人员集成到生产系统中。量产计算模块将包括 16GB eMMC 板载存储和增强型 I/O,带有 PCIe Gen2 x4/x2/x1、MIPI DSI、附加 GPIO 和 12 个 MIPI CSI-2 通道,用于连接多达三个 x4 摄像头或四个摄像头在 x4/x2 配置中。Jetson 的统一内存子系统在 CPU、GPU 和多媒体引擎之间共享,提供精简的 ZeroCopy 传感器摄取和高效的处理管道。
深度学习推理基准
Jetson Nano 可以运行各种高级网络,包括流行 ML 框架的完整原生版本,如 TensorFlow、PyTorch、Caffe/Caffe2、Keras、MXNet 等。这些网络可用于构建自主机器和复杂的人工智能系统,通过实现强大的功能,如图像识别、对象检测和定位、姿势估计、语义分割、视频增强和智能分析。
图 3 显示了来自在线可用模型的推理基准测试的结果。 有关在Jetson Nano 上运行这些基准测试的说明,请参阅 此处。推理使用批量大小 1 和 FP16 精度,使用 JetPack 4.2 中包含的 NVIDIA 的TensorRT 加速器库。Jetson Nano 在很多场景下都获得了实时性能,并且能够处理多个高清视频流。
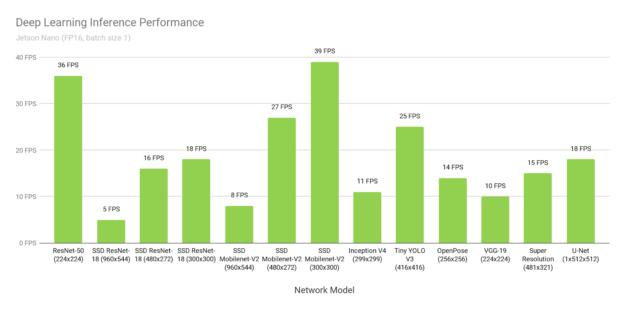
图 3. 使用 Jetson Nano 和 TensorRT 的各种深度学习推理网络的性能,使用 FP16 精度和批量大小 1
表 2 提供了完整结果,包括 Raspberry Pi 3、英特尔神经计算棒 2 和 Google Edge TPU Coral 开发板等其他平台的性能:
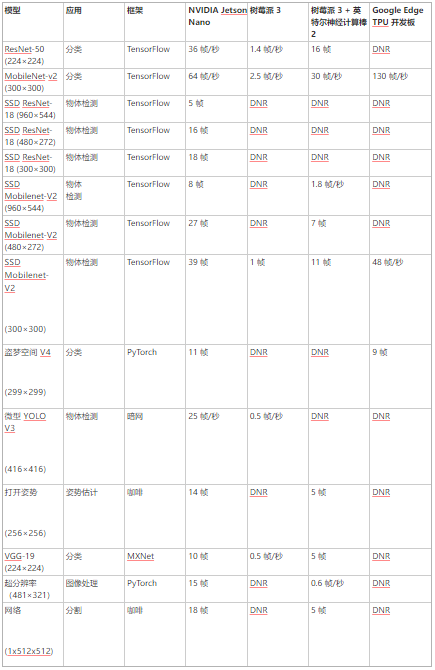
由于内存容量有限、网络层不受支持或硬件/软件限制,DNR(未运行)结果频繁出现。固定功能神经网络加速器通常支持相对狭窄的用例集,硬件支持专用层操作,需要网络权重和激活以适应有限的片上缓存,以避免显着的数据传输损失。它们可能会依靠主机 CPU 来运行硬件不支持的层,并且可能依赖于支持框架的缩减子集(例如 TFLite)的模型编译器。
Jetson Nano 灵活的软件和完整的框架支持、内存容量和统一的内存子系统,使其能够以全高清分辨率运行无数不同的网络,包括同时在多个传感器流上的可变批量大小。这些基准代表了流行网络的样本,但用户可以将各种模型和自定义架构部署到具有加速性能的 Jetson Nano。Jetson Nano 不仅限于 DNN 推理。其 CUDA 架构可用于计算机视觉和数字信号处理 (DSP),使用包括 FFT、BLAS 和 LAPACK 操作在内的算法以及用户定义的 CUDA 内核。
多流视频分析
Jetson Nano 可实时处理多达 8 个高清全动态视频流,并可部署为网络视频录像机 (NVR)、智能摄像机和物联网网关的低功耗边缘智能视频分析平台。NVIDIA 的DeepStream SDK 使用 ZeroCopy 和 TensorRT 优化端到端推理管道,以在边缘和本地服务器上实现终极性能。下面的视频展示了 Jetson Nano 同时在八个 1080p30 流上执行对象检测,同时基于 ResNet 的模型以全分辨率和每秒 500 兆像素 (MP/s) 的吞吐量运行。
图 4 中的框图显示了一个示例 NVR 架构,该架构使用 Jetson Nano 通过深度学习分析通过千兆以太网摄取和处理多达 8 个数字流。该系统可以解码 500 MP/s 的 H.264/H.265 和编码 250 MP/s 的 H.264/H.265 视频。
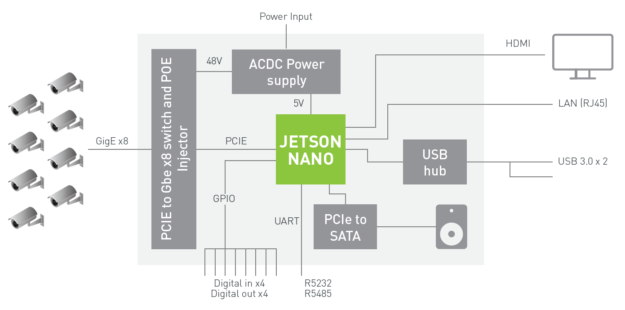
图 4. 具有 Jetson Nano 和 8x 高清摄像头输入的参考 NVR 系统架构
计划在 2019 年第二季度发布对 Jetson Nano 的 DeepStream SDK 支持。请加入DeepStream 开发人员计划 以接收有关即将发布的版本的通知。
喷气机器人
NVIDIA JetBot 是一个新的开源自主机器人套件,它提供了所有软件和硬件计划,以低于 250 美元的价格构建一个人工智能驱动的深度学习机器人。硬件材料包括 Jetson Nano、IMX219 8MP 摄像头、3D 打印机箱、电池组、电机、I2C 电机驱动器和配件。
该项目通过 Jupyter 笔记本为您提供易于学习的示例,介绍如何编写 Python 代码来控制电机、训练 JetBot 检测障碍物、跟踪人和家庭物体等物体,以及训练 JetBot 跟踪地板周围的路径。通过扩展代码和使用 AI 框架,可以为 JetBot 创建新功能。
JetBot也有可用的ROS 节点 ,为那些希望集成基于 ROS 的应用程序和功能(如 SLAM 和高级路径规划)的人支持 ROS Melodic。包含 JetBot ROS 节点的 GitHub 存储库还包括 Gazebo 3D 机器人模拟器模型,允许在虚拟环境中开发和测试新的 AI 行为,然后再部署到机器人上。Gazebo 模拟器生成合成相机数据并在 Jetson Nano 上运行。
你好人工智能世界
Hello AI World 提供了一种很好的方式来开始使用 Jetson 并体验 AI 的力量。只需几个小时,您就可以在带有 JetPack SDK 和 NVIDIA TensorRT 的 Jetson Nano 开发人员套件上启动并运行一组深度学习推理演示,用于实时图像分类和对象检测(使用预训练模型)。本教程侧重于与计算机视觉相关的网络,包括实时摄像头的使用。您还可以使用 C++ 编写自己的易于理解的识别程序。可用的深度学习 ROS 节点 将这些识别、检测和分割推理功能与ROS集成 用于集成到先进的机器人系统和平台中。这些实时推理节点可以轻松放入现有的 ROS 应用程序中。
想要尝试训练自己的模型的开发人员可以遵循完整的“两天演示”教程,该教程涵盖了图像分类、对象检测和语义分割模型的重新训练和自定义迁移学习。迁移学习微调特定数据集的模型权重,避免从头开始训练模型。迁移学习在连接了 NVIDIA 离散 GPU 的 PC 或云实例上执行最为有效,因为训练需要比推理更多的计算资源和时间。
然而,由于 Jetson Nano 可以运行 TensorFlow、PyTorch 和 Caffe 等完整的训练框架,它还可以为那些可能无法使用另一台专用训练机并愿意等待更长时间等待结果的人使用迁移学习进行重新训练。表 3 突出显示了使用 PyTorch 使用 Jetson Nano 在 200,000 张图像、22.5GB 的 ImageNet 子集上训练 Alexnet 和 ResNet-18 从两天到演示教程的迁移学习的一些初步结果:

每个 epoch 的时间是完全通过 200K 图像的训练数据集所需的时间。分类网络可能只需要 2-5 个 epoch 即可获得可用结果,生产模型应在离散 GPU 系统上进行更多 epoch 的训练,直到达到最大准确度。但是,Jetson Nano 通过让网络在一夜之间重新训练,使您能够在低成本平台上试验深度学习和 AI。并非所有自定义数据集都可能与此处使用的 22.5GB 示例一样大。因此,图像/秒表示 Jetson Nano 的训练性能,每个 epoch 的时间随数据集的大小、训练批次大小和网络复杂度而缩放。其他模型也可以通过增加训练时间在 Jetson Nano 上重新训练。
面向所有人的人工智能
Jetson Nano 的计算性能、紧凑的占用空间和灵活性为开发人员创建人工智能驱动的设备和嵌入式系统带来了无限的可能性。
关于作者
Dustin 是 NVIDIA Jetson 团队的一名开发人员推广员。Dustin 拥有机器人技术和嵌入式系统方面的背景,喜欢在社区中提供帮助并与 Jetson 合作开展项目。
审核编辑:郭婷
-
基于JetsoN Nano开发套件的开源智能车项目2020-11-04 0
-
【EASY EAI Nano人工智能开发套件试用体验】EASY EAI Nano人工智能开发套件开箱及硬件初体验2023-05-31 0
-
【EASY EAI Nano人工智能开发套件试用体验】开箱后硬件了解及上电2023-05-31 0
-
【EASY EAI Nano人工智能开发套件试用体验】开箱视频及核心板介绍2023-05-31 0
-
【EASY EAI Nano人工智能开发套件试用体验】EASY EAI Nano人工智能开发套件开箱及最快上手教程2023-06-11 0
-
armsom:为何选择rk3588开发与Jetson Nano引脚兼容的嵌入式产品2023-10-18 0
-
Banana Pi为何选择rk3588开发与Jetson Nano引脚兼容的嵌入式产品2023-11-02 0
-
苹果官方确认:WWDC2017将面向所有人直播2017-05-26 1100
-
EAIDK是全球首个采用Arm架构的人工智能开发平台2019-02-28 8870
-
英伟达推出人工智能小电脑Jetson Nano,为机器人提供大脑2019-03-20 5196
-
微雪电子 人工智能开发套件 AI计算机介绍2019-11-20 1798
-
Jetson Nano b01国产开发套件测评2022-03-09 10399
-
NVIDIA Jetson Nano 2GB开发套件的应用2022-04-18 1383
-
使用 NVIDIA Jetson Nano 开发套件提高您的边缘 AI 和机器人技能2022-12-07 971
-
NVIDIA发布小巧高性价比的Jetson Orin Nano Super开发者套件2024-12-19 339
全部0条评论

快来发表一下你的评论吧 !
