

基于ESP32的TinyML图像分类摄像头的设计方案
描述
项目背景
我们正面临着越来越多的嵌入机器学习革命。而当我们谈到机器学习(ML)时,首先想到的就是图像分类,一种 ML Hello World!
ESP32-CAM 是最受欢迎且价格合理的已集成摄像头的开发板之一,它结合了 Espressif ESP32-S MCU 芯片和 ArduCam OV2640 摄像头。
ESP32 芯片功能强大,甚至可以处理图像。它包括 I2C、SPI、UART 通信以及 PWM 和 DAC 输出。
参数:
工作电压:4.75-5.25V
飞溅:默认 32Mbit
RAM:内部 520KB + 外部 8MB PSRAM
无线网络:802.11b/g/n/e/i
蓝牙:蓝牙 4.2BR/EDR 和 BLE 标准
支持接口(2Mbps):UART、SPI、I2C、PWM
支持TF卡:最大支持4G
IO口:9
串口速率:默认115200bps
频谱范围:2400 ~2483.5MHz
天线形式:板载PCB天线,增益2dBi
图像输出格式:JPEG(仅支持OV2640)、BMP、GRAYSCALE
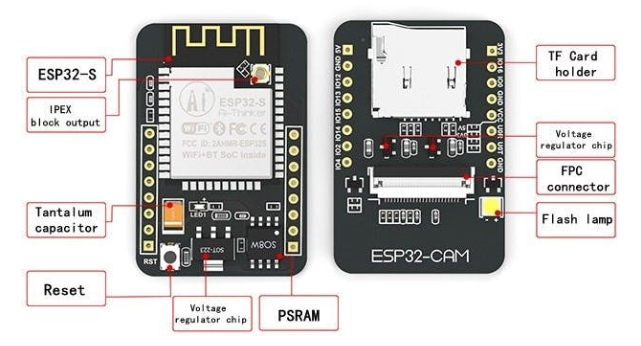
下面,一般威廉希尔官方网站 板引脚排列:
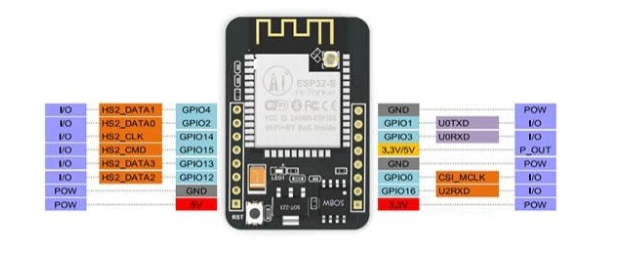
请注意,此设备没有集成 USB-TTL 串行模块,因此要将代码上传到 ESP32-CAM 需要一个特殊的适配器,如下所示:
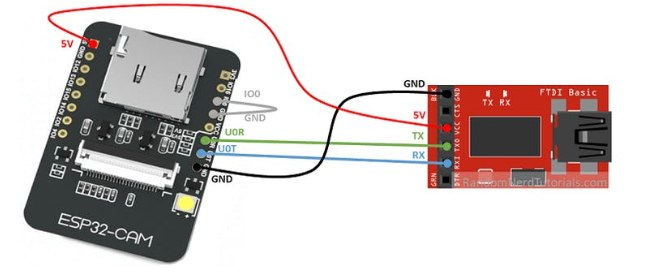
或 USB-TTL 串行转换适配器如下:

如果你想了解 ESP32-CAM,我强烈推荐Rui Santos 的书籍和教程。
在 Arduino IDE 上安装 ESP32-Cam
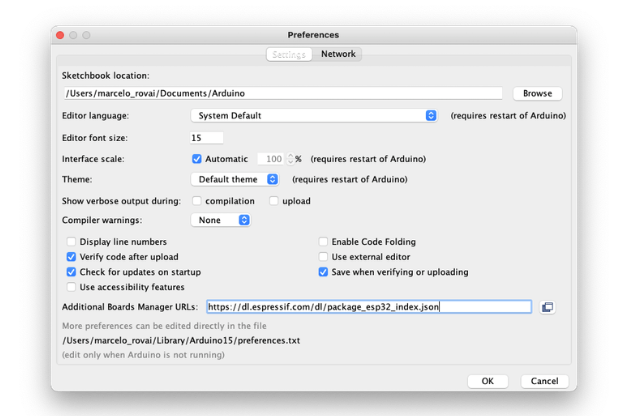
从 Arduino IDE 打开首选项窗口并转到:Arduino 》偏好
使用以下行输入:
https://dl.espressif.com/dl/package_esp32_index.json
在 Additional Board Manager URLs 中输入下图内容
接着,打开 boards manager,转到Tools 》 Board 》 Boards Manager.。。并使用esp32 输入。选择并安装最新的软件包
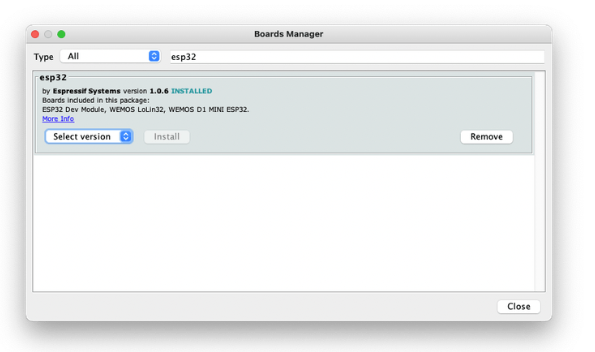
选择 ESP32 开发板:
例如,AI-Thinker ESP32-CAM
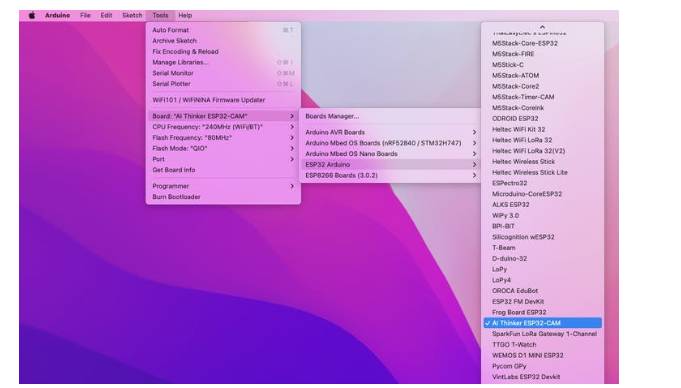
最后别忘记选择连接 ESP32-Cam的端口。
这就对了!设备应该没问题。让我们做一些测试。
用 BLINK 测试威廉希尔官方网站
板
ESP32-CAM 有一个与 GPIO33 连接的内置 LED。因此,相应地更改 Blink 草图:
| #define LED_BUILT_IN 33 void setup() { pinMode(LED_BUILT_IN, OUTPUT); // Set the pin as output } // Remember that the pin work with inverted logic // LOW to Turn on and HIGH to turn off void loop() { digitalWrite(LED_BUILT_IN, LOW); //Turn on delay (1000); //Wait 1 sec digitalWrite(LED_BUILT_IN, HIGH); //Turn off delay (1000); //Wait 1 sec } |
特别提醒,LED 位于威廉希尔官方网站 板下方。
测试 WiFi
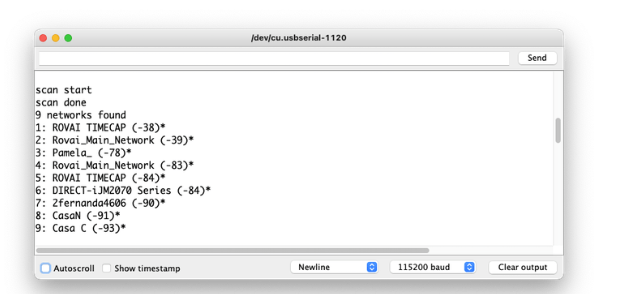
ESP32S 的声音特性之一是其 WiFi 功能。所以,让我们测试一下它的收音机,扫描它周围的 wifi 网络。你可以做到这一点,运行板附带的代码示例之一。
转到 Arduino IDE 示例并查找WiFI ==> WiFIScan
在串行监视器上,您应该会看到设备范围内的 wifi 网络(SSID 和 RSSI)。这是我在家里得到的:
测试相机
对于相机测试,您可以使用以下代码:
示例 ==> ESP32 ==> 相机 ==> CameraWebServer
只选择合适的相机:
| #define CAMERA_MODEL_AI_THINKER |
并使用网络凭据输入:
|
const char* ssid = "*********"; const char* password = "*********"; |

在串行监视器上,您将获得正确的地址来运行您可以控制摄像机的服务器:
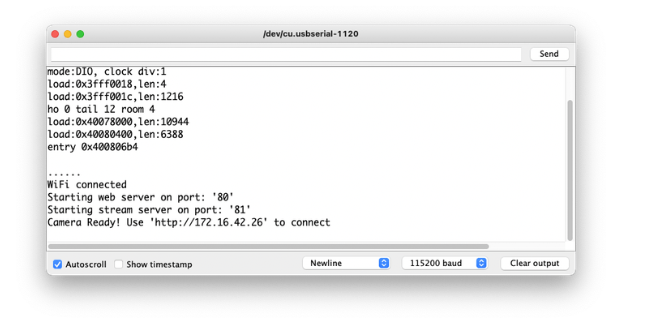
这里我输入的是:http: //172.16.42.26
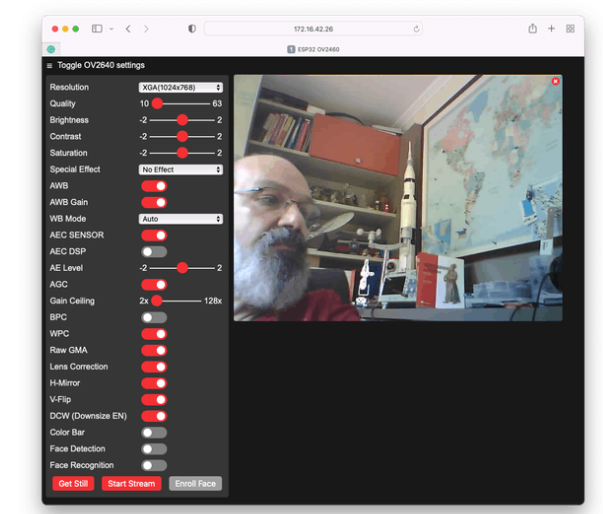
运行你的网络服务器
到目前为止,我们可以测试所有 ESP32-Cam 硬件(MCU 和摄像头)以及 wifi 连接。现在,让我们运行一个更简单的代码来捕获单个图像并将其呈现在一个简单的网页上。本代码基于 Rui Santos 伟大的教程:ESP32-CAM Take Photo and Display in Web Server 开发
从 GitHub 下载文件:ESP332_CAM_HTTP_Server_STA ,更改 wifi 凭据并运行代码。结果如下:
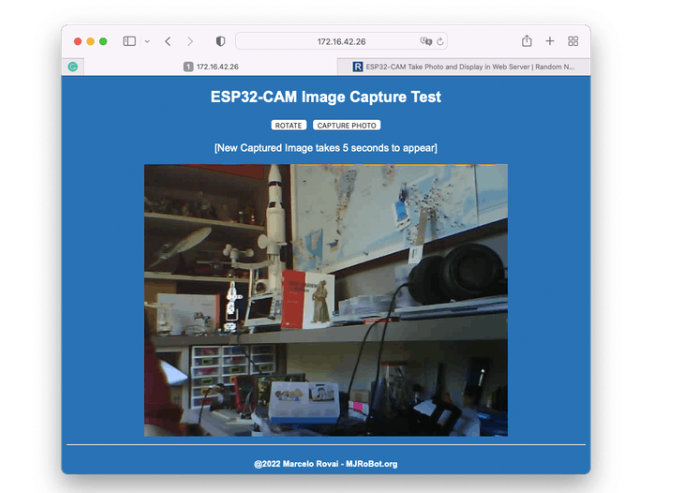
尝试检查代码;更容易理解相机的工作原理。
水果与蔬菜 - 图像分类
现在我们已经运行了嵌入式相机,是时候尝试图像分类了。
我们应该开始训练模型并继续在 ESP32-CAM 上进行推理。我们需要找到大量的数据用于训练模型。
TinyML 是一组与嵌入式设备上的机器学习推理相关的技术,由于限制(在这种情况下主要是内存),我们应该将分类限制为三到四个类别。我们将苹果与香蕉和土豆区分开来(您可以尝试其他类别)。
因此,让我们找到一个包含这些类别的图像的特定数据集。Kaggle 是一个好的开始:
https://www.kaggle.com/kritikseth/fruit-and-vegetable-image-recognition
该数据集包含以下食品的图像:
水果-香蕉、苹果、梨、葡萄、橙子、猕猴桃、西瓜、石榴、菠萝、芒果。
蔬菜- 黄瓜、胡萝卜、辣椒、洋葱、土豆、柠檬、番茄、萝卜、甜菜根、卷心菜、生菜、菠菜、大豆、花椰菜、甜椒、辣椒、萝卜、玉米、甜玉米、红薯、辣椒粉、墨西哥胡椒、姜、 大蒜、 豌豆、 茄子。
每个类别分为训练(100 张图像)、测试(10 张图像)和验证(10 张图像)。
将数据集从 Kaggle 网站下载到您的计算机。
使用 Edge Impulse Studio 训练模型
我们将使用 Edge Impulse 进行培训,这是在边缘设备上进行机器学习的领先开发平台。
在 Edge Impulse 输入您的帐户凭据(或创建一个免费帐户)。接下来,创建一个新项目:
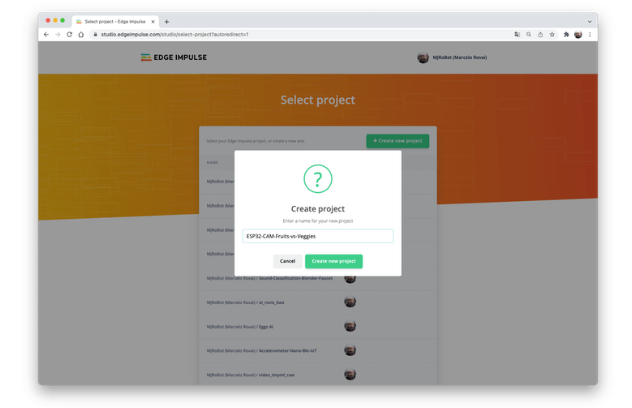
数据采集
接下来,在上传数据部分,从您的计算机上传所选类别的文件:
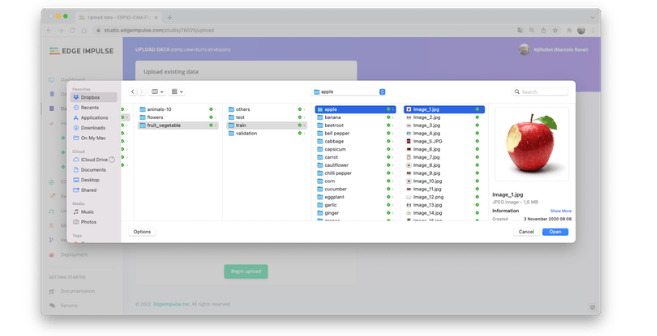
如果您以三类数据结束,阅读培训会有所帮助
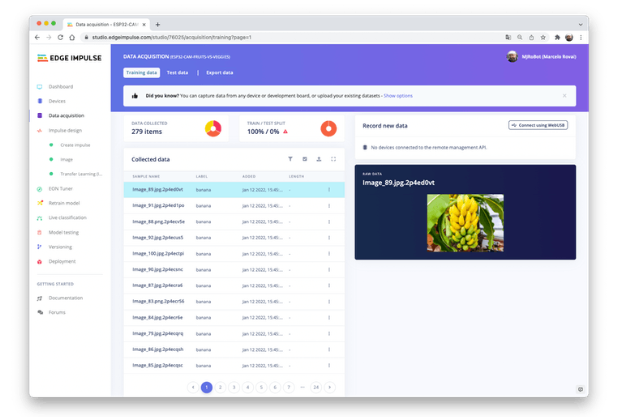
您还可以上传额外的数据以进行进一步的模型测试或拆分训练数据。
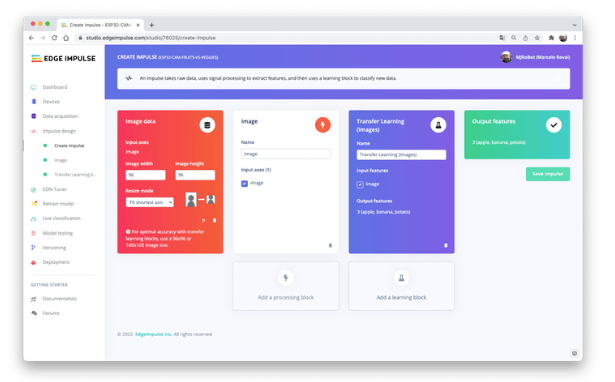
冲动设计
脉冲获取原始数据(在本例中为图像),提取特征(调整图片大小),然后使用学习块对新数据进行分类。
如前所述,对图像进行分类是深度学习最常见的用途,但要完成这项任务需要使用大量数据。每个类别我们有大约 90 张图片。这个数字够吗?一点也不!我们将需要数千张图像来“教授或建模”以区分苹果和香蕉。但是,我们可以通过使用数千张图像重新训练先前训练的模型来解决这个问题。我们将这种技术称为“迁移学习”(TL)。
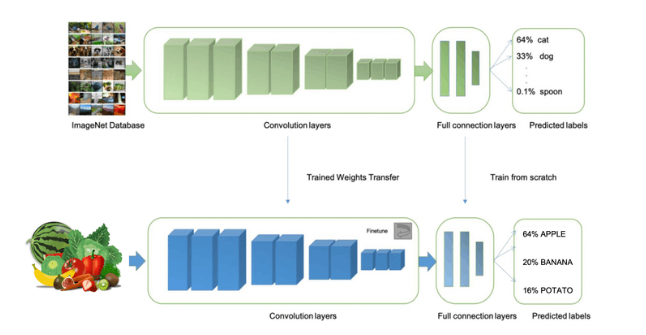
使用 TL,我们可以在我们的数据上微调预训练的图像分类模型,即使在相对较小的图像数据集(我们的案例)中也能达到良好的性能。
因此,从原始图像开始,我们将调整它们的大小(96x96)像素,然后将它们提供给我们的迁移学习块:
预处理(特征生成)
除了调整图像大小外,我们还应该将它们更改为灰度,以保持实际的 RGB 颜色深度。这样做,我们的每个数据样本都将具有 9 维、216 个特征 (96x96x1)。保持RGB,这个尺寸会大三倍。使用灰度有助于减少推理所需的最终内存量。
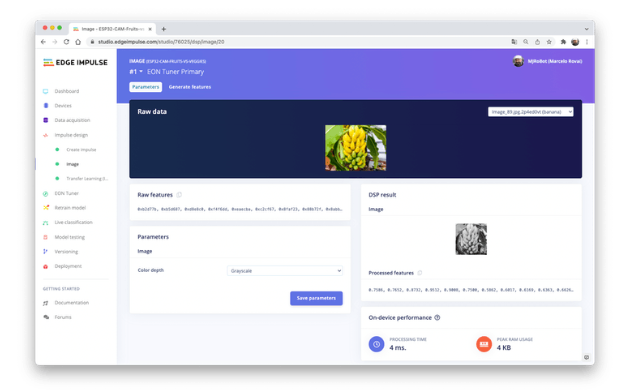
不要忘记“保存参数”。这将生成要在训练中使用的特征。
培训(迁移学习和数据增强)
2007 年,Google 推出了MobileNetV1,这是一个通用计算机视觉神经网络系列,专为移动设备而设计,支持分类、检测等。MobileNets 是小型、低延迟、低功耗的模型,参数化以满足各种用例的资源限制。
尽管基本的 MobileNet 架构已经很小并且具有低延迟,但很多时候,特定用例或应用程序可能需要模型更小更快。为了构建这些更小且计算成本更低的模型,MobileNet 引入了一个非常简单的参数α (alpha),称为宽度乘数。宽度乘数 α 的作用是在每一层均匀地细化网络。
Edge Impulse Studio 提供 MobileNet V1(96x96 图像)和 V2(96x96 和 160x160 图像),具有多个不同的α值(从 0.05 到 1.0)。例如,对于 V2、160x160 图像和 α=1.0,您将获得最高准确度。当然,有一个权衡。精度越高,运行模型所需的内存就越多(大约 1.3M RAM 和 2.6M ROM),这意味着更多的延迟。
在另一个极端,使用 MobileNet V1 和 α=0.10(大约 53.2K RAM 和 101K ROM)将获得更小的占用空间。
为了在 ESP32-CAM 上运行这个项目,我们应该停留在可能性的较低端,保证推理的情况,但不能保证高精度。
与深度学习一起使用的另一项必要技术是数据增强。数据增强是一种可以帮助提高机器学习模型准确性的方法。数据增强系统在训练过程中(如翻转、裁剪或旋转图像)对训练数据进行小的、随机的更改。
在这里,您可以看到 Edge Impulse 如何对您的数据实施数据增强策略:
|
# Implements the data augmentation policy def augment_image(image, label): # Flips the image randomly image = tf.image.random_flip_left_right(image) # Increase the image size, then randomly crop it down to # the original dimensions resize_factor = random.uniform(1, 1.2) new_height = math.floor(resize_factor * INPUT_SHAPE[0]) new_width = math.floor(resize_factor * INPUT_SHAPE[1]) image = tf.image.resize_with_crop_or_pad(image, new_height, new_width) image = tf.image.random_crop(image, size=INPUT_SHAPE) # Vary the brightness of the image image = tf.image.random_brightness(image, max_delta=0.2) return image, label |
在训练期间暴露于这些变化可以帮助防止模型通过“记忆”训练数据中的表面线索而走捷径,这意味着它可以更好地反映数据集中深层的潜在模式。
我们模型的最后一层将有 16 个神经元,其中 10% 的 dropout 用于防止过拟合。这是训练输出:
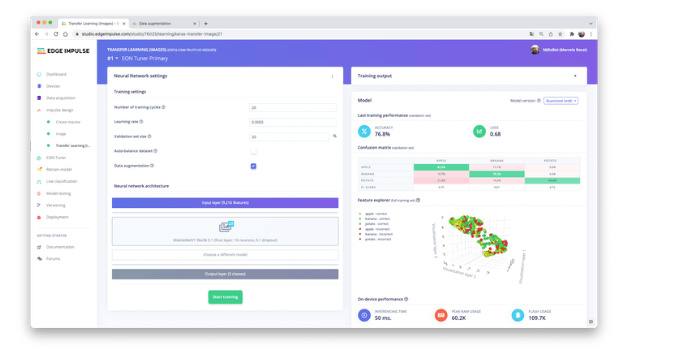
结果不是很好。该模型达到了大约 77% 的准确率,但预计在推理期间使用的 RAM 内存量非常小(大约 60 KB),这非常好。
部署
训练后的模型将部署为 .zip Arduino 库,用于特定的 ESP32-Cam 代码。
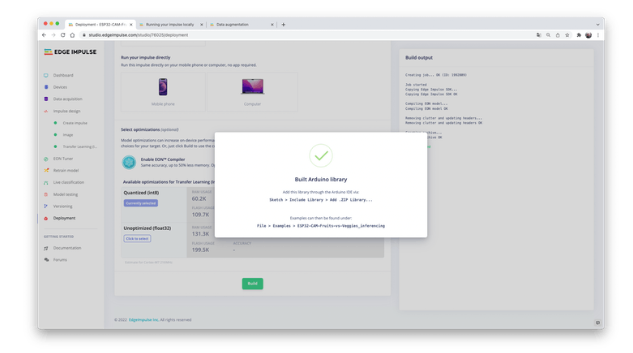
打开您的 Arduino IDE 并在Sketch 下,转到Include Library并添加.ZIP Library。选择您刚刚从 Edge Impulse Studio 下载的文件,就是这样!
在Arduino IDE 的示例选项卡下,您应该在项目名称下找到一个草图代码。
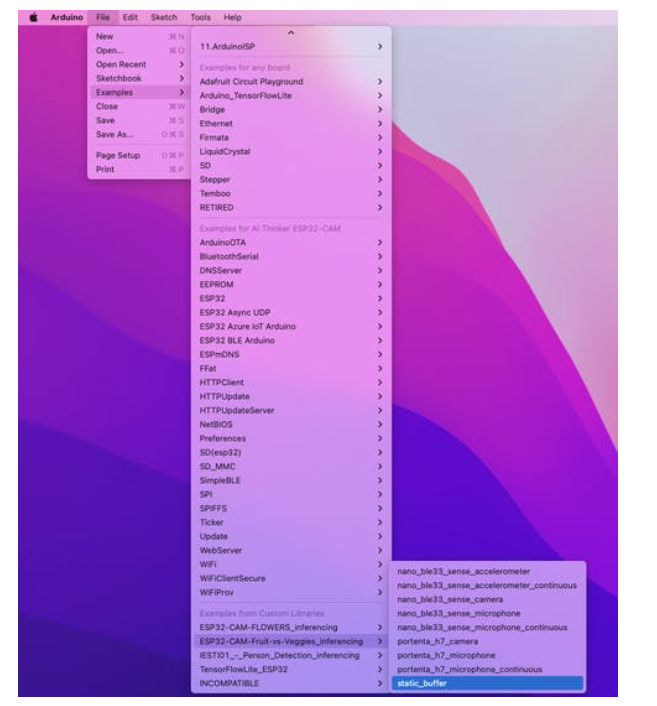
打开静态缓冲区示例:
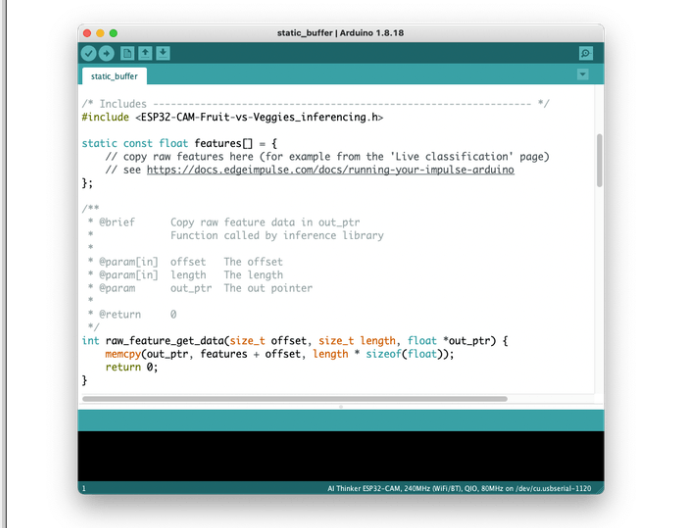
您可以看到,第一段代码正是调用了一个库,该库具有在您的设备上运行推理所需的一切。
#include 《ESP32-CAM-Fruit-vs-Veggies_inferencing.h》
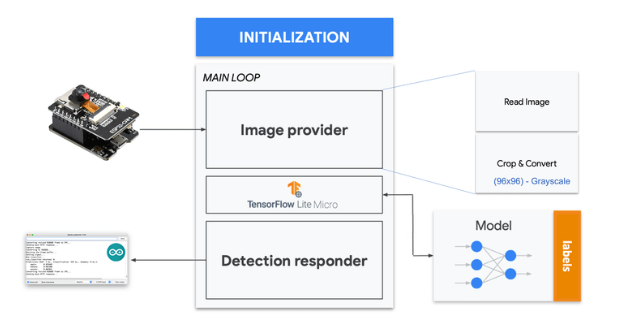
当然,这是一个通用代码(一个“模板”),它只获取一个原始数据样本(存储在变量中:features = {} 并运行分类器,进行推理。结果显示在串行监视器上。
我们应该做的是从相机中获取样本(图像),对其进行预处理(调整为 96x96,转换为灰度并平整它。这将是我们模型的输入张量。输出张量将是一个包含三个值,显示每个类的概率。
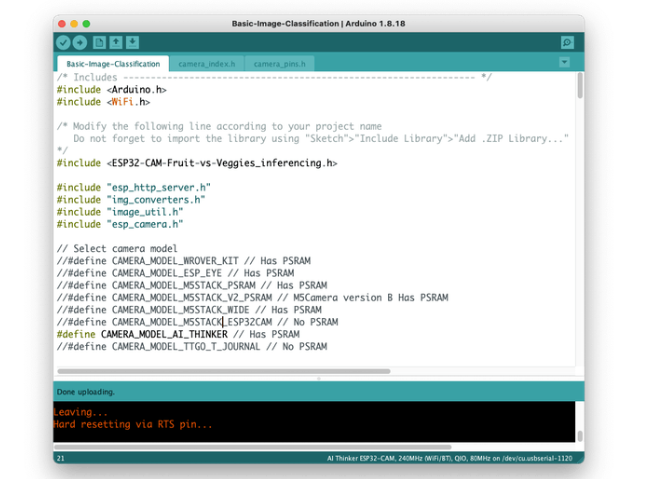
在网站上:https ://github.com/edgeimpulse/example-esp32-cam,Edge impulse 改编了可用于相机测试的代码(示例 ==》 ESP32 ==》 相机 ==》 CameraWebServer),包括必要的在 ESP32-CAM 上运行推理。在 GitHub 上,下载代码Basic-Image-Classification,包括您的项目库,选择您的相机和您的 wifi 网络凭据:
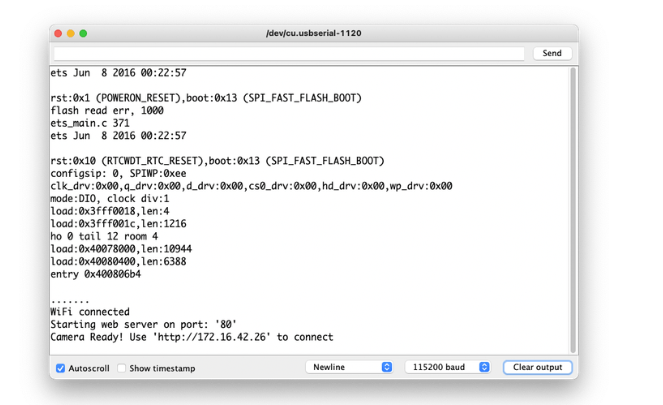
将代码上传到您的 ESP32-Cam,您应该可以开始对水果和蔬菜进行分类了!您可以在串行监视器上检查它:
测试模型(推理)

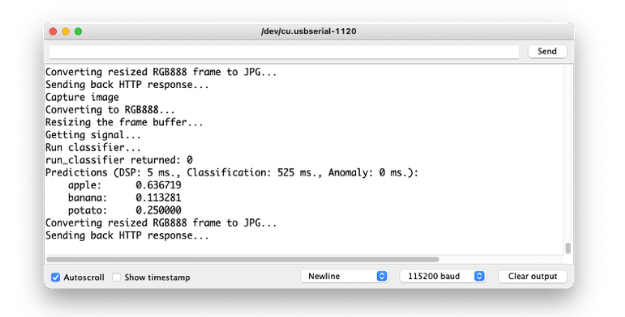
用相机拍照,分类结果会出现在串口监视器上:
可以在网页上验证相机捕获的图像:
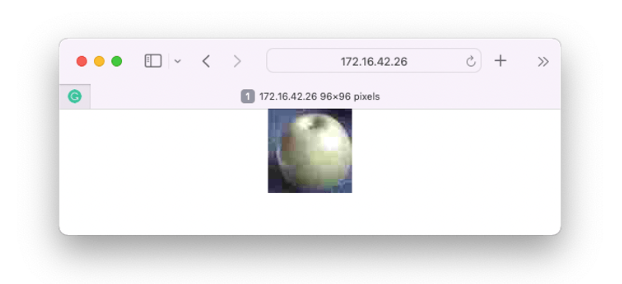
其他测试:
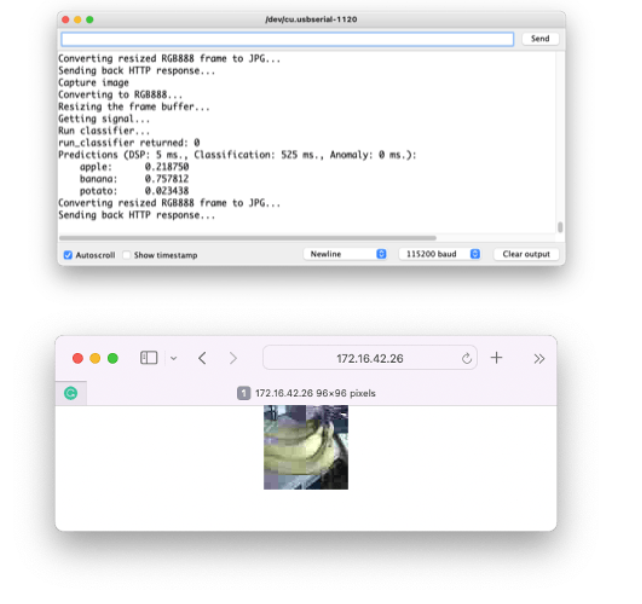
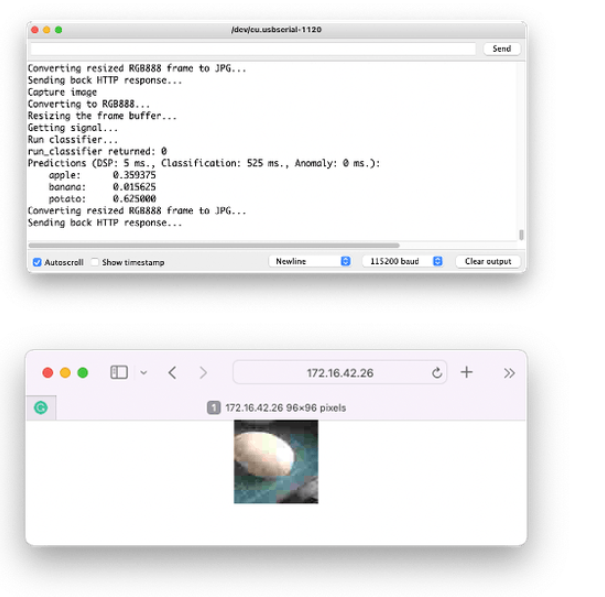
结论
ESP32-Cam 是一种非常灵活、不昂贵且易于编程的设备。该项目可以证明 TinyML 的潜力,但我不确定整体结果是否可以应用于实际应用程序(以开发的方式)。只有最小的迁移学习模型才能正常工作(MobileNet V1,α=0.10),任何使用更大的α来提高准确性的尝试都会导致 Arena 分配错误。可能的原因之一是运行相机的最终通用代码中已经使用的内存量。因此,项目的下一步是优化最终代码,释放更多内存用于运行模型。
-
esp32是如何与摄像头连接的呢?2024-06-28 0
-
如何对ESP32 AUDIO OV2640摄像头的音频进行调试呢2022-02-15 0
-
esp32的模组中没有摄像头的硬件接口,请问它是如何与摄像头连接的呢?2023-03-13 0
-
ESP32如何传输摄像头视频码流?2023-10-17 0
-
ESP32 AUDIO OV2640摄像头 音频调试日记2021-12-16 1238
-
带有ESP32的Discord安全摄像头2022-11-08 434
-
ESP32 CAM:遥控物体检测摄像头2022-12-15 671
-
基于ESP32-CAM的RSTP协议的网络摄像头2022-12-15 3814
-
基于ESP32的安全摄像头设计2022-12-27 457
-
TinyML:ESP32 CAM和TFT上的实时图像分类2023-02-08 770
-
什么是ESP32-CAM摄像头?2023-02-17 23639
-
使用Esp32和TinyML进行手势分类2023-06-15 838
-
ESP32触屏摄像头2023-06-27 432
-
使用ESP32-S3搭建网络摄像头2023-09-06 6420
-
如何使用ESP32摄像头模块构建简单的CCTV安全摄像头2024-02-11 7227
全部0条评论

快来发表一下你的评论吧 !
