

并非所有的模拟计算都是平等的
描述
随着消费、生物医学和 IoT/IIoT 市场中始终监听设备的爆炸式增长,似乎每个人都在尝试使用模拟来节省设计中的功耗。借助使用“模拟内存计算”来降低处理器功率的新型机器学习 (ML) 数字芯片,半导体供应商正在发明新方法来利用模拟计算的固有功率和计算效率。那么,有什么问题呢?事实是,尽管这些芯片利用模拟威廉希尔官方网站 的固有优势来节省芯片内用于神经网络处理的功率,但它们最终是在数字域中对数字数据进行操作的数字处理芯片——这意味着它们只为系统提供有限的节能。幸运的是,模拟ML ) 内核——现在可以在系统级实现更高的功率效率。
虽然模拟内存计算和模拟ML 有时都被标记为“模拟计算”,但它们绝不是一回事。设计人员需要了解模拟内存计算和模拟ML 内核之间的差异,以便他们能够创建更节能的终端设备?
内存模拟计算的芯片级效率
模拟内存计算通常是指在其他数字机器学习处理器的神经网络中使用模拟威廉希尔官方网站 ,以便以较低的功率执行乘法累加 (MAC) 功能。但是利用这种方法的芯片仍然是在标准数字处理范式内运行的时钟处理器,需要立即对所有模拟传感器数据进行数字化,无论是否相关。事实上,使用模拟内存计算的芯片实际上需要三个单独的数据转换才能确定数据的重要性。传感器数据立即转换为数字进行初始处理(数字化优先架构),然后将它们转换为芯片内的模拟数据以实现 MAC 功能,最后,它们在芯片内被转换回数字,以进行推理、分类和其他功能所需的额外数字处理。因此,大量的数据转换,但没有太多的实际模拟处理。
虽然模拟内存计算可能会降低单个推理芯片的功率,但它仅以非常有限的方式使用模拟,因此它只能为整个系统提供同样有限的功率降低。
AnalogML 的系统级效率
相比之下,analogML 内核完全在模拟域内运行,不需要时钟,并且在对任何数据进行数字化之前使用原始模拟传感器数据进行推理和分类。集成到始终监听的设备中,analogML 内核在花费任何精力进行单个数据转换之前确定数据的重要性。我们称其为“先分析”,因为analogML 核心保持数字系统关闭,除非检测到相关数据。
与包含模拟内存计算的 ML 芯片相比,analogML 内核处理模拟传感器数据的更简化方法对系统级效率产生重大影响。(见图 1。)
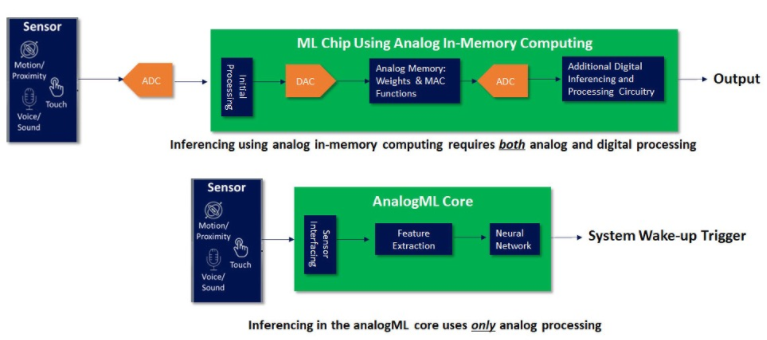
图 1:使用具有模拟内存计算的 ML 芯片的数字化优先系统架构(顶部模块)与使用模拟ML 内核的分析优先系统架构(底部模块)的比较
例如,在典型的语音优先系统中,analogML 内核 100% 的时间都处于开启状态,在始终侦听模式下消耗低至 10µA 的电流以确定哪些数据是重要的(分析优先架构),然后再消耗任何功率关于数字化。这会使系统的其余部分保持休眠状态,直到检测到相关数据。与在数字域中 100% 的时间(数字化优先架构)运行并消耗高达 3000-4000µA 的更传统的 ML 芯片相比,使用模拟ML 的分析优先方法可将电池寿命延长多达 10 倍。这就是持续数天而不是数小时的智能耳塞与一次充电即可持续数年而不是数月的声控电视遥控器之间的区别。
AnalogML Core 中有什么?
深入analogML 核心的底层揭示了模拟内存计算(模拟计算仅用于神经网络)与analogML 核心(由多个软件控制的模拟处理块组成,我们可以启用、重新配置)之间的区别,并针对各种分析优先应用程序进行调整。这些模块——可以在需要时独立供电——实现了一系列功能。(见图 2)。
图 2:analogML 内核的框图
传感器接口——可以为特定传感器类型(麦克风、加速度计等)合成接口威廉希尔官方网站
模拟特征提取——从原始的模拟传感器数据中挑选出显着特征,大大减少进入神经网络的数据量
模拟神经网络——高效、小尺寸、可编程模拟推理模块
模拟数据压缩——模拟传感器数据的连续收集和压缩支持低功耗数据缓冲
模拟范式转变
AnalogML 远远超出了在整个 ML 芯片计算的一小部分中使用一点点模拟计算来节省功耗。这是一个完整的模拟前端解决方案,它使用接近零的功率来确定信号链中最早点的数据的重要性——而数据仍然是模拟的——以最大限度地减少通过系统运行的数据量和数字系统 (ADC/MCU/DSP) 开启的时间量。在某些应用中,例如玻璃破碎检测,事件可能每十年发生一次(或从不发生),使用模拟ML 内核使数字系统在 99% 以上的时间内保持关闭可以将电池寿命延长数年。这开辟了新类别的持久远程应用程序,如果所有相关或不相关的数据在处理之前都被数字化,这些应用程序将无法实现。
底线是所有模拟计算都不相等。无论芯片中包含多少模拟处理来降低其功耗,除非该芯片在模拟域中运行,在模拟数据上,它并没有做我们所知道的最能节省系统功耗的一件事——减少数字处理数据。
审核编辑:郭婷
-
SPT Olga V7.1 全动态多相流模拟计算2012-08-12 0
-
模拟计算机制作2021-08-18 0
-
单片机模拟计算器2021-11-18 0
-
实时模拟计算芯片AD5382009-04-23 988
-
遗传算法的手工模拟计算示例2008-12-20 1452
-
旋转油封装配过程仿真模拟计算2009-05-16 1830
-
实时模拟计算器件AD538的原理及应用2010-09-01 2609
-
地面数据模拟计算风能参数的合理性分析_高健2016-12-30 547
-
模拟计算才是AI技术的未来发展方向2019-08-27 1314
-
模拟计算才是AI算法的发展趋势2019-09-05 4685
-
AD538:实时模拟计算单元数据表2021-04-26 521
-
您的固态电能表有多坚固?并非所有IC都是平等的。2021-05-18 438
-
模拟计算机相比数字计算机真的就一无是处了吗2022-08-01 2759
-
并非所有模拟计算都是平等的2022-11-21 571
-
基于ZYNQ FPGA构建嵌入式的模拟计算板卡2024-01-09 1274
全部0条评论

快来发表一下你的评论吧 !
