

基于Raspberry Pi4构建一个教学点读机
描述
介绍
在这个项目中,我构建了一个支持语音的可教学机器,它可以扫描书页或任何文本源中的文本并将其转换为上下文,用户可以提出与该上下文相关的问题,机器可以仅使用上下文进行回答。我一直想制造这种易于部署的边缘设备,并且可以在不需要任何互联网连接的情况下轻松地针对给定的上下文进行训练。
如何工作
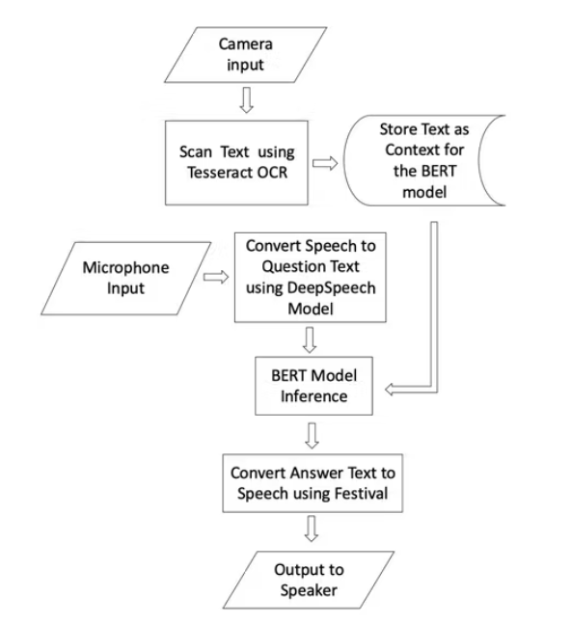
Raspberry Pi 4 连接到 ReSpeaker 2-mics PI HAT,用于使用板载麦克风接收语音。Raspberry Pi 摄像头模块使用 CSI2 连接器连接到 Raspberry Pi 4,该连接器用于扫描书中的文本。ReSpeaker 2-mics PI HAT 上有一个按钮,用于触发扫描过程的开始。按下按钮后,用户必须在 5 秒内立即向相机显示文本(书页或带有一些有意义的英文文本的论文,例如故事段落或维基百科条目)。
使用 Tesseract OCR 应用程序捕获书页图像并将其转换为文本。捕获的文本用作 BERT 模型的上下文,用于回答问题。机器要求用户提问。用户提出问题并使用 DeepSpeech 应用程序将问题语音转换为文本。转换后的问题文本被输入到在英特尔神经计算棒 2 上运行的 BERT 模型中,该模型通过置信度分数推断出答案。使用 Festival 应用程序将最佳答案文本转换为语音,该应用程序在连接到 Raspberry Pi 4 音频输出(3.5 毫米插孔)的扬声器上播放。请参阅连接图的原理图部分并查看下面的流程图以更好地了解应用流程。
使用 Festival 应用程序将最佳答案文本转换为语音,该应用程序在连接到 Raspberry Pi 4 音频输出(3.5 毫米插孔)的扬声器上播放。请参阅连接图的原理图部分并查看下面的流程图以更好地了解应用流程。使用 Festival 应用程序将最佳答案文本转换为语音,该应用程序在连接到 Raspberry Pi 4 音频输出(3.5 毫米插孔)的扬声器上播放。请参阅连接图的原理图部分并查看下面的流程图以更好地了解应用流程。
流程图
应用程序中使用的机器学习模型
使用了三种机器学习模型:
1. Tesseract OCR(基于 LSTM 的模型)
Tesseract 是一个 OCR 引擎,支持 unicode 并且能够开箱即用地识别 100 多种语言。它可以被训练来识别其他语言。
2. DeepSpeech(TensorFlow Lite 模型)
DeepSpeech 是一个开源的 Speech-To-Text 引擎,使用由机器学习技术训练的模型,谷歌的 TensorFlow 使实现更容易。
3.BERT
BERT 是一种语言表示模型,代表 Transformers 的双向编码器表示。预训练的 BERT 模型只需一个额外的输出层就可以进行微调,从而为各种任务(例如问答和语言推理)创建最先进的模型,而无需对特定于任务的架构进行大量修改。
前 2 个模型在 Raspberry Pi 4 上运行,最后一个模型在英特尔神经计算棒 2 上使用 OpenVINO 工具包运行。
安装说明
请按照下面给出的分步说明下载并安装应用程序的所有先决条件。假设已经安装了 Raspberry PI OS(以前称为 Raspbian),并且使用 raspi-config 实用程序启用了 SSH、音频、SPI、I2C 和摄像头。
安装适用于 Raspberry Pi OS 的 OpenVINO 工具包
$ sudo apt update
$ sudo apt install festival cmake wget python3-pip
$ mkdir -p ~/Downloads
$ cd ~/Downloads
$ wget https://download.01.org/opencv/2020/openvinotoolkit/2020.4/l_openvino_toolkit_runtime_raspbian_p_2020.4.287.tgz
$ sudo mkdir -p /opt/intel/openvino
$ sudo tar -xf l_openvino_toolkit_runtime_raspbian_p_2020.4.287.tgz --strip 1 -C /opt/intel/openvino
设置 USB 规则
$ sudo usermod -a -G users “$(whoami)”
现在注销并重新登录。
初始化 OpenVINO 环境
$ source /opt/intel/openvino/bin/setupvars.sh
为英特尔神经计算棒 2 安装 USB 规则
$ sh /opt/intel/openvino/install_dependencies/install_NCS_udev_rules.sh
插入英特尔神经计算棒 2
Festival(语音合成系统框架)配置
Replace the following line in the /etc/festival.scm:
(Parameter.set ‘Audio_Command “aplay -q -c 1 -t raw -f s16 -r $SR $FILE”)
with the line below:
(Parameter.set ’Audio_Command “aplay -Dhw:0 -q -c 1 -t raw -f s16 -r $SR $FILE”)
为 Respeaker 2-mics PI HAT 安装驱动程序
$ cd ~
$ git clone https://github.com/HinTak/seeed-voicecard
$ cd seeed-voicecard
$ sudo 。/install.sh
$ sudo reboot
下载应用程序存储库
$ cd ~
$ git clone https://github.com/metanav/TeachableMachine
下载 BERT 模型 OpenVINO 中间表示文件
$ cd ~/TeachableMachine
$ mkdir models
$ cd models
$ wget https://download.01.org/opencv/2020/openvinotoolkit/2020.4/open_model_zoo/models_bin/3/bert-small-uncased-whole-word-masking-squad-0001/FP16/bert-small-uncased-whole-word-masking-squad-0001.bin
$ wget https://download.01.org/opencv/2020/openvinotoolkit/2020.4/open_model_zoo/models_bin/3/bert-small-uncased-whole-word-masking-squad-0001/FP16/bert-small-uncased-whole-word-masking-squad-0001.xml
下载 DeepSpeech 模型文件
$ cd ~/TeachableMachine/models
$ wget https://github.com/mozilla/DeepSpeech/releases/download/v0.8.2/deepspeech-0.8.2-models.tflite$ wget https://github.com/mozilla/DeepSpeech/releases/download/v0.8.2/deepspeech-0.8.2-models.scorer
运行应用程序
$ cd ~/TeachableMachine
$ pip3 install -r requirements.txt
$ python3 main.py
- 相关推荐
- 点读机
-
如何将16x2 LCD与Raspberry pi4连接2023-06-19 366
-
Raspberry Pi 4/3B的Pico开发板2022-07-26 0
-
一文了解Raspberry Pi 4各项性能跑分2019-07-07 29994
-
树莓派Raspberry Pi4 B型的威廉希尔官方网站 原理图免费下载2019-08-14 7458
-
适用于Raspberry Pi 4的Raspberry Pi Pico开发板2022-07-22 1078
-
使用Raspberry Pi构建Amazon Alexa扬声器的方法2022-07-25 1217
-
在Raspberry Pi4上实现一个面部表情识别系统2022-08-01 2321
-
构建Raspberry Pi电机驱动器HAT的教程分享2022-08-05 1462
-
使用Raspberry Pi构建一个OpenCV人群计数装置2022-08-12 3026
-
使用Raspberry Pi构建一个智能车库开门器2022-09-07 2184
-
构建自己的Raspberry Pi ALPR停车系统2022-11-08 441
-
使用Raspberry Pi4控制直流电机2022-11-29 395
-
Raspberry Pi Zero便携终端的构建2023-01-05 403
-
如何使用Raspberry Pi4摄像头和PIR传感器发送电子邮件2023-06-19 384
-
使用Raspberry PI 4单板计算机构建Samba NAS服务器2023-07-05 286
全部0条评论

快来发表一下你的评论吧 !
