

AI开发平台Vitis AI 2.5让AI加速体验更上一层楼 Vitis AI新功能概述
人工智能
描述
作者:郭冰清
AMD 软件与 AI 产品市场经理
作为广受青睐的 AI 加速开发平台,Vitis AI 已发布全新版本,并于 6 月 15 日正式推出。
我们一直期待 AI 在不同的工作负载和器件平台上发挥更重要的作用。由于从数据中心到边缘端都对 Vitis AI 有着巨大的市场需求,因此,AMD 赛灵思着力丰富与强化 Vitis AI 的功能,旨在提供更快的 AI 加速。本文将对 Vitis AI 2.5 的新功能及优化进行概述。

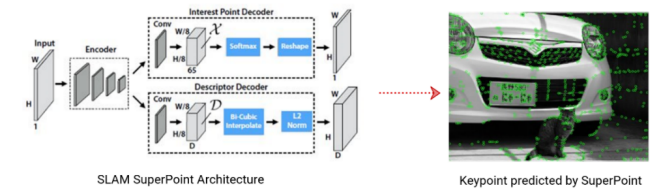
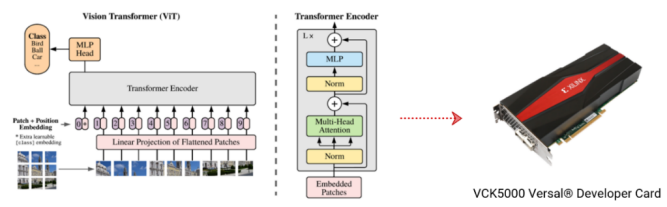
Vitis AI 2.5 的模型库增加了广受欢迎的NLP及更多 CNN 模型,例如 Bert-base,Vision Transformer、端到端 OCR, 以及应用于 SLAM 场景的SuperPoint 与 HFNet 模型等。随着 AMD 对赛灵思的收购, AMD 进一步获得了卓越的软硬件功能;如今,Vitis AI 2.5 支持基于 AMD EPYC 服务器处理器的深度神经网络 ZenDNN 库的 38 种基本模型和优化模型。可以想象,更多的 AMD CPU 用户将通过 Vitis AI 体验更快的 AI 性能加速。

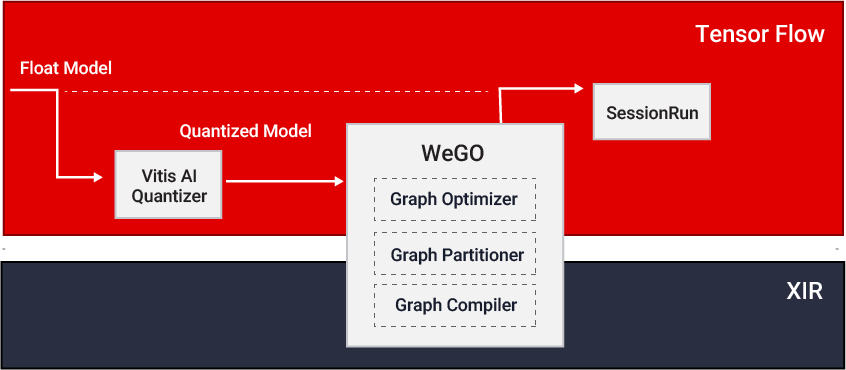
在上一个版本 Vitis AI 2.0 中,我们首次增加了“全图形优化器( WeGO )”这一功能,并在开发者群体中获得了积极的反馈。通过将Vitis AI 堆栈与主流AI框架的集成,WeGO 提供了一套便捷的在云端深度学习处理器单元( Deep Learning Processing Unit,以下简称DPU )上部署 AI 模型的方案。在 Vitis 2.5 中,WeGO 进一步支持了 Pytorch 和 Tensorflow 2 框架。此外,还新增了图像分类、目标检测和分割等 19 个示例,旨在帮助用户在数据中心平台上更顺利地部署 AI 模型。

AMD 赛灵思平台上卓越的 AI 加速性能,离不开一系列强大的AI加速引擎和易于使用的软件工具。目前,我们向主要的 FPGA、自适应 SoC、Versal ACAP 以及 Alveo 数据中心加速器卡提供可扩展的深度学习处理器单元DPU。
随着 Vitis AI 2.5 的发布,Versal DPU IP 可支持 Versal AI Core 系列 VC1902 器件上的多个计算单元模式( Multiple compute unit ),支持 Depthwise 卷积和 LeakyReLU 算子组合等;Zynq Ultrascale MPSoC DPU IP 新增了由算术逻辑单元( ALU )实现的 Pool 和 Depthwise 卷积功能,HardSigmoid 和 HardSwish 功能,Depthwise 卷积结合 LeakyReLU算子组合,此外,还支持大 kernel-size MaxPool、大kernel-size AveragePool及矩形kernel-size AveragePool ,以及 16 位常数权重等新功能。
数据中心端 DPU IP 新增支持更大kernel-size 的Depthwise 卷积(从1x1到8x8),支持基于 AI 引擎( AI Engine )的 pooling、ElementWise 加法及乘法,和大 kernel-size pooling 等功能,满足更多云端 AI 应用开发需求。
本文仅简要讲解了 Vitis AI 2.5 的主要功能。
-
ADI公司测量工程更上一层楼的挑战2018-10-23 0
-
测量工程怎么更上一层楼2019-06-10 0
-
高级进阶-更上一层楼-Android研发工程师高级进阶2019-07-17 0
-
【米尔FZ3深度学习计算卡试用体验】搭建Vitis Ai系统平台并测试2020-12-03 0
-
Vitis AI Model Zone软件平台具备哪些功能?2021-07-09 0
-
【KV260视觉入门套件试用体验】部署vitis-ai环境以及测试demo2023-08-27 0
-
【KV260视觉入门套件试用体验】Vitis AI 初次体验2023-09-10 0
-
【KV260视觉入门套件试用体验】部署DPU镜像并运行Vitis AI图像分类示例程序2023-09-10 0
-
【KV260视觉入门套件试用体验】五、VITis AI (人脸检测和人体检测)2023-09-26 0
-
【KV260视觉入门套件试用体验】基于Vitis AI的ADAS目标识别2023-09-27 0
-
【KV260视觉入门套件试用体验】Vitis-AI加速的YOLOX视频目标检测示例体验和原理解析2023-10-06 0
-
【KV260视觉入门套件试用体验】Vitis AI 构建开发环境,并使用inspector检查模型2023-10-14 0
-
【KV260视觉入门套件试用体验】Vitis AI Library体验之OCR识别2023-10-16 0
-
海马汽车:AnyShare让数据共享上更上一层楼2018-11-04 1066
-
基于软件的Vitis AI 2.0加速解决方案2022-03-15 2340
全部0条评论

快来发表一下你的评论吧 !
