

基于随机分区的超快并行DBSCAN算法介绍
描述
DBSCAN是一种基于密度的空间聚类算法。如在点 p 邻域范围内的点达到一定数量则点p称为核心点,若点 q 在 p 的邻域范围内,则 p 直接密度可达 q ,且 p 、 q属于同一密集区域。由这种关系连接的最大数据点集形成一个簇。DBSCAN算法有检测任意形状的簇、不需要提前知道检测簇的数量等优点。随着近年来大规模并行化的热潮,又出现了许多并行DBSCAN算法。大多数并行DBSCAN算法中,为并行地发现直接密度可达关系,相邻的点被分配到相同的数据分区中进行并行处理,以方便计算相邻点的密度。但是,这种数据分区方案会导致一些问题,如分割成本大、子区域重叠、数据分区之间的负载不平衡等,其中负载问题在分布不均匀的数据集中尤为体现。
为了解决这些问题,本文提出了一种新的并行DBSCAN算法,随机分区DBSCAN,简称RP-DBSCAN,它使用伪随机划分和两级单元格字典。伪随机划分是一种基于单元格的数据划分方案,它可以随机采样小的单元格,而不是点本身。无论数据如何分布,它都可以实现负载平衡,同时保持DBSCAN所需的数据连续性。两级单元格字典是整个数据集的一个高度凝炼的摘要,来表示每个随机分区。该算法能够实现同时找到每个数据分区的局部聚类,然后将这些局部聚类合并得到全局聚类。
一.伪随机划分
本文定义 d 维空间中的一个单元格是一个对角线长度为 ε 的 d 维超立方体, ε 是一个表示邻域半径的参数。如果至少有一个数据点位于一个密集区域内,则可以保证该单元格中的所有数据点都属于同一簇。这大大简化了之后的聚类合并过程。在进行数据分区时,我们随机采样单元格,而不是采样数据点,因此称为伪随机划分。然后,将相同颜色的单元格及其内部的数据点划分为同一个分区。由于 ε 远小于整个空间的长度,这种划分也可以实现真正的随机划分的效果。图 1 说明了伪随机分区的思想,不同颜色代表不同分区。
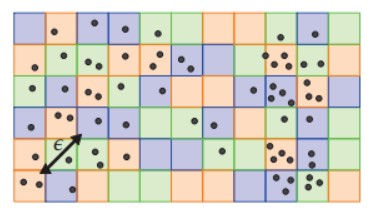
图1 伪随机划分
二.两级单元格字典
两级单元格字典是整个数据集的一个摘要。本质上它是一个两级的树。第一级的节点对应单元格,第二级的节点对应子单元格,其边长为单元格的 h 分之一,其中h由用户给出以指定近似度。每个节点编码每个(子)单元格的密度及其位置。密度是其内部的点数,而位置可以用它们所属单元内的子单元的顺序来表示,故只用 d (h − 1)位。(d 是维度, h 是字典级数)如图 2,h = 2,d = 2,只需两位来表示子单元格位置(00,01,10,11)。
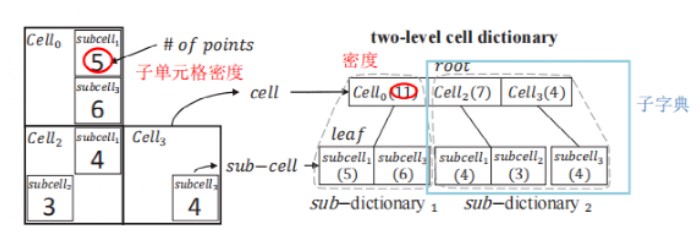
图2 两级单元格字典的构建
因此,可以得出两级单元格字典总大小为
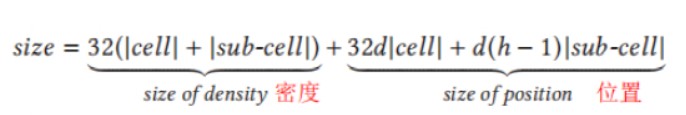
如果数据集非常大,由于内存的限制,有可能无法立即加载整个两级单元格字典,因此把字典划分成较小的子字典,它由根节点集合的一个子集以及与它们连接的叶节点组成。
三. 算法实现的三个阶段
1. 数据分区
通过伪随机划分对整个数据集进行分区,并构建两级单元格字典,为并行处理做好准备。向并行系统中的每个工作者发送一个分区和对应的两级单元格字典。如图3,整个空间被划分为诸多单元格,其中没有为空区域创建单元格。将黄色和绿色单元格划分到两个不同的分区 P1 和 P2 中。然后为每个分区生成一个两级单元格字典。
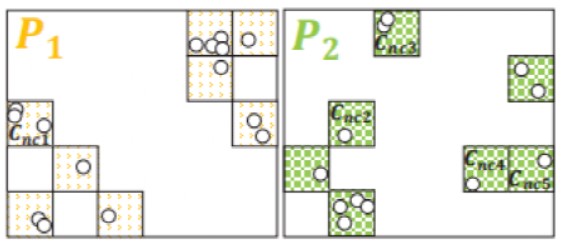
图3 数据分区
2. 单元格图的构造
通过(ε, ρ)区域查询的方式区分单元格是否为核心单元格,构造单元格图时将排除非核心单元格。如图3中的Cnc1-Cnc5判断为非核的,它们在图4中将被排除。然后,从每个分区的每个核心单元搜索其所有完全或部分直接可达的单元格来构建一个单元图。这些单独的关系可以在单元格级别上进行聚合,从而生成一个单元格图。单元格图的顶点是单元格,边是单元格之间的可达性关系。总的来说,一个单元格图表示从一个给定的分区中获得的局部聚类。
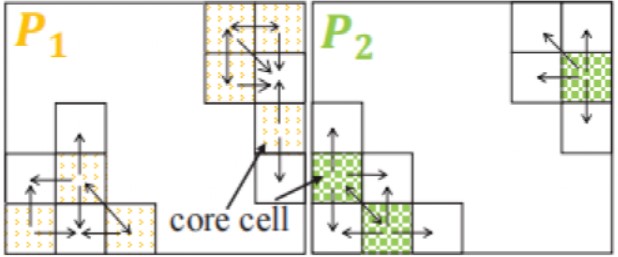
图4 单元格图构造
(ε, ρ)区域查询:
如图5所示,若点p与子单元格中心scn的距离小于ε ,那么,就将这个子单元格加入到点p的邻居集合当中。当点p的邻居点数大于等于设定的参数minPts,就把包含p的单元格标记为核心单元格。
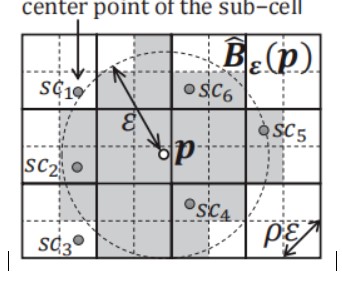
图5 (ε,ρ)区域查询
3. 单元格图的合并
这一部分主要包括渐进式图合并和点标记两个过程。首先,结合从每个工作者返回的对应每个分区的单元格图,确认每条边直接可达性关系,以合并成全局单元格图。之后,根据合并后的图对聚类进行扩展,并根据最终的聚类结果来标记所有的点。整个过程就是由局部聚类产生全局聚类。例如在图 6 中,单元格图简单合并后要进行边类型检测,即判断是完全边(深色实线),部分边(实线箭头)还是未知边(虚线箭头),还要进行减边操作,根据树的结构去除冗余边,最终得到一个树式的全局单元格图。然后,图 7 中进行点标记,图4中位于 P1 和 P2 左下角的单元格在图 7 中形成了一个C1簇,将单元格其中的点标记为同一个颜色,即为最终聚类的结果。
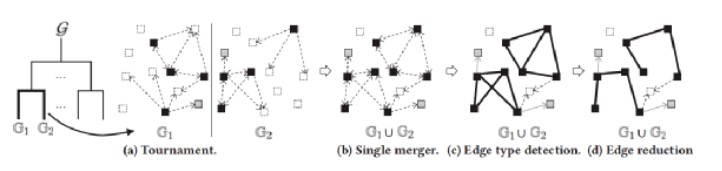
图6 渐进式图合并
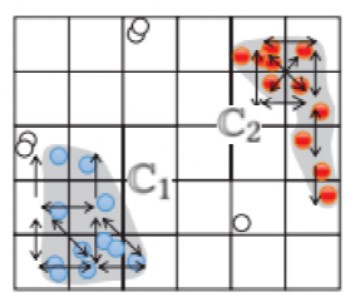
图7 点标记
四. 总结
本文提出采用随机划分策略并行运行DBSCAN。为此,提出了一种基于单元格的数据分割策略,即伪随机划分,它具有区域划分策略和随机划分策略的优点。为了能够在随机分割上执行区域查询,本文设计了两级单元格字典,它是整个数据集的一个高度凝炼的摘要。将它们放在一起,开发了一个高效的并行DBSCAN算法RP-DBSCAN。本文使用GeoLife,Cosmo50,OpenStreetMap等大规模数据集进行实验,将RP-DBSCAN与SPARK-DBSCAN,ESP-DBSCAN等其它6种算法进行效率和精确度的对比。结果显示,RP-DBSCAN更快,更精准,更高效且可扩展性强。RP-DBSCAN显著地超过了最先进的并行DBSCAN算法高达180倍。此外,只有RP-DBSCAN可以处理最大的362GB数据集,而其他算法则不能,有力地验证了其性能的优越性。本文的研究工作显著地提高了DBSCAN算法在大数据时代的可用性。
审核编辑:刘清
-
基于DBSCAN的批量更新聚类算法2009-03-31 901
-
基于分区连通性恢复算法DCRA2017-11-21 916
-
GPU上的维度并行随机吸引策略萤火虫算法2017-11-24 668
-
新型超字级并行改进算法2017-12-06 932
-
基于场景分区的随机潮流解析算法2017-12-15 630
-
随机块模型学习算法2018-01-09 1074
-
Spark渐进填充分区映射算法2018-01-14 674
-
基于数据划分和融合策略的并行DBSCAN算法2018-02-08 1027
-
基于密度DBSCAN的聚类算法2018-04-26 21709
-
如何使用Spark进行并行FP-Growth算法优化及实现2018-11-23 1103
-
基于DBSCAN算法的铁路系统恐怖袭击风险评估方法2021-04-16 697
-
改进的DBSCAN聚类算法在Spark平台上的应用2021-04-26 987
-
基于分布式编码的同步随机梯度下降算法2021-04-27 617
-
基于DBSCAN算法的铁路恐怖袭击风险模型2021-05-31 654
全部0条评论

快来发表一下你的评论吧 !
