

对结构体的对齐理解上有点偏差
描述
最近看到一些朋友在交流结构体对齐方面的一些问题,从他们的交谈中隐隐约感觉有几个朋友对结构体成员的对齐理解上有点偏差,不能说完全不对吧,毕竟这是老生常谈的问题了~
1、变量与内存
首先我们要明确,在嵌入式C语言中变量是什么?其实所谓的变量就是一小段内存。
当你随心所欲的在C程序中定义着各种变量,有没有想过他们是如何被安排到相应内存上的?
好吧,其实他们是怎么安排的,并不需要程序员太多的操心,这个映射过程都是编译器自动给大家分配的,(可以借助动态内存的角度去看待这个分配问题),因为大部分变量在一定内存区域上是可以任意选择地址的,比如你定义一个全局的int gVar 变量,在不进行特殊指定内存位置的情况下,其编译后所分配的内存地址并不一定每次都是相同的;当然,每次编译完成便会确定下来,并且程序中对该变量的访问,均会使用所确定下来的内存地址。
既然变量的地址分配过程由编译器自动完成,但有时候我们想把一些或者某个变量放在固定的内存地址处等,此时就需要通过一些语法来告诉编译器该如何分配这些指定变量内存的分配,比如要做复位数据恢复等。
然而内存的对齐问题也是对这些变量分配位置处理的一种方式,通常我们看到的align或者pack等就是来干预编译器的这块处理的。
2、结构体对齐
理解了上面的一个思路,那么我们来分析分析结构体对齐问题。
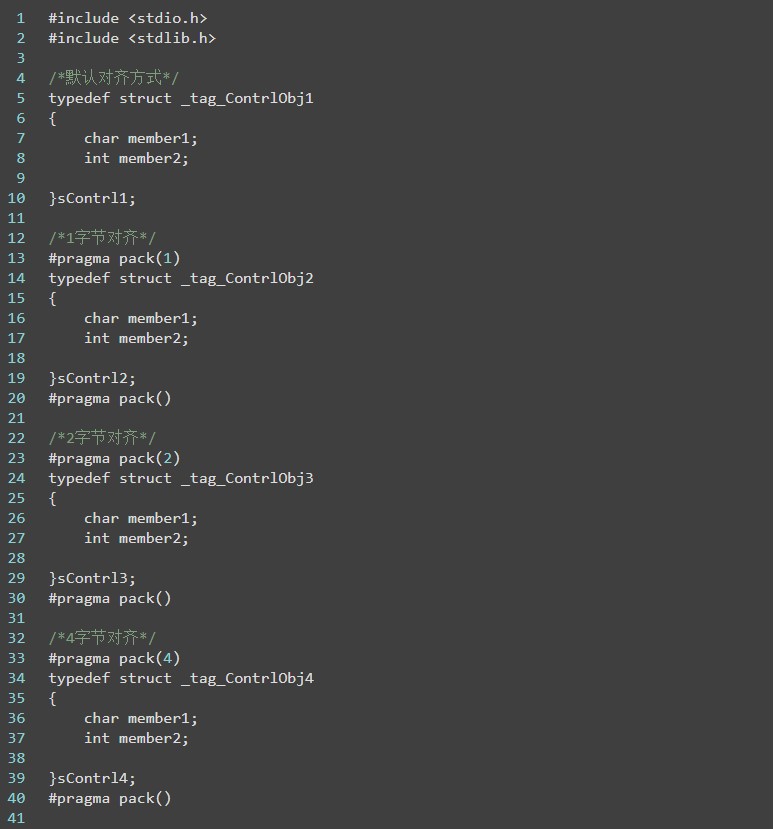
参考demo:
运行结果:

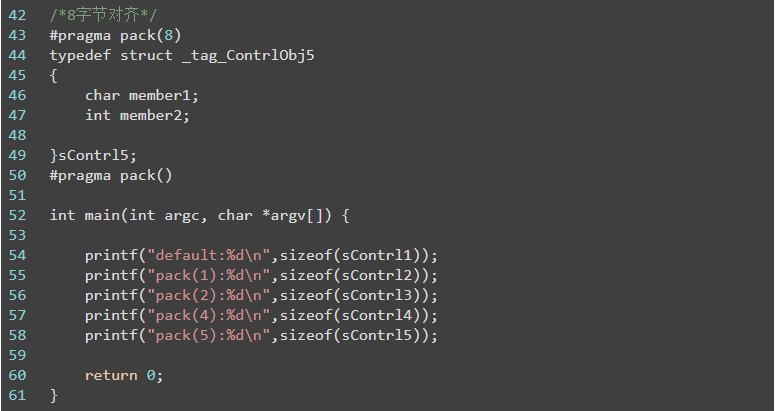
以上编译结果采用的是32位编译器,默认对齐方式是4个字节,char类型占据1个字节,int占据4个字节,
下面简单分析一下结果:
1、默认方式,采用4个字节对齐,那么char后面需要填充3个字节,然后存放int类型,所以结构体大小输出为8。
2、1字节对齐方式,直接紧凑排列,很多人也叫不进行对齐处理,所以输出结果是5。
3、2字节对齐方式,其实和4个字节对齐是类似的,char按照2字节对齐,所以后面需要填充一个字节,这样int才能以两字节对齐排布,此时整个结构体占据6个字节。
4、4字节对齐方式与默认对齐方式一致,最后看看8字节对齐,此时char类型与int类型完全能够被8个字节容纳,而该结构体最大数据类型是4个字节,所以char后面会预留3个字节,进行4字节对齐,然后放置int类型,此时与4字节对齐是一致的。那么一些朋友会问,是不是在上面的8字节例子中再加入一个char类型的成员,整个结构体就会占据16个字节了呢?
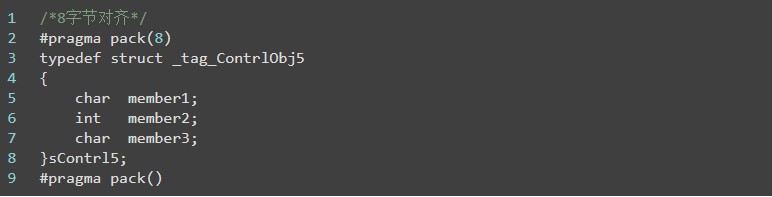
其输出结果如下:
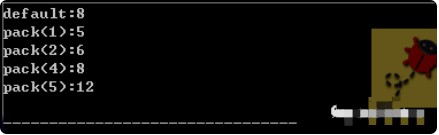
结构体所占据的字节是12个,那是不是认为8字节对齐没有意义呢?我们再看一个实验:
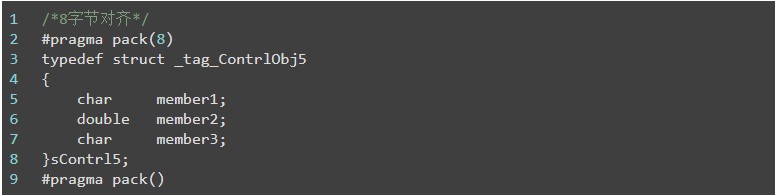
此时double占据了8个字节,按照前面的思路应该是4+8+4,应该最终结构体的大小是16个字节,而结果显示:

输出结果显示24=8+8+8的形式,大家也可以直接采用打印结构体成员地址的办法查看是几个字节对齐,有点晕,到底编译器这一块是怎么处理的呢?结论是:对齐字节数 = min<当前指定的pack值,最大成员所占字节大小>。
很多朋友其实研究到这个阶段基本上就没有再继续探究了~嵌入式C语言一定要跟硬件结合理解~
3、内存对齐
其实所谓的结构体对齐,并不是简单的1个字节、两个字节等多个字节的排列组合,而是在对应对齐地址上分布。首先对齐需要解决的问题是什么 ? 即为啥需要对齐?
提高内存的访问效率,也可以说是受CPU等硬件方面的限制,按照特定的对齐地址进行数据的访问要快于跨非对齐地址的内存访问;并且有些平台仅支持对齐方式访问,非对齐方式会直接运行错误。
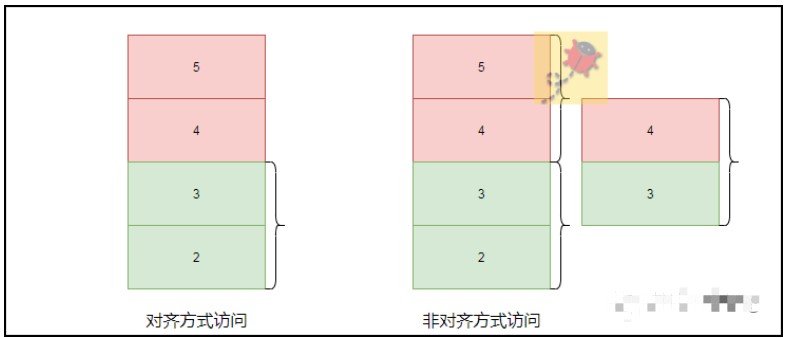
为了加快相关数据的正确访问,编译器会把相关的变量尽量的放到对齐的地址上,也就是默认的对齐方式,比如CPU在偶数地址上访问比较快,那么就会采用2个字节对齐的方式。
所以结构体内部成员并不是简单成员字节个数的对齐拼凑,而是让结构体成员落在对齐的地址上以便访问。如下图所示,当进行2字节对齐,如果只是简单的拼凑,两种分布都是可以的,但是左侧才是正确的2字节对齐方式,char成员变量的地址是2,int变量的地址是4,均为2字节的倍数。
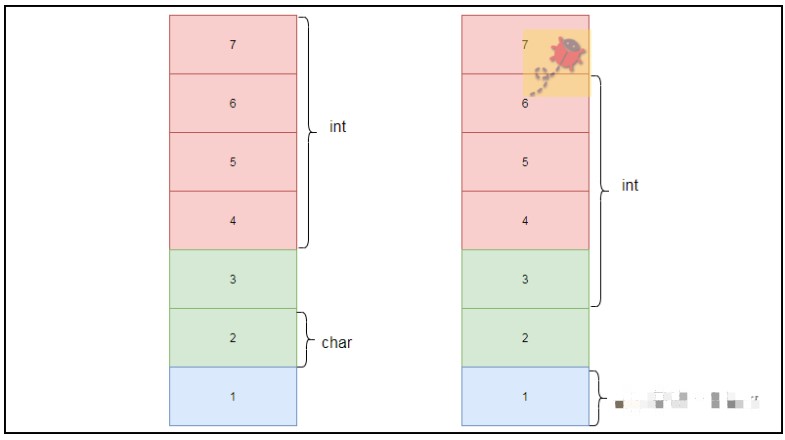
总结一下: 结构体对齐不再是简单的字节个数的拼凑,而是要与内存地址进行挂钩~一般我们也可以理解为内存地址分配是多少字节的倍数,就是多少直接对齐~
审核编辑:刘清
-
C语言-结构体对齐详解2017-07-12 0
-
CCS3.3 结构体成员对齐2018-06-21 0
-
请问在ccs4.2 中怎么设置结构体的字节对齐?2018-08-02 0
-
请问z-stack结构体默认对齐方式是一字节吗?2018-08-18 0
-
漫谈C语言结构体2018-11-15 0
-
结构体变量的定义与使用变量访问结构体成员2021-12-17 0
-
测试结构体成员内存对齐的方式方法2021-12-21 0
-
为什么ST库函数结构体没加对齐地址是连续的?2023-10-15 0
-
解析C语言结构体字节如何对齐2021-06-12 3074
-
STM32 终极字节对齐解析2021-11-23 1187
-
结构体对齐为什么那么重要?2023-04-03 1397
-
为什么要结构体对齐?为什么结构体对齐那么重要?2023-05-26 1268
-
C语言结构体对齐介绍2023-07-11 2510
-
什么是结构体的字节对齐现象2023-11-20 612
-
keil arm工程中结构体1字节对齐如何实现2024-01-05 3793
全部0条评论

快来发表一下你的评论吧 !
