

通过RX MCU和CPU相结合提高电机控制效率
工业控制
描述
与传统的定点 MCU 解决方案相比,当将浮点硬件单元添加到 CPU 内核以内联执行指令时,可以提高电机控制效率。
随着对使用节能技术的日益关注,工程师们越来越多地将他们的控制设计转向更高效的三相无刷直流电机 (BLDC) 和永磁同步电机 (PMSM)。这些电机的电机控制算法通常采用矢量和无传感器矢量控制,其中涉及速度和位置的复杂变换和控制回路。工业应用通常采用基于传感器的控制,因为需要更高的精度,而消费产品应用由于其成本敏感的性质,通常使用无传感器配方。
矢量控制提供对电机速度和扭矩的高效和准确控制。这是通过将交流电动机的三相定子电流解耦为磁通分量和转矩分量来实现的。因此,可以直接控制转矩和磁通(类似于直流电机),从而实现快速的动态响应和出色的稳态性能。事实上,矢量控制使 BLDC 电机驱动器的性能与直流电机驱动器的性能相当,甚至更胜一筹。
无传感器矢量控制 (SVC) 通过在设计中取消速度传感器来降低成本,根据观察到的定子电流估计电机的速度和转子的位置。SVC 使用复杂的坐标变换和电机数学模型,需要大量计算。因此,SVC 与 VC 一样,需要具有高计算能力的快速 MCU。
直到最近,有几个因素阻碍了这些先进的电机控制技术获得更广泛的接受:(1) 复杂的理论数学建模,(2) 涉及的实施策略,以及 (3) 传统的微控制器 (MCU) 和数字信号处理器 (DSP) 实施矢量控制。MCU 和 DSP 使用定点公式,因为这些设备通常没有硬件浮点单元 (FPU)。
可以合理地得出结论,硬件浮点单元将使矢量控制实现更加简单和快捷,因为在矢量控制算法中非常常见的乘法、除法和三角函数可以使用浮点更有效地执行价值观。但由于工程师更喜欢基于知识而非假设进行设计,因此本文将提供性能测试数据,比较使用瑞萨电子浮点 MCU RX 系列的实现与使用定点 MCU 的设计。
我们将展示使用嵌入式 FPU 的解决方案可在 BLDC 和 PMSM 电机上提供更轻松的开发、更高的效率和更低的功耗。具体来说,我们将讨论使用定点和浮点实现的几个关键计算,并展示 FPU 如何在 PI 和 PID 控制回路、克拉克和帕克变换、转换为当前值的 ADC 测量以及编码器数据处理方面提供优势。
关键计算领域
出于测试和分析目的,我们将重点关注 FPU 可能产生影响的四个关键计算领域。
第一个区域是电流和速度变量的 PID 和 PI 回路。PID(比例-积分-微分控制器)是工业控制系统中最常用的反馈控制器。PI 控制器(比例积分控制器)是 PID 控制器的一种特殊情况,其中不使用误差的微分 (D)。
使用瑞萨电子 RX62N 开发平台执行的测量,针对两个电流控制器和一个速度控制器实现为 PI 回路,如下表 1 所示。基于 FPU 的实现在 CPU 带宽和代码大小方面提供了明显的优势。

表 1:PI 回路的测试比较
第二个领域是称为克拉克和帕克变换的坐标变换。但是,需要一些背景知识。矢量控制公式的目标是将三相交流电机等效转换为直流,然后像控制直流电机一样控制交流电机,直接控制电机磁通和转矩。
要将三相电流转换为两相直流电流,第一个变换称为克拉克变换,表示为 αβ→
abc
在下面的图 1 中。它将三相定子框架中的三个平衡电流转换为正交静止框架中的两个相位平衡电流。这发生在与定子框架相同的平面上,但两个轴之间的角度是 90 度而不是 120 度。变换方程如图 1 左下角所示。
第二个变换
dq
→αβ 称为 Park 变换,由图 1 右下方的等式给出。它将静止框架转移到转子框架,使交流电流变为直流电流。同样在图 1 中,F 是磁动力,θ 是 d 轴和 α 轴之间的角度,也称为转子角。
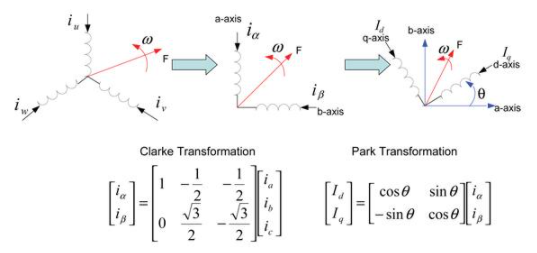
图 1:向量公式中使用的 Clarke 和 Park 变换
我们对 Clarke 和 Park 变换的组合进行了测量,结果如表 2 所示。可以看到 CPU 带宽和代码大小的显着改进。

表 2:Clarke 和 Park 变换的测试比较
第三个领域是基于当前测量的角度估计。这些计算非常复杂,结果如下表 3 所示。在这种情况下,CPU 带宽有很好的提升,而代码大小有很小的提升。

表 3:位置估计的测试比较
第四个方面是将 ADC 测量值转换为适当的电流值。结果显示在下面的表 4 中。我们再次看到两种测量的改进。

表 4:传感器测量的测试比较
对于整体测试,我们为瑞萨电子 RX62N 设备实现了一个完整的定点和 FPU 格式的无传感器矢量控制算法。使用我们的 HEW 工具编译算法代码并将其下载到 Renesas RX62N 设备的闪存中,并使用其开发板,我们测试了 CPU 带宽和代码大小的完整算法。结果如表 5 所示。对于 CPU 带宽,实现了近 35% 的改进,而代码大小减少了近 45%。总的来说,我们发现 FPU 使矢量控制变换以及位置和速度估计更容易和更准确。需要注意的是,RX62N 的 FPU 非常简单,只有 8 条指令,但它对电机控制算法的影响非常显着。

表 5:整体算法的测试比较
支持 Renesas FPU 的 MCU
让我们仔细看看我们测试中使用的 Renesas MCU 可用的资源。Renesas RX600 CPU 架构是一种复杂指令集计算 (CISC) 架构,具有 16 个通用 32 位寄存器和 9 个控制寄存器来处理快速中断。此外,该架构还具有内存保护单元、片上调试、DSP 指令(48 位和 80 位 MAC、桶形移位器)和硬件除法器。
RX600 内核具有符合 IEE-754 标准的单精度 32 位浮点单元。FPU 紧密连接到共享相同寄存器的 CPU(参见图 2)。竞争架构必须经过额外的步骤,首先将操作数值加载到通用寄存器中,然后将它们移动到浮点的专用寄存器中。浮点单元的结果随后被移动到专用寄存器,然后返回到通用寄存器存储到内存中。

图 2:RX600 FPU 实现使用通用寄存器来执行所有指令
与早期的 CISC CPU 相比,RX CPU 实现了大约四倍的算术计算性能,即 165 DMIPS(Dhrystone 7 MIPS)。特别是,32 位乘法最多可以在一个周期内执行(除法需要 2 到 8 个周期),因此可以更快地执行电机控制的矢量计算。一旦在 PC 上开发了电机控制算法,使用 Matlab 等高级抽象工具,它们就可以直接移植到 FPU 中,以便在硬件平台上进行进一步测试和检查。
概括
总而言之,当将浮点硬件单元添加到 CPU 内核以内联执行指令时,可为电机控制等嵌入式应用带来更高的性能和更简单的软件开发。性能测试生成的数据用于将此实现与使用定点 MCU 的设计进行比较。
这些实验表明,FPU SVC 的 CPU 带宽使用与定点 SVC 相比显着降低,并且 FPU SVC 的代码大小是定点 SVC 的一半,这使得使用具有更小的闪存尺寸,从而降低了成本。
因此,数据表明,在 MCU 中添加 FPU 可实现计算更先进的算法,有助于提高电机控制效率并节省能源,同时扩展系统功能。
更重要的是,从模拟中创建代码很容易,因为所有代码都是用 C 编写的。当程序员完成代码并且系统工程师正在查看代码时,很容易理解代码以及更改的影响变量值。
-
利用先进的MCU技术实现电机高效率控制2011-07-27 0
-
提高MCU设计效率的方法2022-02-08 0
-
使用智能外设提高CPU效率2017-06-09 676
-
三相电机控制:瑞萨RX系列单片机浮点优于固定点2017-07-19 1107
-
电机与DSP控制相结合是电机发展重要方向2018-11-29 497
-
32位RX66T系列MCU 优化工业、家电和机器人设备的电机控制2019-01-18 3262
-
RX62T微控制器和功率器件相结合的电机控制解决方案2021-06-22 5520
-
通过修改电源选项,提高cpu使用效率。2022-01-05 1151
-
基于RX13T电机控制MCU方案2022-07-01 1355
-
MCU中如何通过外设提高CPU效率2022-08-09 1694
-
单个MCU即可实现多电机控制!基于RX72T的4电机控制示例2023-10-25 695
-
32位高性能电机控制MCU-RX66T/RX72T产品介绍2023-09-18 1825
-
32位高性能电机控制MCU-RX66T/RX72T产品介绍(1)2023-10-26 1026
-
基于瑞萨电子RX MCU的电机控制解决方案2024-12-10 316
全部0条评论

快来发表一下你的评论吧 !
