

知识图谱自动化构建的探索与挑战
电子说
描述
知识图谱自动化构建的探索与挑战|论文分享
达观数据
知识图谱的自动化构建是知识图谱中具有极强挑战性且巨大应用价值的技术方向。就实体抽取技术,达观数据副总裁、上海市人工智能技术标准委员会委员王文广提到“狭义的实体抽取,即命名实体识别(NER)技术发展至今已较为成熟,能够很好地抽取出人名、地名、机构名等少数类型的实体。但在知识图谱实际应用中,则需要抽取出各式各样各不相同的广义实体,比如金融业中的产品名称、品牌名、业务名、风险提示、观点等,制造业中的失效模式、失效现象、工艺、设备、零部件、物料、方法、故障原因、改善措施等,商业中的产品、功能、特点、适合人群、搭配方法等等。抽取出这些广义实体的挑战巨大。”关系抽取技术也同样问题多挑战大,已有关系抽取大多基于实体对之间共现,而现实复杂的场景中,实体对共现既可能不存在任何关系,可能存在万千种的关系,这就造成了关系抽取的难题。此外,在知识图谱构建中,还涉及实体消歧、实体融合等方面的技术要求。
除了技术发展本身并不成熟之外,在实际场景中还遇到样本少的问题。在真实落地的项目或产品中, 往往存在标注样本少的问题,其原因即可能是标注成本高导致样本少,也可能是本身样本就少,无法获得大规模的标注样本。这方面王文广深有体会,他提到“在很多场景下,总的文档数量有几千或几万份,对于具体某些类型的实体或关系来说则文档数量更少。在这种情况下要做好知识图谱的构建,是极大的挑战,也是在实际落地中必须综合使用十八般武器,逢山开路遇水搭桥,使用最新的技术结合业务经验、专家规则等来解决这些问题。”
为了促进知识图谱自动化构建技术的进一步发展,达观数据在CCKS2020(2020全国知识图谱与语义计算大会)组织了金融研报知识图谱的自动化构建的算法竞赛。竞赛选择了样本丰富但复杂度较高的金融研报文档作为知识的来源,根据金融投研领域常见的需求,设计了简化版的知识图谱模式,并标注了大规模的金融研报知识图谱数据集FR2KG。竞赛任务从预定义的知识图谱模式和少量的种子知识图谱开始,从非结构化的金融研报文本中抽取出符合知识图谱模式的实体、关系和属性值, 并进行适当的实体消歧和实体融合,构建出知识图谱,并使用FR2KG来评估竞赛参赛队伍所提交的结果。
金融研报是各类金融研究结构对宏观经济、金融、行业、产业链以及公司的研究报告,是金融行业中最为复杂、多样的文档。报告通常是专业人员撰写,对宏观、行业和公司的数据信息搜集全面、研究深入,质量高,内容可靠。报告内容往往包含产业、经济、金融、政策、社会等多领域的数据与知识,是构建行业知识图谱非常关键的数据来源。另一方面,由于研报本身所容纳的数据与知识涉及面广泛,专业知识众多,不同的研究结构和专业认识对相同的内容的表达方式也会略有差异。这些特点导致了从研报自动化构建知识图谱困难重重,解决这些问题则能够极大促进自动化构建知识图谱方面的技术进步。同时所构建的图谱在大金融行业、监管部门、政府、行业研究机构和行业公司等应用非常广泛,如风险监测、智能投研、智能监管、智能风控等,具有巨大的学术价值和产业价值。
数据集
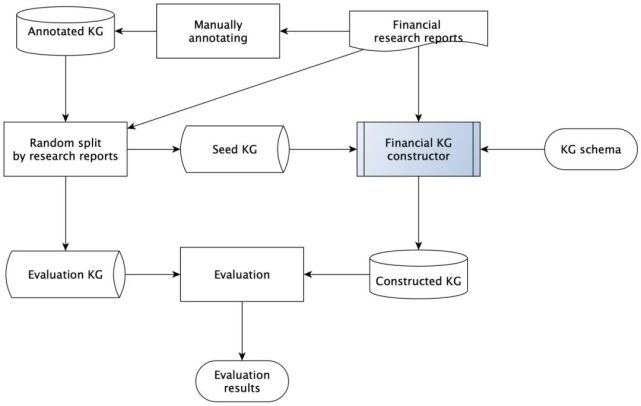
达观数据所构建的大规模金融研报知识图谱数据集FR2KG是用于评测知识图谱自动化构建技术的专业数据集,是当前最大规模的中文金融研报知识图谱。下图是数据集构建过程示意图
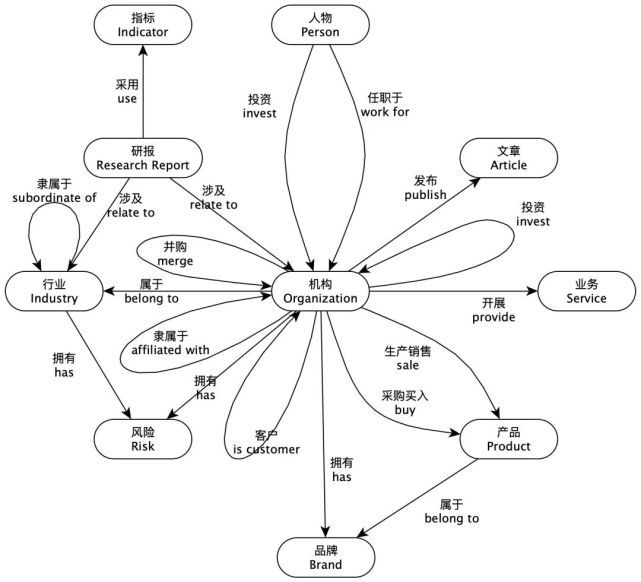
FR2KG的知识图谱模式包含10个实体类型,19个关系类型和6种属性,如下图所示。
构建好的金融研报知识图谱数据集FR2KG包含17,799实体,26,798关系三元组,1,328属性三元组,SeedKG和EvaluationKG的数据情况如下图所示。
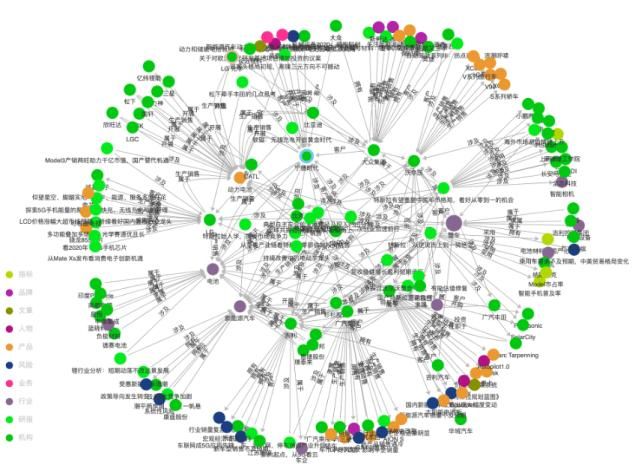
下图是数据集的样例,使用达观数据渊海知识图谱平台可视化:
目前数据集已经发布在SCIDB和OpenKG上,欢迎大家前往下载。在使用数据集进行研究时请引用本论文。
文章:Data Set and Evaluation of Automated Construction of Financial Knowledge Graph
作者:王文广,徐永林、杜春辉、陈运文、王逸捷、文辉
引用: Wang, W.G., et al.: Data set and evaluation of automated construction of financial knowledge graph. Data Intelligence 3(3), 418-443 (2021). doi: 10.1162/dint_a_00108
竞赛技术回顾
本次评测一共有740个队伍报名,其中F1分数最高的18支队伍中,有3支队伍来自企业,10支队伍来自高校,3支队伍高校和企业的组合,另外2支队伍未透露相关信息。本次评测的top5队伍都梳理并提交了他们所使用的方法的简要说明,下文对这些方法和说明进行分析总结。
所有队伍都使用了规则或者labelling function来生产训练样本,只有一个队伍在自动生成样本之外,又额外人工标注了20份的研报来作为补充和验证的训练样本。
所有队伍在实体抽取中都使用了基于BERT的模型,并且在模型之外也都使用了基于规则的方法来对特定的实体类型进行补充。
在关系和属性抽取方面,所有的队伍都使用了基于共现的方法,共现是远程监督的基本假设,也就是说,当两个实体共同出现在一个较短的一段文本时,即可假设它们存在符合相应的关系。在基于共现的假设之上,三支队伍使用了规则来判断是否真正存在这种关系,另外两只队伍使用了基于BERT的模型来对关系进行分类。
其中一支队伍使用了聚类的方法来将相似或相同主题的研报给聚在一起,对研报进行了预处理。
知识图谱自动化构建的挑战
从本次基于知识图谱模式的自动化构建知识图谱评测的结果来看,单纯使用算法来构建完全自动化地构建知识图谱,尚存在较多挑战,这里总结了一些具有相当挑战性的课题和研究方向:
在给定知识图谱模式和种子知识图谱来自动化的构建知识图谱上,现有的方法效果都不太好,如何实现端到端或者多步的框架实现知识图谱的完全自动化构建是值得继续探索的。
通过知识图谱及其对应的Schema如何实现自动化标注语料是一个值得研究的课题,能够实现高精度的自动化标注语料可以带来更好的抽取模型。此外,自动化标注语料方面的评测也是一件非常有意义的事情。
实体抽取方面,评测的优秀选手都使用了基于BERT的模型,再加上基于规则的方法来实现,在这种真实的场景且计算力资源受限的情况下,如何在少量语料的情况下实现高精度的抽取。
关系和属性抽取与识别上,目前集中在采用短文本内共现并过滤的方法来实现,这极大的依赖于实体抽取的F1分数,高precision和高recall的实体抽取决定了关系和属性抽取有好的效果。那么如何在噪声较多,即不那么高的情况下来实现好的关系和属性抽取?
本次评测没有看到使用端到端的实现实体和关系联合抽取的模型,可能的原因是实体和关系类型较多且没有大量的语料,那么在这种情况下如何开发出端到端的模型也是非常具有挑战性的课题。
当Schema的规模进一步扩大时,比如50种实体类型,数百种的实体属性和实体间的关系,对这样的知识图谱研究其自动化构建是一个兼具挑战性与现实意义的课题。
多语言的知识图谱自动化构建技术的研究。本次评测集中在中文,以及中文中存在的少量英文的情况,特别的,没有涉及到多语言之间实体融合的情况。但在真实场景下,多语言语料以及构建多语言图谱是非常重要的。这涉及了多方面的内容,包括多语言的实体、关系和属性的抽取,多语言之间实体的融合等等方面技术的研究。同时,组织多语言知识图谱自动化构建方面的评测也是非常有意义的事情。
本次评测中隐含着少量实体的消歧与融合,这块没有显性的进行评测,未来可以将这块明确的表达出来,以促进相关领域的研究。
-
NLPIR大数据知识图谱完美展现文本数据内容2019-07-01 0
-
知识图谱相关应用2019-08-22 0
-
分享自底向上构建知识图谱的过程2019-09-29 0
-
KGB知识图谱基于传统知识工程的突破分析2019-10-22 0
-
KGB知识图谱技术能够解决哪些行业痛点?2019-10-30 0
-
知识图谱的三种特性评析2019-12-13 0
-
KGB知识图谱通过智能搜索提升金融行业分析能力2020-06-22 0
-
各种知识图谱精化方法,为国内同行介绍本领域的最新研究成果2018-09-23 6888
-
知识图谱划分的相关算法及研究2021-03-18 880
-
知识图谱在工程应用中的关键技术、应用及案例2021-03-30 1021
-
通用知识图谱构建技术的应用及发展趋势2021-04-14 915
-
数学课程知识图谱构建研究应用综述2021-04-22 836
-
知识图谱Knowledge Graph构建与应用2022-09-17 651
-
知识图谱:知识图谱的典型应用2022-10-18 1970
-
基于本体的金融知识图谱自动化构建技术2022-11-24 1137
全部0条评论

快来发表一下你的评论吧 !
