

如何使用Python进行数学建模
嵌入式技术
描述
Python 是一种易于学习又功能强大的编程语言。它提供了高效的高级数据结构,还能简单有效地面向对象编程。Python 优雅的语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的理想语言。
Python 解释器及丰富的标准库,提供了适用于各个主要系统平台的源码或机器码,这些可以到 Python 官网:
https://www.python.org/
Python 解释器易于扩展,可以使用 C 或 C++(或者其他可以从 C 调用的语言)扩展新的功能和数据类型。Python 也可用作可定制化软件中的扩展程序语言。
简单来说,易用,需要深入理解和记忆的东西不需要很多,其次库多,可以让编写者集中精神研究逻辑。其次就是免费了,使用起来没有什么成本。最后就是它真的很火,侧面的好处就是别人遇到的问题早就被解决,生态良好。
我们经常说,Python一行胜千语:
是因为Python 是一种解释型语言,在程序开发阶段可以为你节省大量时间,因为不需要编译和链接。解释器可以交互式使用,这样就可以方便地尝试语言特性,写一些一次性的程序,或者在自底向上的程序开发中测试功能。它也是一个顺手的桌面计算器。
Python 程序的书写是紧凑而易读的。Python 代码通常比同样功能的 C,C++,Java 代码要短很多,有如下几个原因:
1.高级数据类型允许在一个表达式中表示复杂的操作;
2.代码块的划分是按照缩进而不是成对的花括号;
3.不需要预先定义变量或参数。
也就是说,样板代码变少了,一些独特的语法糖也让编写的效率更高。
Python可以以很多的形式被运行,一种是命令行终端,一种是脚本的样子。
python -c command [arg] ...
其中 command 要换成想执行的指令,就像命令行的 -c 选项。由于 Python 代码中经常会包含对终端来说比较特殊的字符,通常情况下都建议用英文单引号把 command 括起来。
有些 Python 模块也可以作为脚本使用。可以这样输入:
python -m module [arg] ...
这会执行 module 的源文件,就跟你在命令行把路径写全了一样。
在运行脚本的时候,有时可能也会需要在运行后进入交互模式。这种时候在文件参数前,加上选项 -i 就可以了。
如果可能的话,解释器会读取命令行参数,转化为字符串列表存入 sys 模块中的 argv 变量中。执行命令:
import sys
你可以导入这个模块并访问这个列表。这个列表最少也会有一个元素;如果没有给定输入参数,sys.argv[0] 就是个空字符串。如果给定的脚本名是 '-' (表示标准输入),sys.argv[0] 就是 '-'。使用 -c command 时,sys.argv[0] 就会是 '-c'。如果使用选项 -m module,sys.argv[0] 就是包含目录的模块全名。在 -c command 或 -m module 之后的选项不会被解释器处理,而会直接留在 sys.argv 中给命令或模块来处理。
有些东西不得不说,因为它时时刻刻存在,所以请原谅我的啰嗦。
最后讲一下编码信息,你看到的程序其实和你看到的小说没有什么区别,都是一堆0101010,但是为啥0101010就变成了你看到的字符,其实是因为编码的缘故。
在编辑器的右下角,大概率都会看到这个
默认情况下,Python 源码文件以 UTF-8 编码方式处理。在这种编码方式中,世界上大多数语言的字符都可以同时用于字符串字面值、变量或函数名称以及注释中——尽管标准库中只用常规的 ASCII 字符作为变量或函数名,而且任何可移植的代码都应该遵守此约定。要正确显示这些字符,你的编辑器必须能识别 UTF-8 编码,而且必须使用能支持打开的文件中所有字符的字体。
如果不使用默认编码,要声明文件所使用的编码,文件的 第一 行要写成特殊的注释。语法如下所示:
# -*- coding: encoding -*-
其中 encoding 可以是 Python 支持的任意一种 codecs。
比如,要声明使用 Windows-1252 编码,你的源码文件要写成:
# -*- coding: cp1252 -*-
关于 第一行 规则的一种例外情况是,源码以 UNIX "shebang" 行 开头。这种情况下,编码声明就要写在文件的第二行。例如:
#!/usr/bin/env python3# -*- coding: cp1252 -*-
这可能会回答,为什么代码一开始会有一行奇怪的东西。
本来是想直接给大家写一些教程的,但是官网写的真的太好啦!
https://docs.python.org/zh-cn/3.8/tutorial/introduction.html
大家直接去看。
字符串是可以被 索引 (下标访问)的,第一个字符索引是 0。单个字符并没有特殊的类型,只是一个长度为一的字符串:
>>>>>> word = 'Python'>>> word[0] # character in position 0'P'>>> word[5] # character in position 5'n'
索引也可以用负数,这种会从右边开始数:
>>>>>> word[-1] # last character'n'>>> word[-2] # second-last character'o'>>> word[-6]'P'
注意 -0 和 0 是一样的,所以负数索引从 -1 开始。
除了索引,字符串还支持 切片。索引可以得到单个字符,而 切片 可以获取子字符串:
>>>>>> word[0:2] # characters from position 0 (included) to 2 (excluded)'Py'>>> word[2:5] # characters from position 2 (included) to 5 (excluded)'tho'
注意切片的开始总是被包括在结果中,而结束不被包括。这使得 s[:i] + s[i:] 总是等于 s
>>>>>> word[:2] + word[2:]'Python'>>> word[:4] + word[4:]'Python'
切片的索引有默认值;省略开始索引时默认为0,省略结束索引时默认为到字符串的结束:
>>>>>> word[:2] # character from the beginning to position 2 (excluded)'Py'>>> word[4:] # characters from position 4 (included) to the end'on'>>> word[-2:] # characters from the second-last (included) to the end'on'
您也可以这么理解切片:将索引视作指向字符 之间 ,第一个字符的左侧标为0,最后一个字符的右侧标为 n ,其中 n 是字符串长度。例如:
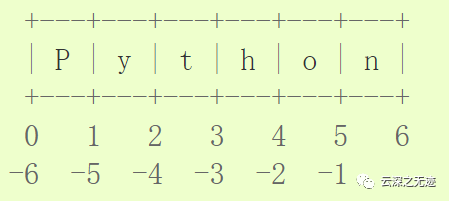
第一行数标注了字符串 0...6 的索引的位置,第二行标注了对应的负的索引。那么从 i 到 j 的切片就包括了标有 i 和 j 的位置之间的所有字符。
对于使用非负索引的切片,如果索引不越界,那么得到的切片长度就是起止索引之差。例如, word[1:3] 的长度为2。
试图使用过大的索引会产生一个错误:
>>>>>> word[42] # the word only has 6 charactersTraceback (most recent call last): File "", line 1, inIndexError: string index out of range
但是,切片中的越界索引会被自动处理:
>>>>>> word[4:42]'on'>>> word[42:]''
Python 中的字符串不能被修改,它们是 immutable 的。因此,向字符串的某个索引位置赋值会产生一个错误:
>>>>>> word[0] = 'J'Traceback (most recent call last): File "", line 1, inTypeError: 'str' object does not support item assignment>>> word[2:] = 'py'Traceback (most recent call last): File "", line 1, inTypeError: 'str' object does not support item assignment
如果需要一个不同的字符串,应当新建一个:
>>>>>> 'J' + word[1:]'Jython'>>> word[:2] + 'py''Pypy'
记不住?string就是个不可变的列表,完事儿了。
老师!等下!
什么是列表啊?
Python 中可以通过组合一些值得到多种复合数据类型。其中最常用的列表 ,可以通过方括号括起、逗号分隔的一组值(元素)得到。一个 列表 可以包含不同类型的元素,但通常使用时各个元素类型相同:

粗糙点的话,这就介绍完了
但是为了完整性,这里要补一些,Python 编程语言中有四种集合数据类型:
列表(List)是一种有序和可更改的集合。允许重复的成员。
元组(Tuple)是一种有序且不可更改的集合。允许重复的成员。
集合(Set)是一个无序和无索引的集合。没有重复的成员。
词典(Dictionary)是一个无序,可变和有索引的集合。没有重复的成员。
选择集合类型时,了解该类型的属性很有用。为特定数据集选择正确的类型可能意味着保留含义,并且可能意味着提高效率或安全性。
上面的都可以叫数据容器,也就是放东西的罐子。我们要对它动手动脚的,也就是要操作它。无外乎2种操作:取一些(看看里面有啥),改一些(比如调整顺序,删除)。
再总结一下,就是你做完操作,有没有对这个原来的东西有副作用的。这样的抽象模型是理解对数据操作的必由之路。
按说看懂了吧?
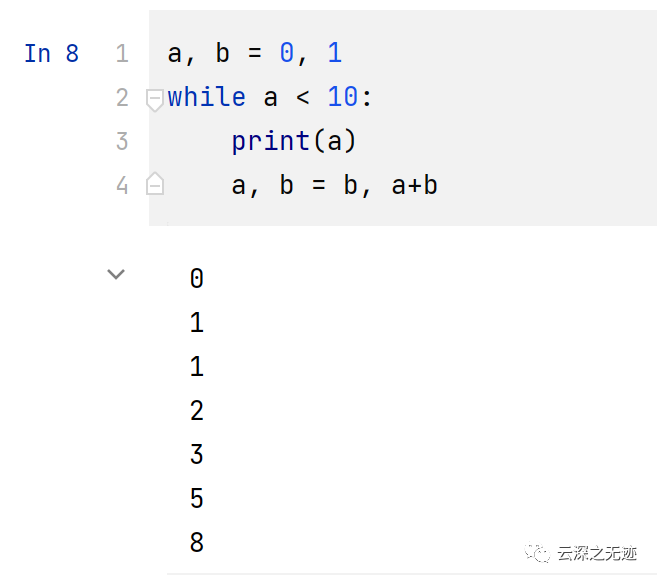
我假定你有其它语言的经验,这里就直接开始了
我们来想想,上面的代码做了什么?初始化要使用的变量,开始操作变量,在一个合适的时机输出结果。
第一行含有一个多重赋值: 变量 a 和 b 同时得到了新值 0 和 1. 最后一行又用了一次多重赋值, 这展示出了右手边的表达式,在任何赋值发生之前就被求值了。右手边的表达式是从左到右被求值的。
while 循环只要它的条件(这里指:a < 10)保持为真就会一直执行。Python 和 C 一样,任何非零整数都为真;零为假。这个条件也可以是字符串或是列表的值,事实上任何序列都可以;长度非零就为真,空序列就为假。在这个例子里,判断条件是一个简单的比较。
标准的比较操作符的写法和 C 语言里是一样:< (小于)、 > (大于)、 == (等于)、 <= (小于或等于)、 >= (大于或等于)以及 != (不等于)。
循环体是缩进的 :缩进是 Python 组织语句的方式。在交互式命令行里,你得给每个缩进的行敲下 Tab 键或者(多个)空格键。实际上用文本编辑器的话,你要准备更复杂的输入方式;所有像样的文本编辑器都有自动缩进的设置。交互式命令行里,当一个组合的语句输入时, 需要在最后敲一个空白行表示完成(因为语法分析器猜不出来你什么时候打的是最后一行)。注意,在同一块语句中的每一行,都要缩进相同的长度。
print() 函数将所有传进来的参数值打印出来. 它和直接输入你要显示的表达式(比如我们之前在计算器的例子里做的)不一样, print() 能处理多个参数,包括浮点数,字符串。字符串会打印不带引号的内容, 并且在参数项之间会插入一个空格, 这样你就可以很好的把东西格式化。
缩进这个事情,其实Python的创始人说,没有那么夸张,只是必要的缩进会对阅读代码有益,现在看到是比较糟糕的设计,最好还是使用括号来匹配。

end参数可以取消输出
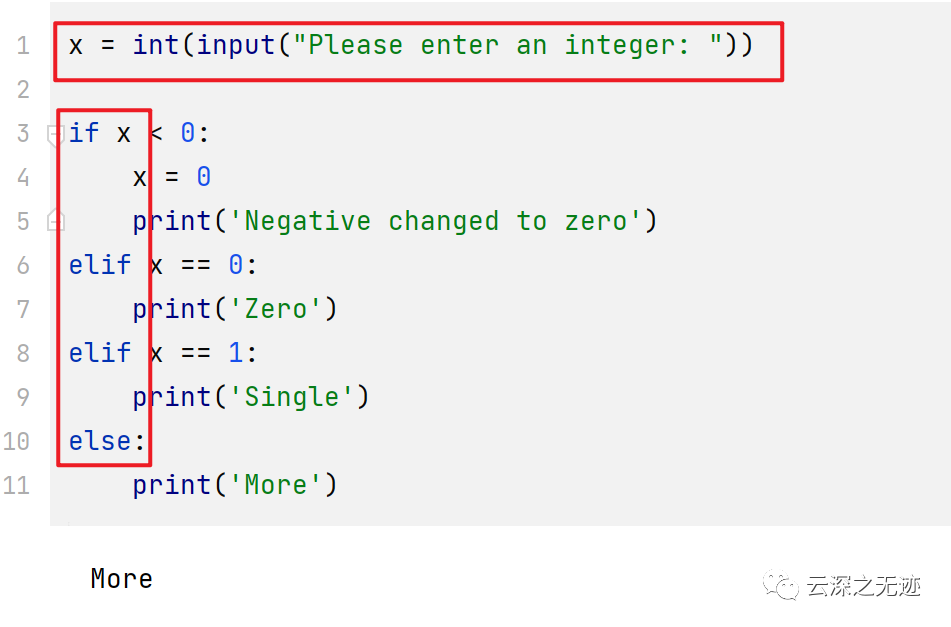
再看看分支结构,分支结构是赋予计算机判断能力的本源动力
可以有零个或多个 elif 部分,以及一个可选的 else 部分。关键字 'elif' 是 'else if' 的缩写,适合用于避免过多的缩进。一个 if ... elif ... elif ... 序列可以看作是其他语言中的 switch 或 case 语句的替代。再最新的3.10版本已经有了switch语句,但是太新的特性了,不建议使用。
Python 中的 for 语句与你在 C 或 Pascal 中所用到的有所不同。Python 中的 for 语句并不总是对算术递增的数值进行迭代(如同 Pascal),或是给予用户定义迭代步骤和暂停条件的能力(如同 C),而是对任意序列进行迭代(例如列表或字符串),条目的迭代顺序与它们在序列中出现的顺序一致。
words = ['cat', 'window', 'defenestrate']for w in words: print(w, len(w))
在遍历同一个集合时修改该集合的代码可能很难获得正确的结果。通常,更直接的做法是循环遍历该集合的副本或创建新集合:
for user, status in users.copy().items(): if status == 'inactive': del users[user]
# Strategy: Create a new collectionactive_users = {}for user, status in users.items(): if status == 'active': active_users[user] = status
for 语句用于对序列(例如字符串、元组或列表)或其他可迭代对象中的元素进行迭代:
for_stmt ::= "for" target_list "in" expression_list ":" suite ["else" ":" suite]
表达式列表会被求值一次;它应该产生一个可迭代对象。系统将为 expression_list 的结果创建一个迭代器,然后将为迭代器所提供的每一项执行一次子句体,具体次序与迭代器的返回顺序一致。每一项会按标准赋值规则 (参见 赋值语句) 被依次赋值给目标列表,然后子句体将被执行。当所有项被耗尽时 (这会在序列为空或迭代器引发 StopIteration 异常时立刻发生),else 子句的子句体如果存在将会被执行,并终止循环。
第一个子句体中的 break 语句在执行时将终止循环且不执行 else 子句体。第一个子句体中的 continue 语句在执行时将跳过子句体中的剩余部分并转往下一项继续执行,或者在没有下一项时转往 else 子句执行。
for 循环会对目标列表中的变量进行赋值。这将覆盖之前对这些变量的所有赋值,包括在 for 循环体中的赋值:
for i in range(10): print(i) i = 5
目标列表中的名称在循环结束时不会被删除,但如果序列为空,则它们根本不会被循环所赋值。提示:内置函数 range() 会返回一个可迭代的整数序列,适用于模拟 Pascal 中的:
for i := a to b do
这种效果;例如 list(range(3)) 会返回列表 [0, 1, 2]。
当序列在循环中被修改时会有一个微妙的问题(这只可能发生于可变序列例如列表中)。会有一个内部计数器被用来跟踪下一个要使用的项,每次迭代都会使计数器递增。当计数器值达到序列长度时循环就会终止。这意味着如果语句体从序列中删除了当前(或之前)的一项,下一项就会被跳过(因为其标号将变成已被处理的当前项的标号)。类似地,如果语句体在序列当前项的前面插入一个新项,当前项会在循环的下一轮中再次被处理。这会导致麻烦的程序错误,避免此问题的办法是对整个序列使用切片来创建一个临时副本:
for x in a[:]: if x < 0: a.remove(x)
一般重复语句主要有两种类型的循环:
1)重复一定次数的循环,这个称谓计数循环。
比如打印1到99之间所有的整数,就是重复99次执行print( )指令。
2)重复直至发生某种情况时结束的循环,成为条件循环。也就是说只有条件为True,循环才会一直持续下去。
比如猜数字,如果没猜中就继续猜,如果猜中了就退出。
循环的知识太多了,其实就是简简单单的重复,但是最难的就是什么时候停下来再做别的事情。
在C语言里面的循环大多数是小于一个什么数字,也就是变相的输出了一些算数级数,在Python里面有着更加优雅的写法。
for i in range(5): print(i)
给定的终止数值并不在要生成的序列里;range(10) 会生成10个值,并且是以合法的索引生成一个长度为10的序列。range也可以以另一个数字开头,或者以指定的幅度增加(甚至是负数;有时这也被叫做 '步进')
但是更加的常见一种用法是:
a = ['Mary', 'had', 'a', 'little', 'lamb']for i in range(len(a)): print(i, a[i])
我相信你一定会看到这个写法。
当然Python里面还有别的写法:

函数返回一个枚举对象。iterable 必须是一个序列,或 iterator,或其他支持迭代的对象。enumerate() 返回的迭代器的 __next__() 方法返回一个元组,里面包含一个计数值(从 start 开始,默认为 0)和通过迭代 iterable 获得的值。

当然我们这样也可以实现,但是有现成的干嘛不用
range() 所返回的对象在许多方面表现得像一个列表,但实际上却并不是。此对象会在你迭代它时基于所希望的序列返回连续的项,但它没有真正生成列表,这样就能节省空间。
我们称这样对象为 iterable,也就是说,适合作为这样的目标对象:函数和结构期望从中获取连续的项直到所提供的项全部耗尽。我们已经看到 for 语句就是这样一种结构。
关于迭代器就不说了,它就是一种协议而已。
-
数学建模与实验2008-09-24 0
-
什么是数学建模,怎样建立数学模型2009-09-15 0
-
数学建模资料2012-04-29 0
-
matlab语言与数学建模2012-05-04 0
-
数学建模2012-07-06 0
-
超好的数学建模教程!!!!2013-06-12 0
-
求数学建模论文2013-07-31 0
-
浅析Python建模库2019-10-22 0
-
如何利用Python进行数据分析2020-04-23 0
-
数学建模概论2009-09-15 464
-
数学建模论文基本格式2016-02-23 659
-
数学建模参考文献2016-08-25 1887
-
MATLAB数学建模资料012021-10-08 612
-
MATLAB数学建模资料022021-10-08 636
-
Python建模算法与应用2024-07-24 528
全部0条评论

快来发表一下你的评论吧 !
