

关于AE、OE、SC的序列标注问题
描述
给定句子,定义三个AE、OE、SC的序列标注问题:
AE 目的是预测一个tag序列(和原始句子等长),其中 分别表示 begining of, inside of, outside of 一个aspect term。
OE 目的是预测一个tag序列(和原始句子等长),其中分别表示 begining of, inside of, outside of 一个opinion term。
SC 目的是预测一个tag序列(和原始句子等长),其中分别表示每个单词的极性。
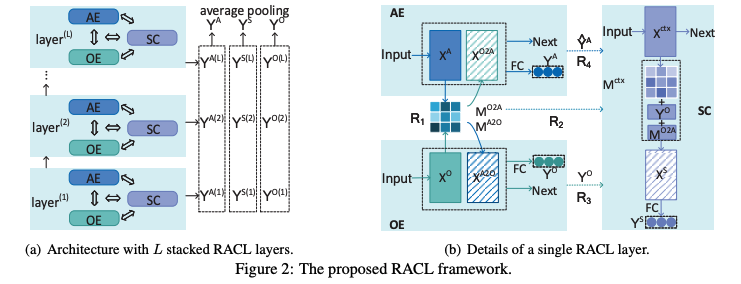 左图是全框架,右图是一个RACL的具体结构
左图是全框架,右图是一个RACL的具体结构
结构解析
1.输入部分是词嵌入经过一个全连接层得到
2.首先进行子任务私有特征的编码,得到面向三个子任务的特征、、
利用卷积得到AE-oriented features 和OE-oriented features ,考虑到的是这两个任务与词的临近词相关性很大。
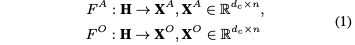
为了得到SC-oriented features
首先从中利用CNN编码上下文特征,然后将共享向量视为query方面,并用注意力机制计算query和上下文特征之间的语义关系,得到(利用的是实现的表达)
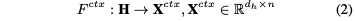
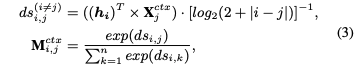
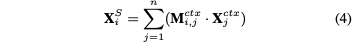
3.Propagating Relations for Collaborative Learning

是AE和OE之间的双向关系,是OE向AE传递的部分,计算方法是和交互,利用表达。然后将交互部分同原来的面向AE的特征拼接在一起,经过一个线性层和softmax就可以得到任务AE的分类结果。同理得到任务OE的分类结果。
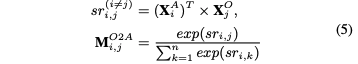
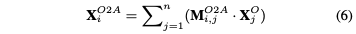
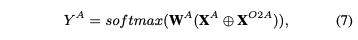
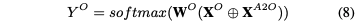
此外,一个单词不可以既是方面词又是情感词,因此加入了合页损失作为正则项来约束和
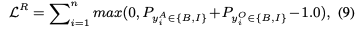
R2是SC和之间的三元关系。注意直接使用注意力权重来相加的,而不是在最后阶段。
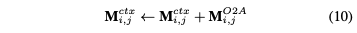
R3是SC和OE之间的双向关系,这表明,在对情感极性进行预测时,需要对抽取出的观点术语多加关注。为了建模R3,采用和R2同样的方式,也就是对SC中的利用生成的 tag序列进行更新,如下:
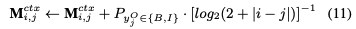
这样的话情感词在注意力机制中可以得到更大的权重,从而有利于情感分类。
得到上述方式完成交互后的后,我们可以按照式子4重新计算面向SC任务的特征,然后我们将和拼接在一起作为最后的SC的特征,并将它们经过一个全连接层后去预测方面极性。
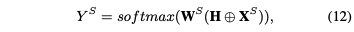
4.Stacking RACL to Multiple Layers以上是一个RACL模块的输出,本实验堆叠了多个模块。具体来说,我们首先编码第一层特征,,,在第二层将这些特征输入到SC,AE和OE去生成,,。以此类推可以将RACL堆叠到L层。最后将各层的最终预测结果进行平均池化的操作
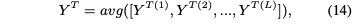
这种shortcut-like的架构可以促进低层中的功能具有意义和信息量,反过来这也有助于高层做出更好的预测。
损失函数
最终RACL总的损失的 L 是所有子任务的损失之和加上正则项的损失,也就是,其中是系数,.
方法比较和Case分析
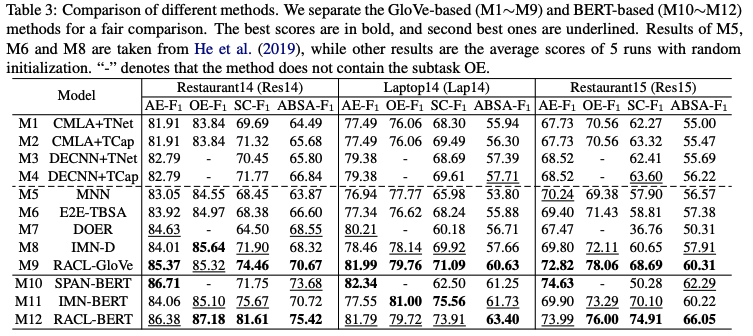
和不同的历史方法作比较:
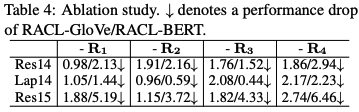
关于本文提出的方法的简单变种的消融实验:
超参和的影响: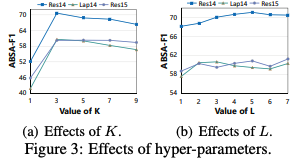
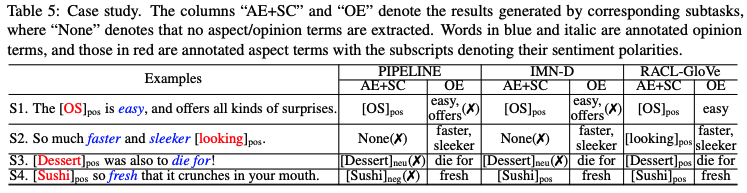
Case分析:
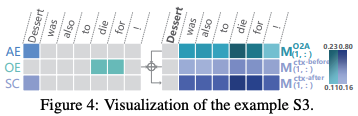
关于上面的可视化分析:
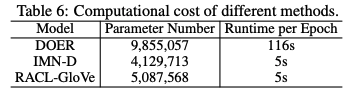
最后就是不同方法的计算量分析:
-
有没有关于SC块工作的视频?2019-05-31 0
-
如何绑定原理图中的标注?2019-09-26 0
-
CAD中怎么批量标注坐标?CAD批量标注坐标2021-06-06 0
-
关于c语言序列化和反序列化的知识点看完你就懂了2021-10-15 0
-
基于无向图序列标注模型的中文分词词性标注一体化系统2010-03-06 713
-
新唐科技NUC125SC2AE单片机简介2020-02-26 1089
-
新唐科技NUC121SC2AE单片机简介2020-02-26 2400
-
新唐科技M031SC2AE控制器介绍2019-11-28 1912
-
NLP:序列标注2021-01-13 2564
-
将对话中的情感分类任务建模为序列标注 并对情感一致性进行建模2021-01-18 3111
-
基于双向长短时记忆的序列标注神经网络模型2021-06-03 583
-
CAT-OE4-SD69 CAT-OE4-SD69 功率继电器2021-07-24 224
-
CAT-OE4-EF1 CAT-OE4-EF1 功率继电器2021-08-03 211
-
基于序列标注的实体识别所存在的问题2022-07-28 1815
-
基于BIO序列标注的方法和基于片段的图解析方法2022-10-21 2928
全部0条评论

快来发表一下你的评论吧 !
