

基于重构的方法存在的“恒等映射”问题
描述
Introduction
异常检测已经取得了非常突出的进展。考虑到异常的多样性,通常的异常检测方案是首先拟合出正常样本的分布,之后检测该分布之外的离群点作为异常。因此,异常检测需要学习出一个非常紧凑的正常样本的边界 (下图a)。出于这种目的,当前所有的异常检测方法都只能用一个模型解决一个类别 (下图c)。但是,这种“一个模型只处理一个类别”的separate setting是十分耗费储存空间的,并且无法处理正常样本具有一定多样性的场景 (比如,一种物体有多种正常的型号)。

传统的separate setting V.S. our unified setting
我们致力于解决一个更困难的unified setting,那就是用一个模型解决所有类别的异常检测 (上图d)。这就需要所有类别共享相同的分类边界 (上图b),因此,如何拟合出多类正常样本的分布是十分重要的。
基于重构的方法是一种常用的异常检测方法。这种方法在正常样本上训练一个重构模型,并假设重构只能在正常样本上成功,对于异常样本将会具有较大的重构误差。因此,重构误差可以作为异常评分。但是,基于重构的方法会遇到“恒等映射”的问题。所谓“恒等映射”指的是,虽然重构模型是在正常样本上训练的,其遇到异常样本同样会重构成功。这使得正常样本和异常样本的重构误差都很小,难以被区分开来。更重要的是,相比于传统的separate setting,在unified setting下,正常样本的分布更加复杂,这加剧了“恒等映射”的问题 (详见paper的实验及分析)。
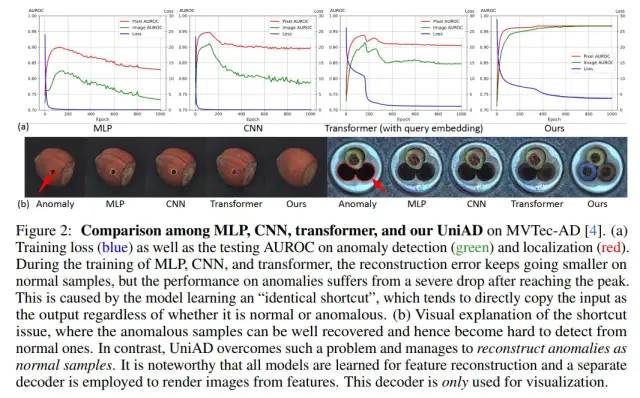
MLP, CNN, transformer都会遇到“恒等映射”的问题
我们首先follow了特征重构 [2] 的框架,并测试了3种通用的网络架构MLP、CNN、transformer (上图)。我们发现,3种网络结构都会遇到“恒等映射”的问题。这使得在训练过程中,重构的loss (上图蓝线) 可以降到非常小,但其检测性能 (上图绿线) 和定位性能 (上图红线) 甚至会随着loss的下降而下降。这证明了“恒等映射”的问题,即,可以非常好地完成重构,但却无法区分正常和异常。
因此,我们希望,从重构网络的结构设计上彻底解决“恒等映射”问题。具体的,我们提出了三个创新点,构成了我们的UniAD网络。
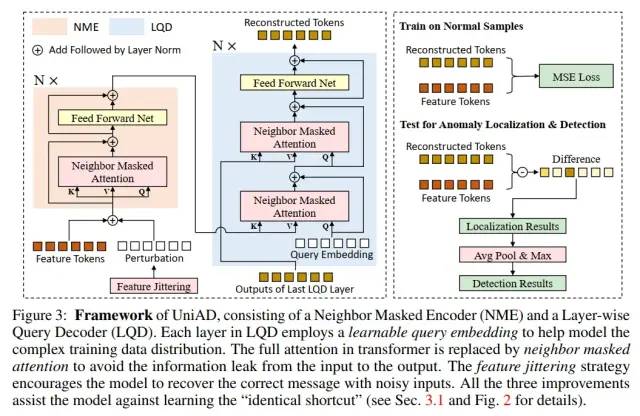
UniAD网络结构
创新点一:Layer-wise Query Embedding
我们观察到,transformer中“恒等映射”的问题比MLP和CNN要轻微一些。第一,在transformer中,loss并不会完全降低到0。第二,在transformer中,检测性能和定位性能的下降幅度远小于MLP和CNN。因此,我们认为transformer中必然存在一种结构可以抑制“恒等映射”。经过数学分析和消融实验,我们认为,具有query embedding的attention可以抑制“恒等映射” (分析与实验详见paper)。
但是,现有的transformer网络,一些不具有query embedding (如类似于ViT的),一些只在decoder的第一层有query embedding (如类似于DETR的)。我们希望通过增加query embedding,来增加其抑制“恒等映射”的能力。因此,我们以transformer为基础,提出了Layer-wise Query Embedding,即,在decoder的每一层都加入query embedding。
创新点二:Neighbor Masked Attention
我们认为,在传统的Attention中,一个token是可以利用自己的信息的,这可能会防止信息泄漏,即,直接将输入进行输出,形成“恒等映射”。因此,我们提出了Neighbor Masked Attention,即,一个token是不能利用自己和自己的邻居的信息的。这样,网络就必须通过更远处的token来理解这个点的信息应该是什么,进而在这个过程中理解了正常样本,拟合了正常样本的分布。
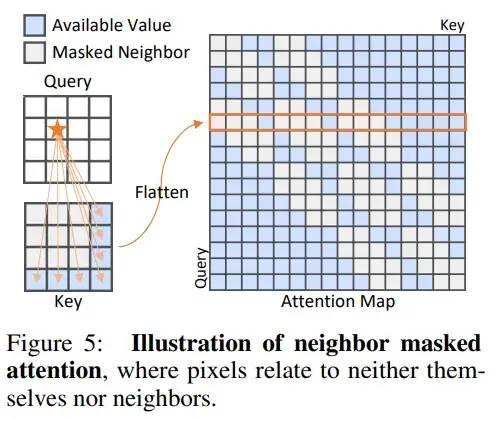
Neighbor Masked Attention
创新点三:Feature Jittering
受到De-noising Auto-Encoder的启发,我们设计了一个Feature Jittering策略。即,在输入的feature tokens中加入噪声,而重构的目标依然是未加噪声的feature tokens。因此,Feature Jittering可以将重构任务转化为去噪任务。网络通过去除噪声来理解正常样本,并拟合正常样本的分布。同时,恒等映射在这种情况下不能使得loss等于0,也就不是最优解了。
性能对比
我们在MVTec-AD上“一个模型处理所有类别”的unified setting下,在检测指标上远超baseline达到了8.4%,在定位指标上远超baseline达到了7.3%。
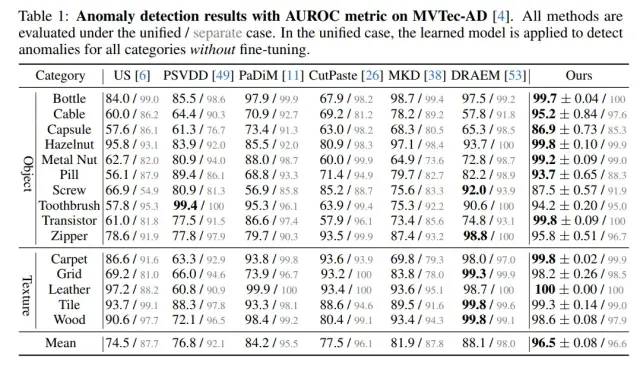
MVTec-AD的异常检测指标
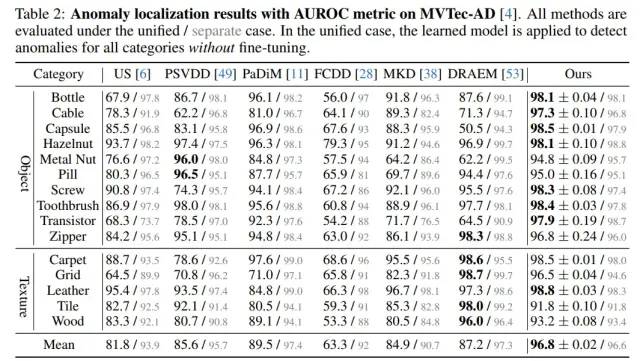
MVTec-AD的异常定位指标
我们的异常检测的可视化结果如下图所示,从左到右依次为,正常 (作为reference)、异常、异常的重构结果、ground-truth、我们的检测结果。结果证明,我们的方法可以将异常重构为对应的正常,所以重构的差异可以准确地定位出异常区域。

可视化结果
我们还将unified setting拓展到了CIFAR-10数据集中,我们的方法同样稳定地超越了Baseline。
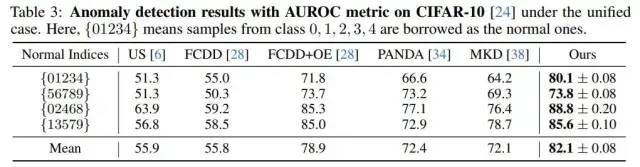
CIFAR-10的异常检测指标
消融实验
消融实验证明了我们所设计模块的有效性。
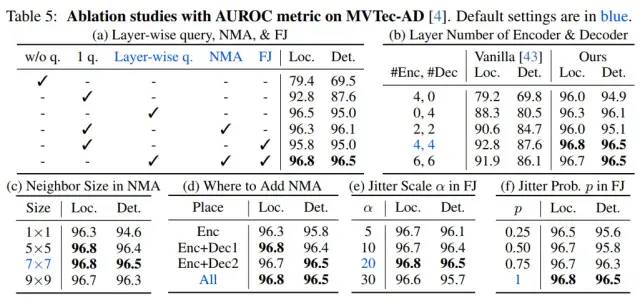
消融实验
结论
首先,我们提出了异常检测的unified setting,即,可以仅仅使用一个模型,解决所有类别的异常检测问题。之后,我们分析了基于重构的方法存在的“恒等映射”问题,并针对性地提出了三点改进,形成了我们的UniAD网络。我们的方法在MVTec-AD上,显著地超越了baseline达到8.4% (异常检测) 和7.3% (异常定位)。
-
FPGA的重构方式2011-05-27 0
-
有什么FPGA可重构方法可以对EPCS在线编程?2019-07-31 0
-
IDE的自动重构方法2020-12-15 0
-
求一种高档FPGA可重构配置方法2021-04-29 0
-
空间映射方法研究及其在LTCC设计中的应用2008-12-13 667
-
大本体的分块与映射方法研究2009-03-21 1559
-
STEP模式映射的一种实用方法2010-02-22 615
-
基于对EPCS在线编程的FPGA可重构方法2009-12-08 1475
-
基于SFS方法的超空泡三维重构研究2012-02-17 706
-
基于规范变量分析的数据重构方法及应用_卢娟2017-03-16 821
-
波形重构的方法比较2017-07-28 1812
-
基于单元相邻关系的重构区域构造方法2017-12-18 699
-
一种多重映射的自动短文摘方法2017-12-23 746
-
空间映射的分形图像编码方法2018-02-08 719
-
采用ARM和CPLD结构的检测系统可重构设计方法2018-10-20 2246
全部0条评论

快来发表一下你的评论吧 !
