

nutsdb的研究以及一些心得体会分享
电子说
描述
背景
有一天nutsdb学习交流群中有一位老哥说nutsdb重新恢复的速度太慢了,他那边大概有一个G左右的数据。我对这个问题还是比较感兴趣的,当场就接下了这个任务。开启了这段时间的优化之路,历时还蛮长时间的,因为平时上班,还有其他的一些兴趣爱好什么,所以开源上面的投入倒是有细水长流的感觉。好了,闲话不多说了,下面把这段时间在这个问题上面的研究以及一些心得体会分享给大家。
分析问题
俗语有云,能复现的问题都不是什么大问题。根据学习老哥的描述,我首先要做的就是准备1G的数据,然后benchmark+pprof测试重启恢复db的cpu和内存情况。最终问题定位到了这段代码上面:
// ReadAt returns entry at the given off(offset).
func (df *DataFile) ReadAt(off int) (e *Entry, err error) {
// 读取header
buf := make([]byte, DataEntryHeaderSize)
if _, err := df.rwManager.ReadAt(buf, int64(off)); err != nil {
return nil, err
}
meta := readMetaData(buf)
e = &Entry{
crc: binary.LittleEndian.Uint32(buf[0:4]),
Meta: meta,
}
if e.IsZero() {
return nil, nil
}
// read bucket
off += DataEntryHeaderSize
bucketBuf := make([]byte, meta.BucketSize)
_, err = df.rwManager.ReadAt(bucketBuf, int64(off))
if err != nil {
return nil, err
}
e.Meta.Bucket = bucketBuf
// read key
off += int(meta.BucketSize)
keyBuf := make([]byte, meta.KeySize)
_, err = df.rwManager.ReadAt(keyBuf, int64(off))
if err != nil {
return nil, err
}
e.Key = keyBuf
// read value
off += int(meta.KeySize)
valBuf := make([]byte, meta.ValueSize)
_, err = df.rwManager.ReadAt(valBuf, int64(off))
if err != nil {
return nil, err
}
e.Value = valBuf
crc := e.GetCrc(buf)
if crc != e.crc {
return nil, ErrCrc
}
return
}
这段代码的作用是给定一个文件的偏移位置,从这个位置开始往后读取一条数据。在db重启恢复的过程中这个函数会被频繁的调用,为什么呢?我们知道nutsdb是基于bitcask模型实现的,本质上来说是hash索引。在重启恢复的过程中会加载所有db的数据来重新构建索引。所以理论上来说,重启的时候当前db有多少数据,这个函数就会被调用多少次,由于这个函数性能不大行,所以这里成为了瓶颈。为什么说这个函数性能不太行呢?且看我娓娓道来。
一条nutsdb中的数据是以这样的形式被存储在磁盘中的:
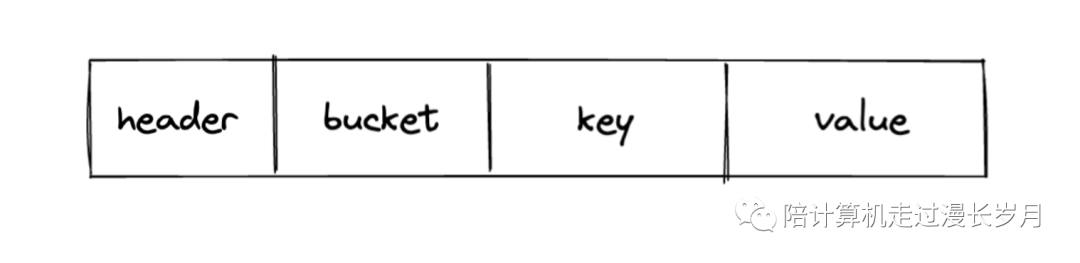
首先我们需要获取这条数据的元数据(header),也就是描述真实数据的数据,这里会记录bucket,key,value的长度,我们拿到这些信息之后会再次发起系统调用去获取真实bucket,key,value。由这段代码我们可以看到,这个函数没执行一次,就会发起四次系统调用,分别在磁盘中获取meta,bucket,key,value。而且每次都需要申请与数据长度匹配字节数组去承接这些数据。这个现状有两个问题,其一是过多的系统调用会是性能的瓶颈,其次是过多的申请内存,在这些对象被使用完之后会在内存中堆积起来,触发gc之后才会被清除回收。但是如果db数据过多,在这个时候也会触发gc造成卡顿。
如何解决?
在定位到问题之后,就开始了解决问题的旅程,这段旅程异常的漫长,这段过程翻阅了很多资料,尝试了很多方法。且看我一一道来。
1. 减少系统调用
在上面的分析中,我们知道读一条数据需要发起四次系统调用。我觉得这里其实大可不必,两次就足够了。因为第一次读取meta之后,我们就知道bucket,key,value这些数据的长度和位置了加上这些数据都是连续存储的,直接一次全部拿出来然后分别解析就好。
所以在第一次优化中,将上面的四次系统调用优化成了2次,带来了一倍速度上的提升。不仅仅是重启速度上的,因为在运行中读取数据用的也是这个函数。所以在数据的读取上同样也是优化了一倍的读取速度。下图是我提交的pr的截图,我构造了大小分别是50B, 256B,1024B的数据,db总数据1G,做并发读取性能测试,实验结果表明此次优化在读取速度上提升了接近一倍,但是在内存的使用上并没有减少。

2. 批量读取,然后解析数据
在做完系统调用的优化之后的一个星期的时间里,这项优化工作其实陷入了沉寂,有时候会脑爆一下这个该怎么做,翻越了bitcask论文和DDIA对hash索引恢复操作的描述,书中所说都是要将数据一条条的拿出来,没有可参考的资料感觉有点寸步难行。不过天无绝人之路,有一天打游戏的时候突然想到了,为什么不一次性读取文件的一部分,比如4KB,然后在这4KB中解析出里面的数据,解析到解析不下去的时候再拿下一个,直到文件解析完毕。下面让我们展开一下这个思路。
我们知道磁盘底层会把自己存储空间划分成一个个扇区,在磁盘之上的文件系统会把磁盘的扇区组成一个个的block,我们的应用程序每次去读取数据都是按照block去读取的。打个比方,一个block是4KB,如果我要读1KB的数据,那么会加载4KB的数据到pagecache,然后返回1KB给我们的应用程序。所以当我们一次次发起系统调用的去磁盘回去数据的时候,实际上数据已经从磁盘里拿出来并且放到pagecache中了。所以我们直接把整个block拿出来就完事了。
一开始想的是批量获取一批完整的数据。这个时候其实不太好控制,因为我们不知道一条数据有多大,所以如果要要批量获取数据还需要额外的数据结构去描述,我把这个东西叫做断点,也就是说一个文件分成若干个断点,断点之间存储的是一批数据。如果朝这个方向改会衍生出很多问题,其一是在什么样的标准下面去写这个断点,比如按照数据量来记呢,还是按照一个固定的空间大小来记录。其二是再增加这个逻辑去额外记录还需要在数据写入过程中做添加。一来二去感觉太复杂了。
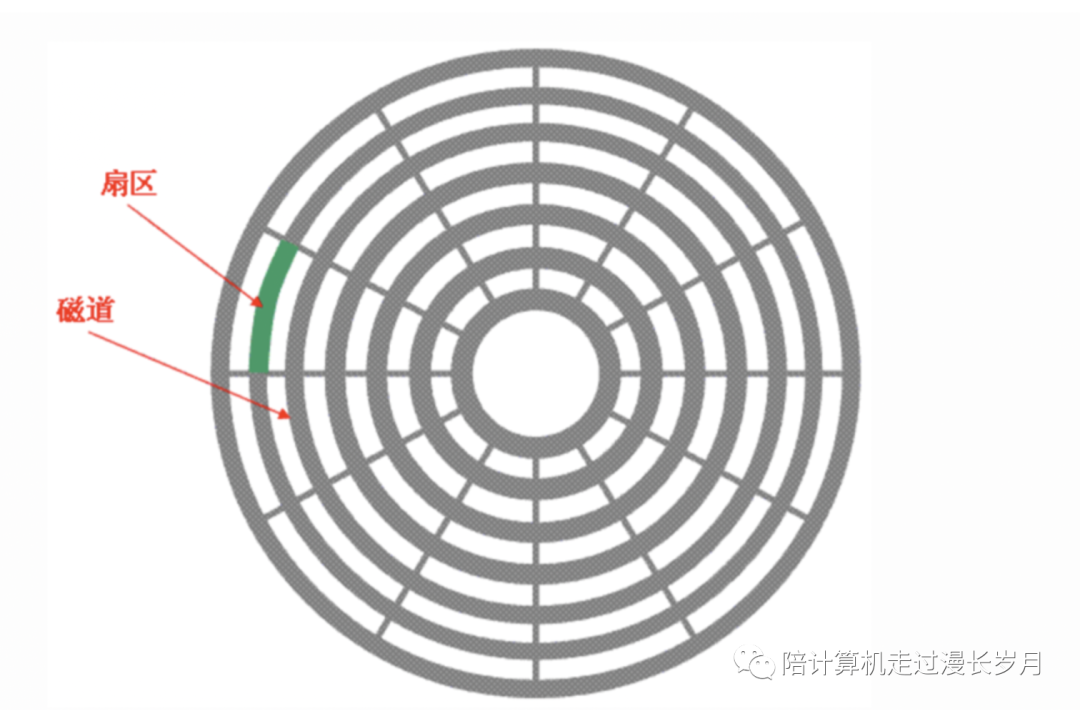
那么我们按照一个个固定的块来搞。由于我们不知道数据的大小是怎么样的,所以按照固定块读取会出现以下的情况。

我们看上图,上图中的e1和e2代表着在一个存储文件中一条条连续着存储的数据,header是元数据,payload是对bucket,key,value这三个数据的整体描述,即有效数据部分。图中的箭头代表按块读取数据的时候有可能读到的块的边界。其实也很好理解,在读一个块的时候可能会出现的情况是:
这个块就包含了若干条完完整整的数据。这个时候不需要额外的处理。
这个块前面包含了若干条完整的数据,但是最后的一条是残缺的,缺失了header。这个时候我们需要读入header残余的数据,解析出一整个header。为什么不读一整个block然后在在block中获取解析header所需的剩余数据呢?因为我们不知道这条数据长什么样子,如果他的大小超过了一个block的size,那么还需要在后续做额外的处理。
最后一种情况是缺失了payload,那么我们需要根据缺失数据的大小来判断要读多少个block进来。
经过这一分析之后,其实一整个解析数据的流程就是在这三个状态之间来回转换。解析的流程就是一个状态机的算法。等到文件读完,那么也就解析完了。
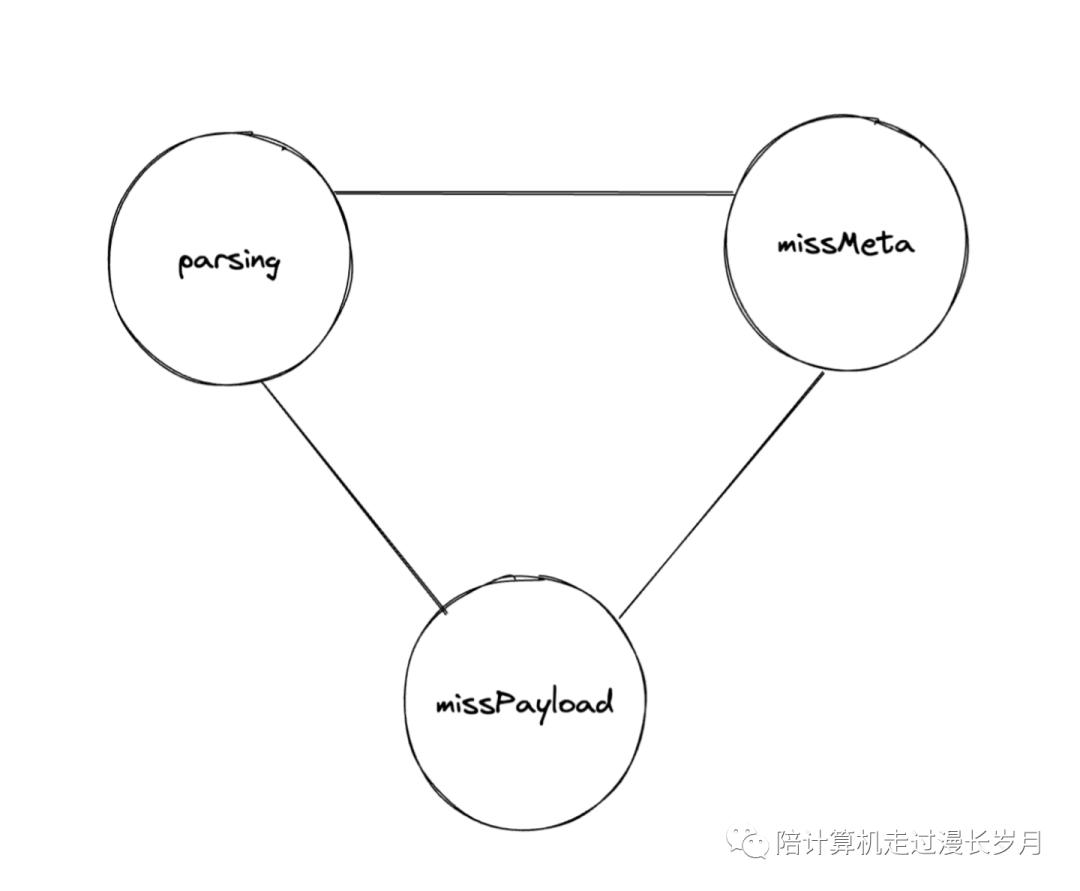
激动的心颤抖的手,代码写完之后做了一版benchmark。
BenchmarkRecovery-10 1 2288482750 ns/op 1156858488 B/op 14041579 allocs/op
BenchmarkRecovery-10 2 701933396 ns/op 600666340 B/op 3947879 allocs/op
我们分析一下这个思路下的优化,理论上来说db中一条数据越小,优化效果越明显,因为这就意味着单次获取的block中蕴含着更多的数据,就可以减少更多的系统调用。但是我们可以看到的是,虽然启动的时间变短了,申请内存的次数变少了,但是申请的内存还是不少。
执行两次启动恢复1G左右的数据大概花了4G的内存。也就是说一次启动花了2G,里面有1G消耗不知道是在哪里来的。一开始我以为是读取数据的时候会在用户空间往内核空间拷贝,会存在读取放大的情况。不过转念一想觉得不大可能,因为pagecache是类似LRU的缓存机制,不会缓存你所有的数据,他也有数据的淘汰策略,不太可能1比1放大的。
所以问题出在哪里呢?我百思不得其解。不过源码之下无秘密,我反复一次又一次看我写下的代码,终于让我在一个地方发现了猫腻。一个我意想不到的地方,那就是append操作。
我的文件数据恢复恢复操作所代表的结构体是这样的:
FileRecovery struct {
fd *os.File
rest []byte
state state
blockSize uint32
finish bool
entry *handlingEntry
entries []*Entry
off int64
}
我的解析流程是把文件读完,把里面的数据一个个append进entries字段里面,文件解析完了再把entries返回。要是在平时我不会觉得这个操作是有什么问题的,不过我准备的数据量太大了(两百万条),append应该会触发多次扩容操作,然后反复申请内存。去翻看了一下append操作的扩容机制,当数据量小于1024的时候,会扩成原来的2倍,数据量大于1024时,会变成原来的1.25倍。看到这里其实基本验证了我的猜想,不过谨慎起见还是计算了一下, nutsdb数据有segment设置,当一个文件大于这个参数的大小的时候会保存成只读文件。两百万条数据写了两个文件,这个结构体是解析单个文件的,我们按照每个文件100万条数据算。100万条数据大概要扩容几次呢:

1024前面的过程就忽略不计了,直接从1024开始,掏出计算器,这里x的值是30次,那么扩容30次总共需要多少内存呢?
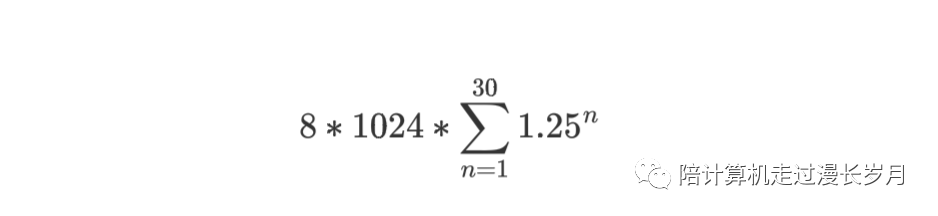
为什么是乘8呢,因为我是64位机器,entries里面的元素是指针,那么指针的长度和字长是一样的,也就是8个byte。这里的结果大概是3000万,3000万个比特大概是220MB的内存,两个文件加起来大概就是440MB的内存了。惊不惊喜,意不意外?
那么如何优化这里呢,其实一个个往外传就可以了,不要等到解析完了堆在数组里再往外丢。如果要在原来的基础上改的话,我需要每次处理完一条数据的时候记录下当前这个block处理到哪里,也就是要把block改成ring buffer的形式,这个时候我隐隐约约想到了go的标准库里有一个东西做了类似的事情,没错,就是bufio.Reader.他不仅仅会帮我们看到记录ringbuffer的位置,还会预读block。整体上看是完美契合这个需求的。
3. bufio.Reader
bufio.Reader会维护一个默认大小4KB的ring buffer,当读取的内容大于它所能承载的缓存时,他会直接在读取而不使用缓存,如果读取的是比较小的数据,会在他的缓存中copy出来一份返回。这个就完美的契合了我们多次读取的场景。看一下改成这样子的性能提升吧:

这下无论是速度上,还是内存的使用上,都达到了一个比较理想的状态。这次优化历程就到此结束了。

总结
做性能优化的感觉就像和计算机对话,依照自己现有的知识去想方案, 然后写出来之后做实验求证。做这个的思路是让他慢慢的变好,而不是上来就追求完美主义,完美主义是不靠谱的,反而会让你陷入到纠结之中,能优化一点是一点,我们要看到一个变好的趋势,然后在这个趋势上面不断的基于上一次的结果去猜想下一次怎么优化,也就是所谓的“小步快跑”。在做这个的过程中会往各个方向去脑爆,一些背景知识不是很清楚的时候需要翻越各种资料。整体来说是一次很不错的成长体验。
审核编辑:刘清
-
VHDL编程心得体会o2012-08-20 0
-
学习fpga心得体会2012-09-14 0
-
Linux链表操作心得体会2019-07-26 0
-
求大神分享学习51单片机的心得体会?2021-03-10 0
-
C语言编程的学习经验和心得体会概括2021-11-03 0
-
学习STM32控制蜂鸣器的心得体会分享2021-12-07 0
-
Ucos2/3系统和FreeRtos系统心得体会记录2021-12-22 0
-
改造电烙铁的心得体会2012-02-09 9728
-
飞机电子狗的正确使用方法-心得体会2016-07-28 993
-
单片机应用研发暑期实习小结_第一周焊接部分心得体会2016-08-17 724
-
单片机应用研发暑期实习小结_第二周PCB心得体会2016-08-17 604
-
单片机应用研发暑期实习小结_第四周STM32心得体会2016-08-17 909
-
VHDL编程心得体会2016-11-11 650
-
Linux内核阅读心得体会2017-10-24 811
-
marantz7K•9K试听会心得体会2021-07-31 563
全部0条评论

快来发表一下你的评论吧 !
