

xenomai+linux双内核下的时钟管理机制
嵌入式技术
描述
作者简介:
顺刚(网名:沐多),一线码农,从事工控行业,目前在一家工业自动化公司从事工业实时现场总线开发工作,喜欢钻研Linux内核及xenomai,个人博客 wsg1100,欢迎大家关注!
clock可以说是操作系统正常运行的发动机,整个操作系统的活动都受到它的激励。系统利用时钟中断维持系统时间、促使任务调度,以保证所有进程共享CPU资源;可以说,“时钟中断”是整个操作系统的脉搏。
那你是否好奇xenomai cobalt内核和Linux内核双内核共存的情况下,时间子系统是如何工作的?一个硬件时钟如何为两个操作系统内核提供服务的?本文将揭开xenomai双核系统下clock机制的面纱。
首先回看一下之前的文章xenomai内核解析之xenomai的组成结构。
我们说到:在内核空间,在标准linux基础上添加一个实时内核Cobalt,得益于基于ADEOS(Adaptive Domain Environment for Operating System),使Cobalt内核在内核空间与linux内核并存,并把标准的Linux内核作为实时内核中的一个idle进程在实时内核上调度。
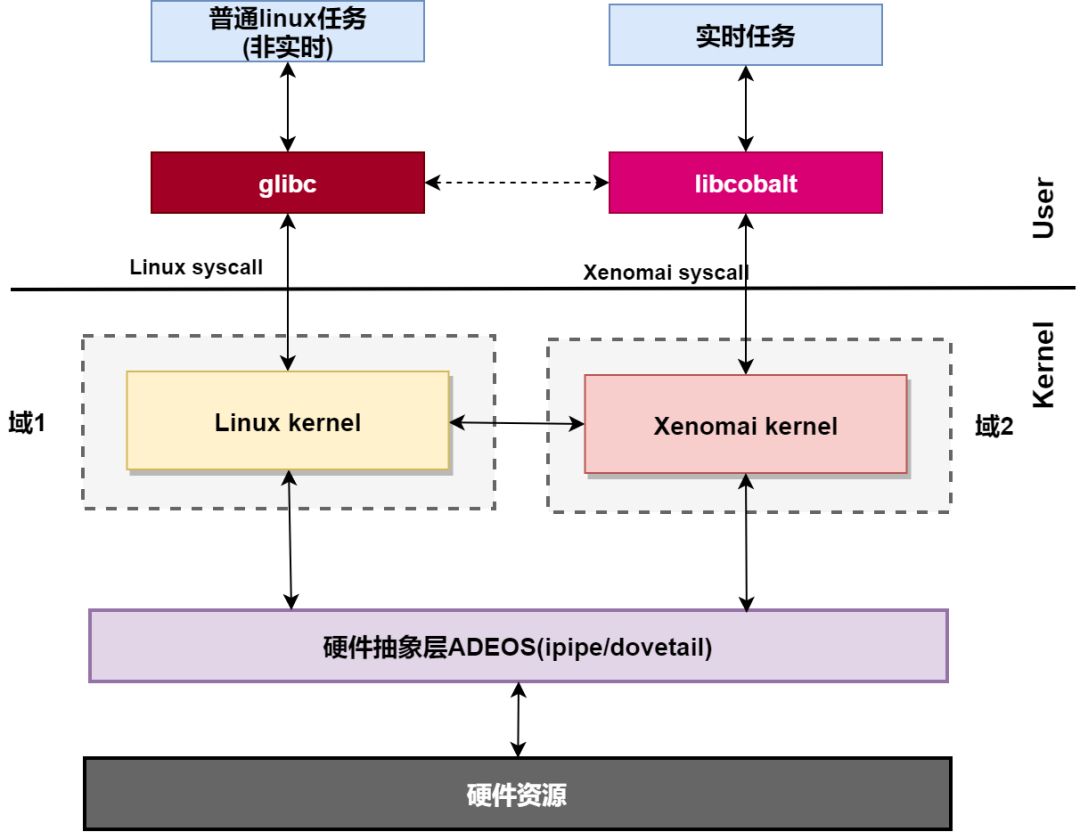 “并把标准的Linux内核作为实时内核中的一个idle进程在实时内核上调度“,这句话是本文的重点,接下我们先从Linux时间子系统介绍。
“并把标准的Linux内核作为实时内核中的一个idle进程在实时内核上调度“,这句话是本文的重点,接下我们先从Linux时间子系统介绍。
中间部分为个人分析代码简单记录,比较啰嗦,如果你只是想知道xenomai时钟子系统与linux时钟子系统之间的关系可直接到2.6 xenomai内核下Linux时钟工作流程查看总结。
一、linux时间子系统
linux时间子系统是一个很大的板块,控制着linux的方方面面。这里只说双核相关的部分。即侧重于Linux与底层硬件交互这一块。
关于Linux时间子系统的详细内容,请移步蜗窝科技关系Linux 时间子系统专栏。文章中Linux时间子系统大部分内容来自于此,在此谢过~
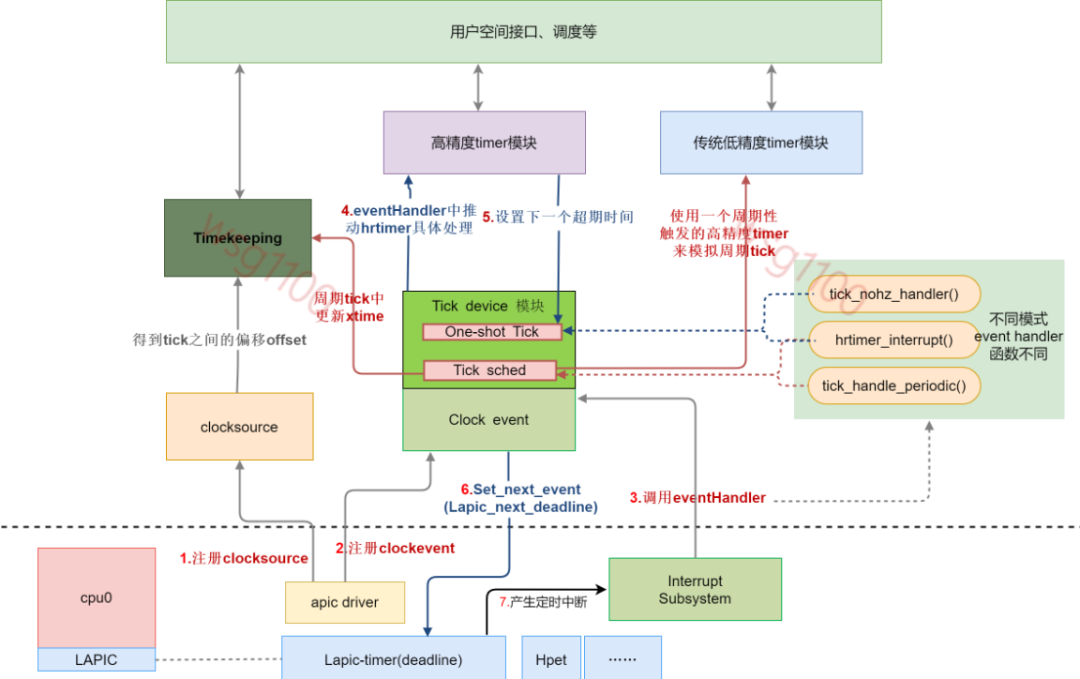
Linux时间子系统框架大致如下:
1.1 tick device
处理器采用时钟定时器来周期性地提供系统脉搏。时钟中断是普通外设中断的一种。调度器利用时钟中断来定时检测当前正在运行的线程是否需要调度。提供时钟中断的设备就是tick device。
如今在多核架构下,每个CPU形成了自己的一个小系统,有自己的调度、自己的进程统计等,这个小系统拥有自己的tick device,而且每个CPU上tick device是唯一的,tick device可以工作在periodic mode或者one shot mode,这是和系统配置有关(由于中断的处理会影响实时性,一般将xenomai所在CPU的tick device配置工作在one shot mode模式)。因此,整个系统中,在tick device layer,有多少个cpu,就会有多少个tick device,称为local tick device。当然,有些事情(例如整个系统的负荷计算)不适合在local tick驱动下进行,因此,所有的local tick device中会有一个被选择做global tick device,该device负责维护整个系统的jiffies,更新wall clock,计算全局负荷什么的。
tick_device 数据结构如下:
/*tick device可以工作在两种模式下,一种是周期性tick模式,另外一种是one shot模式。*/
enum tick_device_mode {
TICKDEV_MODE_PERIODIC,
TICKDEV_MODE_ONESHOT,/*one shot模式主要和tickless系统以及高精度timer有关*/
};
struct tick_device {
struct clock_event_device *evtdev;
enum tick_device_mode mode;
};
1.2 clock event和clock source
tick device依赖于底层硬件产生定时事件来推动运行,这些产生定时事件的硬件是timer,除此之外还需要一个在指定输入频率的clock下工作的一个counter来提供计时。对形形色色的timer和counter硬件,linux kernel抽象出了通用clock event layer和通用clock source模块,这两个模块和硬件无关。所谓clock source是用来抽象一个在指定输入频率的clock下工作的一个counter。clock event提供的是一定周期的event,如果应用程序需要读取当前的时间,比如ns精度时,就需要通过timekeeping从clock source中获取与上个tick之间的时间后返回此时时间。
底层的clock source chip驱动通过调用通用clock event和clock source模块的接口函数,注册clock source和clock event设备。
int clocksource_register(struct clocksource *cs) void clockevents_register_device(struct clock_event_device *dev)
1.3 clock event 设备注册
每个CPU上tick device是唯一的,但为Tick device提供tick event的timer硬件并不唯一,如上图中有Lapic-timer、lapic-deadline、Hpet等,有多少个timer硬件就注册多少个clock event device,各个cpu的tick device会选择自己适合的那个clock event设备。
clock_event_devic结构如下:
struct clock_event_device {
void (*event_handler)(struct clock_event_device *);
int (*set_next_event)(unsigned long evt, struct clock_event_device *);
int (*set_next_ktime)(ktime_t expires, struct clock_event_device *);
ktime_t next_event;
u64 max_delta_ns;
u64 min_delta_ns;
u32 mult;
u32 shift;
enum clock_event_state state_use_accessors;
unsigned int features;
unsigned long retries;
int (*set_state_periodic)(struct clock_event_device *);
int (*set_state_oneshot)(struct clock_event_device *);
int (*set_state_oneshot_stopped)(struct clock_event_device *);
int (*set_state_shutdown)(struct clock_event_device *);
int (*tick_resume)(struct clock_event_device *);
void (*broadcast)(const struct cpumask *mask);
void (*suspend)(struct clock_event_device *);
void (*resume)(struct clock_event_device *);
unsigned long min_delta_ticks;
unsigned long max_delta_ticks;
const char *name;
int rating;
int irq;
int bound_on;
const struct cpumask *cpumask;
struct list_head list;
......
} ____cacheline_aligned;
简要说下各成员变量的含义:
event_handler产生了clock event的时候调用的handler,硬件timer中断到来的时候调用该timer中断handler,而在这个中断handler中再调用event_handler。
set_next_event设定产生下一个event。一般是clock的counter的cycle数值,一般的timer硬件都是用cycle值设定会比较方便,当然,不排除有些奇葩可以直接使用ktime(秒、纳秒),这时候clock event device的features成员要打上CLOCK_EVT_FEAT_KTIME的标记使用set_next_ktime()函数设置。
set_state_periodic、set_state_oneshot、set_state_shutdown设置各个模式的配置函数。
broadcast上面说到每个cpu有一个tcik device外还需要一个全局的clock event,为各CPU提供唤醒等功能。
rating该clock evnet的精度等级,在选做tick device时做参考。
irq 该clock event对应的系统中断号。
void clockevents_register_device(struct clock_event_device *dev)
{
unsigned long flags;
......
if (!dev->cpumask) {
WARN_ON(num_possible_cpus() > 1);
dev->cpumask = cpumask_of(smp_processor_id());
}
list_add(&dev->list, &clockevent_devices);/*加入clock event设备全局列表 */
tick_check_new_device(dev);/*让上层软件知道底层又注册一个新的clock device,当然,是否上层软件要使用这个新的clock event device是上层软件的事情*/
clockevents_notify_released();
......
}
clock event device的cpumask指明该设备为哪一个CPU工作,如果没有设定并且cpu的个数大于1的时候要给出warning信息并进行设定(设定为当前运行该代码的那个CPU core)。在multi core的环境下,底层driver在调用该接口函数注册clock event设备之前就需要设定cpumask成员,毕竟一个timer硬件附着在哪一个cpu上底层硬件最清楚。这里只是对未做设定的的设定为当前CPU。
将新注册的clockevent device添加到全局链表clockevent_devices,然后调用tick_check_new_device()让上层软件知道底层又注册一个新的clock device,当然,是否上层软件会通过一系列判断后来决定是否使用这个clock event作为tick device。如果被选作tick device 会为该clock event设置回调函数event_handler,如上图所示:event_handler不同的模式会被设置为tick_handle_periodic()、hrtimer_interrupt()或tick_nohz_handler()。代码详细解析,后面会简要说明;
对应x86平台,clock event device有APIC-timer、hept,hept的rating没有lapic timer高。所以每个CPU上的loacl-apic timer作为该CPU的tick device。
//archx86kernelhpet.c
static struct clock_event_device lapic_clockevent = {
.name = "lapic",
.features = CLOCK_EVT_FEAT_PERIODIC |
CLOCK_EVT_FEAT_ONESHOT | CLOCK_EVT_FEAT_C3STOP
| CLOCK_EVT_FEAT_DUMMY,
.shift = 32,
.set_state_shutdown = lapic_timer_shutdown,
.set_state_periodic = lapic_timer_set_periodic,
.set_state_oneshot = lapic_timer_set_oneshot,
.set_state_oneshot_stopped = lapic_timer_shutdown,
.set_next_event = lapic_next_event,
.broadcast = lapic_timer_broadcast,
.rating = 100,
.irq = -1,
};
//archx86kernelapicapic.c
static struct clock_event_device hpet_clockevent = {
.name = "hpet",
.features = CLOCK_EVT_FEAT_PERIODIC |
CLOCK_EVT_FEAT_ONESHOT,
.set_state_periodic = hpet_legacy_set_periodic,
.set_state_oneshot = hpet_legacy_set_oneshot,
.set_state_shutdown = hpet_legacy_shutdown,
.tick_resume = hpet_legacy_resume,
.set_next_event = hpet_legacy_next_event,
.irq = 0,
.rating = 50,
};
apic的中断函数smp_apic_timer_interrupt(),然后调用local_apic_timer_interrupt():
__visible void __irq_entry smp_apic_timer_interrupt(struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
/*
* NOTE! We'd better ACK the irq immediately,
* because timer handling can be slow.
*
* update_process_times() expects us to have done irq_enter().
* Besides, if we don't timer interrupts ignore the global
* interrupt lock, which is the WrongThing (tm) to do.
*/
entering_ack_irq();
trace_local_timer_entry(LOCAL_TIMER_VECTOR);
local_apic_timer_interrupt(); /*执行handle*/
trace_local_timer_exit(LOCAL_TIMER_VECTOR);
exiting_irq();
set_irq_regs(old_regs);
}
static void local_apic_timer_interrupt(void)
{
struct clock_event_device *evt = this_cpu_ptr(&lapic_events);
if (!evt->event_handler) {
pr_warning("Spurious LAPIC timer interrupt on cpu %d
",
smp_processor_id());
/* Switch it off */
lapic_timer_shutdown(evt);
return;
}
inc_irq_stat(apic_timer_irqs);
evt->event_handler(evt);/*执行event_handler*/
}
local_apic_timer_interrupt()先获得产生该中断的clock_event_device,然后执行event_handler()。
1.4 clock source设备注册
linux 中clock source主要与timekeeping模块关联,这里不细说,查看系统中的可用的clock source:
$cat /sys/devices/system/clocksource/clocksource0/available_clocksource tsc hpet acpi_pm
查看系统中当前使用的clock source的信息:
$ cat /sys/devices/system/clocksource/clocksource0/current_clocksource tsc
这里主要说一下与xenomai相关的clock source 设备TSC(Time Stamp Counter),x86处理器提供的TSC是一个高分辨率计数器,以恒定速率运行(在较旧的处理器上,TSC计算内部处理器的时钟周期,这意味着当处理器的频率缩放比例改变时,TSC的频率也会改变,现今的TSC在处理器的所有操作状态下均以恒定的速率运行,其频率远远超过了处理器的频率),可以用单指令RDTSC读取。
struct clocksource clocksource_tsc = {
.name = "tsc",
.rating = 300,
.read = read_tsc,
.mask = CLOCKSOURCE_MASK(64),
.flags = CLOCK_SOURCE_IS_CONTINUOUS |
CLOCK_SOURCE_MUST_VERIFY,
.archdata = { .vclock_mode = VCLOCK_TSC },
.resume = tsc_resume,
.mark_unstable = tsc_cs_mark_unstable,
.tick_stable = tsc_cs_tick_stable,
};
tsc在init_tsc_clocksource()中调用int clocksource_register(struct clocksource *cs)注册,流程如下:
1.调用__clocksource_update_freq_scale(cs, scale, freq),根据tsc频率计算mult和shift,具体计算流程文章实时内核与linux内核时钟漂移过大原因.docx已分析过。
2.调用clocksource_enqueue(cs)根据clock source按照rating的顺序插入到全局链表clock source list中
3.选择一个合适的clock source。kernel当然是选用一个rating最高的clocksource作为当前的正在使用的那个clock source。每当注册一个新的clock source的时候调用clocksource_select进行选择,毕竟有可能注册了一个精度更高的clock source。X86系统中tsc rating最高,为300。
到此clock source注册就注册完了。
1.5 时间子系统的数据流和控制流
上面说到tick device的几种模式,下面结合整个系统模式说明。高精度的timer需要高精度的clock event,工作在one shot mode的tick device工提供高精度的clock event(clockeventHandler中处理高精度timer)。因此,基于one shot mode下的tick device,系统实现了高精度timer,系统的各个模块可以使用高精度timer的接口来完成定时服务。
虽然有了高精度timer的出现, 内核并没有抛弃老的低精度timer机制(内核开发人员试图整合高精度timer和低精度的timer,不过失败了,所以目前内核中,两种timer是同时存在的)。当系统处于高精度timer的时候(tick device处于one shot mode),系统会setup一个特别的高精度timer(可以称之sched timer),该高精度timer会周期性的触发,从而模拟的传统的periodic tick,从而推动了传统低精度timer的运转。因此,一些传统的内核模块仍然可以调用经典的低精度timer模块的接口。系统可根据需要配置为以下几种模式,具体配置见其他文档:
1、使用低精度timer + 周期tick
根据当前系统的配置情况(周期性tick),会调用tick_setup_periodic函数,这时候,该tick device对应的clock event device的clock event handler被设置为tick_handle_periodic。底层硬件会周期性的产生中断,从而会周期性的调用tick_handle_periodic从而驱动整个系统的运转。
这时候高精度timer模块是运行在低精度的模式,也就是说这些hrtimer虽然是按照高精度timer的红黑树进行组织,但是系统只是在每一周期性tick到来的时候调用hrtimer_run_queues函数,来检查是否有expire的hrtimer。毫无疑问,这里的高精度timer也就是没有意义了。
2、低精度timer + Dynamic Tick
系统开始的时候并不是直接进入Dynamic tick mode的,而是经历一个切换过程。开始的时候,系统运行在周期tick的模式下,各个cpu对应的tick device的(clock event device的)event handler是tick_handle_periodic。在timer的软中断上下文中,会调用tick_check_oneshot_change进行是否切换到one shot模式的检查,如果系统中有支持one-shot的clock event device,并且没有配置高精度timer的话,那么就会发生tick mode的切换(调用tick_nohz_switch_to_nohz),这时候,tick device会切换到one shot模式,而event handler被设置为tick_nohz_handler。由于这时候的clock event device工作在one shot模式,因此当系统正常运行的时候,在event handler中每次都要reprogram clock event,以便正常产生tick。当cpu运行idle进程的时候,clock event device不再reprogram产生下次的tick信号,这样,整个系统的周期性的tick就停下来。
高精度timer和低精度timer的工作原理同上。
3、高精度timer + Dynamic Tick
同样的,系统开始的时候并不是直接进入Dynamic tick mode的,而是经历一个切换过程。系统开始的时候是运行在周期tick的模式下,event handler是tick_handle_periodic。在周期tick的软中断上下文中(参考run_timer_softirq),如果满足条件,会调用hrtimer_switch_to_hres将hrtimer从低精度模式切换到高精度模式上。这时候,系统会有下面的动作:
(1)Tick device的clock event设备切换到oneshot mode(参考tick_init_highres函数)
(2)Tick device的clock event设备的event handler会更新为hrtimer_interrupt(参考tick_init_highres函数)
(3)设定sched timer(即模拟周期tick那个高精度timer,参考tick_setup_sched_timer函数)这样,当下一次tick到来的时候,系统会调用hrtimer_interrupt来处理这个tick(该tick是通过sched timer产生的)。
在Dynamic tick的模式下,各个cpu的tick device工作在one shot模式,该tick device对应的clock event设备也工作在one shot的模式,这时候,硬件Timer的中断不会周期性的产生,但是linux kernel中很多的模块是依赖于周期性的tick的,因此,在这种情况下,系统使用hrtime模拟了一个周期性的tick。在切换到dynamic tick模式的时候会初始化这个高精度timer,该高精度timer的回调函数是tick_sched_timer。这个函数执行的函数类似周期性tick中event handler执行的内容。不过在最后会reprogram该高精度timer,以便可以周期性的产生clock event。当系统进入idle的时候,就会stop这个高精度timer,这样,当没有用户事件的时候,CPU可以持续在idle状态,从而减少功耗。
4、高精度timer + 周期性Tick
这种配置不多见,多半是由于硬件无法支持one shot的clock event device,这种情况下,整个系统仍然是运行在周期tick的模式下。
总结一下:linux启动过程中初始化时钟系统,当xenomai内核未启动时,linux直接对底层硬件lapic-timer编程,底层硬件lapic-timer产生中断推动整个Linux中的各个时钟及调度运行。
我们可以将Linux抽出如下图,只需要为Linux提供设置下一个时钟事件set_next_event()和提供event触发eventHandler()执行两个接口就能推动整个linux时间子系统运转,下面解析Xenomai是怎样为linux提供这两个接口的,达到控制整个时钟系统的。
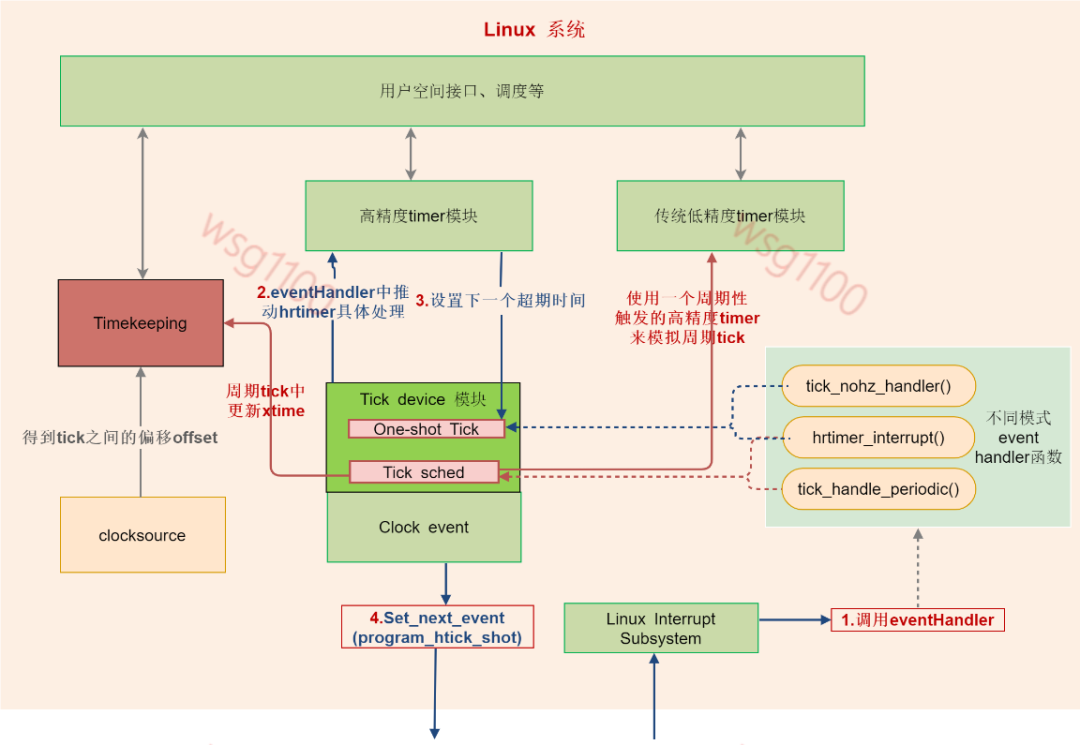
二、xenomai时间子系统
2.1 xnclock
我们知道x86下每个cpu核有一个lapic,lapic中有定时硬件lapic-timer和hpet。tsc作为timeline,提供计时,lapic-timer用来产生clock event。对于现今X86 CPU 操作系统一般都是使用TSC和lapic-timer作为clock source和clock event,因为精度最高(Atom 系列处理器可能会有区别).
xenomai的默认时间管理对象是xnclock,xnclock管理着xenomai整个系统的时间、任务定时、调度等,xnclok的默认时钟源为TSC。当然我们可以自定义clocksource。比如在TSC不可靠的系统上,可以使用外部定时硬件来作为时钟源,当自定义时钟时需要实现结构体中的宏CONFIG_XENO_OPT_EXTCLOCK包含的几个必要函数,且编译配置使能CONFIG_XENO_OPT_EXTCLOCK。
注意:这里的自定义时钟源只是将TSC替换为其他时钟源,产生event的还是lapic-timer.
struct xnclock {
/** (ns) */
xnticks_t wallclock_offset; /*获取时钟偏移:timekeeping - tsc*/
/** (ns) */
xnticks_t resolution;
/** (raw clock ticks). */
struct xnclock_gravity gravity;
/** Clock name. */
const char *name;
struct {
#ifdef CONFIG_XENO_OPT_EXTCLOCK
xnticks_t (*read_raw)(struct xnclock *clock);
xnticks_t (*read_monotonic)(struct xnclock *clock);
int (*set_time)(struct xnclock *clock,
const struct timespec *ts);
xnsticks_t (*ns_to_ticks)(struct xnclock *clock,
xnsticks_t ns);
xnsticks_t (*ticks_to_ns)(struct xnclock *clock,
xnsticks_t ticks);
xnsticks_t (*ticks_to_ns_rounded)(struct xnclock *clock,
xnsticks_t ticks);
void (*program_local_shot)(struct xnclock *clock,
struct xnsched *sched);
void (*program_remote_shot)(struct xnclock *clock,
struct xnsched *sched);
#endif
int (*set_gravity)(struct xnclock *clock,
const struct xnclock_gravity *p);
void (*reset_gravity)(struct xnclock *clock);
#ifdef CONFIG_XENO_OPT_VFILE
void (*print_status)(struct xnclock *clock,
struct xnvfile_regular_iterator *it);
#endif
} ops;
/* Private section. */
struct xntimerdata *timerdata;
int id;
#ifdef CONFIG_SMP
/** Possible CPU affinity of clock beat. */
cpumask_t affinity;
#endif
#ifdef CONFIG_XENO_OPT_STATS
struct xnvfile_snapshot timer_vfile;
struct xnvfile_rev_tag timer_revtag;
struct list_head timerq;
int nrtimers; /*统计挂在xnclock xntimer 的数量*/
#endif /* CONFIG_XENO_OPT_STATS */
#ifdef CONFIG_XENO_OPT_VFILE
struct xnvfile_regular vfile;//vfile.ops= &clock_ops
#endif
};
wallclock_offset:linux系统wall time(1970开始的时间值)与系统TSC cycle转换为时间的偏移
resolution:该xnclock的精度
struct xnclock_gravity gravity:该xnclok下,中断、内核、用户空间程序定时器的调整量,对系统精确定时很重要,后面会说到。
struct xnclock_gravity {
unsigned long irq;
unsigned long kernel;
unsigned long user;
};
ops:该xnclok的各操作函数。
timerdata:xntimer 管理结构头节点,当系统中使用红黑树来管理xntimer时,他是红黑树head节点,当系统使用优先级链表来管理时它是链表头节点,系统会为每个cpu分配一个timerdata,管理着本CPU上已启动的xntimer,当为红黑树时head始终指向最近到期的xntimer,当某个cpu上一个clockevent到来时,xnclock会从该CPU timerdata取出head指向的那个timer看是否到期,然后进一步处理。
#if defined(CONFIG_XENO_OPT_TIMER_RBTREE)
typedef struct {
struct rb_root root;
xntimerh_t *head;
} xntimerq_t;
#else
typedef struct list_head xntimerq_t;
#endif
struct xntimerdata {
xntimerq_t q;
};
timerq:不论是属于哪个cpu的xntimer初始化后都会挂到这个链表上,nrtimers挂在timerq上xntimer的个数
vfile:proc文件系统操作接口,可通过proc查看xenomai clock信息。
cat /proc/xenomai/clock/coreclok gravity: irq=99 kernel=1334 user=1334 devices: timer=lapic-deadline, clock=tsc status: on setup: 99 ticks: 376931548560 (0057 c2defd90)
gravity即xnclock中的结构体gravity的值,devices表示xenomai用于产生clock event的硬件timer,clock为xnclock计时的时钟源。
xenomai 内核默认定义xnclock如下,名字和结构体名一样,至于xnclock怎么和硬件timer 、tsc联系起来后面分析:
struct xnclock nkclock = {
.name = "coreclk",
.resolution = 1, /* nanosecond. */
.ops = {
.set_gravity = set_core_clock_gravity,
.reset_gravity = reset_core_clock_gravity,
.print_status = print_core_clock_status,
},
.id = -1,
};
2.2 xntimer
实时任务的所有定时行为最后都会落到内核中的xntimer上,而xnclock管理着硬件clock event,xntimer要完成定时就需要xnclock来获取起始时间,xntimer结构如下:
struct xntimer {
#ifdef CONFIG_XENO_OPT_EXTCLOCK
struct xnclock *clock;
#endif
/** Link in timers list. */
xntimerh_t aplink;
struct list_head adjlink;
/** Timer status. */
unsigned long status;
/** Periodic interval (clock ticks, 0 == one shot). */
xnticks_t interval;
/** Periodic interval (nanoseconds, 0 == one shot). */
xnticks_t interval_ns;
/** Count of timer ticks in periodic mode. */
xnticks_t periodic_ticks;
/** First tick date in periodic mode. */
xnticks_t start_date;
/** Date of next periodic release point (timer ticks). */
xnticks_t pexpect_ticks;
/** Sched structure to which the timer is attached. 附加计时器的Sched结构。*/
struct xnsched *sched;
/** Timeout handler. */
void (*handler)(struct xntimer *timer);
#ifdef CONFIG_XENO_OPT_STATS
#ifdef CONFIG_XENO_OPT_EXTCLOCK
struct xnclock *tracker;
#endif
/** Timer name to be displayed. */
char name[XNOBJECT_NAME_LEN];
/** Timer holder in timebase. */
struct list_head next_stat;
/** Number of timer schedules. */
xnstat_counter_t scheduled;
/** Number of timer events. */
xnstat_counter_t fired;
#endif /* CONFIG_XENO_OPT_STATS */
};
clock:当自定义外部时钟源时,使用外部时钟时的xnclock.
aplink:上面介绍新clock时说到timerdata,当xntimer启动是,aplink就会插入到所在cpu的timerdata中,当timerdata为红黑树时,aplink就是一个rb节点,否则是一个链表节点。分别如下:
//优先级链表结构
struct xntlholder {
struct list_head link;
xnticks_t key;
int prio;
};
typedef struct xntlholder xntimerh_t;
//树结构
typedef struct {
unsigned long long date;
unsigned prio;
struct rb_node link;
} xntimerh_t;
系统默认配置以红黑树形式管理xntimer,date表示定时器的多久后到期;prio表示该定时器的优先级,当加入链表时先date来排序,如果几个定时器date相同就看优先级,优先级高的先处理;link为红黑树节点。
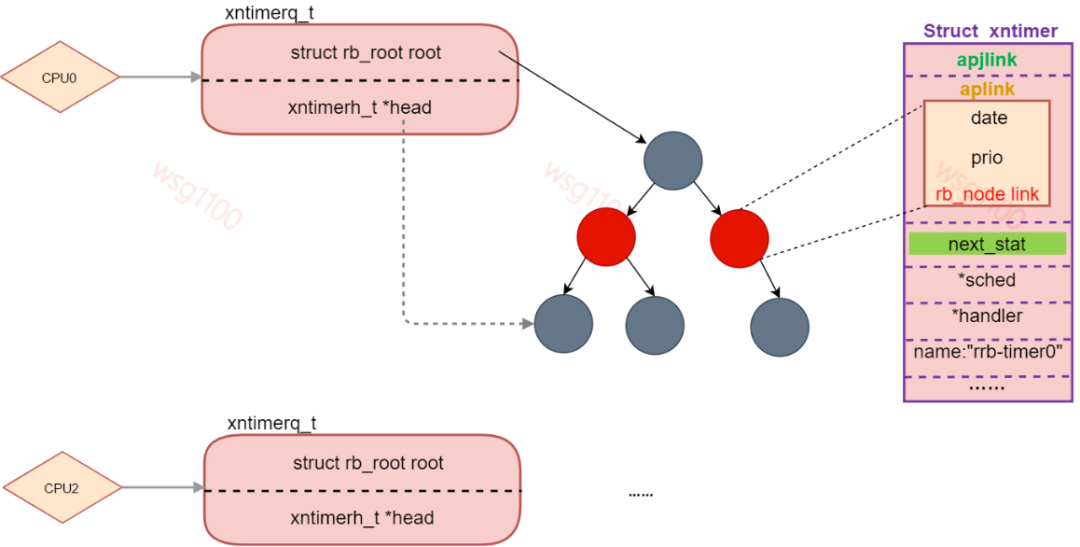
status:定时器状态,所有状态为如下:
#define XNTIMER_DEQUEUED 0x00000001 /*没有挂在xnclock上*/ #define XNTIMER_KILLED 0x00000002 /*该定时器已经被取消*/ #define XNTIMER_PERIODIC 0x00000004 /*该定时器是一个周期定时器*/ #define XNTIMER_REALTIME 0x00000008 /*定时器相对于Linux walltime定时*/ #define XNTIMER_FIRED 0x00000010 /*定时已经到期*/ #define XNTIMER_NOBLCK 0x00000020 /*非阻塞定时器*/ #define XNTIMER_RUNNING 0x00000040 /*定时器已经start*/ #define XNTIMER_KGRAVITY 0x00000080 /*该timer是一个内核态timer*/ #define XNTIMER_UGRAVITY 0x00000100 /*该timer是一个用户态timer*/ #define XNTIMER_IGRAVITY 0 /*该timer是一个中断timer*/
interval、interval_ns:周期定时器的定时周期,分别是tick 和ns,0表示这个xntimer 是单次定时的。
handler:定时器到期后执行的函数。
sched:该timer所在的sched,每个cpu核上有一个sched,管理本cpu上的线程调度,timer又需要本cpu的lapic定时,所以指定了sched就指定了该timer所属cpu。
xntimer 使用需要先调用xntimer_init()初始化xntimer结构成员,然后xntimer_start()启动这个xntimer,启动timer就是将它插入xnclock管理的红黑树。
xntimer_init()是一个宏,内部调用__xntimer_init初始化timer,参数timer:需要初始化的timer;clock:该timer是依附于哪个xnclock,也就是说哪个xnclock来处理我是否触发,没有自定义就是xnclock,在timer_start的时候就会将这个timer挂到对应的xnclock上去;handler:该timer到期后执行的hanler;sched:timer所属的sched;flags:指定该timer标志。
#define xntimer_init(__timer, __clock, __handler, __sched, __flags)
do {
__xntimer_init(__timer, __clock, __handler, __sched, __flags);
xntimer_set_name(__timer, #__handler);
} while (0)
void __xntimer_init(struct xntimer *timer,
struct xnclock *clock,
void (*handler)(struct xntimer *timer),
struct xnsched *sched,
int flags)
{
spl_t s __maybe_unused;
#ifdef CONFIG_XENO_OPT_EXTCLOCK
timer->clock = clock;
#endif
xntimerh_init(&timer->aplink);
xntimerh_date(&timer->aplink) = XN_INFINITE;//0
xntimer_set_priority(timer, XNTIMER_STDPRIO);
timer->status = (XNTIMER_DEQUEUED|(flags & XNTIMER_INIT_MASK)); // (0x01 | flags & 0x000001A0)
timer->handler = handler;
timer->interval_ns = 0;
timer->sched = NULL;
/*
* Set the timer affinity, preferably to xnsched_cpu(sched) if
* sched was given, CPU0 otherwise.
*/
if (sched == NULL)
sched = xnsched_struct(0);
xntimer_set_affinity(timer, sched);
#ifdef CONFIG_XENO_OPT_STATS
#ifdef CONFIG_XENO_OPT_EXTCLOCK
timer->tracker = clock;
#endif
ksformat(timer->name, XNOBJECT_NAME_LEN, "%d/%s",
task_pid_nr(current), current->comm);
xntimer_reset_stats(timer);
xnlock_get_irqsave(&nklock, s);
list_add_tail(&timer->next_stat, &clock->timerq);
clock->nrtimers++;
xnvfile_touch(&clock->timer_vfile);
xnlock_put_irqrestore(&nklock, s);
#endif /* CONFIG_XENO_OPT_STATS */
}
前面几行都是初始化xntimer 结构体指针,xntimer_set_affinity(timer, sched)表示将timer移到sched上(timer->shced=sched)。后面将这个初始化的time加到xnclock 的timerq队列,nrtimers加1。基本成员初始化完了,还有优先级没有设置,aplink中的优先级就代表了该timer的优先级:
static inline void xntimer_set_priority(struct xntimer *timer,
int prio)
{
xntimerh_prio(&timer->aplink) = prio;/*设置timer节点优先级*/
}
启动一个定时器xntimer_start()代码如下:
int xntimer_start(struct xntimer *timer,
xnticks_t value, xnticks_t interval,
xntmode_t mode)
{
struct xnclock *clock = xntimer_clock(timer);
xntimerq_t *q = xntimer_percpu_queue(timer);
xnticks_t date, now, delay, period;
unsigned long gravity;
int ret = 0;
trace_cobalt_timer_start(timer, value, interval, mode);
if ((timer->status & XNTIMER_DEQUEUED) == 0)
xntimer_dequeue(timer, q);
now = xnclock_read_raw(clock);
timer->status &= ~(XNTIMER_REALTIME | XNTIMER_FIRED | XNTIMER_PERIODIC);
switch (mode) {
case XN_RELATIVE:
if ((xnsticks_t)value < 0)
return -ETIMEDOUT;
date = xnclock_ns_to_ticks(clock, value) + now;
break;
case XN_REALTIME:
timer->status |= XNTIMER_REALTIME;
value -= xnclock_get_offset(clock);
/* fall through */
default: /* XN_ABSOLUTE || XN_REALTIME */
date = xnclock_ns_to_ticks(clock, value);
if ((xnsticks_t)(date - now) <= 0) {
if (interval == XN_INFINITE)
return -ETIMEDOUT;
/*
* We are late on arrival for the first
* delivery, wait for the next shot on the
* periodic time line.
*/
delay = now - date;
period = xnclock_ns_to_ticks(clock, interval);
date += period * (xnarch_div64(delay, period) + 1);
}
break;
}
/*
* To cope with the basic system latency, we apply a clock
* gravity value, which is the amount of time expressed in
* clock ticks by which we should anticipate the shot for any
* outstanding timer. The gravity value varies with the type
* of context the timer wakes up, i.e. irq handler, kernel or
* user thread.
*/
gravity = xntimer_gravity(timer);
xntimerh_date(&timer->aplink) = date - gravity;
if (now >= xntimerh_date(&timer->aplink))
xntimerh_date(&timer->aplink) += gravity / 2;
timer->interval_ns = XN_INFINITE;
timer->interval = XN_INFINITE;
if (interval != XN_INFINITE) {
timer->interval_ns = interval;
timer->interval = xnclock_ns_to_ticks(clock, interval);
timer->periodic_ticks = 0;
timer->start_date = date;
timer->pexpect_ticks = 0;
timer->status |= XNTIMER_PERIODIC;
}
timer->status |= XNTIMER_RUNNING;
xntimer_enqueue_and_program(timer, q);
return ret;
}
启动一个timer即将该timer插入xnclock 红黑树xntimerq_t。参数value表示定时时间、interval为0表示这个timer是单次触发,非0表示周期定时器定时间隔,value和interval的单位由mode决定,当mode设置为XN_RELATIVE表示相对定时定时、XN_REALTIME为相对linux时间定时,时间都为ns,其他则为绝对定时单位为timer的tick。
首先取出红黑树根节点q,如果这个timer的状态是从队列删除(其他地方取消了这个定时器),就先把他从红黑树中删除。读取tsc得到此时tsc的tick值now,然后根据参数计算timer的到期时间date,中间将单位转换为ticks。下面开始设置红黑树中的最终值,xntimer_gravity(timer)根据这个timer为谁服务取出对应的gravity。
static inline unsigned long xntimer_gravity(struct xntimer *timer)
{
struct xnclock *clock = xntimer_clock(timer);
if (timer->status & XNTIMER_KGRAVITY)/*内核空间定时器*/
return clock->gravity.kernel;
if (timer->status & XNTIMER_UGRAVITY)/*用户空间定时器*/
return clock->gravity.user;
return clock->gravity.irq;/*中断*/
}
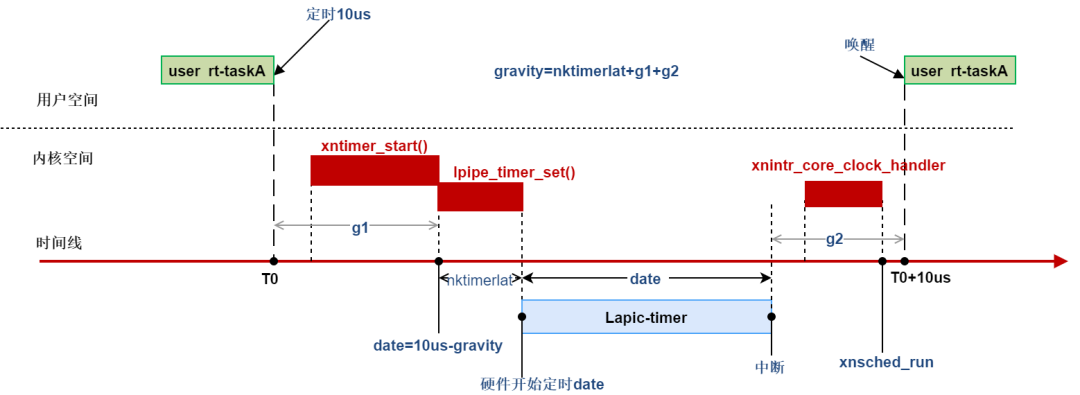
为什么要设置gravity呢?xenomai是个实时系统必须保证定时器的精确,xntimer都是由硬件timer产生中断后处理的,如果没有gravity,对于用户空间实时任务RT:假如此时时间刻度是0,该任务定时10us后触发定时器,10us后,产生了中断,此时时间刻度为10us,开始处理xntimer,然后切换回内核空间执行调度,最后切换回用户空间,从定时器到期到最后切换回RT也是需要时间的,已经超过RT所定的10us,因此,需要得到定时器超时->回到用户空间的这段时间gravity;不同空间的任务经过的路径不一样,所以针对kernel、user和irq分别计算gravity,当任务定时,定时器到期时间date-gravity才是xntimer的触发时间。当切换回原来的任务时刚好是定时时间。
gravity是怎样计算的,xenomai初始化相关文章分析;
最后将timer状态设置为XNTIMER_RUNNING,调用xntimer_enqueue_and_program(timer, q)将timer按超时时间date和优先级插入该CPU红黑树timedata,新加入了一个timer就需要重新看看,最近超时的timer是哪一个,然后设置底层硬件timer的下一个event时间,为最近一个要超时的timer date:
void xntimer_enqueue_and_program(struct xntimer *timer, xntimerq_t *q)
{
xntimer_enqueue(timer, q);/*添加到红黑树*/
if (xntimer_heading_p(timer)) {/*这个timer处于第一个节点或者需要重新调度的sched的第二个节点*/
struct xnsched *sched = xntimer_sched(timer);/*timer所在的sched*/
struct xnclock *clock = xntimer_clock(timer);/*当前存数所在的CPU*/
if (sched != xnsched_current())/*不是当前CPU任务的定时器*/
xnclock_remote_shot(clock, sched);/*给当前CPU发送ipipe_send_ipi(IPIPE_HRTIMER_IPI),让 sched 对应CPU重新调度*/
else
xnclock_program_shot(clock, sched);/*设置下一个one shot*/
}
}
int xntimer_heading_p(struct xntimer *timer)
{
struct xnsched *sched = timer->sched;
xntimerq_t *q;
xntimerh_t *h;
q = xntimer_percpu_queue(timer);
h = xntimerq_head(q);
if (h == &timer->aplink)/*timer 就是第一个*/
return 1;
if (sched->lflags & XNHDEFER) {/*处于重新调度状态*/
h = xntimerq_second(q, h);/*这个timer 处于重新调度状态下红黑树下 */
if (h == &timer->aplink)
return 1;
}
return 0;
}
由于head始终指向时间最小的timer,xntimer_heading_p()中先看head是不是刚刚插入的这个timer,如果是并且是本CPU上的timer就直接设置这timer的时间为lapic-timer的中断时间,对应22行返回->执行10行。
如果是最小但是不是本CPU上的就需要通过ipipe向timer所在CPU发送一个中断信号IPIPE_HRTIMER_IPI,告诉那个cpu,那个cpu就会执行中断处理函数xnintr_core_clock_handler(),对应22行返回->执行8行,为什么是IPIPE_HRTIMER_IPI?相当于模拟底层lapic-timer 产生了一个event事件,ipipe会让那个cpu 执行xnintr_core_clock_handler()对timer进行一个刷新,重新对底层硬件timer编程。
如果新插入的timer不是最小的,但是所在的sched处于XNHDEFER状态,说明第一个timer虽然最小,但是这个最小的如果到期暂时不需要处理,那就取出定时时间第二小的timer,看是不是新插入的timer,如果是,返回1,继续决定是编程还是发中断信号。
如果其他情况,那就不用管了,启动定时器流程完毕。一个一个timer到期后总会处理到新插入的这个的。
其中的向某个cpu发送中断信号函数如下,IPIPE_HRTIMER_IPI是注册到xnsched_realtime_domain的中断,底层硬件timer产生中断的中断号就是IPIPE_HRTIMER_VECTOR,这里的发送中断是通过中断控制器APIC来完成的,APIC会给对应cpu产生一个中断,然后就会被ipipe通过ipipeline,优先给xnsched_realtime_domain处理,ipipe domain管理说过:
void xnclock_core_remote_shot(struct xnsched *sched)
{
ipipe_send_ipi(IPIPE_HRTIMER_IPI, *cpumask_of(xnsched_cpu(sched)));
}
int xntimer_setup_ipi(void)
{
return ipipe_request_irq(&xnsched_realtime_domain,
IPIPE_HRTIMER_IPI,
(ipipe_irq_handler_t)xnintr_core_clock_handler,
NULL, NULL);
}
对底层timer编程的函调用xnclock_core_local_shot()函数,最后调用ipipe_timer_set(delay)进行设置,event时间:
static inline void xnclock_program_shot(struct xnclock *clock,
struct xnsched *sched)
{
xnclock_core_local_shot(sched);
}
void xnclock_core_local_shot(struct xnsched *sched)
{
.......
delay = xntimerh_date(&timer->aplink) - xnclock_core_read_raw();
if (delay < 0)
delay = 0;
else if (delay > ULONG_MAX)
delay = ULONG_MAX;
ipipe_timer_set(delay);
}
ipipe_timer_set()中先获取这个cpu的percpu_timer t,然后将定时时间转换为硬件的tick数,最后调用t->set(tdelay, t->timer_set)进行设置。这里的percpu_timer 与ipipe 相关下面解析,这里只用知道最后是调用了percpu_timer 的set函数,这个set函数是直接设置硬件lapic-timer的。
void ipipe_timer_set(unsigned long cdelay)
{
unsigned long tdelay;
struct ipipe_timer *t;
t = __ipipe_raw_cpu_read(percpu_timer);
.......
/*将时间转换定时器 频率数*/
tdelay = cdelay;
if (t->c2t_integ != 1)
tdelay *= t->c2t_integ;
if (t->c2t_frac)
tdelay += ((unsigned long long)cdelay * t->c2t_frac) >> 32;
if (tdelay < t->min_delay_ticks)
tdelay = t->min_delay_ticks;
if (tdelay > t->max_delay_ticks)
tdelay = t->max_delay_ticks;
if (t->set(tdelay, t->timer_set) < 0)
ipipe_raise_irq(t->irq);
}
总结:启动一个xntimer,首先确定属于哪个cpu,然后将它插入到该cpu的xntimer管理结构timerdata,插入时按定时长短和优先级来决定,最后设置底层硬件timer产生下一个中断的时间点。
2.3 ipipe tick设备管理
linux时间系统中说到有多少个硬件timer,就会注册多少个clock event device,最后linux会为每个cpu选择一个合适的clock event来为tick device产生event。xenomai系统的运行也需要这么一个合适的硬件timer来产生event,由于xenomai需要的硬件都是由ipipe来提供,所以ipipe需要知道系统中有哪些clock event device被注册,然后ipipe为每一个cpu核选择一个合适的。
ipipe将linux中clock event device按xenomai系统需要重新抽象为结构体struct ipipe_timer,系统中有一个全局链表timer,当底层驱动调用clockevents_register_device,注册clock event设备时ipipe对应的创建一个ipipe_timer插入链表timer。struct ipipe_timer如下:
struct ipipe_timer {
int irq;
void (*request)(struct ipipe_timer *timer, int steal);
int (*set)(unsigned long ticks, void *timer);
void (*ack)(void);
void (*release)(struct ipipe_timer *timer);
/* Only if registering a timer directly */
const char *name;
unsigned rating;
unsigned long freq;
unsigned long min_delay_ticks;
unsigned long max_delay_ticks;
const struct cpumask *cpumask;
/* For internal use */
void *timer_set; /* pointer passed to ->set() callback */
struct clock_event_device *host_timer;/*依赖的clock event*/
struct list_head link;
unsigned c2t_integ;
unsigned c2t_frac;
/* For clockevent interception */
u32 real_mult;
u32 real_shift;
void (*mode_handler)(enum clock_event_mode mode,
struct clock_event_device *);
int orig_mode;
int (*orig_set_state_periodic)(struct clock_event_device *);
int (*orig_set_state_oneshot)(struct clock_event_device *);
int (*orig_set_state_oneshot_stopped)(struct clock_event_device *);
int (*orig_set_state_shutdown)(struct clock_event_device *);
int (*orig_set_next_event)(unsigned long evt,
struct clock_event_device *cdev);
unsigned int (*refresh_freq)(void);
};
irq:该ipipe_timer所依赖的clock_event_device的中断号,产生中断时ipipe将中断分配给谁处理用到;
request:设定clock_event_device模式的函数
set:设置下一个定时中断的函数,这个就是上面启动xntimer时的那个函数
ack:产生中断后中断清除函数
rating:该clock_event_device的raning级别
freq:该clock_event_device的运行频率
min_delay_ticks、max_delay_ticks:最小、最大定时时间
cpumask:cpu掩码,标识可以为哪个cpu提供定时服务
host_timer:这个ipipe_timer对应是哪个clock_event_device
link:链表节点,加入全局链表timer时使用
orig_set_state_periodic、orig_set_state_oneshot、orig_set_state_oneshot_stopped、orig_set_next_event,为xenomai提供服务需要将clock_event_device中一些已经设置的函数替换,这些用来备份原clock_event_device中的函数。
再来看一看clock xevent注册函数clockevents_register_device(),ipipe补丁在其中插入了一个注册函数ipipe_host_timer_register()先把clock xevent管理起来:
void clockevents_register_device(struct clock_event_device *dev)
{
unsigned long flags;
......
ipipe_host_timer_register(dev);
....
}
static int get_dev_mode(struct clock_event_device *evtdev)
{
if (clockevent_state_oneshot(evtdev) ||
clockevent_state_oneshot_stopped(evtdev))
return CLOCK_EVT_MODE_ONESHOT;
if (clockevent_state_periodic(evtdev))
return CLOCK_EVT_MODE_PERIODIC;
if (clockevent_state_shutdown(evtdev))
return CLOCK_EVT_MODE_SHUTDOWN;
return CLOCK_EVT_MODE_UNUSED;
}
void ipipe_host_timer_register(struct clock_event_device *evtdev)
{
struct ipipe_timer *timer = evtdev->ipipe_timer;
if (timer == NULL)
return;
timer->orig_mode = CLOCK_EVT_MODE_UNUSED;
if (timer->request == NULL)
timer->request = ipipe_timer_default_request;/*设置request函数*/
/*
* By default, use the same method as linux timer, on ARM at
* least, most set_next_event methods are safe to be called
* from Xenomai domain anyway.
*/
if (timer->set == NULL) {
timer->timer_set = evtdev;
timer->set = (typeof(timer->set))evtdev->set_next_event;/*设定的counter的cycle数值*/
}
if (timer->release == NULL)
timer->release = ipipe_timer_default_release;
if (timer->name == NULL)
timer->name = evtdev->name;
if (timer->rating == 0)
timer->rating = evtdev->rating;
timer->freq = (1000000000ULL * evtdev->mult) >> evtdev->shift;/*1G*mult >> shift*/
if (timer->min_delay_ticks == 0)
timer->min_delay_ticks =
(evtdev->min_delta_ns * evtdev->mult) >> evtdev->shift;
if (timer->max_delay_ticks == 0)
timer->max_delay_ticks =
(evtdev->max_delta_ns * evtdev->mult) >> evtdev->shift;
if (timer->cpumask == NULL)
timer->cpumask = evtdev->cpumask;
timer->host_timer = evtdev;
ipipe_timer_register(timer);
}
这里面通过evtdev直接将一些结构体成员赋值,这里需要注意的的是timer->set = (typeof(timer->set))evtdev->set_next_event;对于lapic-timer来说timer->set=lapic_next_event,如果CPU支持tsc deadline特性则是timer->set=lapic_next_deadline,TSC-deadline模式允许软件使用本地APIC timer 在绝对时间发出中断信号,使用tsc来设置deadline,为了全文统一,使用apic-timer,这决定了xenomai是否能直接控制硬件,然后调用ipipe_timer_register()将ipipe_timer添加到链表timer完成注册:
void ipipe_timer_register(struct ipipe_timer *timer)
{
struct ipipe_timer *t;
unsigned long flags;
if (timer->timer_set == NULL)
timer->timer_set = timer;
if (timer->cpumask == NULL)
timer->cpumask = cpumask_of(smp_processor_id());
raw_spin_lock_irqsave(&lock, flags);
list_for_each_entry(t, &timers, link) {/*按插入链表*/
if (t->rating <= timer->rating) {
__list_add(&timer->link, t->link.prev, &t->link);
goto done;
}
}
list_add_tail(&timer->link, &timers);/*按插入全局链表尾*/
done:
raw_spin_unlock_irqrestore(&lock, flags);
}
xenomai在每一个cpu核都需要一个ipipe_timer 来推动调度、定时等,ipipe为每个CPU分配了一个ipipe_timer指针percpu_timer,链表timers记录了所有ipipe_timer,这样就可以从链表中选择可供xenomai使用的ipipe_timer:
static DEFINE_PER_CPU(struct ipipe_timer *, percpu_timer);
另外,在3.ipipe domian管理说到每个cpu上管理不同域的结构体ipipe_percpu_data,里面有一个成员变量int hrtimer_irq,这个hrtimer_irq是用来存放为这个cpu提供event的硬件timer的中断号的,用于将ipipe_percpu_data与ipipe_timer联系起来,介绍完相关数据结构下面来看xenomai 时钟系统初始化流程。
DECLARE_PER_CPU(struct ipipe_percpu_data, ipipe_percpu);
2.4 xenomai 时钟系统初始化流程
xenomai内核系统初始化源码文件:kernelxenomaiinit.c,时钟系统在xenomai初始化流程中调用mach_setup()完成硬件相关初始化:
xenomai_init(void)
->mach_setup()
static int __init mach_setup(void)
{
struct ipipe_sysinfo sysinfo;
int ret, virq;
ret = ipipe_select_timers(&xnsched_realtime_cpus);
...
ipipe_get_sysinfo(&sysinfo);/*获取 系统ipipe 信息*/
if (timerfreq_arg == 0)
timerfreq_arg = sysinfo.sys_hrtimer_freq;
if (clockfreq_arg == 0)
clockfreq_arg = sysinfo.sys_hrclock_freq;
cobalt_pipeline.timer_freq = timerfreq_arg;
cobalt_pipeline.clock_freq = clockfreq_arg;
if (cobalt_machine.init) {
ret = cobalt_machine.init();/* mach_x86_init */
if (ret)
return ret;
}
ipipe_register_head(&xnsched_realtime_domain, "Xenomai");
......
ret = xnclock_init(cobalt_pipeline.clock_freq);/*初始化xnclock,为Cobalt提供clock服务时钟*/
return 0;
首先调用ipipe_select_timers()来为每个cpu选择一个ipipe_timer。
int ipipe_select_timers(const struct cpumask *mask)
{
unsigned hrclock_freq;
unsigned long long tmp;
struct ipipe_timer *t;
struct clock_event_device *evtdev;
unsigned long flags;
unsigned cpu;
cpumask_t fixup;
.......
if (__ipipe_hrclock_freq > UINT_MAX) {
tmp = __ipipe_hrclock_freq;
do_div(tmp, 1000);
hrclock_freq = tmp;
} else
hrclock_freq = __ipipe_hrclock_freq;/*1000ULL * cpu_khz*/
.......
for_each_cpu(cpu, mask) {/*从timers 为每一个CPU选择一个 percpu_timer*/
list_for_each_entry(t, &timers, link) {/*遍历ipipe全局timer链表*/
if (!cpumask_test_cpu(cpu, t->cpumask))
continue;
evtdev = t->host_timer;
if (evtdev && clockevent_state_shutdown(evtdev))/*该CPU timer 被软件shutdown则跳过*/
continue;
goto found;
}
....
goto err_remove_all;
found:
install_pcpu_timer(cpu, hrclock_freq, t);/*设置每一个CPU的timer*/
}
.......
flags = ipipe_critical_enter(ipipe_timer_request_sync);
ipipe_timer_request_sync();/*如果支持,则切换到单触发模式。*/
ipipe_critical_exit(flags);
.......
}
先得到从全局变量cpu_khz得到tsc频率保存到hrclock_freq,然后为xenomai运行的每一个cpu核进行ippie_timer选择,对每一个遍历全局链表timers,取出evtdev,看是否能为该cpu服务,并且没有处于关闭状态。evtdev在Linux没有被使用就会被Linux关闭。最后选出来的也就是lapic-timer 。
找到合适的tevtdev后调用install_pcpu_timer(cpu, hrclock_freq, t),为该cpu设置ipipe_timer:
static void install_pcpu_timer(unsigned cpu, unsigned hrclock_freq,
struct ipipe_timer *t)
{
per_cpu(ipipe_percpu.hrtimer_irq, cpu) = t->irq;
per_cpu(percpu_timer, cpu) = t;
config_pcpu_timer(t, hrclock_freq);
}
主要是设置几个xenomai相关的precpu变量,ipipe_percpu.hrtimer_irq设置为该evtdev的irq,percpu_timer为该evtdev对应的ipipe_timer,然后计算ipipe_timer中lapic-timer与tsc频率之间的转换因子c2t_integ、c2t_frac;
回到ipipe_select_timers(),通过ipipe给每一个cpu发送一个中断IPIPE_CRITICAL_IPI,将每一个lapic-timer通过ipipe_timer->request设置为oneshot模式。
回到mach_setup(),为每个cpu选出ipipe_timer后获取此时系统信息:ipipe_get_sysinfo(&sysinfo)
int ipipe_get_sysinfo(struct ipipe_sysinfo *info)
{
info->sys_nr_cpus = num_online_cpus();/*运行的cpu数据*/
info->sys_cpu_freq = __ipipe_cpu_freq;/*1000ULL * cpu_khz*/
info->sys_hrtimer_irq = per_cpu(ipipe_percpu.hrtimer_irq, 0);/*cpu0的ipipe_timer中断号*/
info->sys_hrtimer_freq = __ipipe_hrtimer_freq;/*time的频率*/
info->sys_hrclock_freq = __ipipe_hrclock_freq;/*1000ULL * cpu_khz*/
return 0;
}
在这里还是觉得有问题,CPU和TSC、timer三者频率不一定相等。
这几个变量在接下来初始化xnclock中使用。xnclock_init(cobalt_pipeline.clock_freq):
int __init xnclock_init(unsigned long long freq)
{
xnclock_update_freq(freq);
nktimerlat = xnarch_timer_calibrate();
xnclock_reset_gravity(&nkclock); /* reset_core_clock_gravity */
xnclock_register(&nkclock, &xnsched_realtime_cpus);
return 0;
}
xnclock_update_freq(freq)计算出tsc频率与时间ns单位的转换因子tsc_scale,tsc_shift,计算流程可参考文档实时内核与linux内核时钟漂移过大原因.docx
xnarch_timer_calibrate()计算出每次对硬件timer编程这个执行过程需要多长时间,也就是测量ipipe_timer_set()这个函数的执行时间nktimerlat,计算方法是这样先确保测量这段时间timer不会触发中断干扰,所以先用ipipe_timer_set()给硬件timer设置一个很长的超时值,然后开始测量,先从TSC读取现在的时间tick值t0,然后循环执行100次ipipe_timer_set(),接着从TSC读取现在的时间tick值t1,ipipe_timer_set()平均每次的执行时间是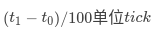 ,为了算上其他可能的延迟5%,nktimerlat=(t1−t0)/105;
,为了算上其他可能的延迟5%,nktimerlat=(t1−t0)/105;
下面计算对kernel、user、irq xntimer精确定时的gravity,上面已经说过为甚需要这个,xnclock_reset_gravity(&nkclock)调用执行xnclock->ops.reset_gravity(),也就是reset_core_clock_gravity()函数:
static void reset_core_clock_gravity(struct xnclock *clock)
{
struct xnclock_gravity gravity;
xnarch_get_latencies(&gravity);
gravity.user += nktimerlat;
if (gravity.kernel == 0)
gravity.kernel = gravity.user;
if (gravity.irq == 0)
gravity.irq = nktimerlat;
set_core_clock_gravity(clock, &gravity);
}
首先通过xnarch_get_latencies()函数来计算各空间的gravity,其实这个函数里没有具体的计算流程,给的都是一些经验值,要么我们自己编译时配置:
static inline void xnarch_get_latencies(struct xnclock_gravity *p)
{
unsigned long sched_latency;
#if CONFIG_XENO_OPT_TIMING_SCHEDLAT != 0
sched_latency = CONFIG_XENO_OPT_TIMING_SCHEDLAT;
#else /* !CONFIG_XENO_OPT_TIMING_SCHEDLAT */
if (strcmp(ipipe_timer_name(), "lapic") == 0) {
#ifdef CONFIG_SMP
if (num_online_cpus() > 1)
sched_latency = 3350;
else
sched_latency = 2000;
#else /* !SMP */
sched_latency = 1000;
#endif /* !SMP */
} else if (strcmp(ipipe_timer_name(), "pit")) { /* HPET */
#ifdef CONFIG_SMP
if (num_online_cpus() > 1)
sched_latency = 3350;
else
sched_latency = 1500;
#else /* !SMP */
sched_latency = 1000;
#endif /* !SMP */
} else {
sched_latency = (__get_bogomips() < 250 ? 17000 :
__get_bogomips() < 2500 ? 4200 :
3500);
#ifdef CONFIG_SMP
sched_latency += 1000;
#endif /* CONFIG_SMP */
}
#endif /* !CONFIG_XENO_OPT_TIMING_SCHEDLAT */
p->user = sched_latency;
p->kernel = CONFIG_XENO_OPT_TIMING_KSCHEDLAT;
p->irq = CONFIG_XENO_OPT_TIMING_IRQLAT;
}
首先判断宏CONFIG_XENO_OPT_TIMING_SCHEDLAT 如果不等于0,说明我们自己配置了这个数,直接赋值就行,否则的话,根据xenomai使用的定时器是lapic 还是hept给不同的一些经验值了:
p->user = CONFIG_XENO_OPT_TIMING_SCHEDLAT; p->kernel = CONFIG_XENO_OPT_TIMING_KSCHEDLAT; p->irq = CONFIG_XENO_OPT_TIMING_IRQLAT;
CONFIG_XENO_OPT_TIMING_SCHEDLAT宏在内核编译时设置,默认为0,使用已有的经验值:
[*] Xenomai/cobalt ---> Latency settings ---> (0) User scheduling latency (ns) (0) Intra-kernel scheduling latency (ns) (0) Interrupt latency (ns)
实际使用后发现这个经验值也不太准,从测试数据看i5处理器与赛扬就存在差别,如果开启内核trace,就更不准了.
计算出gravity后加上ipipe_timer_set()执行需要的时间nktimerlat,就是最终的gravity。以用户空间实时程序定时为例如下(图中时间段与比例无关):
 到此mach_setup()函数中上层软件时钟相关初始化完了,但xenomai还不能直接对硬件timer,此时xenomai进程调度还没初始化,硬件timer与内核调度等息息相关,xenomai内核还不能掌管硬件timer,不能保证linux愉快运行,硬抢过来只能一起阵亡。等xenomai内核任务管理等初始化完毕,给Linux舒适的运行空间,就可以直接控制硬件timer了,下面继续解析这个函数sys_init();
到此mach_setup()函数中上层软件时钟相关初始化完了,但xenomai还不能直接对硬件timer,此时xenomai进程调度还没初始化,硬件timer与内核调度等息息相关,xenomai内核还不能掌管硬件timer,不能保证linux愉快运行,硬抢过来只能一起阵亡。等xenomai内核任务管理等初始化完毕,给Linux舒适的运行空间,就可以直接控制硬件timer了,下面继续解析这个函数sys_init();
2.5 xenomai接管lapic-timer
sys_init()涉及每个CPU上的调度结构体初始化等。先插以点内容,每个cpu上的xenomai 调度由对象xnsched来管理,xnsched对象每个cpu有一个,其中包含各类sched class,还包含两个xntimer,一个host timer ---htimer,主要给linux定时,另一个循环计时timer rrbtimer;一个xnthead结构rootcb,xenomai调度的是线程,每个实时线程使用xnthead结构表示,这个rootcb表示本cpu上xenomai调度的linux,在双核下linux只是xenomai的一个idle任务,cpu0上xnsched结构如下:
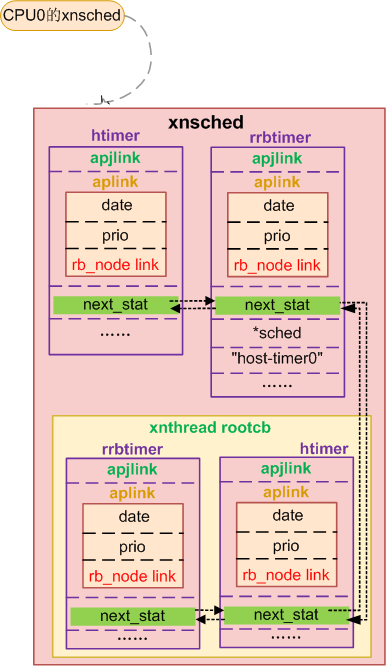
详细的结构后面会分析,这里只解析时钟相关部分。
static __init int sys_init(void)
{
struct xnsched *sched;
void *heapaddr;
int ret, cpu;
if (sysheap_size_arg == 0)
sysheap_size_arg = CONFIG_XENO_OPT_SYS_HEAPSZ;/**/
heapaddr = xnheap_vmalloc(sysheap_size_arg * 1024);/*256 * 1024*/
.....
xnheap_set_name(&cobalt_heap, "system heap");
for_each_online_cpu(cpu) {
sched = &per_cpu(nksched, cpu);
xnsched_init(sched, cpu);
}
#ifdef CONFIG_SMP
ipipe_request_irq(&xnsched_realtime_domain,
IPIPE_RESCHEDULE_IPI,
(ipipe_irq_handler_t)__xnsched_run_handler,
NULL, NULL);
#endif
xnregistry_init();
/*
* If starting in stopped mode, do all initializations, but do
* not enable the core timer.
*/
if (realtime_core_state() == COBALT_STATE_WARMUP) {
ret = xntimer_grab_hardware(); /*霸占硬件host定时器*/
.....
set_realtime_core_state(COBALT_STATE_RUNNING); /*更新实时内核状态*/
}
return 0;
}
sys_init()中先初始化内核堆空间,初始化每个CPU上的调度结构体xnsched、创建idle线程,也就是上面说到的roottcb,多cpu核调度等,经过这一些步骤,LInux已经变成xenomai的一个idle线程了,最后调用xntimer_grab_hardware(),接管硬件timer:
int xntimer_grab_hardware(void)
{
struct xnsched *sched;
int ret, cpu, _cpu;
spl_t s;
.......
nkclock.wallclock_offset =
xnclock_get_host_time() - xnclock_read_monotonic(&nkclock);
ret = xntimer_setup_ipi(); ipipe_request_irq(&xnsched_realtime_domain,IPIPE_HRTIMER_IPI,
(ipipe_irq_handler_t)xnintr_core_clock_handler, NULL, NULL);
for_each_realtime_cpu(cpu) {
ret = grab_hardware_timer(cpu);
if (ret < 0)
goto fail;
xnlock_get_irqsave(&nklock, s);
sched = xnsched_struct(cpu);
if (ret > 1)
xntimer_start(&sched->htimer, ret, ret, XN_RELATIVE);
else if (ret == 1)
xntimer_start(&sched->htimer, 0, 0, XN_RELATIVE);
#ifdef CONFIG_XENO_OPT_WATCHDOG /*启动看门狗定时器*/
xntimer_start(&sched->wdtimer, 1000000000UL, 1000000000UL, XN_RELATIVE);
xnsched_reset_watchdog(sched);
#endif
xnlock_put_irqrestore(&nklock, s);
}
......
return ret;
}
注册xnclock时nkclock.wallclock_offset没有设置,现在设置也就是walltime的时间与tsc 的时间偏移。然后注册IPIPE_HRTIMER_IPI中断到xnsched_realtime_domain,9.2xntimer那一节启动一个xntimer需要通知其他cpu处理时发送的IPIPE_HRTIMER_IPI:
int xntimer_setup_ipi(void)
{
return ipipe_request_irq(&xnsched_realtime_domain,
IPIPE_HRTIMER_IPI,
(ipipe_irq_handler_t)xnintr_core_clock_handler,
NULL, NULL);
}
接下来就是重要的为每个cpu接管硬件timer了,其实过程也简单,就是将原来lcock event的一些操作函数替换来达到目的,每个cpu上xenomai调度管理结构xnsched,每个xnsched中有一个定时器htimer,这个xntimer就是为linux服务的,根据底层timer的类型,后启动htimer,htimer 推动linux继时间子系统运行。这些后面会详细解析。回到接管timer函数grab_hardware_timer(cpu):
static int grab_hardware_timer(int cpu)
{
int tickval, ret;
ret = ipipe_timer_start(xnintr_core_clock_handler,
switch_htick_mode, program_htick_shot, cpu);
switch (ret) {
case CLOCK_EVT_MODE_PERIODIC:
/*
* Oneshot tick emulation callback won't be used, ask
* the caller to start an internal timer for emulating
* a periodic tick.
*/
tickval = 1000000000UL / HZ;
break;
case CLOCK_EVT_MODE_ONESHOT:
/* oneshot tick emulation */
tickval = 1;
break;
case CLOCK_EVT_MODE_UNUSED:
/* we don't need to emulate the tick at all. */
tickval = 0;
break;
case CLOCK_EVT_MODE_SHUTDOWN:
return -ENODEV;
default:
return ret;
}
return tickval;
}
主要的操作在ipipe_timer_start(xnintr_core_clock_handler,switch_htick_mode, program_htick_shot, cpu),后面的就是判断这个timer工作在什么模式,相应的返回好根据模式设置htimer为linux服务;
ipipe_timer_start(xnintr_core_clock_handler,switch_htick_mode, program_htick_shot, cpu)其中的xnintr_core_clock_handler是lapic-timer 产生中断时xenomai内核的处理函数,里面会去处理每个xntimer以及xenomai调度;switch_htick_mode是lapic-timer工作模式切换函数,program_htick_shot函数是对sched->htimer重新定时的函数,这个函数对linux来说特别重要,以后linux就不直接对硬件timer设置定时了,而是给xenomai中的sched->htimer设置。下面是ipipe_timer_start代码:
int ipipe_timer_start(void (*tick_handler)(void),
void (*emumode)(enum clock_event_mode mode,
struct clock_event_device *cdev),
int (*emutick)(unsigned long evt,
struct clock_event_device *cdev),
unsigned int cpu)
{
struct grab_timer_data data;
int ret;
data.tick_handler = tick_handler;/*xnintr_core_clock_handler*/
data.emutick = emutick;/*program_htick_shot*/
data.emumode = emumode;/*switch_htick_mode*/
data.retval = -EINVAL;
ret = smp_call_function_single(cpu, grab_timer, &data, true);/*执行grab_timer*/
return ret ?: data.retval;
}
先将传入的几个函数指正存到结构体data,然后调用smp_call_function_single传给函数grab_timer处理,smp_call_function_single中的smp表示给指定的cpu去执行grab_timer,对应的cpu执行grab_timer(&data):
static void grab_timer(void *arg)
{
struct grab_timer_data *data = arg;
struct clock_event_device *evtdev;
struct ipipe_timer *timer;
struct irq_desc *desc;
unsigned long flags;
int steal, ret;
flags = hard_local_irq_save();
timer = this_cpu_read(percpu_timer);
evtdev = timer->host_timer;
ret = ipipe_request_irq(ipipe_head_domain, timer->irq,
(ipipe_irq_handler_t)data->tick_handler,
NULL, __ipipe_ack_hrtimer_irq);
if (ret < 0 && ret != -EBUSY) {
hard_local_irq_restore(flags);
data->retval = ret;
return;
}
steal = evtdev != NULL && !clockevent_state_detached(evtdev);
if (steal && evtdev->ipipe_stolen == 0) {
timer->real_mult = evtdev->mult;
timer->real_shift = evtdev->shift;
timer->orig_set_state_periodic = evtdev->set_state_periodic;
timer->orig_set_state_oneshot = evtdev->set_state_oneshot;
timer->orig_set_state_oneshot_stopped = evtdev->set_state_oneshot_stopped;
timer->orig_set_state_shutdown = evtdev->set_state_shutdown;
timer->orig_set_next_event = evtdev->set_next_event;
timer->mode_handler = data->emumode;/*switch_htick_mode*/
evtdev->mult = 1;
evtdev->shift = 0;
evtdev->max_delta_ns = UINT_MAX;
if (timer->orig_set_state_periodic)
evtdev->set_state_periodic = do_set_periodic;
if (timer->orig_set_state_oneshot)
evtdev->set_state_oneshot = do_set_oneshot;
if (timer->orig_set_state_oneshot_stopped)
evtdev->set_state_oneshot_stopped = do_set_oneshot_stopped;
if (timer->orig_set_state_shutdown)
evtdev->set_state_shutdown = do_set_shutdown;
evtdev->set_next_event = data->emutick; /* program_htick_shot */
evtdev->ipipe_stolen = 1;
}
hard_local_irq_restore(flags);
data->retval = get_dev_mode(evtdev);
desc = irq_to_desc(timer->irq);
if (desc && irqd_irq_disabled(&desc->irq_data))
ipipe_enable_irq(timer->irq);
if (evtdev->ipipe_stolen && clockevent_state_oneshot(evtdev)) {/* 启动oneshot*/
ret = clockevents_program_event(evtdev,
evtdev->next_event, true);
if (ret)
data->retval = ret;
}
}
首先从percpu_timer取出我们在ipipe_select_timers选择的那个clockevent device evtdev,现在要这个evtdev为xenomai服务,所以将它的中断注册到ipipe_head_domain,当中断来的时候后ipipe会交给ipipe_head_domain调用data->tick_handler也就是xnintr_core_clock_handler处理,xnintr_core_clock_handler中处理xenomai在本CPU当上的调度、定时等。
在struct clock_event_device中ipipe添加了一个标志位ipipe_stolen用来表示该evtdev是不是已经为实时系统服务,是就是1,否则为0,这里当然为0,先将原来evtdev的操作函数备份到’orig_‘打头的成员变量中,设置ipipe_timer的real_mult、real_shift为evtdev的mult、shift,原evtdev的mult、shift设置为1、0,linux计算的时候才能与xntimer定时时间对应起来。
最重要的是把原来evtdev->set_next_event设置成了program_htick_shot,program_htick_shot如下,从此linux就是对shched->htimer 定时器设置定时,来替代原来的evtdev:
static int program_htick_shot(unsigned long delay,
struct clock_event_device *cdev)
{
struct xnsched *sched;
int ret;
spl_t s;
xnlock_get_irqsave(&nklock, s);
sched = xnsched_current();
ret = xntimer_start(&sched->htimer, delay, XN_INFINITE, XN_RELATIVE); /*相对,单次定时*/
xnlock_put_irqrestore(&nklock, s);
return ret ? -ETIME : 0;
}
其余的最后如果evtdev中断没有使能就使能中断,evtdev是oneshot状态启动oneshot,到此xenomai掌管了lpic-tiemr,从此xenomai内核直接设置lpic-tiemr,lpic-tiemr到时产生中断,ipipe调用执行xnintr_core_clock_handler处理lpic-tiemr中断,xnintr_core_clock_handler处理xenomai时钟系统:
void xnintr_core_clock_handler(void)
{
struct xnsched *sched = xnsched_current();
int cpu __maybe_unused = xnsched_cpu(sched);
xnstat_exectime_t *prev;
if (!xnsched_supported_cpu(cpu)) {
#ifdef XNARCH_HOST_TICK_IRQ
ipipe_post_irq_root(XNARCH_HOST_TICK_IRQ);
#endif
return;
}
......
++sched->inesting; /*中断嵌套++*/
sched->lflags |= XNINIRQ; /*在中断上下文状态*/
xnlock_get(&nklock);
xnclock_tick(&nkclock); /* 处理一个时钟tick*/
xnlock_put(&nklock);
trace_cobalt_clock_exit(per_cpu(ipipe_percpu.hrtimer_irq, cpu));
xnstat_exectime_switch(sched, prev);
if (--sched->inesting == 0) { /*如果没有其他中断嵌套,执行从新调度*/
sched->lflags &= ~XNINIRQ;
xnsched_run(); /*调度*/
sched = xnsched_current();
}
/*
* If the core clock interrupt preempted a real-time thread,
* any transition to the root thread has already triggered a
* host tick propagation from xnsched_run(), so at this point,
* we only need to propagate the host tick in case the
* interrupt preempted the root thread.
*/
if ((sched->lflags & XNHTICK) &&
xnthread_test_state(sched->curr, XNROOT))
xnintr_host_tick(sched);
}
xnintr_core_clock_handler中,首先判断产生这个中断的cpu属不属于实时调度cpu,如果不属于,那就把中断post到root域后直接返回,ipipe会在root域上挂起这个中断给linux处理。
如果这是运行xenomai的cpu,接下来调用xnclock_tick(&nkclock),来处理一个时钟tick,里面就是看该cpu上哪些xntimer到期了做相应处理:
void xnclock_tick(struct xnclock *clock)
{
struct xnsched *sched = xnsched_current();
struct xntimer *timer;
xnsticks_t delta;
xntimerq_t *tmq;
xnticks_t now;
xntimerh_t *h;
atomic_only();
......
tmq = &xnclock_this_timerdata(clock)->q;/**/
/*
* Optimisation: any local timer reprogramming triggered by
* invoked timer handlers can wait until we leave the tick
* handler. Use this status flag as hint to xntimer_start().
*/
sched->status |= XNINTCK;
now = xnclock_read_raw(clock);
while ((h = xntimerq_head(tmq)) != NULL) {
timer = container_of(h, struct xntimer, aplink);
delta = (xnsticks_t)(xntimerh_date(&timer->aplink) - now);
if (delta > 0)
break;
trace_cobalt_timer_expire(timer);
xntimer_dequeue(timer, tmq);
xntimer_account_fired(timer);/*timer->fired ++*/
/*
* By postponing the propagation of the low-priority
* host tick to the interrupt epilogue (see
* xnintr_irq_handler()), we save some I-cache, which
* translates into precious microsecs on low-end hw.
*/
if (unlikely(timer == &sched->htimer)) {
sched->lflags |= XNHTICK;
sched->lflags &= ~XNHDEFER;
if (timer->status & XNTIMER_PERIODIC)
goto advance;
continue;
}
/* Check for a locked clock state (i.e. ptracing).*/
if (unlikely(nkclock_lock > 0)) {
if (timer->status & XNTIMER_NOBLCK)
goto fire;
if (timer->status & XNTIMER_PERIODIC)
goto advance;
/*
* We have no period for this blocked timer,
* so have it tick again at a reasonably close
* date in the future, waiting for the clock
* to be unlocked at some point. Since clocks
* are blocked when single-stepping into an
* application using a debugger, it is fine to
* wait for 250 ms for the user to continue
* program execution.
*/
xntimerh_date(&timer->aplink) +=
xnclock_ns_to_ticks(xntimer_clock(timer),
250000000);
goto requeue;
}
fire:
timer->handler(timer);/******************************/
now = xnclock_read_raw(clock);
timer->status |= XNTIMER_FIRED;
/*
* Only requeue periodic timers which have not been
* requeued, stopped or killed.
*/
if ((timer->status &
(XNTIMER_PERIODIC|XNTIMER_DEQUEUED|XNTIMER_KILLED|XNTIMER_RUNNING)) !=
(XNTIMER_PERIODIC|XNTIMER_DEQUEUED|XNTIMER_RUNNING))
continue;
advance:
do {
timer->periodic_ticks++;
xntimer_update_date(timer);
} while (xntimerh_date(&timer->aplink) < now);
requeue:
#ifdef CONFIG_SMP
/*
* If the timer was migrated over its timeout handler,
* xntimer_migrate() re-queued it already.
*/
if (unlikely(timer->sched != sched))
continue;
#endif
xntimer_enqueue(timer, tmq);
}
sched->status &= ~XNINTCK;
xnclock_program_shot(clock, sched);
}
xnclock_tick里主要处理各种类型的xntimer,首先取出本cpu上管理xntimer红黑树的根节点xntimerq_t,然后开始处理,为了安全设置sched状态标识status为XNINTCK,标识该sched正在处理tick,得到现在tsc值now,然后一个while循环,取出红黑树上定时最小的那个xntimer,得到这个xntimer的时间date,如果date减去now大于0,说明最短定时的xntimer都没有到期,那就不需要继续处理,直接跳出循环,执行xnclock_program_shot(clock, sched)设置定时器下一个中断触发时间。
如果有xntimer到期,date减去now小于等于0,首先从红黑树中删除,然后xntimer.fire加1,表示xntimer到期次数,然后处理,这里逻辑有点绕:
1.如果是sched->htimer,就是为Linux定时的,先设置sched->lflags |= XNHTICK,这个标志设置的是lflags不是status,因为linux的不是紧急的,后面本cpu没有高优先级实时任务运行才会给linux处理。接着判断是不是一个周期timer,如果是,goto到advance更新timer时间date,可能已将过去几个周期时间了,所有使用循环一个一个周期的增加直到现在时间now,然后重新插入红黑树。
2.如果这个xntimer是一个非阻塞timer,直接跳转fire执行handler,并设置状态已经FIRED。
3.如果这是一个非htimer的周期定时器,那同样更新时间后重新加入红黑树。
4.以上都不是就将xntimer重新定时250ms,加入红黑树。
xnclock_tick执行返回后,xnstat_exectime_switch()更新该cpu上每个域的执行时间,然后如果没有其他中断嵌套则进行任务调度xnsched_run();
不知经过多少个rt任务切换后回到这个上下文,并且当前cpu运行linux,上次离开这linux的定时器htimer还没处理呢,检查如果当前cpu上运行linux,并且sched->lflags中有XNHTICK标志,那将中断通过ipipe post给linux处理,并清除lflags中的XNHTICK,linux中断子系统就会去只执行eventhandler,处理linux时间子系统。
void xnintr_host_tick(struct xnsched *sched) /* Interrupts off. */
{
sched->lflags &= ~XNHTICK;
#ifdef XNARCH_HOST_TICK_IRQ
ipipe_post_irq_root(XNARCH_HOST_TICK_IRQ);
#endif
}
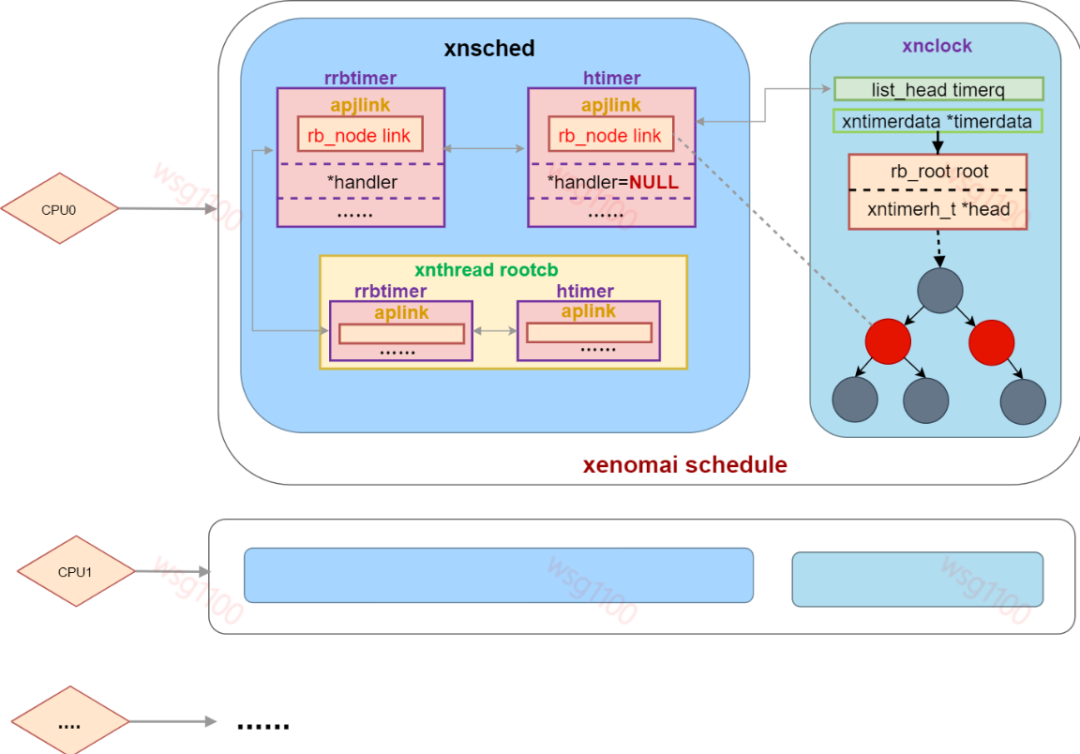
2.6 xenomai内核下Linux时钟工作流程
到此时钟系统中除调度相关的外,一个CPU上双核系统时钟流程如下图所示:
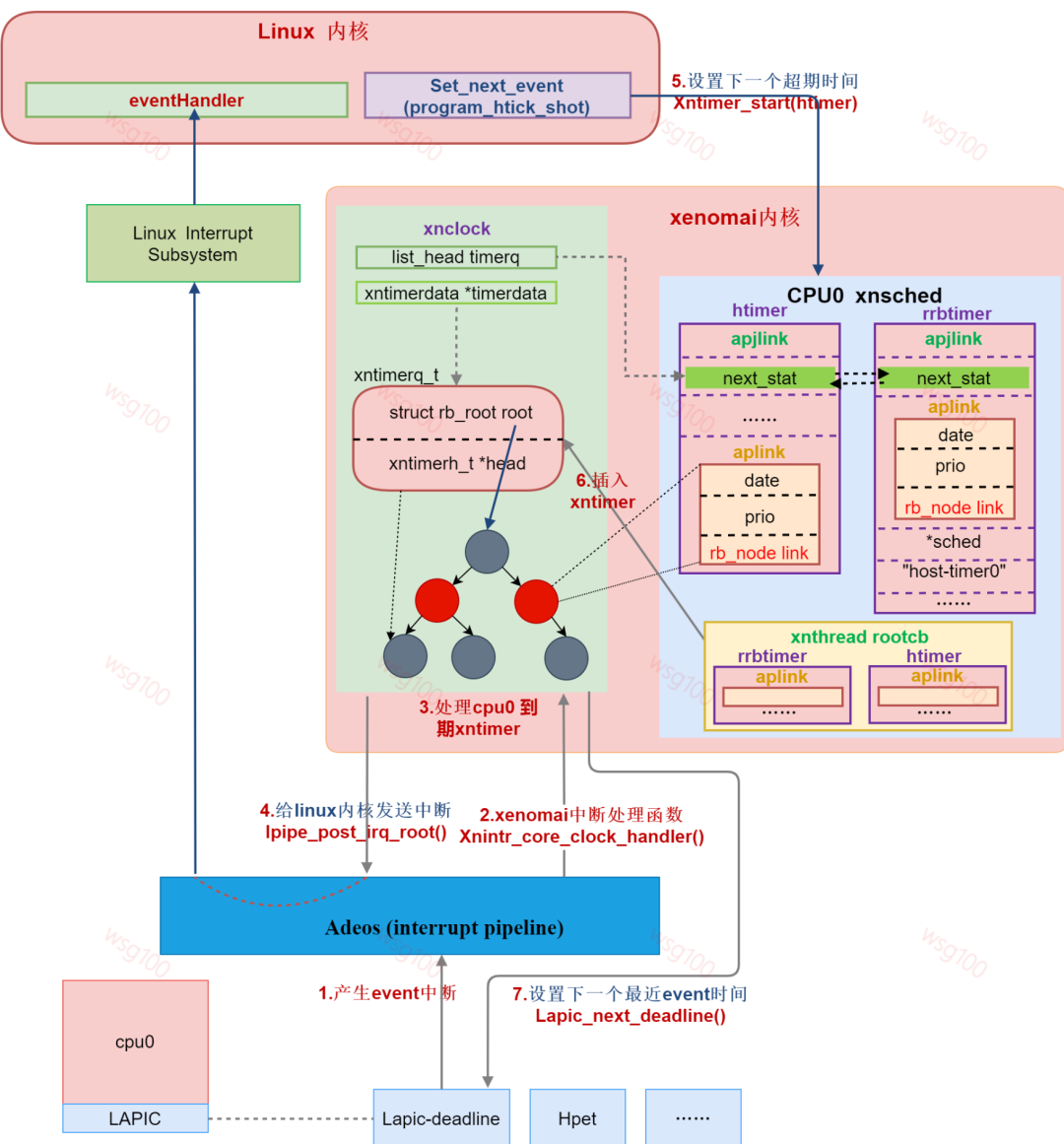
总结:xenomai内核启动时,grab_timer()结合ipipe通过替换回调函数将原linux系统timer lapic-timer作为xenomai 系统timer,xenomai直接对层硬件lapic-timer编程,linux退化为xenomai的idle任务,idle任务的主时钟就变成linux的时钟来源,由linux直接对层硬件lapic-timer编程变成对idle hrtimer编程。idle hrtimer依附于xenomai时钟xnclock,xnclock运作来源于底层硬件lapic-timer。
2.7 gravity
为什么要设置gravity呢?
xenomai是个实时系统必须保证定时器的精确,xntimer都是由硬件timer产生中断后处理的,如果没有gravity,对于用户空间实时任务RT:假如此时时间刻度是0,该任务定时10us后触发定时器,10us后,产生了中断,此时时间刻度为10us,开始处理xntimer,然后切换回内核空间执行调度,最后切换回用户空间,从定时器到期到最后切换回RT也是需要时间的,已经超过RT所定的10us,因此,需要得到定时器超时->回到用户空间的这段时间gravity;不同空间的任务经过的路径不一样,所以针对kernel、user和irq分别计算gravity,当任务定时,定时器到期时间date-gravity才是xntimer的触发时间。当切换回原来的任务时刚好是定时时间。
总结来说是,CPU执行代码需要时间,调度度上下切换需要时间,中断、内核态、用户态需要的时间不一样,需要将中间的这些时间排除,这些时间就是gravity。
2.8 autotune
gravity可以使用xenomai 内核代码中的经验值,还可以内核编译时自定义,除这两种之外,xenomai还提供了一种自动计算的程序autotune,它的使用需要配合内核模块autotune,编译内核时选中编译:
[] Xenomai/cobalt ---> Core features ---> <> Auto-tuning
程序autotune位于/usr/xenomai/sbin目录下,直接执行会分别计算irq、kernel、user的gravity;
审核编辑:汤梓红
-
嵌入式系统内存管理机制详解2018-11-18 4507
-
安卓应用商店和APP市场管理机制2019-07-15 0
-
命令终端的常用操作有哪些?软件包管理机制是什么2021-12-21 0
-
基于RK3399的Linux kernel中CPU时钟管理介绍2022-06-21 0
-
实时系统Preempt RT与Xenomai之争!谁更主流,谁更实时?2023-06-15 0
-
linux内存管理机制浅析2011-12-19 883
-
最全SPARK内存管理机制2017-09-08 576
-
μC/OS—II中的时钟节拍管理机制技术分析2018-04-09 1435
-
驱动之路-内存管理机制及mmap方法2019-05-16 968
-
Linux 内核的文件 Cache 管理机制介绍2019-04-02 460
-
Linux + Xenomai实时操作系统创建方案2020-12-26 6228
-
浅析物理内存与虚拟内存的关系及其管理机制2021-04-12 5424
-
Linux内核文件Cache机制2021-08-31 669
-
如何区分xenomai、linux系统调用/服务2022-05-10 2053
-
xenomai系统中的xnheap管理机制2022-05-25 1742
全部0条评论

快来发表一下你的评论吧 !
