

DIMP:Learning Discriminative Model Prediction for Tracking 学习判别模型预测的跟踪
电子说
描述
论文地址:https://arxiv.org/pdf/1904.07220v1.pdf
代码:pytracking 中有 dimp 的代码
摘要
与大多数其他视觉问题相比,跟踪需要在推理阶段在线学习鲁棒的特定于目标的外观模型。为了能够进行端到端的培训,目标模型的在线学习因此需要自身嵌入到跟踪体系结构中。由于这些困难,流行的孪生网络仅预测了目标特征模板。但是,这种模型由于无法集成背景信息而具有有限的判别能力。
我们开发了一种端到端的跟踪体系结构,能够充分利用目标和背景外观信息来进行目标模型预测。通过设计专用的优化过程(仅需几次迭代即可预测功能强大的模型),我们的体系结构源自有区别的学习损失。此外,我们的方法能够学习判别损失本身的关键方面。我们的跟踪器在6个跟踪基准上设置了最新技术,在VOT2018上EAO得分0.440,运行40FPS。
1.简介
目前孪生网络学习框架仍受到严重限制。首先,孪生网络跟踪者仅在推断模型时利用目标外观。这完全忽略了背景外观信息,这对于将目标与场景中的相似对象区分开来至关重要(请参见图1)。其次,所学习的相似性度量对于未包含在离线训练集中的对象不一定是可靠的,从而导致没有泛化能力。第三,大部分孪生网络不能更新模型,有更新的算法求助于简单的模板平均(DA-SiamRPN,干扰物感知模型,到跟踪帧时,模板z和当前位置 p_k 计算相似度之后,减去当前位置与检测帧中其他位置的相似度的加权和,可以更新模型提高精度)。与其他最新跟踪方法相比,这些局限性导致鲁棒性较差。
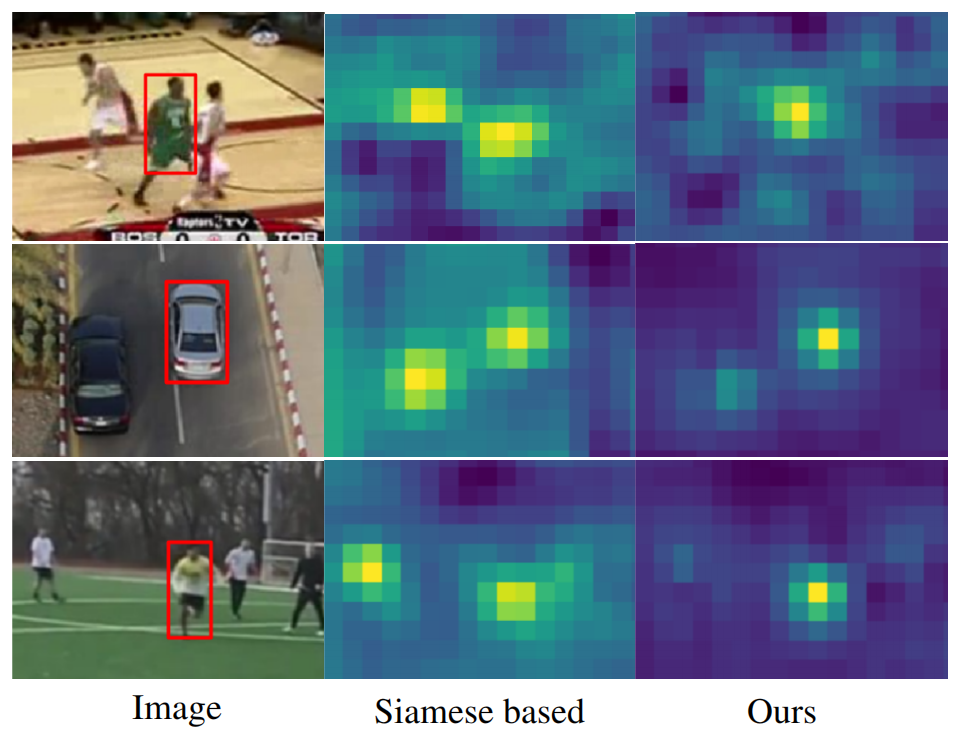
在这项工作中,我们引入了一种以端到端的方式训练的替代跟踪体系结构,该体系结构直接解决了所有上述限制。在我们的设计中,我们从判别性学习(Discriminative Learning Loss)过程中汲取了灵感。我们的方法基于目标模型预测网络,该网络是通过应用迭代优化过程从判别性学习损失中得出的。该体系结构可以进行有效的端到端训练,同时最大程度地提高预测模型的判别力。通过确保通过两个关键设计选择最少的优化步骤来实现这一目标。
首先,我们采用基于最速下降法的方法来计算每次迭代的最佳步长。其次,我们集成了一个模块,该模块可以有效地初始化目标模型。此外,我们通过学习判别损失本身,将极大的灵活性引入了最终的架构。
我们的整个判别式跟踪体系结构,以及主干特征提取器,都通过标注注释的跟踪序列来进行训练,方法是将未来帧的预测误差降至最低。
2.相关工作
RPN详细介绍:https://mp.weixin.qq.com/s/VXgbJPVoZKjcaZjuNwgh-A
SiamFC详细介绍:https://mp.weixin.qq.com/s/kS9osb2JBXbgb_WGU_3mcQ
SiamRPN详细介绍:https://mp.weixin.qq.com/s/pmnip3LQtQIIm_9Po2SndA
SiamRPN++详细介绍:https://mp.weixin.qq.com/s/a9wt67Gn5JowQ4eOmgX75g
孪生网络方法的一个关键限制是它们无法将背景区域或先前跟踪的帧中的信息合并到模型预测中。
3.方法
与在孪生网络跟踪器中一样,我们的方法得益于端到端培训。但是,与Siamese不同,我们的体系结构可以充分利用背景信息,并提供有效的手段来用新数据更新目标模型。
我们的模型预测网络来自两个主要原理:(1)一个判别力强的损失函数可以指导网络学到鲁棒的特征;(2)一个powerful的优化器可以加快网络收敛。
我们的架构仅需几次迭代即可预测目标模型,而不会损害其判别能力。在我们的框架中,目标模型构成卷积层的权重,提供目标分类分数作为输出。
我们的模型预测体系结构通过将一组带 bb 注释的图像样本作为输入来计算这些权重。模型预测器包括一个初始化程序网络,该初始化程序网络仅使用目标外观即可有效提供模型权重的初始估计。然后由优化器模块处理这些权重,同时考虑目标样本和背景样本。通过设计,我们的优化器模块几乎没有需要学习的参数,以避免在离线训练期间过分适应某些类别和场景。因此,我们的模型预测变量可以泛化到其他的对象,这在通用对象跟踪中至关重要。
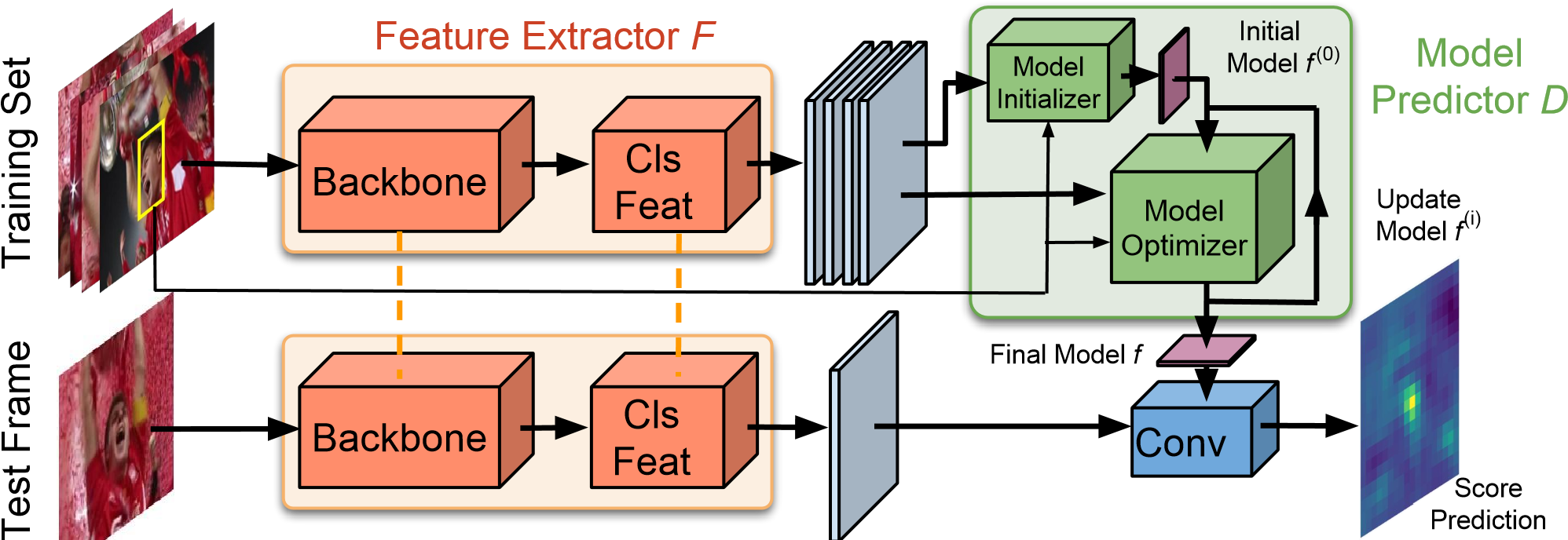
图2.我们的跟踪架构概述。给定带注释的训练集(左上),我们使用骨干网络提取深度特征图,然后再附加卷积块(Cls Feat)。然后将特征图输入到由初始化器(initializer)和循环优化器模块(optimizer)组成的模型预测器D。模型预测器输出卷积层的权重,该卷积层对从测试帧中提取的特征图执行目标分类。为了清楚起见,此处未显示边界框回归分支。
我们的最终跟踪架构如图2所示。我们的网络包括两个分支:分类和回归。两个分支都从通用骨干网输入深层功能。
目标分类分支包含一个卷积块,提取出分类器对其进行操作的特征。给定一组训练样本和相应的目标框,模型预测器将生成目标分类器的权重。然后将这些权重应用于从测试帧中提取的特征,以计算目标置信度分数。
对于bb框估计分支,我们利用基于重叠最大化(就是在目标检测网络上增加了一个IoU分支,用于预测bb与gt的IoU,使用最大化IoU来调整bb)的体系结构。它可以预测目标和一组proposal boxes之间的IoU。
整个跟踪网络,包括目标分类,bb估计和骨干模块,都在跟踪数据集中进行了离线培训。
3.1 Discriminative Learning Loss
判别性学习损失
论文提出了一个概念,就是单纯以图片对方式训练,传统的方法只会让网络过分注意于优化负样本的影响,而忽略了学到的正样本的特征本身的判别能力。为了解决这个问题,他们用了SVM中使用的hinge-like损失,就是不仅将前景背景分开,更加使得两类之间有一定的距离,使得分类结果更好。
在本节中,我们描述用于推导模型预测体系结构的判别性学习损失。我们的模型预测器 D 的输入由特征提取器网络 F 生成的深度特征图 x_j \\in X 训练集 S_{train}=(x_j,c_j)^n_{j-1} 组成。每个样本与相应的目标中心坐标 c_j \\in R^2 对。有了这些数据,我们的目标是预测目标模型 f=D(S_{train}) 。模型 f=D(S_{train}) 定义为卷积层的滤波器权重,该卷积层的特征是区分特征空间 x 中的目标外观和背景外观。
L(f)= \\frac{1}{|S_{train}|} \\sum_{(x,c) \\in S_{train}} ||r(x*f,c)||^2+||\\lambda f||^2\\tag{1}
在这里,*表示卷积,\\lambda为正则化因子。函数 r(s,c) 根据目标置信度得分 s=x*f 和 gt 中心坐标 c 计算每个空间位置的残差。最常见的选择是 r(s,c)=s-y_c ,其中 y_c 是每个位置的期望目标分数,通常设置为以 c 为中心的高斯函数。然而,简单地求差通常会使模型对所有负样本回归校准的置信度得分为零,这需要学习将重点放在负面数据样本上,而不是获得最佳的判别能力。简单的差异并不能解决目标与背景之间数据不平衡的问题。
为了解决数据不平衡的问题,我们使用空间权重函数 v_c。下标 c 表示目标的中心位置的依赖性,如3.4节所述。为了适应第一个问题,我们按照支持向量机的原理修改了损失。我们采用hinge-like loss,用 max(0,s) 将背景区域中的负分数取零。因此,该模型可以自由地为背景中的简单样本预测较大的负值,而不会增加损失。另一方面,对于目标区域,我们发现添加类似的hinge-like loss max(0,1-s) 是不利的,因为目标类和背景类之间的基本不对称,数值上不平衡。此外,在跟踪情况下,例如精确校准的目标置信度确实是有利的。
为了兼顾最小二乘回归和hinge loss的优点,我们定义了残差函数:
r(s,c)=v_c *(m_cs+(1-m_c)max(0,s)-y_c)\\tag{2}
目标区域mask由 m_c 定义,其值在每个空间位置 t \\in R^2 有 m_c(t) \\in[0,1],即正样本就用正样本的score,负样本的话就用大于零的。同样,下标c表示对目标中心坐标的依赖性。上式能够根据相对于目标中心c的图像位置连续地将损失从标准最小二乘回归更改为hinge loss。将 m_c \\approx 1 设置为目标,将 m_c \\approx 0 设置为背景会产生上述所需的行为。但是,如何最佳设置 m_c 尚不清楚,特别是在目标和背景之间的过渡区域。尽管经典策略是使用试错法手动设置 mask 参数,但我们的端到端公式允许我们以数据驱动的方式学习 mask。实际上我们的方法都是网络中自己学到的,并不是人工指定的:目标 mask m_c,空间权重 v_c ,正则化因子 \\lambda。
3.2 Optimization-Based Architecture
基于优化的架构
作者表示使用固定的学习率不仅会导致模型迭代次数多,获得的精度也不够理想,所以作者自己设计了一个梯度下降的方式,自适应的学到学习率。这里的策略就是希望梯度下降沿着最陡的方向走。
我们得出网络架构D,它通过公式(1)最小化误差来预测滤波器f=D(S_{train})。该网络是通过制定优化程序来设计的。从等式(1)和(2)我们可以得出损耗 \\nabla L 相对于滤波器 f 的梯度的表达式。直接的选择是使用步长来梯度下降。
f^{i+1}=f^i-\\alpha \\nabla L(f^i) \\tag{3}
梯度下降的缓慢收敛主要是由于步长不变,所以步长不依赖于数据或当前模型估计。我们通过推导使用了更复杂的优化方法来解决此问题,该方法仅需要进行几次迭代即可预测出强大的判别滤波器 f。核心思想是基于最速下降法计算步长,这是一种常见的优化技术。我们首先在当前估计值 f^i 处用二次函数来估算损失:
L(f)\\approx \\tilde{L}(f)=\\frac 1 2 (f-f^i)^TQ^i(f-f^i)+(f-f^i)T\\nabla L(f^i)+L(f^i) \\tag{4}
在这里,滤波器变量 f 和 f_i 被视为向量,而 Q^i 是正定方阵。然后,通过找到使梯度方向上的近似损失最小的步长来进行最陡的下降:
\\alpha=\\frac{\\nabla L(f^i)^T \\nabla L(f^i)^T}{\\nabla L(f^i)^TQ^i \\nabla L(f^i)} \\tag{5}
在最速下降时,公式(5)用于计算滤波器更新的每次迭代中的标量步长。
二次模型(4)以及因此得到的步长(5)取决于 Q^i 的选择。例如,通过使用缩放的单位矩阵 ,我们以固定步长来重新获取标准梯度下降算法。对于我们的最小二乘公式(1),Gauss-Newton方法提供了一个强大的替代方法,因为它仅涉及一阶导数,因此具有明显的计算优势。因此,我们设置 Q^i=(j^i)^T J^i,其中 J^i 是 f^i 处残差的雅可比行列式。实际上,矩阵 Q^I 和 J^i 都不需要显式构造,而是实现为一系列神经网络操作。
3.3 Initial filter prediction
初始过滤器预测
这个模型初始化就是将所有的 bbox 里面的东西取平均,就像原始的 Siamese 网络一样,只不过在这里只用于初始化,后面还会训练更新。
为了进一步减少预测模块D中所需的优化递归次数,我们引入了一个经过训练的小型网络模块以预测初始模型评估 f^0 。我们的初始化器网络由一个卷积层和一个精确的 ROI 池化层组成。ROI 池化层从目标区域中提取特征并将其合并为与目标模型 f 相同的大小。然后将合并的特征图对 s_{train} 中的所有样本求平均值,以获得初始模型 f^0 。与孪生网络跟踪器一样,此方法仅利用目标特征。但是,我们的初始化程序网络仅负责提供初始估计值,而不是预测最终模型,然后由优化程序模块进行处理以提供最终的判别模型。
3.4 Learning the Discriminative Loss
学习判别性损失
这个部分就解释了刚刚公式2和其中的参数是如何学习的,y_c,v_c 和 m_c 都是根据与目标中心距离决定的,通过转化到对偶空间求的。
在这里,我们描述了如何学习残差函数(2)中的自由参数,这些参数定义了判别损失(1)。我们的残差函数包括标签置信度 y_c ,空间权重函数 v_c ,和目标mask m_c ,此类变量通常是在当前的判别跟踪器中手动构建的,但本文的方法是从数据中学习这些功能的。我们根据与目标中心的距离对它们进行参数化。这是由问题的径向对称性引起的,其中相对于目标的样品位置的方向意义不大。另一方面,到样品位置的距离起着至关重要的作用,特别是在从目标到背景的过渡中。
因此,我们使用径向基函数 ** \\rho_k**,对 y_c,v_c 和 m_c 进行参数化,并学习它们的系数 ** \\phi _k** 。例如,位置 t \\in R^2 处的标签 y_c 为:
y_c(t)=\\sum^{N-1}_{k=0}\\phi^y_k\\rho_k(||t-c||) \\tag{6}
我们使用函数:
\\rho_k(d)= \\begin{cases} max(0,1-\\frac{|d-k\\Delta|}{\\Delta}), & \\text {k 上述公式对应于结节位移为∆的连续分段线性函数。注意最终情况 k=N-1 表示远离目标中心的所有位置,因此可以同等对待。我们使用一个较小的值来实现目标背景过渡时回归标签的准确表示。类似地,分别使用系数 v_k 和 m_k 在(6)中对函数 v_c 和 m_c 进行参数化。对于目标mask m_c ,我们通过Sigmoid函数将值限制为间隔[0,1]。 图3.学习的回归标签,目标mask和空间权重的图。每个数量的初始化以虚线显示。 训练的时候是用多个图片对训练的 (M_{train},M_{test}) ,这些样本是从同一个序列中抽样出来的,对于给定的样本对,先是用特征提取网络提取到对应的特征 (S_{train},S_{test}) ,得到的特征输入到D网络中得到滤波器 f ,这个文章的目的就是学到一个可以推广到没见过帧的特征。然后在**S_{test}**上测试,然后计算一个损失: l(s,z)= \\begin{cases} s-z, & \\text {z>T} \\ max(0,s)), & \\text{z 这里就是之前提到的 Hinge-like 损失函数,T 表示前景和背景,所以这里只惩罚背景样本。这里他们为了提升模型鲁棒性,对每次迭代的损失都做约束,这就相当于一个中间的监督: L_{cls}=\\frac{1}{N_{iter}} \\sum^{N_{iter}}_{i=0} \\sum_{(x,c) \\in S_{test}} ||l(x*f^i,z_c)||^2 \\tag{9} 迭代次数也不是指定的,而是自适应的。上述公式中 z_c 是一个 mask 中心位于 bb 的中心的高斯函数,在 bb 回归的地方,他们用了 IOUNet 来做。最终的损失函数为: L_{tot}=\\beta L_{cls}+L_{bb} \\tag{10} 对于给定的第一帧,他们用数据增强方式添加了15个样本,然后用10次梯度下降来学习 f,在模型更新过程中,他们保持最新的50个样本,每20帧更新一次。 给定带有注释的第一帧,我们采用数据增强策略来构建包含15个样本的初始集合 S_{train} 。然后使用我们的判别模型预测架构 f=D(S_{train} ) 。得目标模型。对于第一帧,用10次梯度下降来学习。只要有足够的置信度预测目标,我们的方法就可以通过向 S_{train} 添加新的训练样本轻松地更新目标模型。通过丢弃最早的样本,保持最新的50个样本。在跟踪过程中,我们通过每20帧执行两次优化器递归完成更新,或在检测到干扰波峰时执行一次递归来更新目标模型。 我们的方法是使用PyTorch在Python中实现的。在单个NVidia GTX 1080 GPU上,当使用ResNet-18作为主干时,我们的跟踪速度为57 FPS,对于ResNet-50为43 FPS。 学习更多编程知识,请关注我的公众号: [代码的路]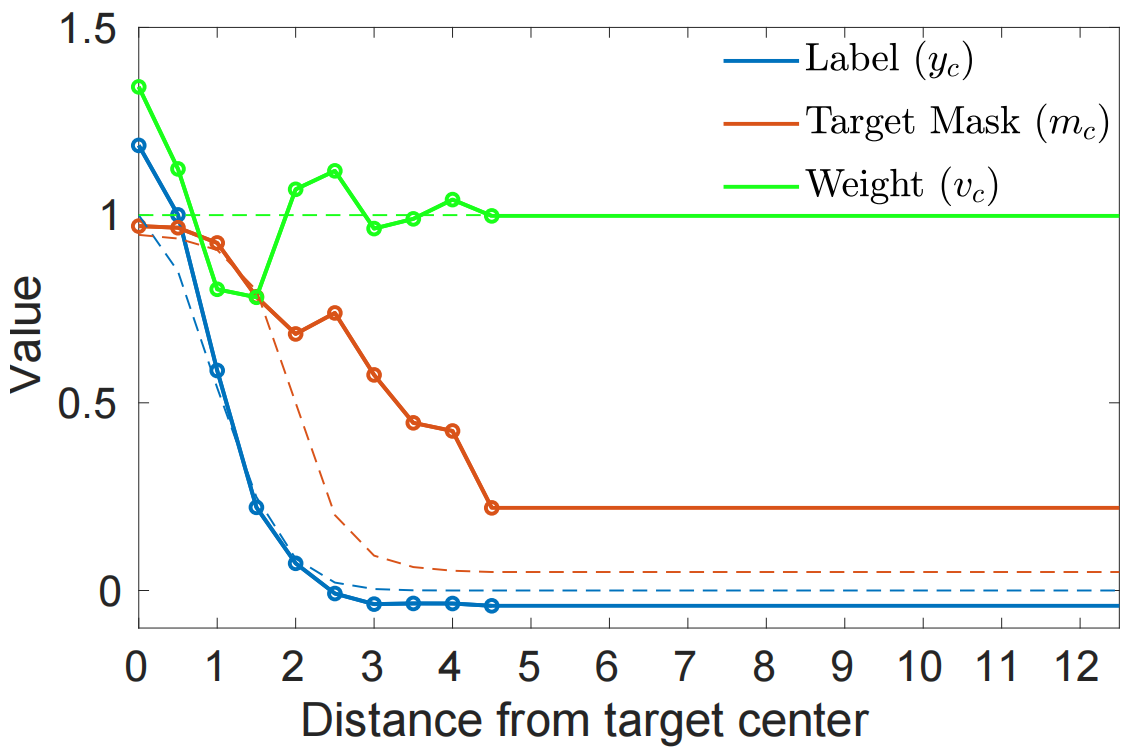
3.5 离线训练
3.6 在线追踪
-
机器学习之偏差、方差,生成模型,判别模型,先验概率,后验概率2020-05-14 0
-
Fast Intra-Prediction Model Selection for H.264 Codec2008-06-25 0
-
【洞幺邦】基于深度学习的GAN应用风格迁移2021-07-01 0
-
Ensemble Learning Task2021-07-07 0
-
模型预测控制介绍2021-08-18 0
-
什么是有限集模型预测控制2021-08-27 0
-
在BBNs的基础上软件残留缺陷预测模型2009-05-26 332
-
自动跟踪对称电源:Tracking Regulated Po2009-05-16 2855
-
FM跟踪发射器FM Tracking Transmitter2009-12-22 2553
-
人工智能--深度学习模型2018-06-29 6091
-
一种基于RNN的社交消息爆发预测模型2017-12-25 961
-
一种新颖的基于模型的机器学习方式——model based machine learning2018-10-21 6071
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 900
-
机器学习发展历程与机器学习应用之道2022-07-10 10314
-
永磁同步电机模型预测转矩控制学习2022-12-19 2244
全部0条评论

快来发表一下你的评论吧 !
