

自动驾驶的ODD边界如何进行有效的检测呢?
描述
由于现在的自动驾驶技术还处于发展阶段,无法保证自动驾驶车在任何天气条件下和任何道路环境中都可以安全行驶的。因此,要根据该系统的能力来提前设定好ODD,通过限制行驶环境和行驶方法,将有可能发生的事故防范于未然。然而,对于这类运行环境边界条件而言,通常会需要考虑如何进行有效的检测呢?也就是说,提出的ODD对于自动驾驶开发而言必须是可测的。
考虑一些ODD所涉及的天气如风、雨、雪、雨夹雪、高低温度会极大的影响整个系统的控制能力。比如车子正常行驶在高速公路上,小雨或小雪能使平均速度降低3%至13%;暴雨会使平均速度降低3%到16%;在大雪中,高速公路的平均速度会下降5%到40%;小雨时自由流速可降低2% ~ 13%;大雨时可降低6% ~ 17%;降雪将使自由流速度降低5%至64%;可以说在降雨期间,整个车辆驾驶速度变化差不多会减少25%。
目前知道的,L2级自动驾驶在雨雪条件下的性能几乎不能满足预期,比如车道保持功能在公路雪地打滑时汽车会转向过度。特斯拉的Autopilot可以在正常的雨雪中导航,路标清晰可见,但在某些棘手的情况下,如暴雨或车道线出现遮盖时候仍然难以驾驶。显然,恶劣的天气条件限制了人类驾驶方向盘,AVs仍然不能完全相信它能独自工作。
因此,为了让ADS继续向前推进到下一个时代,自动驾驶汽车需要更多的时间来适应各种天气。
如图所示是恶劣天气下自动驾驶系统的信息流图:
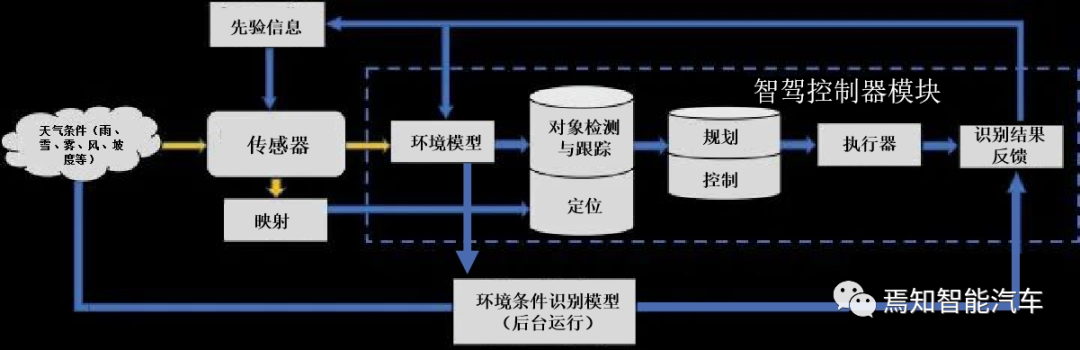
如上图所示,作为车辆传感器的信息源,环境状态直接受到天气条件的影响。这些变化增加了整个ADS系统用受损数据完成目标检测、跟踪和定位任务的难度,因此规划和控制也将不同于正常情况。天气也可能影响自车本身,并产生附加影响,如风和路面状况。自车识别结果反馈整车后形成的车辆控制状态(如雨刮是否启动,除雾装置是否打开等信息)都是可以作为环境信息判断的先验信息的,这也会间接影响对环境状态的判断,由此可以形成一个检测循环。
其实,无论从自动驾驶角度还是从手动驾驶角度上讲,对于环境的有效检测都将显得尤为必要。比如如下的环境条件而言,我们是否可以通过一定的手段进行更加精确的检测呢?
风力大小:从横向车控角度分析,考虑风阻对整个车身控制的影响。
光照条件:考虑炫目和夜晚可视效果的影响
雨量大小:基于视觉的雨量传感测试
路面坑洼:基于多目时觉得路面条件检测。
横纵坡道检测:基于底盘ESP和TCU的坡道数据
涉水路面检测:基于超声波数据
那么这类雨雪天气将如何测量则是我们需要研究的一个课题。常规的方法是通过类似雨量传感器这样的装置进行测量,但是这类装置在很多车型上也不是标配。如果考虑智驾系统而言,则可能出现无法满足测量需求的情况。
本系列文章将针对性讲解整个智驾系统如何利用自身传感器对环境信息进行初级有效探测。无论从智驾本身角度出发的识别和控制,还是从传统驾驶过程对这种探测能力都显得尤为必要。
基于视觉的降雨量预测
对于自动驾驶系统而言,通常会通过判定降雨/降雪量来判定对整个系统是否可激活的前置条件。通常情况下,目前的检测手段要么是通过雨刮刮速大小,要么是通过雨量传感器一类来进行综合判断是否触及ODD边界。那么,从自车平台化和可应用场景的角度出发,是否能够利用自车传感器开发一种可自适应测量环境条件的软件模块呢?答案是肯定的。
本文提出一种基于视觉场景的降雨量预测算法。其主要是通过自车原有的摄像头采集雨量光线,从而计算雨量大小,转化成雨刮器可识别的指令信号发送给车身控制器,车身控制器通过雨刮信号指令自动控制雨刮进行低速、高速、间歇性动作。同时,系统可以控制仪表显示雨刮控制系统的相关零部件故障、以提醒用户及时维修和更换等。
用软件算法代替增加新的硬件(定制的雨刮传感器或其他硬件设备)实现对雨刮的控制功能,不但可以减少成本,软件也可以通过不断更新、迭代、升级来达到最优的用户体验。此外,如果考虑通过利用智驾域的传感器探测的算法来实现整个车身的控制(比如探测到雨量过大,则通过算法计算出雨量大小,自动控制车辆雨刮采用一定的速度刮刷玻璃,一方面可以为整个传感器探测开辟更好的探索通道,另一方面也可以提升用户驾驶的智能化体验)。
相应的实现原理如下:
总体来说,需要通过两阶段算法来实现,实现基于视觉的场景降雨量的智能分类,其类别包括:晴天、小雨、中雨、大雨、暴雨五种。其方法是利用智能驾驶汽车上搭载的摄像头拍摄的视频数据作为输入,记录不同位置、不同时域的降雨数据。将视频数据输入“降雨量识别大小的分类算法模块”中。该算法模块涉及对环境的目标提取、分割、聚类、识别等子模块。归类起来,常用的算法包括基于超像素(Super-Pixel)邻域对齐的雨水分割算法(得到逐帧雨水图分割结果)和基于ResNet的雨量分类算法(带有残差学习的ResNet)的两个阶段。
基于超像素邻域对齐的降雨/降雪检测算法
由于视频中对雨水的分割是不存在分割前景和背景区域的,如果按照逐像素进行识别处理,对于整个算法而言将显得比较臃肿。我们对雨水大小的识别需要从以下几个方面入手:
选定的算法通过测量降雨量视频中不同时域间像素值的区域强度变化,进而得到每一帧图像的雨水分割结果,通过迭代优化训练,不断提高其识别精度,进而达到预期的识别结果。
相应的示意图如下:
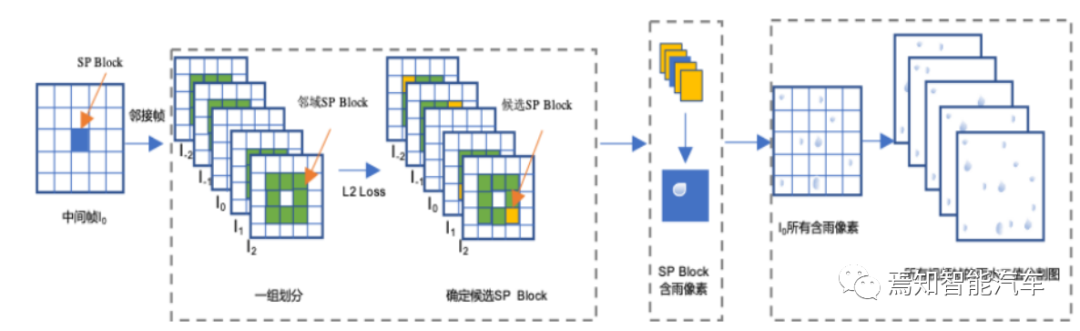
1)通过智能汽车采集的一组降雨视频,截取固定帧数作为视频输入算法模块。
2)帧内超像素块识别:
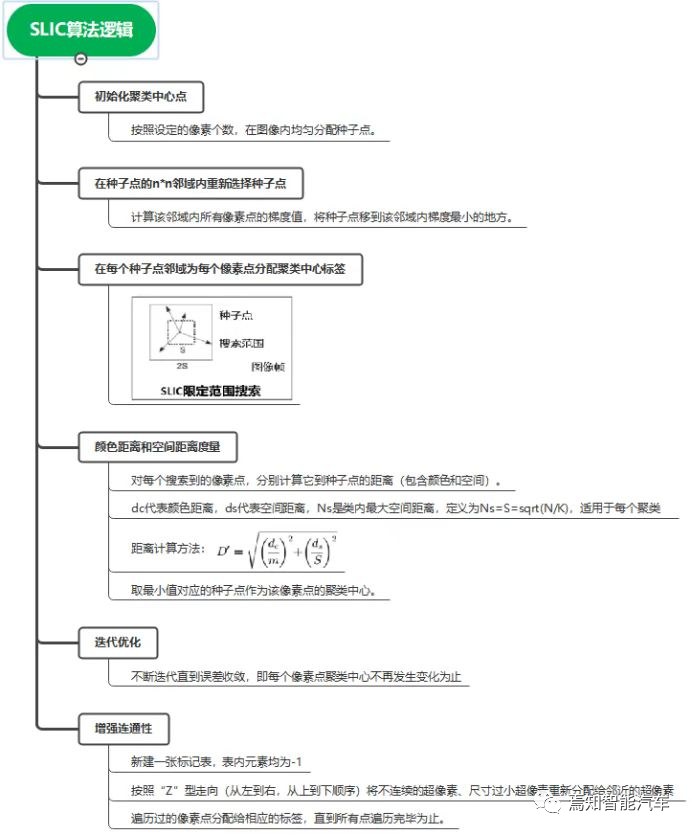
常用的算法包括利用SLIC算法(simple linear iterative cluster)生成每一帧图像的超像素(superpixel)块。相比其他的超像素分割方法,SLIC在运行速度、生成超像素的紧凑度、轮廓保持方面都比较理想。具体过程包括:
利用像素之间特征相似性(如相似纹理、颜色亮度等特征)将像素分组,通过简单的线性迭代聚类,将彩色图像转化为CIELAB颜色空间和XY坐标下的5维特征向量,然后对5维特征向量构造距离度量标准,对图像像素进行局部聚类。最终能生成紧凑、近似均匀的超像素,在运算速度、物体轮廓保持、超像素形状方面具有较高的性能。最终,用少量的超像素代替大量的像素来表达图片特征。
3)帧间超像素块划分:
选定中间帧为关键帧I0,并作为参考位置帧,与其前后各两帧的超像素块图构成一组划分区域。
4)构造损失函数:
通过逐像素遍历的方式可以构造Loss损失函数,从而衡量每个I0超像素块与其前后两帧对应位置邻域块的差异大小。并将其差异最小的邻域块作为候选对齐区域,最终确定I0中每个像素块的4个候选超像素块区域。
5)雨水识别:
由于雨水部分可以增加像素的强度值,因此可以将含有I0的超像素块与候选区域的部分进行像素差异比较。若I0超像素块中的像素与每个候选区域所对应像素差异均大于所设定的雨水像素的阈值时,那么就认为该像素为雨像素。
6)帧内迭代优化:
迭代I0中每一个超像素块,可以得到关键帧I0的雨水二分割图。
7)帧间迭代优化:
迭代降雨量视频中的每一帧,得到全部帧的雨水分割结果。
基于深度学习的降雨/降雪量测量算法
如前所述,对雨/雪这类目标分割完成后,需要重新利用一定有效的算法对降雨/降雪的大小进行预分类识别。同时,从时域的角度上将降雨和降雪在未来一定时间内可能产生的情况和趋势进行有效预测,以便在形势策略上可以提前做出一定的判断和控制。
如上述算法所表述的部分,我们可以通过首先聚类超像素邻域对齐的方式得到雨量场景分割结果,将该结果作为数据输入到深度学习神经网络中从而获得准确的雨量分类结果。常用的卷积神经网络模型涉及ResNet,因为其引入了深度残差学习算法,可以有效的解决网络退化的问题。在包括图像网络ImageNet的多个大型分类数据集上可以很好的实现优异的分类精度。
在对降雨/降雪这类场景的测量可以利用ResNet网络结构通过不同的分层ResNet18、ResNet34、ResNet50、ResNet101以及ResNet152来实现分层训练。各种网络的深度指的是“需要通过训练更新参数”的层数,如卷积层,全连接层等。同时,为了满足轻量化要求,通常可以选择ResNet18作为分层标准进行训练。其中包含17个卷积和一个全连接层进行权重学习,随后通过两个池化层处理。
根据超像素临域对齐的雨量分割算法可以从场景视频中获得场景视频的雨/雪分割结果作为输入数据。选择深度学习方法,获取准确地雨量/雪量分割结果。
基于深度学习的降雨量预测算法
本文这里提到的关于实现雨量检测和预测的算法包含两个阶段,考虑对于智驾系统控制过程的高速推理和模型轻量化特点,采用超像素的雨/雪分割加上利用经典的神经网络算法ResNet进行雨量预测。在ResNet提出之前,所有的神经网络都是通过卷积层和池化层的叠加组成的。卷积层和池化层的层数越多,获取到的图片特征信息越全,学习效果也就越好。
CNN参数个数 = 卷积核尺寸×卷积核深度 × 卷积核组数 = 卷积核尺寸 × 输入特征矩阵深度 × 输出特征矩阵深度
常规的神经网络随着网络加深,其相应的准确率随之下降。使用ResNet神经网络人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系,可以更加精准的预测到环境雨量分割和预测。
将本算法打搭载到各种车载设备上,通过对深度网络进行身份映射(identity mapping,IM)和残差映射(residual mapping,RM)优化网络,随着不断地迭代,其残差映射将逐渐趋于0,最终只剩下身份映射。由此,可以更加实时且精准的预测环境降雨/降雪量。
考虑本算法的ResNet的整个算法逻辑如下:
1)视频采集:
通过智驾车辆前视、侧视摄像头采集场景视频作为原始视频输入。该视频帧需要在摄像头前端进行包含ISP相关的图像处理;
2)视频帧抽取:
考虑到算法处理能力对整个处理器可能产生较大的负担,因此,同需要对视频帧按照每隔一定时间抽取固定帧数的视频,采用“超像素邻域对齐雨量分割算法”进行雨量分割,并得到相应的雨水分割结果;
3)感兴趣区域选择:
对于环境降雨量这类过程处理,因为感兴趣的部分是雨水,且分布没有特定的规律。因此,可以固定的选取每一帧的中间区域作为该视频帧中感兴趣区域(ROI,Region of Interest);
4)视频张量输入ResNet模型
对于ResNet网络就是要构造观测值与估计值之间的差,也可以用残差映射函数,也就是F(x),其中F(x) = H(x)-x。这里H(x)就是观测值,x就是估计值(也就是上一层ResNet输出的特征映射)。 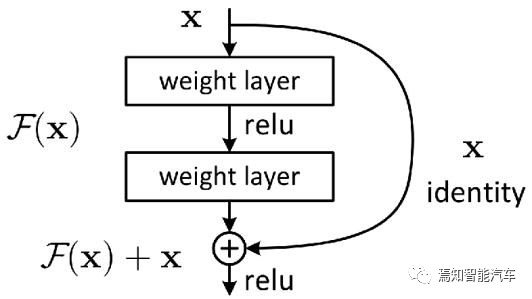
residual结构使用了一种shortcut的连接方式,也可理解为捷径。让特征矩阵隔层相加,注意F(X)和X形状要相同,所谓相加是特征矩阵相同位置上的数字进行相加。
将其按照通道进行拼接,合并为固定通道的张量,并输入到ResNet模型,预测不同降雨量的概率值;
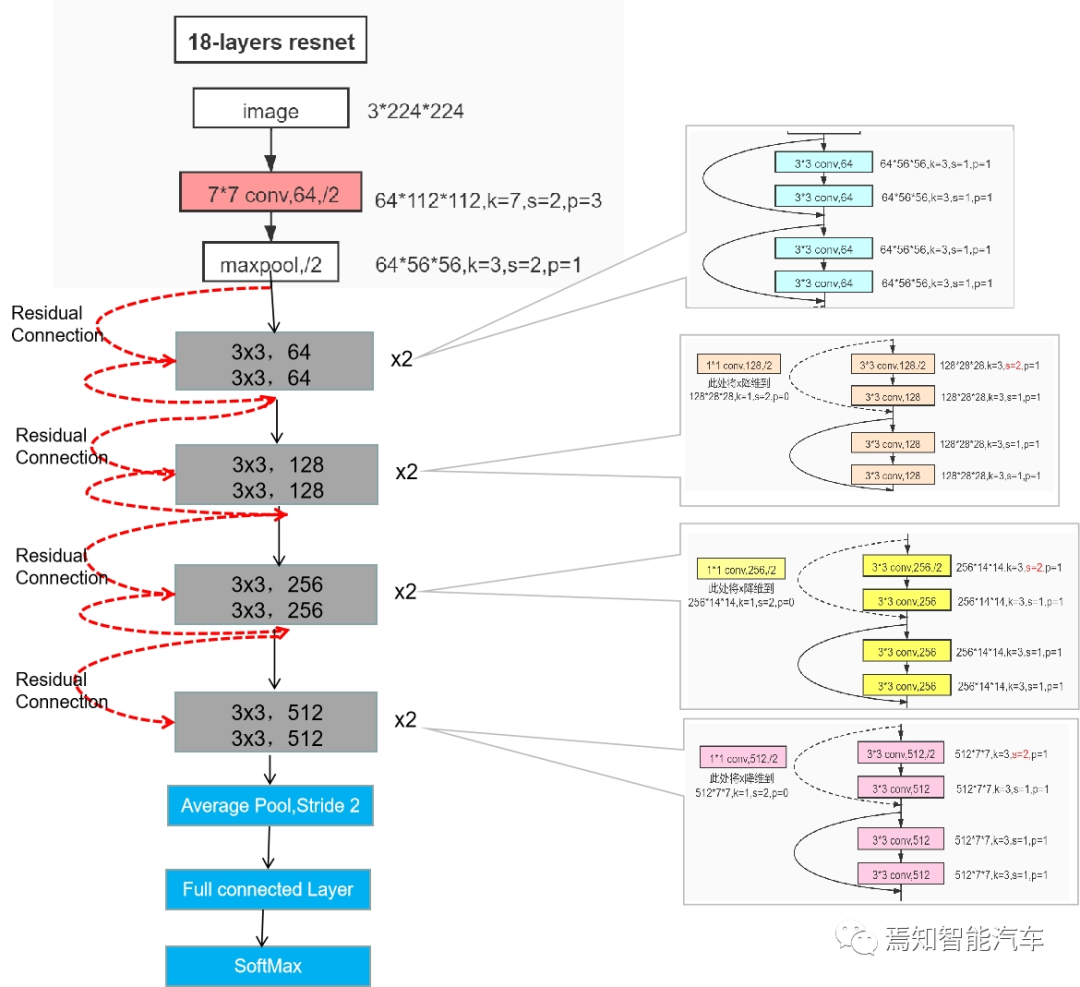
5)根据概率值在分类区间的位置,确定最终的降雨量预测结果
实验证明,ResNet残差网络更容易优化,并且加深的网络层数有助于提高正确率。所以在加深网络深度的同时,需要使用残差学习的结构来减轻深层网络训练的难度。过程中,需要重新构建优化的网络以便学习到包含已经推理过的残差函数,而不是学习未经过推理过的函数。
总结
本文从一些环境设置条件出发考虑如何通过最大化的利用自车配置的软硬件单元模块进行有效的ODD设置和检测,详细讲述如何利用摄像头传感器对环境降雨/降雪量进行有效检测的算法逻辑。
同时,本文就自动驾驶系统设置的ODD边界中的其中一个要素检测考虑通过智驾系统自身搭载的传感器进行实时检测从而获取一定的控制输入源。对于诸如雨量、雪量的检测结果不仅可以完全用于自动驾驶系统自身的边界条件控制,也可以作为在车辆未开启自动驾驶时自动检测雨量、雪量等环境条件,自适应的控制车辆进行雨刮开启、增加刮速,如果有类似自动除霜等功能,也可以控制自动开启自动除霜、除雾等功能。
审核编辑:刘清
-
FPGA在自动驾驶领域有哪些应用?2024-07-29 0
-
FPGA在自动驾驶领域有哪些优势?2024-07-29 0
-
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?2016-07-05 0
-
自动驾驶真的会来吗?2016-07-21 0
-
自动驾驶的到来2017-06-08 0
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰william hill官网2017-09-13 0
-
如何让自动驾驶更加安全?2019-05-13 0
-
自动驾驶汽车的处理能力怎么样?2019-08-07 0
-
为何自动驾驶需要5G?2020-06-08 0
-
网联化自动驾驶的含义及发展方向2021-01-12 0
-
如何打造自动驾驶「自行车」的呢2021-08-26 0
-
自动驾驶系统设计及应用的相关资料分享2021-08-30 0
-
自动驾驶技术的实现2021-09-03 0
-
LabVIEW开发自动驾驶的双目测距系统2023-12-19 0
-
如何进行安全的自动驾驶大规模部署2019-04-29 3377
全部0条评论

快来发表一下你的评论吧 !
