

如何用一种级联的并解决嵌套的实体的三元组抽取模型?
描述
前言
关系抽取是自然语言处理中一个比较基础的任务,除了关系抽取之外还有类似的任务如:属性抽取等。这些任务也都可看成三元组抽取,即(subject,predicate,object)。常见的抽取范式包含:
基于pipeline的分布抽取方式,在已知两个实体subject和object,去预测predicate。
联合抽取方式,一个模型同时将subject,predicate和object抽取出来。
「现实的场景中还存在重叠关系情况,那么针对这种情况该如何解决呢?」,ACL2020有一篇论文:A Novel Cascade Binary Tagging Framework for Relational Triple Extraction[1]介绍了如何一种级联的并解决嵌套的实体的三元组(文中介绍的是关系抽取)抽取模型。下面我们来看看这篇论文介绍的内容。
背景
早期基于pipeline的方法首先识别出语句中的所有实体,然后在对所有的实体对分类。这种方式的一个缺点是:实体识别过程中的误差会被引入到关系抽取的环节中,如下图中的Normal情况。
现有的联合抽取模型中不能够有效地解决:一个句子包含多个相互重叠的关系三元组。如下图中的EPO和SEO。
前言
关系抽取是自然语言处理中一个比较基础的任务,除了关系抽取之外还有类似的任务如:属性抽取等。这些任务也都可看成三元组抽取,即(subject,predicate,object)。常见的抽取范式包含:
基于pipeline的分布抽取方式,在已知两个实体subject和object,去预测predicate。
联合抽取方式,一个模型同时将subject,predicate和object抽取出来。
「现实的场景中还存在重叠关系情况,那么针对这种情况该如何解决呢?」,ACL2020有一篇论文:A Novel Cascade Binary Tagging Framework for Relational Triple Extraction[1]介绍了如何一种级联的并解决嵌套的实体的三元组(文中介绍的是关系抽取)抽取模型。下面我们来看看这篇论文介绍的内容。
背景
早期基于pipeline的方法首先识别出语句中的所有实体,然后在对所有的实体对分类。这种方式的一个缺点是:实体识别过程中的误差会被引入到关系抽取的环节中,如下图中的Normal情况。
现有的联合抽取模型中不能够有效地解决:一个句子包含多个相互重叠的关系三元组。如下图中的EPO和SEO。
EPO(Entity Pair Overlap)实体对的重叠,换句话说一个实体对包含多种关系,文中的例子就是一个人同时担任一部电影中的导演和演员的角色。
SEO(Single Entity Overlap)单个实体的重叠,就是有多个关系共享一个实体。
在2020年,预训练模型大行其道的时期下,文中也是结合了Bert模型完成文本的特征抽取工作。文中的模型在当时也达到了sota水平,下面我们看看模型的具体内容。
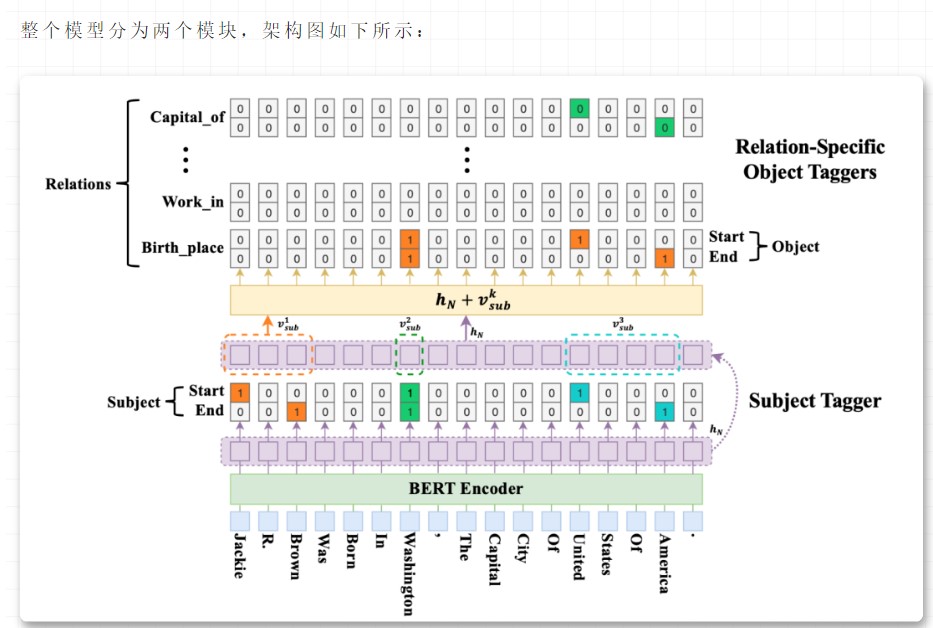
模型结构
关系三元组提取的目标是识别句子中所有可能的三元组(主语、关系、宾语),其中一些三元组可能与主语或宾语共享相同的实体。数学表达如下:

具体如下:
BERT Encoder
在编码器模块中,使用预训练Bert模型提取语句 的特征为 ,作为接下来的tagging模块的输入。
Cascade Decoder
该模块主要分为两个部分,首先从输入的语句中监测出subjects,即Subject Tagger。接着对候选的subject,检查其可能的所有关系类型,即Relation-Specific Object Taggers。
Subject Tagger
在这个模块中主要去识别输入语句中可能存在的subjects。每一个token会输出两个结果:start和end,通过为每个token分配一个二进制标记(0/1)来分别检测subject的开始和结束位置,该标记指示当前标记是否对应于subject的开始或结束位置。subject标记器对每个token的详细操作如下:
其中:


总结
实验效果如下图: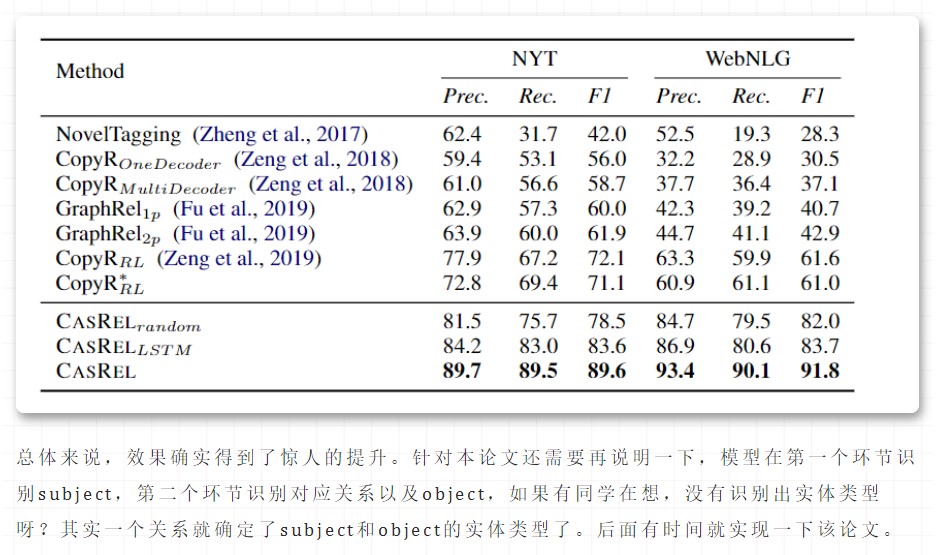
审核编辑:刘清
-
乙烯装置三元制冷技术2010-03-18 0
-
回收电芯组,回收库存电芯组,回收聚合物电芯组,回收锂电芯组,回收动力电芯组,三元电芯组回收2021-08-24 0
-
根据mac地址创建五元组的步骤2022-03-08 0
-
一种基于策略元素三元组的策略描述语言2009-04-09 513
-
一种基于结构的本体分解方法2009-12-22 377
-
三元相图基础2009-08-06 9557
-
基于句法语义依存分析的金融事件抽取2021-03-24 790
-
一种改进的胶囊网络知识图谱补全方法2021-03-30 778
-
融合实体信息的类别增强知识图谱表示学习模型2021-04-27 617
-
介绍一种新颖的三元组对比学习训练框架2021-06-23 3428
-
本体自动化构建方法—面向制造领域人机物三元数据融合2022-05-11 3318
-
泰凌微电子三元组认证功能实现2022-11-23 1174
-
三元锂电池的分类及应用2023-07-04 3216
-
三元锂电池参数 三元锂电池最佳工作温度 三元锂电池寿命一般是几年?2023-11-21 17043
全部0条评论

快来发表一下你的评论吧 !
