

主流分布式存储技术对比分析
电子说
描述
【导读】 如今分布式存储产品众多令人眼花缭乱,如何选型?要根据其背后的核心架构来分析它本来的原貌,然后才能决定其是否适合我们的具体场景。
【作者】 赵海
1 引言
目前市面上各个厂家的分布式存储产品五花八门,但是如果透过产品本身的包装看到其背后的核心技术体系,基本上会分为两种架构,一种是有中心架构的分布式文件系统架构,以GFS、HDFS为代表;另外一种是完全无中心的分布式存储架构,以Ceph、Swift、GlusterFS为代表。对具体分布式存储产品选型的时候,要根据其背后的核心架构来分析它本来的原貌,然后才能决定其是否适合我们的具体场景。
2 主流分布式存储技术对比分析
2.1 GFS & HDFS
GFS和HDFS都是基于文件系统实现的分布式存储系统;都是有中心的分布式架构 (图2.1) ;通过对中心节点元数据的索引查询得到数据地址空间,然后再去数据节点上查询数据本身的机制来完成数据的读写;都是基于文件数据存储场景设计的架构 ;都是适合顺序写入顺序读取,对随机读写不友好。
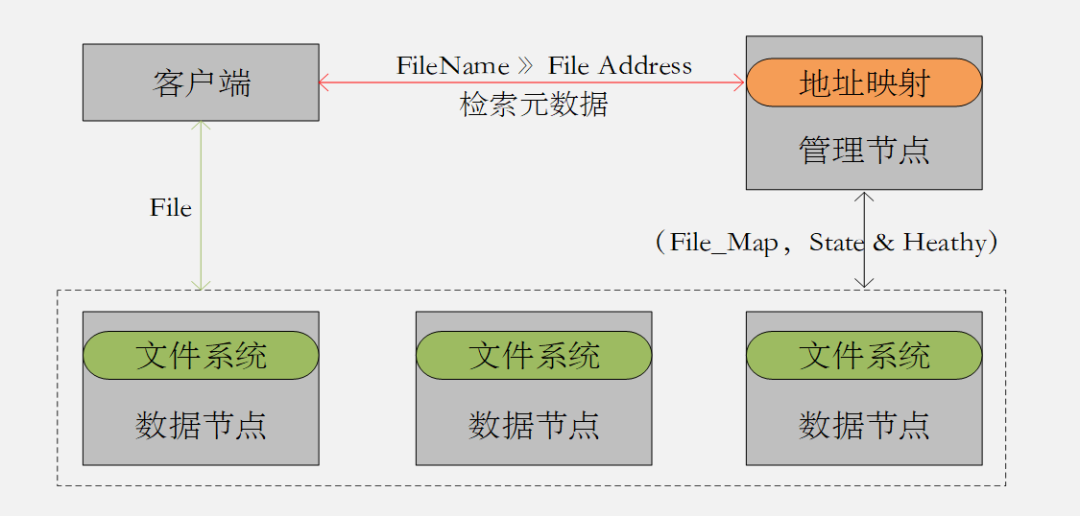
图2.1 中心化的分布式存储架构
接下来,我们来看GFS和HDFS都有哪些具体特性,我们应该如何应用?
- GFS是一种适合大文件,尤其是GB级别的大文件存储场景的分布式存储系统。
- GFS非常适合对数据访问延迟不敏感的搜索引擎服务。
- GFS是一种有中心节点的分布式架构,Master节点是单一的集中管理节点,既是高可用的瓶颈,也是可能出现性能问题的瓶颈。
- GFS可以通过缓存一部分Metadata到Client节点,减少Client与Master的交互。
- GFS的Master节点上的Operation log和Checkpoint文件需要通过复制方式保留多个副本,来保障元数据以及中心管理功能的高可用性。
相对于GFS来说,我们来看HDFS做了哪些区别?
- HDFS的默认最小存储单元为128M,比GFS的64M更大。
- HDFS不支持文件并发写,对于单个文件它仅允许有一个写或者追加请求。
- HDFS从2.0版本之后支持两个管理节点(NameNode),主备切换可以做到分钟级别。
- HDFS 更适合单次写多次读的大文件流式读取的场景。
- HDFS不支持对已写文件的更新操作,仅支持对它的追加操作。
2.2 GlusterFS
GlusterFS虽然是基于文件系统的分布式存储技术,但是它与GFS/HDFS有本质的区别,它是去中心化的无中心分布式架构(图2.2);它是通过对文件全目录的DHT算法计算得到相应的Brike地址,从而实现对数据的读写;它与Ceph/Swift的架构区别在于它没有集中收集保存集群拓扑结构信息的存储区,因此在做计算的时候,需要遍历整个卷的Brike信息。

图2.2 Gluster FS
接下来,我们来看GlusterFS都有哪些具体特性,我们应该如何应用?
- GlusterFS是采用无中心对称式架构,没有专用的元数据服务器,也就不存在元数据服务器瓶颈。元数据存在于文件的属性和扩展属性中 。
- GlusterFS可以提供Raid0、Raid1、Raid1+0等多种类型存储卷类型。
- GlusterFS采用数据最终一致性算法,只要有一个副本写完就可以Commit。
- GlusterFS默认会将文件切分为128KB的切片,然后分布于卷对应的所有Brike当中。所以从其设计初衷来看,更适合大文件并发的场景。
- GlusterFS 采用的DHT算法不具备良好的稳定性,一旦存储节点发生增减变化,势必影响卷下面所有Brike的数据进行再平衡操作,开销比较大。
- Gluster FS文件 目录利用扩展属性记录子卷的中brick的hash分布范围,每个brick的范围均不重叠。遍历目录时,需要获取每个文件的属性和扩展属性进行聚合,当目录文件 较多 时,遍历 效率很差 。
2.3 Ceph & Swift
我们知道, 相对于文件系统的中心架构分布式存储技术,Ceph&Swift都是去中心化的无中心分布式架构(图2.3);他们底层都是对象存储技术;他们都是通过对对象的哈希算法得到相应的Bucket&Node地址,从而实现对数据的读写 。
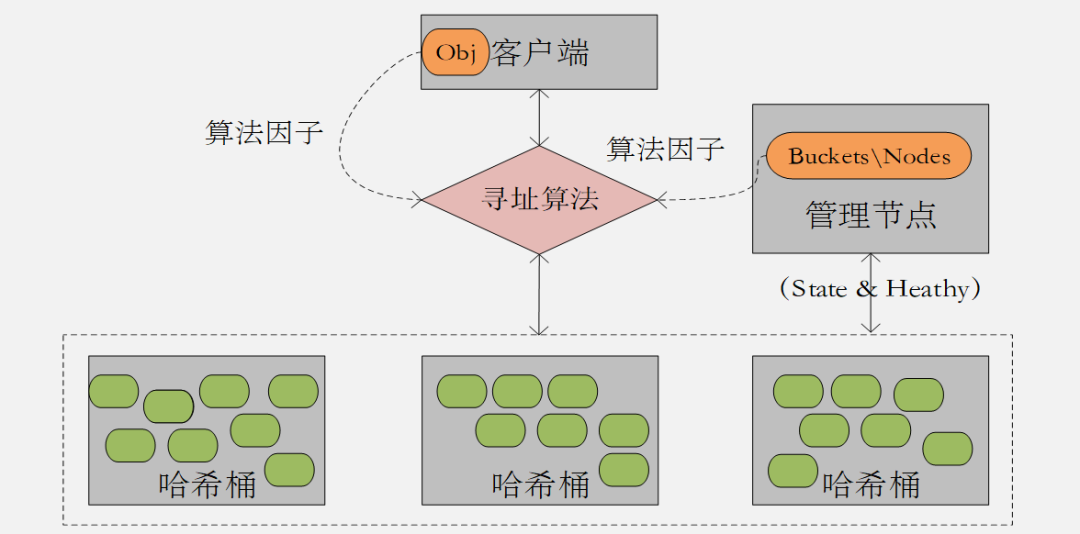
图2.3 去中心化的分布式存储架构
接下来,我们来看Ceph和Swift都有哪些具体特性,我们应该如何应用?
- Ceph是一种统一了三种接口的统一存储平台,上层应用支持Object、Block、File 。
- Ceph采用Crush算法完成数据分布计算,通过Tree的逻辑对象数据结构自然实现故障隔离副本位置计算,通过将Bucket内节点的组织结构,集群结构变化导致的数据迁移量最小。
- Ceph保持数据强一致性算法,数据的所有副本都写入并返回才算写事务的完成,写的效率会差一些,所以更适合写少读多的场景。
- 对象保存的最小单元为4M,相比GFS&HDFS而言,适合一些小的非结构化数据存储。
虽然底层都是对象存储,相对于Ceph来说,Swift又有哪些独特的特性呢?
- Swift只保障数据的最终一致性,写完2个副本后即可Commit,这就导致读操作需要进行副本的对比校验,读的效率相对较低。
- Swift采用一致性哈希算法完成数据分布计算,通过首次计算对象针对逻辑对象(Zone)的映射实现数据副本的故障隔离分布,然后通过哈希一致性算法完成对象在Bucket当中的分布计算,采用Ring环结构组织Bucket节点组织,数据分布不如Ceph均匀。
- Swift 需要借助Proxy节点完成对数据的访问,不同于通过客户端直接访问数据节点,相对数据的访问效率来讲,比Ceph要差一些。
总结来看,由于Swift需要通过Proxy节点完成与数据节点的交互,虽然Proxy节点可以负载均衡,但是毕竟经历了中间层,在并发量较大而且小文件操作量比较的场景下,Ceph的性能表现会优秀一些。 为了说明我们从原理层面的判断,接下来借助ICCLAB&SPLAB的性能测试结果来说明。
表1 Ceph集群配置
| [Node1 - MON] | [Node2 - OSD] | [Node2 - OSD] |
|---|---|---|
| [HDD1: OS] | [HDD1: OS] | [HDD1: OS] |
| [HDD2: not used] | [HDD2: osd.0 - xfs] | [HDD2: osd.2 - xfs] |
| [HDD3: not used] | [HDD3: osd.1 - xfs] | [HDD3: osd.3 - xfs] |
| [HDD4: not used] | [HDD4: journal] | [HDD4: journal] |
表2 Swift集群配置
| [Node1 - Proxy] | [Node2 - Storage] | [Node2 - Storage] |
|---|---|---|
| [HDD1: OS] | [HDD1: OS] | [HDD1: OS] |
| [HDD2: not used] | [HDD2: dev1 - xfs] | [HDD2: dev3 - xfs] |
| [HDD3: not used] | [HDD3: dev2 - xfs] | [HDD3: dev4 - xfs] |
| [HDD4: not used] | [HDD4: not used] | [HDD4: not used] |
以上是测试本身对于Ceph和Swift的节点及物理对象配置信息,从表的对比,基本可以看出物理硬件配置都是相同的,只不过在Swift的配置当中还需要配置Container相关逻辑对象。

{x}count{y}kb,x表示Swift集群当中设置的Container数量,y表示进行压力测试所用的数据大小。从图中表现出来的性能趋势分析:
- Container的数量越多,Swift的读写性能会相对差一些;
- 在4K-128K数据大小的范围内,Ceph和Swift的读性能表现都是最佳的;
- 在4K-64K数据大小范围内,Ceph的读性能几乎是Swift的2-3倍,但是写的性能相差不是非常大。
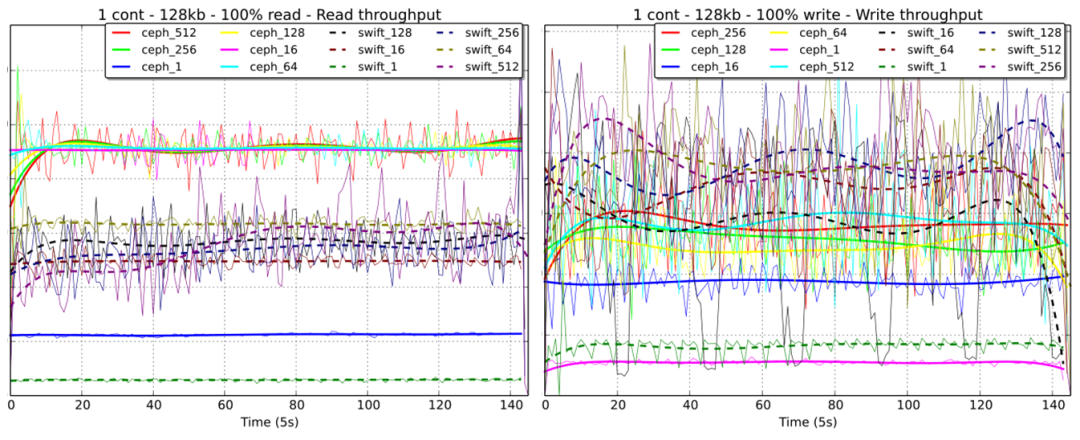
Ceph_{x}Swift{x},x表示并发数量。从图中表现出来的性能趋势分析:
- 对于并发读操作,Ceph的表现上明显优于Swift,无论是稳定性还是IOPS指标;
- 对于并发写操作,Ceph的并发量越高其性能表现越接近Swift,并发量越少其性能表现会明显逊色于Swift。
- 对于并发读写操作的性能稳定性上,Ceph远胜于Swift。
3 结语
通过对主流分布式存储技术的各项特性分析梳理之后,我们基本上可以得出以下若干结论:
- GFS/HDFS还是适合特定大文件应用的分布式文件存储系统(搜索、大数据...);
- GlusterFS是可以代替NAS的通用分布式文件系统存储技术,可配置性较强;
- Ceph是平衡各个维度之后相对比较宽容的统一分布式存储技术;
- 分布式存储技术终究不适合应用到热点比较集中的关系型数据库的存储卷场景上。
-
分布式发电技术与微型电网2011-03-11 0
-
主流CAN收发器性能对比分析哪个最好?2021-05-20 0
-
主流的三种RF方案及其优缺点对比分析2021-05-25 0
-
几款主流的Python开发板对比分析哪个好?2021-10-26 0
-
7大主流单片机优缺点对比分析哪个好?2021-11-02 0
-
常见的分布式供电技术有哪些?2023-04-10 0
-
实例分析分布式数据存储协议对比2017-09-30 796
-
深度解读分布式存储技术之分布式剪枝系统2017-10-27 1848
-
什么是分布式存储技术?有哪些应用?2017-11-17 23207
-
浅谈分布式块存储的元数据服务设计2018-05-31 4942
-
分布式存储技术有哪些2019-01-04 16319
-
主流分布式存储技术的对比分析与应用2020-07-13 3656
-
AFS,GFS ,QKFile主流分布式存储文件系统2020-08-02 3542
-
盘点分布式存储系统的主流框架2020-08-06 2654
-
分布式存储的7个特征2023-07-18 1125
全部0条评论

快来发表一下你的评论吧 !
