

LabVIEW图形化的AI视觉开发平台(非NI Vision),大幅降低人工智能开发门槛
电子说
描述
前言
之前每次进行机器学习和模型训练的时候发现想要训练不同模型的时候需要使用不同的框架,有时候费了九牛二虎之力终于写下了几百行代码之后,才发现环境调试不通,运行效率也差强人意,于是自己写了一个基于LabVIEW的机器视觉工具包,让编程变得更简单便捷的同时,还能够使用多种框架和硬件加速。
一、工具包内容
此人工智能视觉工具包主要优势如下:
- 图形化编程,无需掌握文本编程基础即可完成机器视觉项目。
- 多种摄像头数据采集和矩阵计算。
- 数百种图像算子的调用。
- 提供tensorflow、pytorch、caffe、darknet、onnx、paddle等多种框架深度学习模型的调用并实现推理。
- 支持Nvidia GPU、Intel、TPU、NPU多种加速。
- 提供近百个应用程序范例,包括物体分类、物体检测、物体测量、图像分割、 人脸识别、自然场景下OCR等多种实用场景。**
工具包中的函数选版如下:
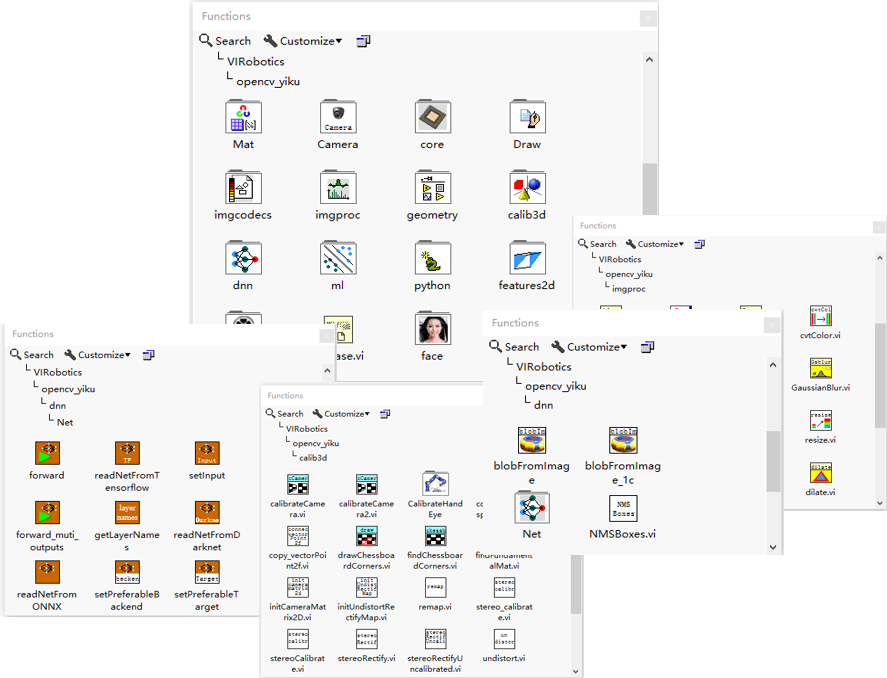
例如,一个摄像头采集并进行yolov5目标检测的范例程序,只需在LabVIEW中编写简单的图形化程序,即可实现。在大量简化编程难度的同时,也保持了c++的高效运行特性。
二、工具包下载链接
https://pan.baidu.com/s/1nyclNG8uMLnYBmcGKVDtWQ?pwd=yiku
三、实现物体识别
无论使用何种框架训练物体检测模型,都可以无缝集成到LabVIEW中,并使用智能视觉工具包提供的CUDA接口实现加速推理,模型包括但不限于:
- yolov3/yolov4/yolov5//yolox/pp-yolo
- SSD,Fastest-RCNN(物体检测)
- mobileNet、VGGnet、Resnet、Densenet、Efficientnet等(物体分类)
通过算法优化,在LabVIEW中运行模型的速度明显好于python,这对于对性能要求较高的工业现场来说非常友好实用。比如说:工地安全帽检测、物体表面缺陷检测等,如下图使用yolov4进行物体识别,在GPU模式下,无论是运行速度和识别率都可以达到工业级别。。

实测过程中我们发现同一系统环境下,使用labview工具包的识别效率远高于python识别效率。

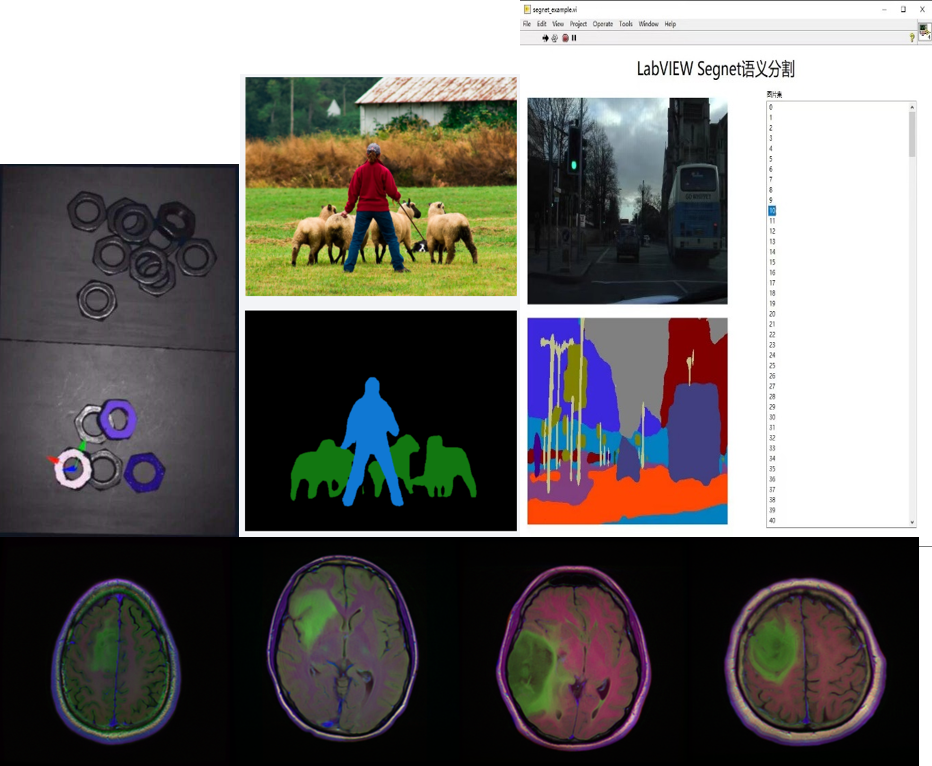
四、实现图像分割
图像分割是当今计算机视觉领域的关键问题之一。从宏观上看,图像分割是一项高层次的任务,为实现场景的完整理解铺平了道路。场景理解作为一个核心的计算机视觉问题,其重要性在于越来越多的应用程序通过从图像中推断知识来提供营养。随着深度学习软硬件的加速发展,一些前沿的应用包括自动驾驶汽车、人机交互、医疗影像等,都开始研究并使用图像分割技术。
本次集成的智能工具包提供了多种图像分割的调用模块,并实现了GPU模式下的加速运行。如:
语义分割:Segnet、deeplabv1~deeplabv3、u-net等;实例分割:Mask-RCNN、PANet等
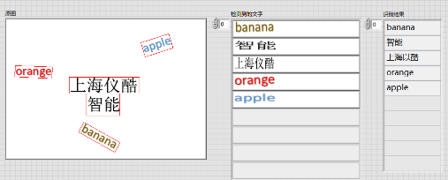
五、自然场景下的文字识别
人工智能提供了文本检测定位(DB_TD500_resnet50、EAST)、文本识别的模块(CRNN),用户可以使用该模块实现自然场景下的中英文文字识别
应用:身份证识别、表单识别、包装盒标签检测等

总结
可以通过链接进行工具包的下载,如有问题可添加技术交流群进行进一步的探讨。
审核编辑 黄宇
-
嵌入式人工智能的就业方向有哪些?2024-02-26 0
-
3种适用于人工智能开发的编程语言2018-09-12 0
-
用 NI Vision Development Module(VDM)视觉开发模块 还是用 NI Vision Assistant视觉助手?2019-07-22 0
-
全网唯一一套基于人工智能LabVIEW深度学习基础必修课操作员可以学会的传统视觉2020-10-12 0
-
图形化软件开发平台LabVIEW是什么?包括哪些部分?2021-04-07 0
-
如何使用Python配合PyQT5模块来开发图形化应用程序2021-12-24 0
-
AI人工智能计算棒RK1808 Al Compute Stick介绍2022-08-15 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
-
【EASY EAI Nano人工智能开发套件试用体验】EASY EAI Nano人工智能开发套件开箱及硬件初体验2023-05-31 0
-
NI发布了LabVIEW图形化编程环境的最新版软件LabVI2010-08-03 913
-
NI LabVIEW图形化开发环境与NI硬件平台,开发无人驾驶赛车2018-07-19 1529
-
EAIDK是全球首个采用Arm架构的人工智能开发平台2019-02-28 8869
-
LabVIEW AI视觉工具包(非NI Vision)下载与安装教程2023-02-20 3858
-
LabVIEW图形化的AI视觉开发平台(非NI Vision)VI简介2023-08-08 1692
-
labview视觉开发模块认识及应用2023-12-28 1471
全部0条评论

快来发表一下你的评论吧 !
