

爬虫的学习方法
描述
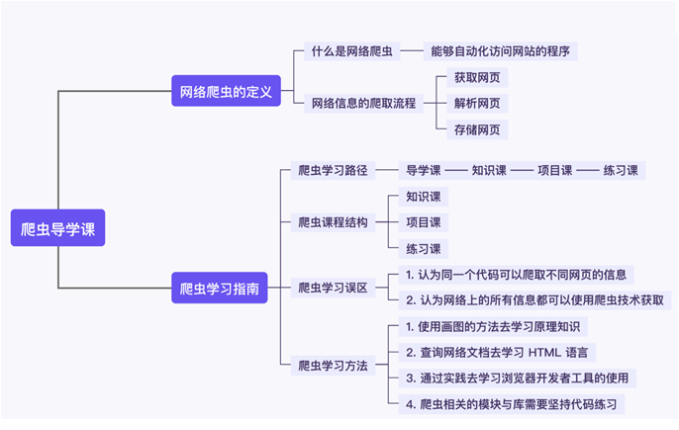
1. 网络爬虫的定义
1.1 爬虫是什么?
爬虫的本质就是模仿人类自动访问网站的程序,你在浏览器中做的大部分动作基本都可以通过网络爬虫程序来实现。
网络爬虫指的是能够自动化访问网站的程序,其目的一般是提取和保存网页信息。
爬虫能做很多事,它结合数据分析可以做商业分析,还可以给应用程序的开发提供数据支持,比如:爬二手房成交均价是多少?节日期间酒店的价格…等等。
在数据量爆发式增长的互联网时代,网站与用户的沟通,本质上就是数据的交换。以百度为例,你在搜索的时候会发现每个搜索结果下面都有一个百度快照。
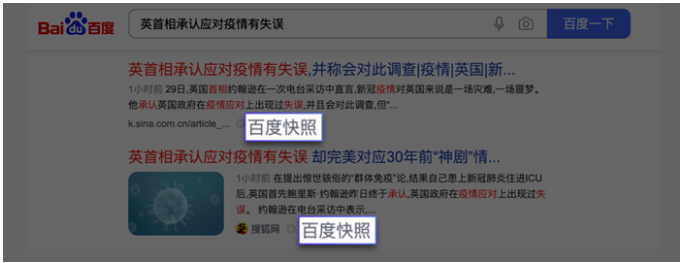
点击百度快照,你会发现网址的开头有 baidu 这个词,也就是说这个网页属于百度。
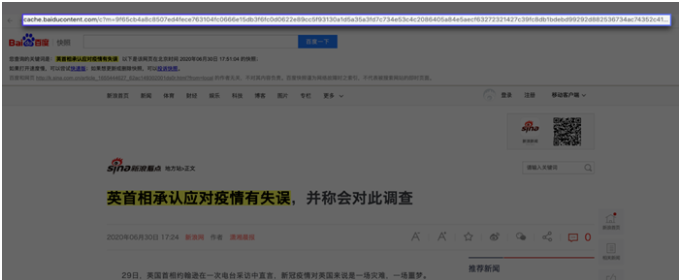
这是因为,百度这家公司会源源不断地把千千万万个网站爬取下来,存储在自己的服务器上。
你在百度搜索的本质就是在它的服务器上搜索信息,你搜索到的结果是一些超链接,在超链接跳转之后你就可以访问其它网站了。
1.2 网络信息的爬取流程
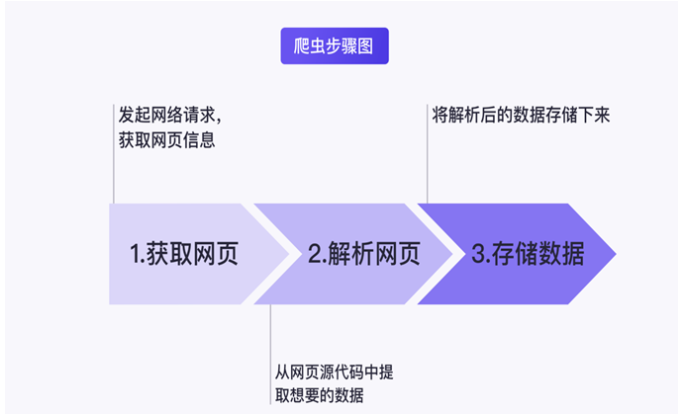
网络爬虫的流程主要可以分为三步,分别是:获取网页、解析网页以及存储数据。
获取网页,顾名思义就是获取网页信息,在网络爬虫技术中这里获取的就是网页源代码。
解析网页,指的是从网页源代码中提取想要的数据,由于网页的结构有一定的规则,配合 Python 的一些第三方库我们可以高效地从中提取网页数据。
存储数据,就是将数据存储下来。
2. 学习指南
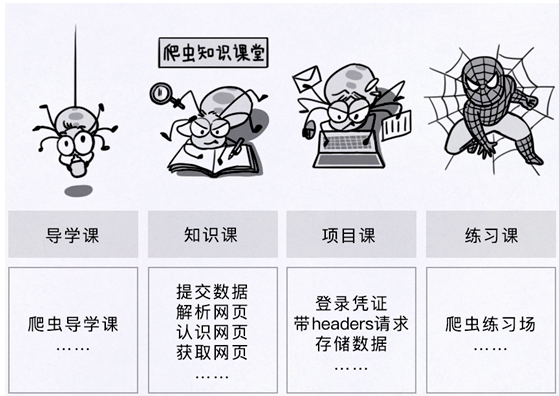
2.1 爬虫学习路径
2.2 爬虫课程的学习误区
误区1:认为同一个代码可以爬取不同网页的信息。
爬虫程序不是万能钥匙。不同网页结构的爬虫代码也是不一样的,我们要学习探索网页结构,在各色各样的网站中找到它的爬取方法。
误区2:认为网络上的所有信息都可以使用爬虫技术获取。
网络上的信息并非都能随意使用。滥用爬虫程序可能会侵犯别人隐私,占用网站资源,甚至会触犯法律风险,引发牢狱之灾。在网络世界中,有一个专门的 Robots 协议来规范爬虫,维护网络秩序。它可以告诉网络爬虫程序哪些内容是可以获取的,哪些内容是不能获取的。
2.3 爬虫学习方法
在爬虫课程中将深入学习一些 Python 模块与库的使用,除此之外还会学习大量的网络请求、爬虫的原理知识以及工具使用。
【学习方法】
1. 使用画图的方法去学习网络原理
爬虫的本质是通过程序模仿人类上网的过程,你必须了解一些基本的网络原理才能写好爬虫程序。
对于这些网络原理,你更需要的是去理解,而不是死记硬背。当你感觉理解起来很痛苦时,你可以动手将你的理解画出来。
比如网络请求,它指的是我们从浏览器点开一个网络链接再到我们看到实际网页这一过程中的工作原理。这些工作原理如下图:
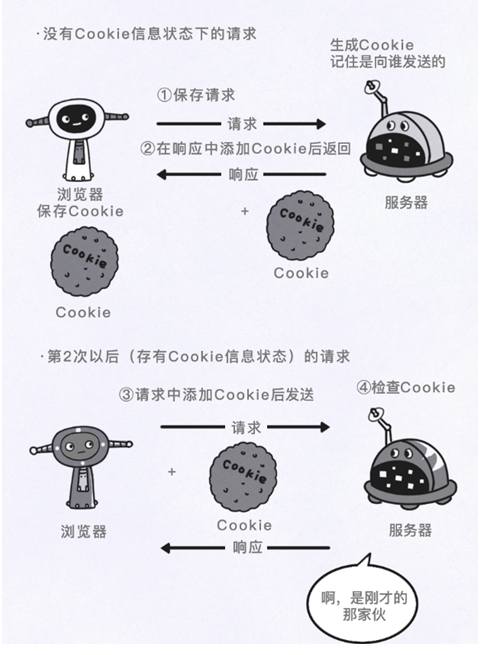
以上图为例,这一方法并不需要什么绘画技巧,重要的是将你的想法画出来,以此来加深你对这一知识点的印象。
2. 查询网络文档去学习 HTML 语言
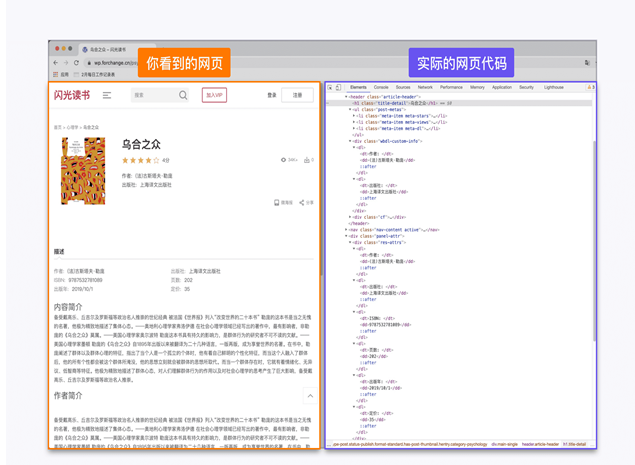
由于爬虫获取的信息大部分都是网页的源代码,这些源代码基本都是使用 HTML 语言编写的,所以 HTML 语言对于爬虫的学习十分重要。对于HTML只需要简单理解 HTML 语言的标签结构,遇到不熟悉的标签再去网上查询即可满足爬虫对于 HTML 语言掌握水平的要求。
3. 通过实践去学习浏览器开发者工具的使用
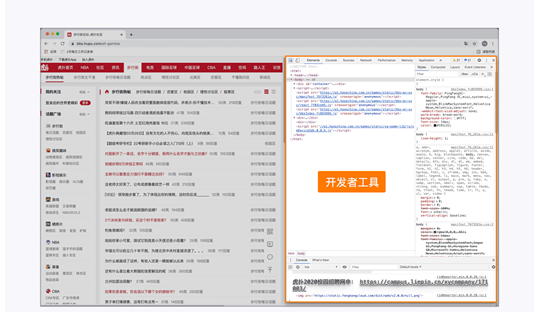
上图展示的是浏览虎扑网时,打开浏览器开发者工具查看网页元素。这部分的学习专注于实践,因为几乎所有的浏览器都有开发者工具,我们可以在日常网上冲浪的时候打开它,熟悉基本操作。
4. 爬虫相关的模块与库需要坚持代码练习
对于 Python 模块与库的知识,要通过练习、实操的方式熟悉这些代码。
【总结】
end
-
MCU的学习方法2013-05-23 0
-
快速的学习方法?2016-06-25 0
-
Linux建议的学习方法2020-04-15 0
-
统计的学习方法2020-07-15 0
-
STM32的学习方法分享?2020-08-14 0
-
STM32的学习方法2023-09-28 0
-
模拟电子威廉希尔官方网站 的学习方法2009-08-07 963
-
嵌入式linux学习方法总结2008-09-10 3531
-
第1章 ZigBee简介和学习方法2015-12-07 573
-
ZigBee 简介和学习方法2016-04-15 617
-
深度讨论集成学习方法,解决AI实践难题2020-08-16 774
-
面向异质信息的网络表示学习方法综述2021-06-09 648
-
单片机学习方法总结资料分享2021-11-13 539
-
联合学习在传统机器学习方法中的应用2023-07-05 771
-
梳理单片机学习方法、产品开发流程2023-09-21 641
全部0条评论

快来发表一下你的评论吧 !
