

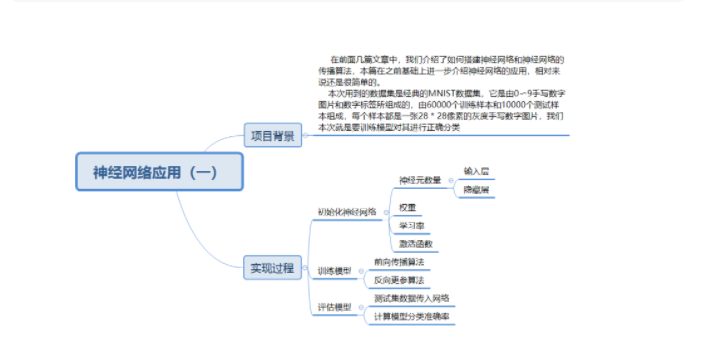
神经网络应用-1
描述
一.项目背景
在前面几篇文章中,我们介绍了如何搭建神经网络构建神经网络(一)和神经网络的传播算法构建神经网络(二),本篇在之前基础上介绍下神经网络的应用。
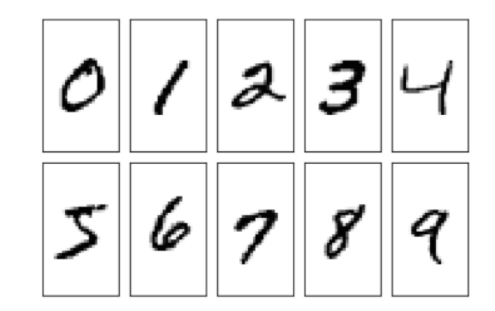
本次用到的数据集是经典的MNIST数据集,它是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。我们本次任务是通过训练集数据来训练模型对测试集数据进行正确分类,也就是说该模型是分类模型,总体来说还是很简单的。
#利用Python读取数据集第一张图片进行展示
import numpy as np
from PIL import Image
#将mnist的训练数据CSV文件加载到一个列表中
training_data_file = open("mnist_train.csv", 'r')
#读取数据
training_data_list = training_data_file.readlines()
#关闭文件
training_data_file.close()
#转换为二维数组图片矩阵
data_0=np.array(training_data_list[0].strip().split(',')[1:]).reshape(28,28)
#array转换成image
pil_img=Image.fromarray(np.uint8(data_0))
#显示图片
pil_img.show()
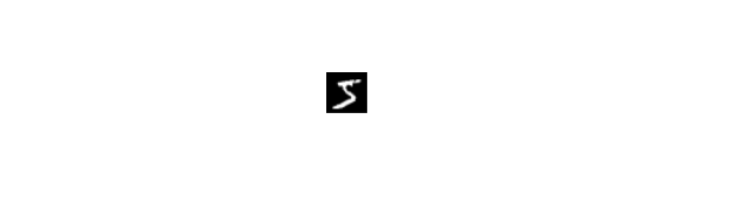
二.实现过程
1.初始化神经网络
1)初始化神经元数量
2)初始化权重和学习率
3)初始化激活函数
import numpy as np
import scipy.special as S
import matplotlib.pyplot as plt
class neuralNetwork:
#初始化神经网络,构造函数
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
#设置每个输入、隐藏、输出层中的节点数
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
#链接权重矩阵,wih和who
self.wih = np.random.normal(0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
self.who = np.random.normal(0.0, pow(self.hnodes, -0.5), (self.onodes, self.hnodes))
#学习率
self.lr = learningrate
#创建激活函数(函数的另一种定义方法,这样以后可以直接调用)
self.activation_function = lambda x: S.expit(x)
2.训练模型
1)前向传播算法
2)反向更参算法
#训练神经网络
def train(self, inputs_list, targets_list):
#将输入列表转换成二维数组
inputs = np.array(inputs_list, ndmin=2).T
targets = np.array(targets_list, ndmin=2).T
#将输入信号计算到隐藏层
hidden_inputs = np.dot(self.wih, inputs)
#计算隐藏层中输出的信号(使用激活函数计算)
hidden_outputs = self.activation_function(hidden_inputs)
#将传输的信号计算到输出层
final_inputs = np.dot(self.who, hidden_outputs)
#计算输出层中输出的信号(使用激活函数)
final_outputs = self.activation_function(final_inputs)
#计算输出层的误差:(target - actual)(预期目标输出值-实际计算得到的输出值)
output_errors = targets - final_outputs
#隐藏层的误差:是输出层误差按权重分割,在隐藏节点上重新组合
hidden_errors = np.dot(self.who.T, output_errors)
#反向传播,更新各层权重
#更新隐层和输出层之间的权重
self.who += self.lr * np.dot((output_errors * final_outputs * (1.0 - final_outputs)),
np.transpose(hidden_outputs))
#更新输入层和隐藏层之间的权重
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), np.transpose(inputs))
3.评估模型
1)测试集数据传入网络
2)计算模型分类准确率
class neuralNetwork:
#查询神经网络:接受神经网络的输入,返回神经网络的输出
def query(self, inputs_list):
#将输入列表转换成二维数组
inputs = np.array(inputs_list, ndmin=2).T
#将输入信号计算到隐藏层
hidden_inputs = np.dot(self.wih, inputs)
#将信号从隐藏层输出
hidden_outputs = self.activation_function(hidden_inputs)
#将信号引入到输出层
final_inputs = np.dot(self.who, hidden_outputs)
#将信号从输出层输出
final_outputs = self.activation_function(final_inputs)
#返回输出层的输出值
return final_outputs
#初始化输入层神经元
input_nodes = 784
#初始化隐藏层神经元
hidden_nodes = 200
#输出层中的节点数
output_nodes = 10
#学习率
learning_rate = 0.1
#将mnist的训练数据CSV文件加载到一个列表中
training_data_file = open("mnist_train.csv", 'r')
#读取数据
training_data_list = training_data_file.readlines()
#关闭文件
training_data_file.close()
#为了节省训练时间,我们此处选择前1000条
training_data_list = training_data_list[:10000]
#输出训练集数据形状
print('shape training_data_list:', np.shape(training_data_list))
#训练神经网络
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
#5轮迭代
epochs = 5
#开始训练
print('begin training...')
#遍历每一轮
for e in range(epochs):
#批量全集训练
for record in training_data_list:
#转换成一行数据,对应一个图片
all_values = record.split(',')
#转换为浮点类型数组,并进行映射, 使其小于1并且非0
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
#初始化目标值
targets = np.zeros(output_nodes) + 0.01 # 初始化target向量
#修改目标值对应概率
targets[int(all_values[0])] = 0.99
#开始训练
n.train(inputs, targets)
#输出每轮提示信息
print("train", e, 'finished!')
#进行测试,输出测试结果
print('begin test...')
#读入测试集数据
test_data_file = open("mnist_test.csv", 'r')
#读取数据
test_data_list = test_data_file.readlines()
#关闭文件
test_data_file.close()
#存储预测值
scorecard = []
#遍历每条数据
for record in test_data_list:
#转换成一行数据,对应一个图片
all_values = record.split(',')
#将实际标签值转换为整型
correct_label = int(all_values[0]) # 标签
#转换为浮点类型数组,并进行映射, 使其小于1并且非0
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
#前向传播
outputs = n.query(inputs)
#找出概率最大值对应标签
label = np.argmax(outputs)
#对比预测标签与实际标签是否相等
if (label == correct_label):
#如果相等,添加1
scorecard.append(1)
else:
#如果不相等,添加0
scorecard.append(0)
#转换为数组
scorecard_array = np.asarray(scorecard)
#计算准确率
print("correct rate = ", scorecard_array.sum() / scorecard_array.size)
结论:本次项目我们训练模型选取数据比较少,准确率已经达到差不多95%,如果选取
更多数据进行训练,准确率会更高,但是训练时间也会随之增加。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
#硬声创作季 #人工智能 模式识别-05.3.2 BP神经网络-1水管工 2022-10-27
-
[11.2.1]--神经网络1学习电子知识 2022-11-25
-
8.2 前馈神经网络(1)#人工智能jf_49750429 2022-11-28
-
9.1 卷积神经网络(1)#人工智能jf_49750429 2022-11-28
-
人脑神经网络和人工神经网络(1)#人工智能jf_49750429 2022-11-29
-
卷积神经网络(1)#人工智能jf_49750429 2022-11-29
-
应用开发:卷积神经网络的应用(1)#硬声创作季学习电子 2022-12-28
-
应用开发:深度神经网络(1)#硬声创作季学习电子 2022-12-28
-
1 LeNet神经网络(1)#神经网络未来加油dz 2023-05-16
-
3.1 多层神经网络(1)#神经网络未来加油dz 2023-05-16
-
6 实现多层神经网络(1)#神经网络未来加油dz 2023-05-17
-
RBF神经网络(1)#人工智能未来加油dz 2023-07-27
-
用Python从头实现一个神经网络来理解神经网络的原理12023-02-27 699
-
手写数字识别神经网络的实现(1)2023-06-23 573
全部0条评论

快来发表一下你的评论吧 !
