

在FPGA上实现一个模块,求32个输入中的最大值和次大值
描述
0. 题目
在FPGA上实现一个模块,求32个输入中的最大值和次大值,32个输入由一个时钟周期给出。(题目来自william hill官网 ,面试题,如果觉得不合适请留言删除)
从我个人的观点来看,这是一道很好的面试题目:
-
其一是这大概是某些机器学习算法实现过程中遇到的问题的简化,是很有意义的一道题目;
-
其二是这道题目不仅要求FPGA代码能力,还有很多可以在算法上优化的可能;
当然,输入的位宽可能会影响最终的解题思路和最终的实现可能性。但位宽在一定范围内,譬如8或者32,解题的方案应该都是一致的,只是会影响最终的频率。后文针对这一题目做具体分析。(题目没有说明重复元素如何处理,这里认为最大值和次大值可以是一样的,即计算重复元素)
1. 解法
从算法本身来看,找最大值和次大值的过程很简单;通过两次遍历:第一次求最大值,第二次求次大值; 算法复杂度是O(2n)。FPGA显然不可能在一个周期内完成如此复杂的操作,一般需要流水设计。这一方法下,整个结构是这样的
-
通过比较,求最大值,通过流水线实现两两之间的比较,32-16-8-4-2-1通过5个clk的延迟可以求得最大值;
-
由于需要求取次大值,因此需要确定最大值的位置,在求最大值的过程中需要维持最大值的坐标;
-
最大值坐标处取值清零(置为最小)
-
通过流水线实现两两之间的比较,32-16-8-4-2-1,再经过5个clk的延迟可以求得次大值;
这种解法有若干个缺点,包括:延迟求最大值和次大值分别需要5clk延时,总延迟会超过10个cycles;资源占用较高,维持最大值坐标和清零操作耗费了较多资源,同时为了计算次大值,需要将输入寄存若干个周期,寄存器消耗较多。
另一个种思路考虑同时求最大值和次大值,由于这一逻辑较为复杂,可以将其流水化,如下图。(以8输入为例,32输入需要增加两级)
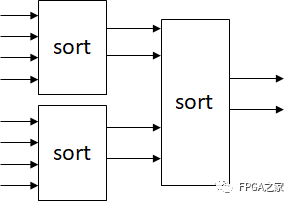
其中sort模块完成对4输入进行排序,得到最大值和次大值输出的功能。4个数的排序较为复杂,这一过程大概需要2-3个cycles完成。对于32输入而言,输入数据经过32-16-8-4-2输出得到结果,延迟大概也有10个周期。
2. 分治
如果需要在FPGA上实现一个特定的算法,那么去找一个合适的方法去实现就好了;但如果是要实现一个特定的功能,那么需要找一个优秀的且适合FPGA实现的方法。
求最大值和次大值是一个很不完全的排序,通过简单的查找复杂度为O(2n),且不利于硬件实现。对于排序而言,无论快速排序或者归并排序都用了分治的思想,如果我们试图用分治的思想来解决这一问题。考虑当只有2个输入时,通过一个比较就可以得到输出,此时得到的是一个长度为2的有序数组。如果两个有序数组,那么通过两次比较就可以得到最大值和次大值。采用归并排序的思想,查找最大值和次大值的复杂度为O(1.5n)(即为n/2+n/2+n/4… ,不知道有没有算错)。采用归并排序的思想,从算法时间复杂度上看更为高效了。
那么这一方案是否适合FPGA实现呢,答案是肯定的。分治的局部性适合FPGA的流水实现,框图如下。(以8输入为例,32输入需要增加两级)
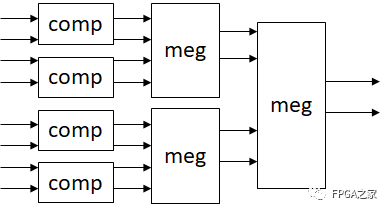
其中meg模块内部有两级的比较器,一般而言1clk就可以完成,输入数据经过32-32-16-8-4-2得到结果,延迟为5个时钟周期。实现代码如下


module test#(
parameter DW = 8
)
(
input clk,
input [32*DW-1 :0] din,
output [DW-1:0] max1,
output [DW-1:0] max2
);
wire[DW-1:0] d[31:0];
generate
genvar i;
for(i=0;i<32;i=i+1)
begin:loop_assign
assign d[i] = din[DW*i+DW-1:DW*i];
end
endgenerate
// stage 1,comp
reg[DW-1:0] s1_max[15:0];
reg[DW-1:0] s1_min[15:0];
generate
for(i=0;i<16;i=i+1)
begin:loop_comp
always@(posedge clk)
if(d[2*i]>d[2*i+1])begin
s1_max[i] <= d[2*i];
s1_min[i] <= d[2*i+1];
end
else begin
s1_max[i] <= d[2*i+1];
s1_min[i] <= d[2*i];
end
end
endgenerate
// stage 2,
wire[DW-1:0] s2_max[7:0];
wire[DW-1:0] s2_min[7:0];
generate
for(i=0;i<8;i=i+1)
begin:loop_megs2
meg u_s2meg(
.clk(clk),
.g1_max(s1_max[2*i]),
.g1_min(s1_min[2*i]),
.g2_max(s1_max[2*i+1]),
.g2_min(s1_min[2*i+1]),
.max1(s2_max[i]),
.max2(s2_min[i])
);
end
endgenerate
// stage 3,
wire[DW-1:0] s3_max[3:0];
wire[DW-1:0] s3_min[3:0];
generate
for(i=0;i<4;i=i+1)
begin:loop_megs3
meg u_s3meg(
.clk(clk),
.g1_max(s2_max[2*i]),
.g1_min(s2_min[2*i]),
.g2_max(s2_max[2*i+1]),
.g2_min(s2_min[2*i+1]),
.max1(s3_max[i]),
.max2(s3_min[i])
);
end
endgenerate
// stage 4,
wire[DW-1:0] s4_max[1:0];
wire[DW-1:0] s4_min[1:0];
generate
for(i=0;i<2;i=i+1)
begin:loop_megs4
meg u_s4meg(
.clk(clk),
.g1_max(s3_max[2*i]),
.g1_min(s3_min[2*i]),
.g2_max(s3_max[2*i+1]),
.g2_min(s3_min[2*i+1]),
.max1(s4_max[i]),
.max2(s4_min[i])
);
end
endgenerate
// stage 5,
meg u_s5meg(
.clk(clk),
.g1_max(s4_max[0]),
.g1_min(s4_min[0]),
.g2_max(s4_max[1]),
.g2_min(s4_min[1]),
.max1(max1),
.max2(max2)
);
endmodule
module meg#(
parameter DW = 8
)
(
input clk,
input [DW-1 :0] g1_max,
input [DW-1 :0] g1_min,
input [DW-1 :0] g2_max,
input [DW-1 :0] g2_min,
output reg [DW-1:0] max1,
output reg [DW-1:0] max2
);
always@(posedge clk)
begin
if(g1_max>g2_max) begin
max1 <= g1_max;
if(g2_max>g1_min)
max2 <= g2_max;
else
max2 <= g1_min;
end
else begin
max1 <= g2_max;
if(g1_max>g2_min)
max2 <= g1_max;
else
max2 <= g2_min;
end
end
endmodule
3. 其他
简单测试了上面的代码,在上一代器件上(20nm FPGA),8bit数据输入模块能综合到很高的频率,逻辑级数大概是5级左右,对于整个工程而言瓶颈基本不会出现在这一部分。32bit数据输入由于数据位宽太大,频率不会太高,但是通过将meg模块做一级流水,也几乎不会成为整个系统的瓶颈。
32bit32输入情况下,数据输入位宽为1024(不是IO输入,是内部信号)。之前在通信/数字信号处理方面可能不会用到这么大位宽的数据,但对于AI领域FPGA的应用,数千比特的输入应该是很平常的,这的确会影响最终FPGA上实现的效果。要想让机器学习算法在FPGA上跑得更好,还需要算法和FPGA共同努力才是。
审核编辑 :李倩
-
有关图形最大值 提取问题2011-02-06 0
-
DAQmx中的最大值最小值的设定2012-08-08 0
-
怎么设置波形体表的两个Y轴的最大值2013-09-29 0
-
labview中怎么判断十个数值中的最大值和最小值2014-04-23 0
-
怎么查找一个数组里面与最大值最近的极大值啊?2017-02-20 0
-
请问C6713找最大值和次大值的可行方法?2018-07-25 0
-
AD9235的使用稳定性未作出找到最大值的操作2018-10-09 0
-
四输入最小 最大值选择威廉希尔官方网站2009-09-25 2742
-
FPGA上如何求32个输入的最大值和次大值:分治2018-06-28 8472
-
交流电的有效值、最大值和平均值2023-10-30 9362
-
python中input怎么输入3个值2023-11-23 10207
-
jvm配置metaspace最大值的参数2023-12-05 2133
-
BUCK威廉希尔官方网站 占空比最小值和最大值的限制因素分别是什么?2024-01-31 3862
-
二极管击穿电压是最大值还是有效值2024-08-08 900
-
三相电流有效值和最大值关系2024-08-08 2937
全部0条评论

快来发表一下你的评论吧 !
