

深入浅出编译优化选项(下)
描述
在《深入浅出编译优化选项(上)》中,我们介绍了如何在IAR Embedded Workbench编译器中进行编译优化等级配置、多文件编译配置、灵活配置编译优化选项作用域、链接阶段优化选项配置等。
本文将进一步探索编译优化技术,介绍编译优化策略以及如何进行编译优化微调项配置。如果把编译优化等级选项看作粗调参数,那么编译优化微调项就可以比作细调参数,帮助用户进一步打磨关键代码的体积和性能的最佳配比。
编译优化等级如何对应到编译优化策略
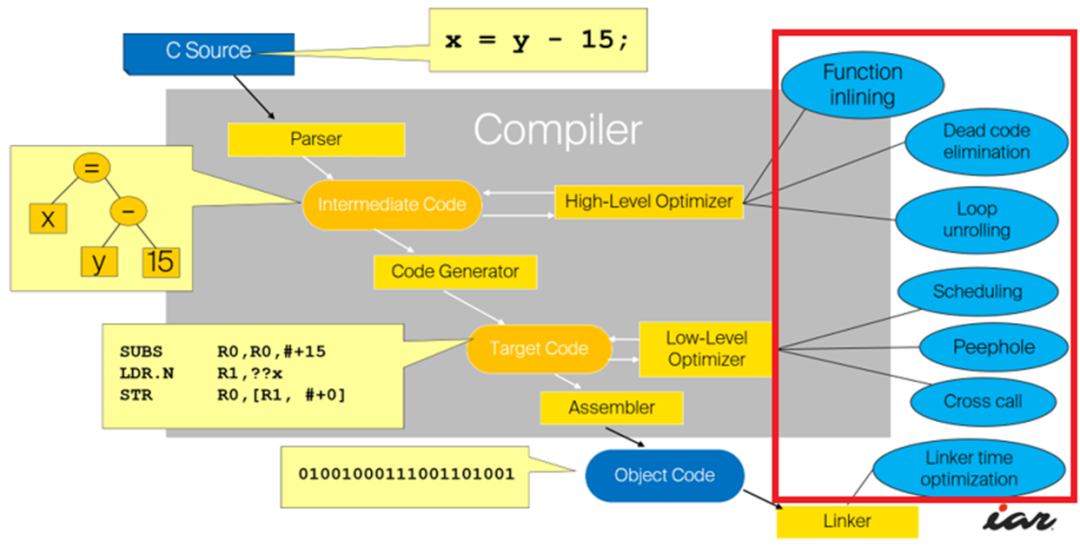
《深入浅出编译优化选项(上)》一文中的“编译器代码构建过程”章节详细介绍了代码构建过程,如上图所示。图中右边红框内的内容为编译过程中所实施的编译优化策略,我们在配置编译优化等级时,其实就是配置了一组相对应的编译优化策略。
以IAR Embedded Workbench(基于EWARM v9.32.2)编译器为例,通过菜单栏(Project -> Options)打开项目选项界面,选中“C/C++ Compiler”栏目,并且在右边选项卡选中“Optimizations”,即可进行编译优化选项配置,如下图所示。
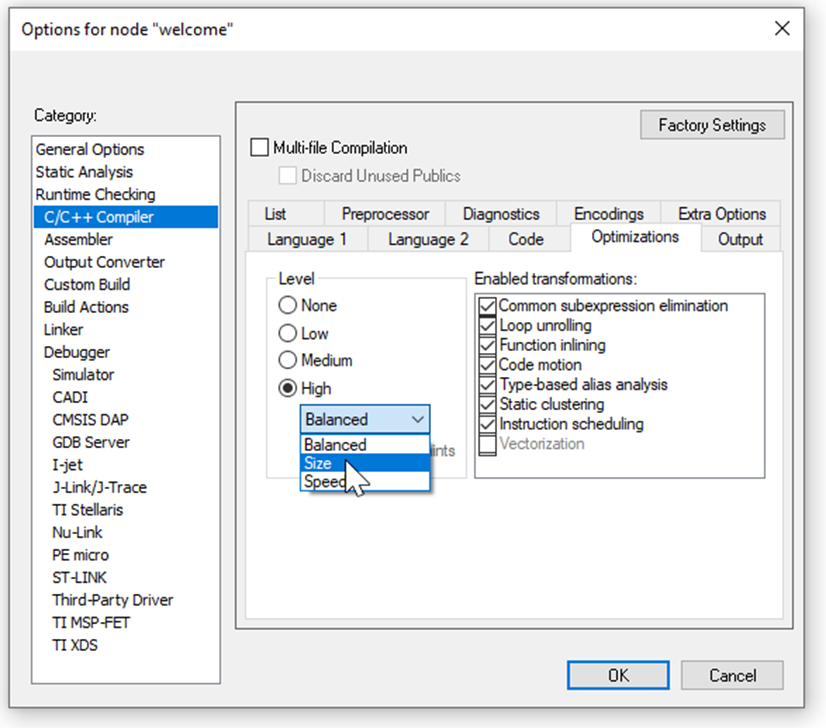
IAR Embedded Workbench共分为4个优化等级(None, Low, Medium, High),其中优化等级 “High” 又分为3个子优化等级(Balanced, Size, Speed)。下表总结各个优化等级对应的优化策略组合。

由上表可以看出,各个编译优化等级包含了不同的编译优化策略组合,每种组合都是IAR根据大量用户使用经验进行配比,因此设置编译优化等级能够满足大多数软件编译优化的需求。但是我们也看到上表中4个优化等级对应了10个以上的编译优化策略,如果能够在设置编译优化等级的基础上,再使能对优化策略的精细配置,那么有助于用户进一步打磨关键代码的体积和性能的最佳配比。
编译优化微调项配置
IAR Embedded Workbench编译器作为一款业界领先的编译工具链,除了提供最佳编译性能之外,也提供了极其灵活的编译优化选项配置来满足上述需求。用户除了可以进行编译优化等级的配置外,IAR Embedded Workbench还提供了编译优化微调项(Enabled transformations),在不同的编译优化等级中,可以进一步打开或者关闭一些优化策略,使得用户可以根据关键代码需求配置出更加精准的编译优化策略组合。
具体微调选项在下图中所示:

公共子表达式消除(Common subexpression elimination)
在编译器优化阶段,消除程序中重复计算的表达式。如下图示例,如果程序中存在多处使用相同的表达式,那么在进行“公共子表达式消除”优化后,只需要计算一次该表达式,然后将结果缓存起来供其他地方使用,从而减少程序的运行时间和计算量。

循环展开(Loop unrolling)
在编译器优化阶段,将循环体中的代码复制多次,以减少循环次数和内存访问次数,从而提高程序的执行效率。如下图示例,如果程序中有一个循环体,每次循环都进行一次printf操作,那么在进行“循环展开”优化后,可以将循环体中的代码复制多次,从而减少循环次数和内存访问次数,从而提高程序的执行效率。

函数内联(Function inline)
指的是在编译器优化阶段,将函数调用的代码替换为函数本体代码,从而减少函数调用的开销和程序的执行时间。如下图示例,如果程序中有一个函数调用语句,那么在进行“函数内联”优化后,可以将函数调用语句替换为函数体中的代码,从而避免了函数调用的开销,同时也使得程序更加紧凑,提高程序的执行效率。

代码移动(Code motion)
指的是在编译器优化阶段,将程序中的某些计算或操作移到可以共享的位置,以减少程序执行时的计算量和内存访问次数,从而提高程序的效率。如下图示例,如果程序中有多处重复计算相同的表达式,那么在进行“代码移动”优化后,可以将这些计算移到一个共享的位置,只计算一次,并将结果缓存起来供其他地方使用,从而减少程序的计算量和内存访问次数。

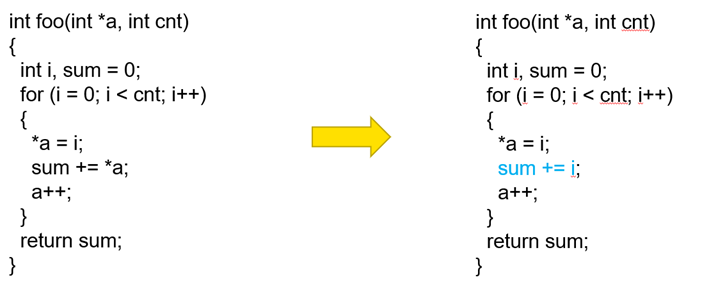
类型别名分析(Type-based alias analysis)
在嵌入式系统中,内存访问往往是非常“昂贵”的操作,而内存的访问速度会影响系统的响应速度和能耗。因此,在编写嵌入式C代码时,需要考虑如何尽可能减少内存访问次数以提高系统的性能。"类型别名分析"是一种编译器优化技术,可在编译代码时识别出哪些变量指向了同一个内存地址,从而可以更有效地使用内存,并避免在访问内存时出现重复数据的加载和存储。如下图示例,优化后,使用临时变量i(通常保存在CPU寄存器)进行计算并赋值给sum,而不使用*a,避免重新从内存中加载,从而提高运行性能。
静态聚类(Static clustering)
指的是在编译器优化阶段,通过对代码进行静态分析,将相关的代码组合在一起,以便在执行时能够更好地利用硬件资源,提高程序的执行效率和响应速度。具体来说,“静态聚类”技术会根据程序中的数据流分析,将具有相同数据依赖关系的代码段组合成独立的块,然后为每个块分配内存空间,并将其存储在连续的物理内存地址上,以便在执行时能够更好地利用缓存和预取机制,减少内存访问延迟,提高程序的性能。
指令调度(Instruction scheduling)
指的是在编译器优化阶段,重新安排程序中指令的顺序,将需要等待某些操作完成的指令与其他指令分离开来,以优化指令的执行顺序,从而减少CPU流水线上的空闲时间和内存访问次数,以提高运行性能。
矢量化(Vectorization)
“矢量化”将顺序循环转换为 NEON 硬件矢量操作,无需编写汇编代码或使用内部函数。这增强了便携性。仅当目标处理器具有 NEON 功能并启用了自动矢量化时,才会对循环进行矢量化。
编译优化微调选项
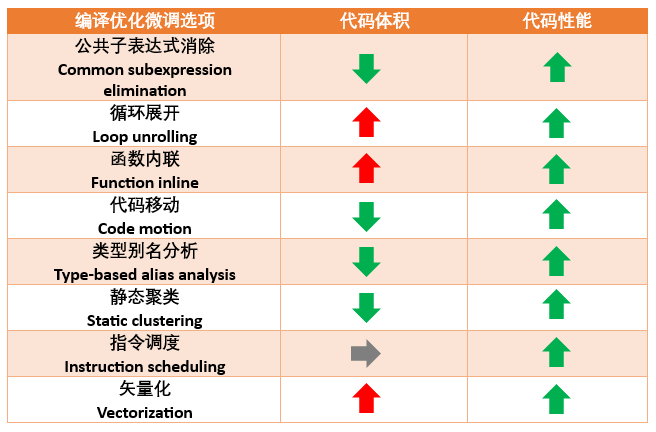
对代码体积和代码性能的影响
以上编译优化微调选项会对生成的代码体积和性能产生不同的影响,用户可以根据下表进行按需配置。
总结
了解各项编译器优化选项的定义和使用,用户就可以按照项目需求,嵌入式应用特点,灵活的配置编译器优化,实现嵌入式软件代码性能和体积达到最佳平衡点。
IAR Embedded Workbench是一款业界领先的编译工具链,除了提供卓越的性能之外,也提供了丰富灵活的编译优化选项配置,可以帮助用户在不同的嵌入式软件应用需求下,都能配比出最佳代码性能和代码体积。
审核编辑:汤梓红
-
深入浅出AVR(傻孩子)2012-06-29 0
-
深入浅出AVR2012-07-15 0
-
深入浅出玩转FPGA2012-07-21 0
-
深入浅出ARM72012-08-18 0
-
HDMI技术深入浅出2012-08-19 0
-
深入浅出Android2012-08-20 0
-
深入浅出安防视频监控系统2014-05-22 0
-
网络讲坛:深入浅出TDMS文件格式(下)-labview视频2010-03-26 950
-
深入浅出数据分析2016-01-15 660
-
深入浅出谈多层面板布线技巧2016-12-13 564
-
深入浅出Android—Android开发经典教材2017-10-24 1212
-
深入浅出数字信号处理2018-12-07 537
-
深入浅出学习250个通信原理资源下载2021-04-12 743
全部0条评论

快来发表一下你的评论吧 !
