

一文了解Intel®Developer Cloud之DL Workbench深度学习工作台
描述
文章作者:周兆靖
DL Workbench 深度学习工作台
是 OpenVINO 软件栈中非常重量级的一个工具
涉及到的内容和操作比较多
决定还是另起一篇来介绍!
1. 概述介绍
如果您对深度学习感兴趣,DL Workbench 提供了更为直观的学习平台:带您了解什么是神经网络,神经网络是如何工作的,以及如何检查它们的架构。您可以在开发产品之前,学习神经网络的分析和优化网络的基础知识,以及熟悉 OpenVINO 生态系统及其主要组件。如果您是资深的 AI 工程师,DL Workbench 将为您提供一个方便的 web 界面,以实时优化您的模型并可以为您的产品落地进行加速。
DL Workbench 可以很方便地测量和分析模型性能,同时在实验中调整模型以提高性能,最终分析模型的拓扑结构并产生可视化输出。DL Workbench 的工作流程如下图所示:
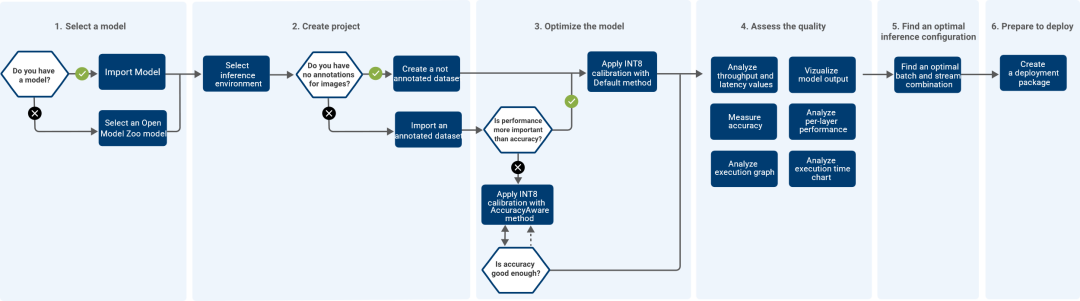
图1-1 DL Workbench 的工作流程
英特尔提供了两种运行 DL workbench(DLWB)环境。基于本地硬件的 DLWB 环境,访问的算力仅限本地现有的算力资源;基于 Intel Developer Cloud 的 DLWB 提供了丰富的算力选项用于模型的横向对比和分析,同时提供了类似本地化的用户操作体验。
Intel Developer Cloud 平台上运行 DLWB 方法:
Run DL Workbench in Intel DevCloud
https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Start_DL_Workbench_in_DevCloud.html
(复制链接到浏览器打开)
本地硬件运行 DLWB 的方法:
Run DL Workbench on Local System
https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Run_Locally.html
(复制链接到浏览器打开)
接下来我们在 Intel Developer Cloud 平台来运行 DLWB,无需安装,直接运行。
2. 启动DL Workbench
在 Intel Developer Cloud 平台上启动 DL Workbench 的步骤如下:
1打开 Work with Intel Distribution of OpenVINO Toolkit 页面:
https://www.intel.com/content/www/us/en/developer/tools/devcloud/edge/overview.html
(复制链接到浏览器打开)
划到页面下半部分,点击 Deep Learning Workbench:
https://www.intel.com/content/www/us/en/developer/tools/devcloud/edge/build/overview.html
(复制链接到浏览器打开)
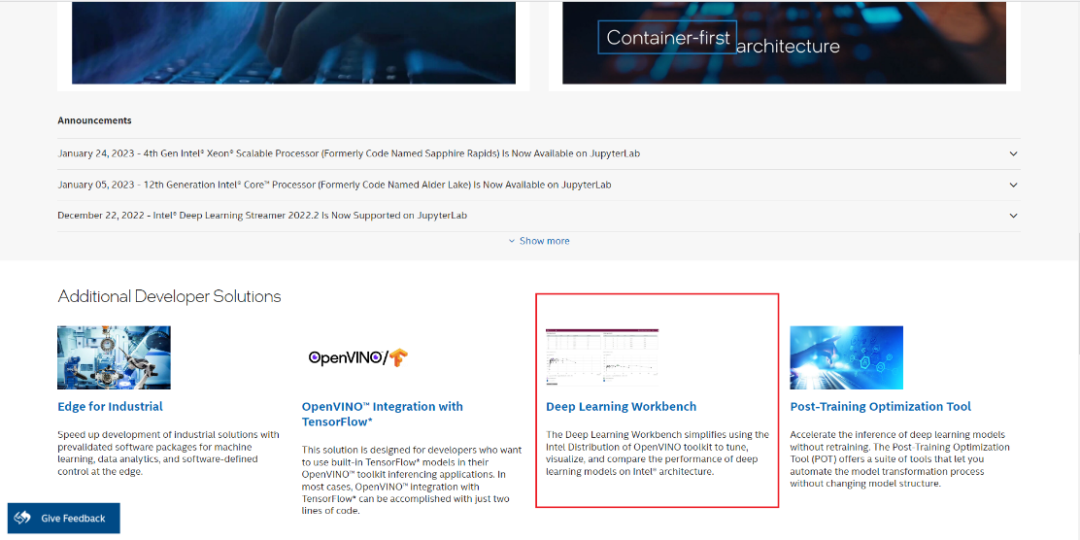
图2-1 DL Workbench启动一
2运行第一个 Cell 里的代码,之后会出现“Start Application”,点击“Start Application”并等待初始化完成,进入点击“Launch DL Workbench”启动 DL Workbench( 以下简称 DLWB):
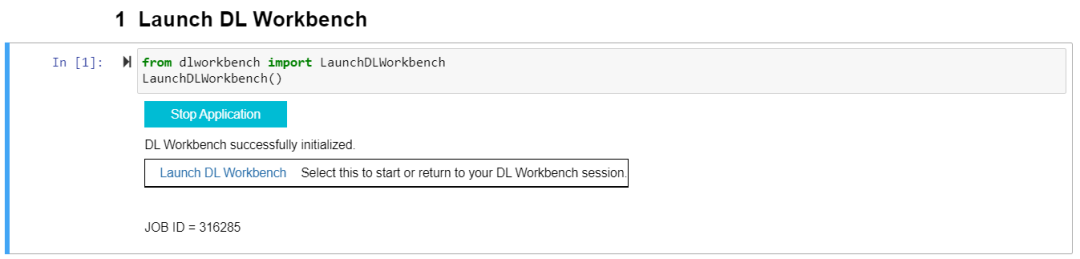
图2-2 DL Workbench 启动二
3. 使用DL Workbench评估模型性能
DLWB 的主界面如下图所示,点击 “Create Project” 进行模型评估:
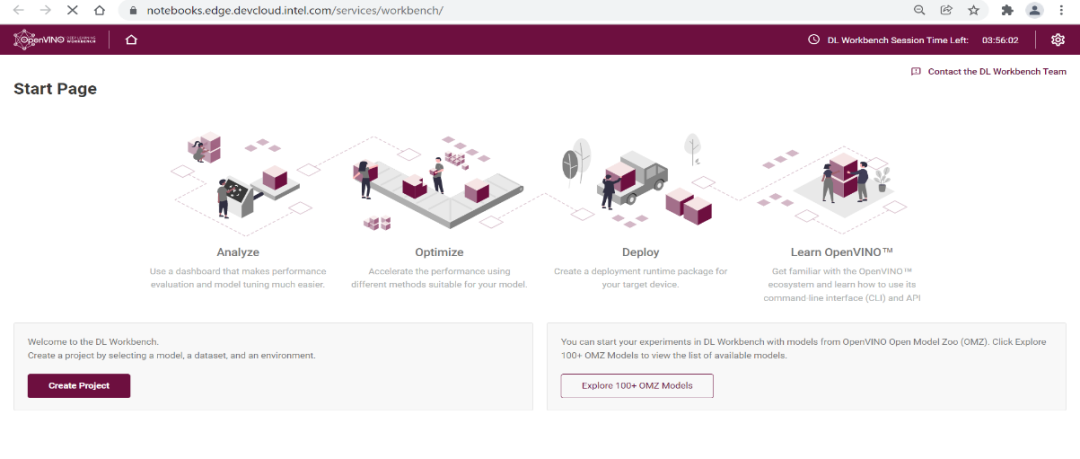
图3-1 创建 Project
步骤一
模型选择
首先点击“import model”,导入需要评估的模型。Open Model Zoo 是我们提供的一个在线模型库,你可以直接从库中下载需评估的模型,当然,你也可以上传你的本地的模型文件,既可以是 IR 格式,也可以是原生的模型格式:
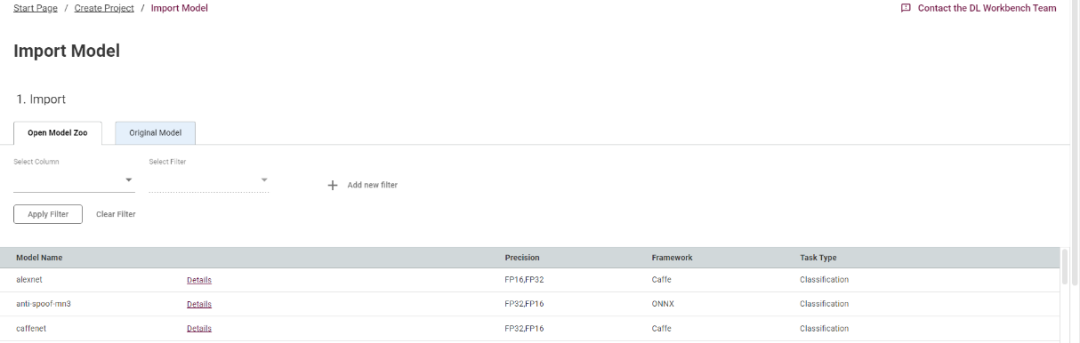
图3-2 选择模型
步骤二
设备选择
单击选定模型完成之后,请点击“Select an Environment”,这里可以选定你部署的设备节点,Intel DevCloud 平台的设备都可以进行实验:
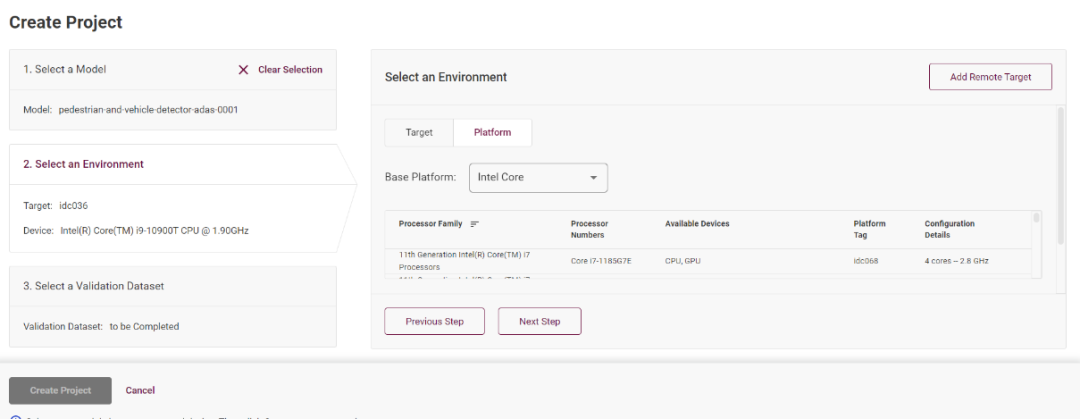
图3-3 选择设备一
你可以在”Device” 下拉菜单里选择该模型运行在 CPU 上还是集成 GPU 上:
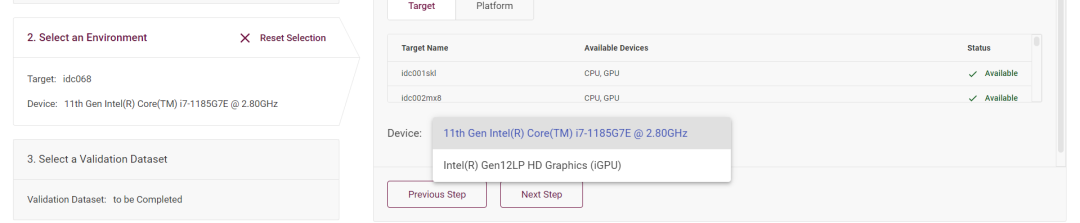
图3-3 选择设备二
步骤三
数据集选择
点击“Next Step”之后进入数据集选择页面,点击“import Dataset”,你可以选择使用 DLWB 提供的图像创建一个数据集,或者通过本地上传已有的数据集,例如 COCO,VOC,ImageNET 等格式的数据集:
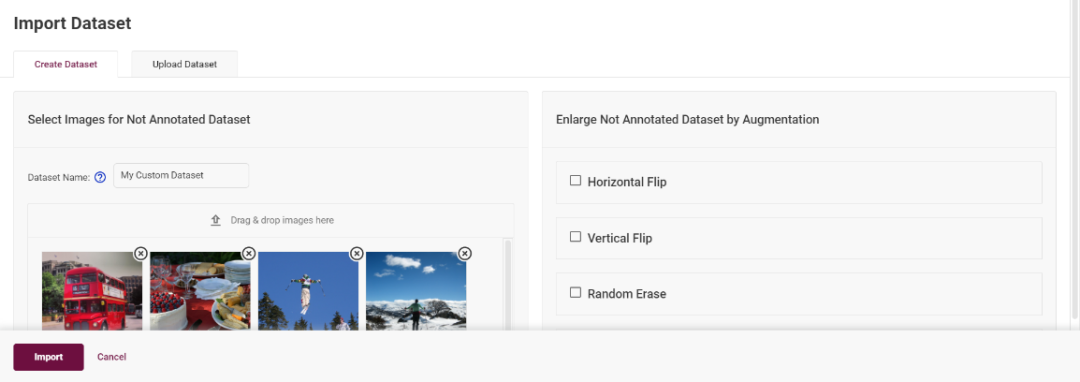
图3-4 选择数据集
步骤四
推理性能测试
点击“Create Project”之后,开始运行推理,等待推理完成之后,可以直观的看到模型的 FPS 指标,以 FPS 值来判断这个模型的性能水平:

图3-5 推理性能测试
4. DL Workbench 模型调试
4.1 模型单层运行时间统计
在模型网络分析板块,DLWB 可以计算出模型中每一层的消耗时间,可以以此进行网络分析,从而决定下一步的优化策略。
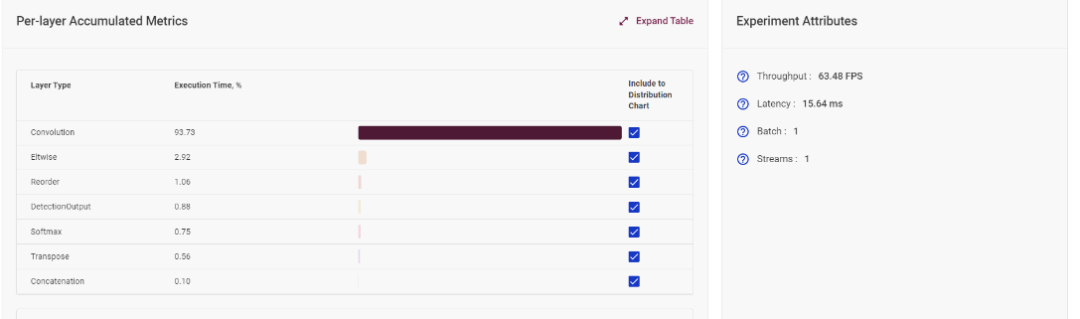
图4-1 模型单层运行时间统计
4.2模型层各精度占比统计
根据这个图表,你可以很直观的看到该模型层中每种精度的占比情况。若你觉得你可以降低 FP32 精度层的占比,你可以根据自己的需求,对高精度层实行量化操作,使其精度下降,并确保模型准确度下降在可接受的范围内,这样可以使得模型推理速度更为快速。
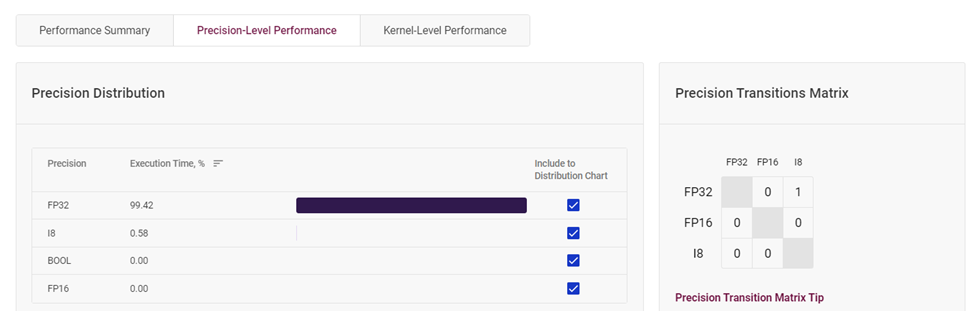
图4-2 模型层各精度占比统计
4.3 模型网络拓扑展示
这个部分通过直接展示模型的拓扑结构图和模型的层属性,让开发者对此模型能有一个更清晰与直观的认识。
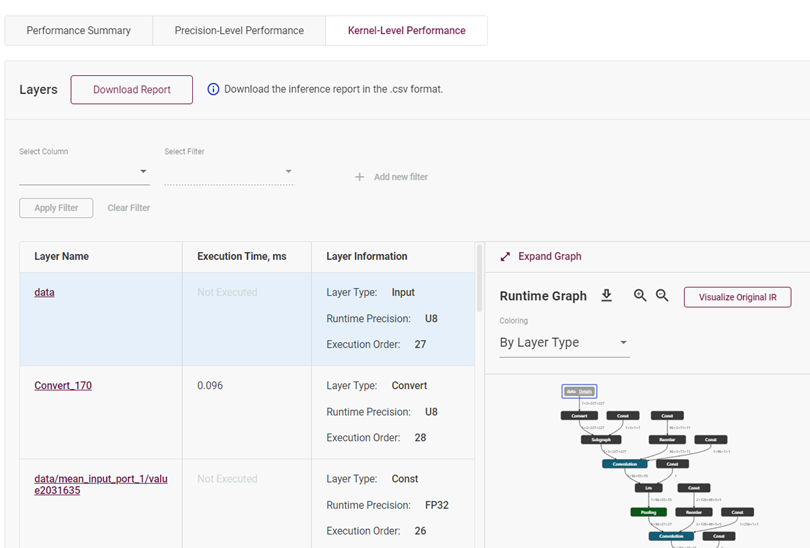
图4-3 模型网络拓扑展示
4.4 模型优化建议
下拉页面,可以看到 DLWB 会自动针对你的模型提供性能提升的建议。比如在这个模型中,它检测到该模型有0%的层运行在 INT8 整型精度上,所以它建议我们对模型进行 INT8 精度校验。
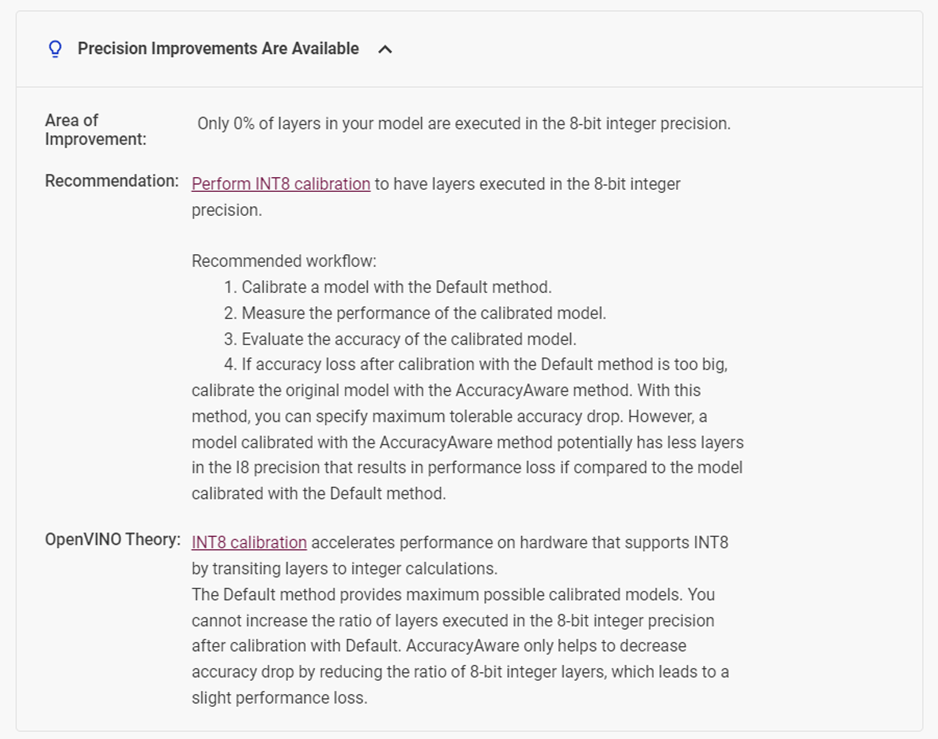
图4-4 DLWB 对模型性能提升的优化建议
4.5 校准模型成为 INT8 精度模型
在“Perform”选项中,包含了对于模型优化评估的多种策略。例如,通过校验模型层从 FP32 到 INT8 来优化推理性能:优化步骤会将原本 FP32 精度格式的模型层校准量化成精度为 INT8 的模型层,不用重训练并且可以控制精度下降不超过1%的范围。
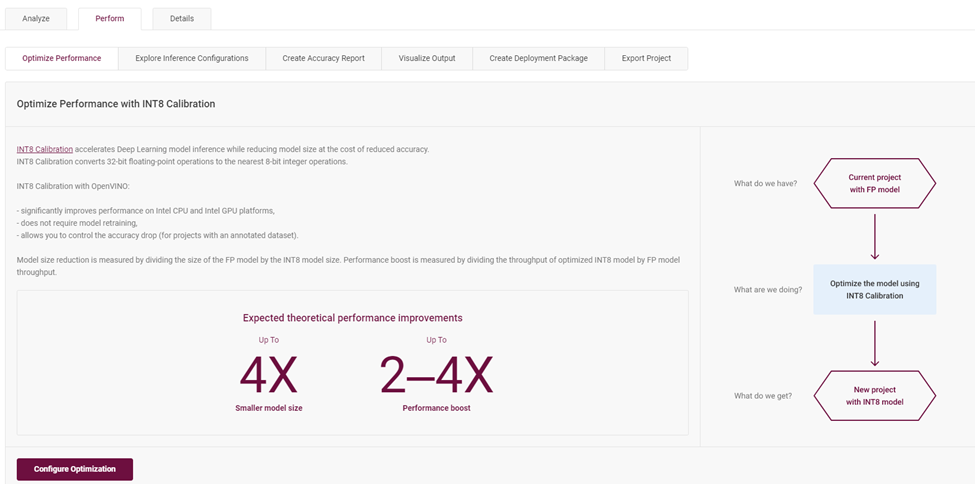
图4-5 校准为 INT8 模型层介绍页面
选择默认模式,点击启动优化,即可完成低精度优化:
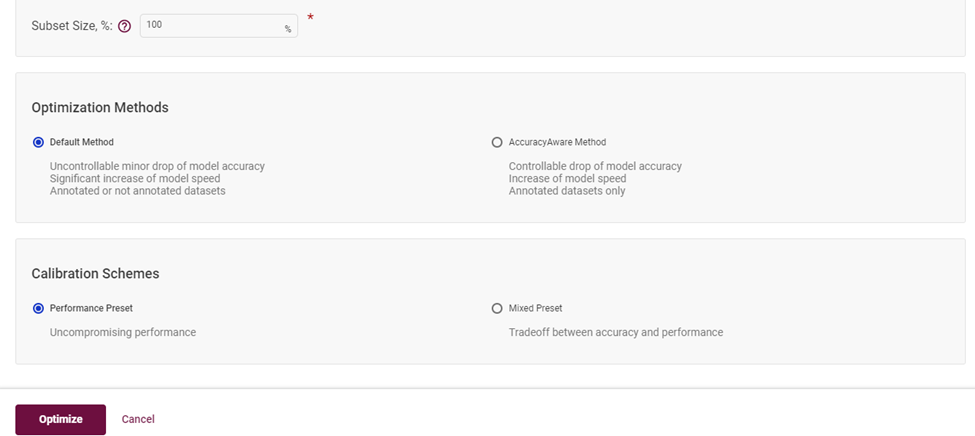
图4-6 选择校准为 INT8 模型层的算法
完成以后,你可以在模型主页看到已优化的模型和未优化的模型,可以看到模型推理吞吐量获得了巨大的提升:
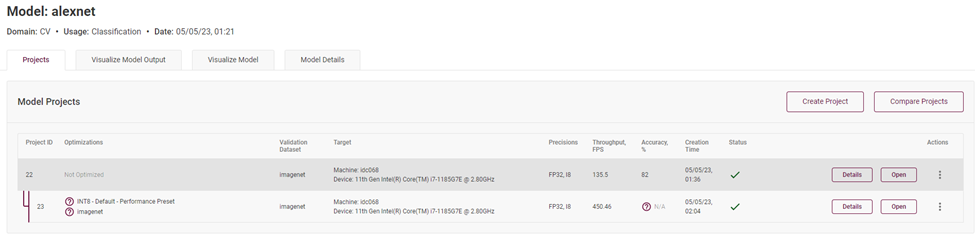
图4-7 精度为 FP32 精度与 INT8 精度模型的性能对比
4.6 创建模型准确度报告
在“Perform”标签下,选择“Create Accuracy Report”,点击创建报告,就可以得到当前模型校验当前数据集获得的识别准确度。
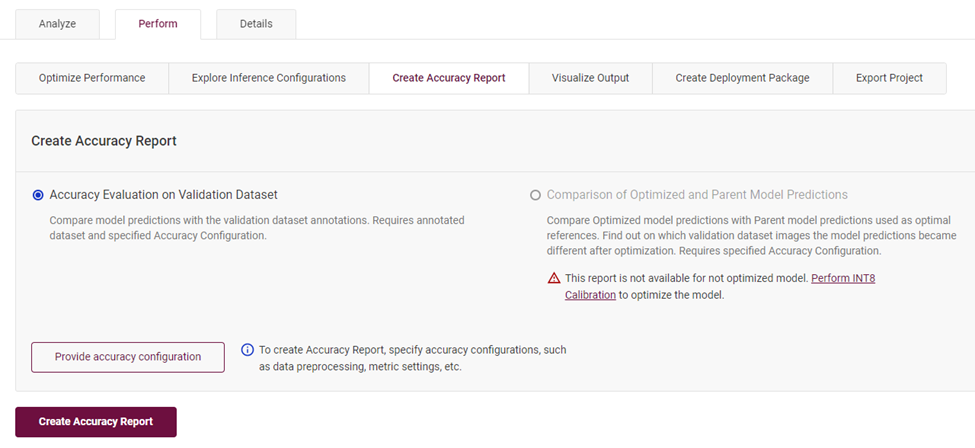
图4-8 创建模型识别准确度报告
当你同时有 FP32 精度模型和 INT8 精度模型时,你可以通过准确度测算报告来获得详细的准确度信息。标注于“Accuracy”一栏中。
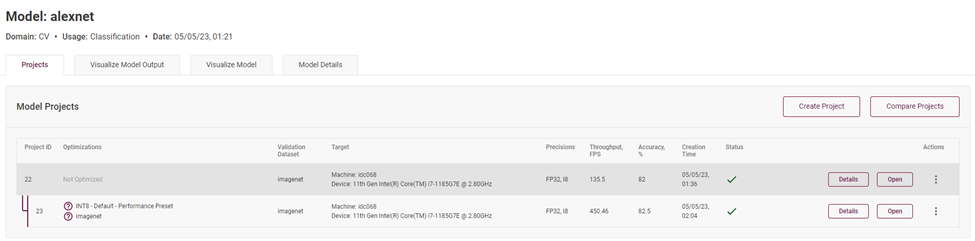
图4-9 对比 INT8 模型与 FP32 模型识别准确度与推理性能数据
最终,我们发现同样一个拓扑结构的模型,模型各层主要精度分别为 FP32 和 INT8,实测 FPS 的数据为 FP32 的 135.5FPS,而 INT8 精度的模型高达 450.46FPS,且前提是在准确度下降在百分之一的范围内。说明低精度推理对于模型推理计算的性能提升还是非常可观的。
4.7 设置多组推理参数,获取最优推理参数
优化策略中也包含了对于推理参数的组合设定,通过“Group Inference”实现:
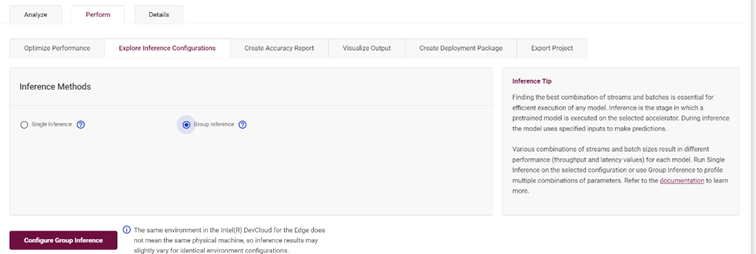
图4-10 Group Inference 设置
在此选择你需要测试的多个 Stream 数值,以及 Batch 的数值,组合推理测试结果将会以图表的方式展现,以帮助你找到该模型的在此设备上的最佳推理参数:
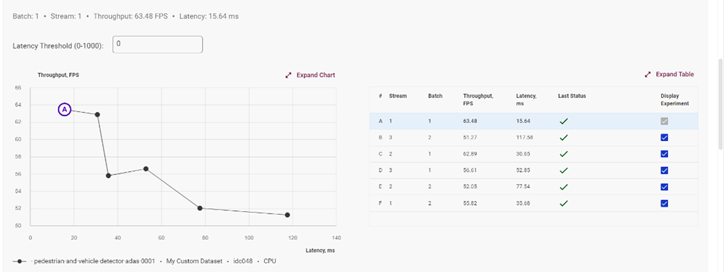
图4-11 推理测试结果展示
4.8横向/纵向模型性能评估
完成了单个模型的性能评估,可以使用不同的设备对此模型进行多次深入评估。
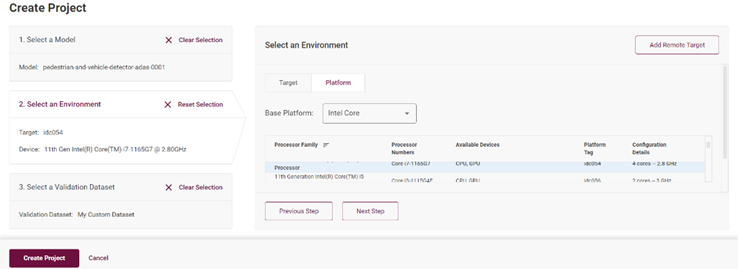
图4-12 横向模型性能对比
由此可知,你可以从横向(精度格式,batch size,steam)对模型进行评估,也可以从纵向(不同的设备,CPU/iGPU)来比较同一个模型的性能水平。当然也可以在相同的机器上选择测试两个不一样的模型来评估两个模型的性能优劣。
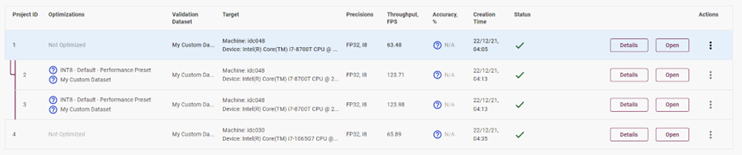
图4-13 纵向模型性能对比
5.总结
DL workbench 工具集成了非常多的功能,方便开发者的调用。由于篇幅的限制,本篇的介绍并不能全部覆盖,仅就 DL workbench 功能做分享。更多功能,请登陆Intel Developer Cloud 平台来尝试吧!
审核编辑:汤梓红
-
模具工作台检测应用案例2017-08-10 0
-
使用SPC5 studio作为工作台调试收到警告2018-09-25 0
-
工作台生成不完整的源代码怎么处理?2023-01-03 0
-
工作台2016-05-27 929
-
深度学习是什么?了解深度学习难吗?让你快速了解深度学习的视频讲解2018-08-23 1137
-
多功能焊接工作台的制作2019-04-26 7650
-
防静电工作台接地方法2019-05-17 25938
-
关于深度强化学习的概念以及它的工作原理2020-01-30 5831
-
人工智能之深度强化学习DRL的解析2020-01-24 5059
-
电机控制工作台的中文资料介绍2020-10-23 1003
-
什么是深度学习(Deep Learning)?深度学习的工作原理详解2022-04-01 10575
-
AN5796_STM32WL 系列射频工作台2022-11-21 270
-
如何借助TigerGraph机器学习工作台加速企业BI2022-11-29 566
-
Intel Developer Cloud Telemetry数据分析(一)2023-06-05 686
-
Intel Developer Cloud之Telemetry数据分析2023-07-07 613
全部0条评论

快来发表一下你的评论吧 !
