

Chiplet架构的前世今生
描述
今天,最先进的大算力芯片研发,正展现出一种拼搭积木式的“角逐”。谁的“拆解”和“拼搭”方案技高一筹,谁就更有机会在市场上赢得一席之地。随着chiplet概念的不断发酵,chiplet架构和异构计算也逐渐从头部大厂偶尔为之的惊鸿一现,演变为高性能芯片的新常态。
与此同时,一场席卷全球的AIGC竞赛,加剧了高性能芯片的需求。面对昂贵且一票难求的高性能赛道,新入局者不得不寻求更经济和更快速的方式,从而反哺了chiplet生态。
接口:Chiplet互联密钥
在高性能计算和人工智能应用中,由于SoC的尺寸已接近reticle size,设计者被迫将SoC分割成更小的芯片,并将其封装在一起。这些分解的die需要超短距离及高数据速率的die间互连。除了带宽,die与die之间的连接必须确保可靠,并具有极低的延迟和功率效率。
Die-to-Die接口定义
Die-to-die接口是在同一个封装内的两个die之间提供数据接口的功能模块,它提供了一种可靠、高带宽的芯片间互连方式,使不同的dielet可以在系统级别上进行连接和协同工作。为了实现功效和高带宽,它们利用了连接裸片的极短通道的特征。
Die-to-die接口通常由一个PHY和一个控制器模块组成,在两个die的内部结构之间建立可靠的数据连接。倘若没有die-to-die接口,die之间的通信会变得十分困难。
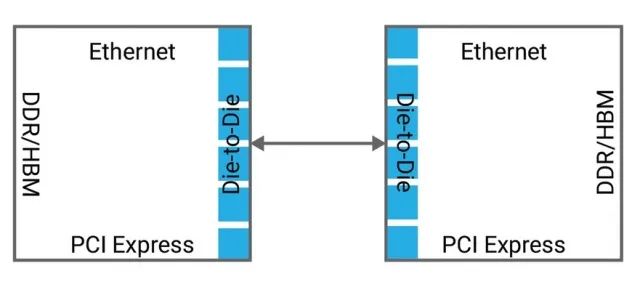
Example of a high-performance computing and server SoC requiring die-to-die connectivity (source:eetimes)
Chiplet架构的前世今生
Die-to-die接口作为一种互联技术,是为支持chiplet设计而诞生的。其背后的chiplet架构为应用需求驱动,经历了三个时期的发展迭代。
同构拆分:首先,是成本的迭代。大型SoC被拆分为多个相同设计的同质die,单独流片,从而提高制造效率并降低成本。典型案例:AMD Zen/Zen+,在性能不变的情况下实现了40%的成本降幅。
同构扩展:而后,是性能的提升。通过把更多的功能单元拼接在一起,进行横向扩展,从而实现更高的计算能力和内存容量;这对于处理大规模的神经网络和海量数据的AI训练任务非常有益。
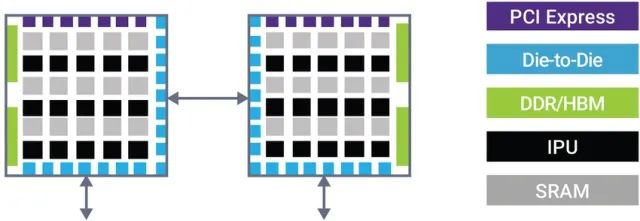
Example of an AI SoC requiring die-to-die connectivity(source:eetimes)
一个典型代表是Tesla DoJo,在Dojo芯片系统中,D1芯片是Dojo系统的基本算力单元(chiplet),每个Dojo则包含了25个D1及40个专用的IO芯片,使用TSMC的system-on-wafer技术集成到一起,实现超大算力支持。
模块化异构组合:随着chiplet发展到3D架构,chiplet 逐渐演变模块化单元,并分化为功能die和互连die两种单元类型。常见的功能die如CPU、GPU、Senser、Wireless、光电等模块,专注于不同的任务和功能的实现;互连die则通常包含一些关键的硬件组件,以实现功能die之间的高速数据传输和通信。通过组合不同功能的芯片模块,有助于芯片更灵活、更容易地实现扩展和定制。
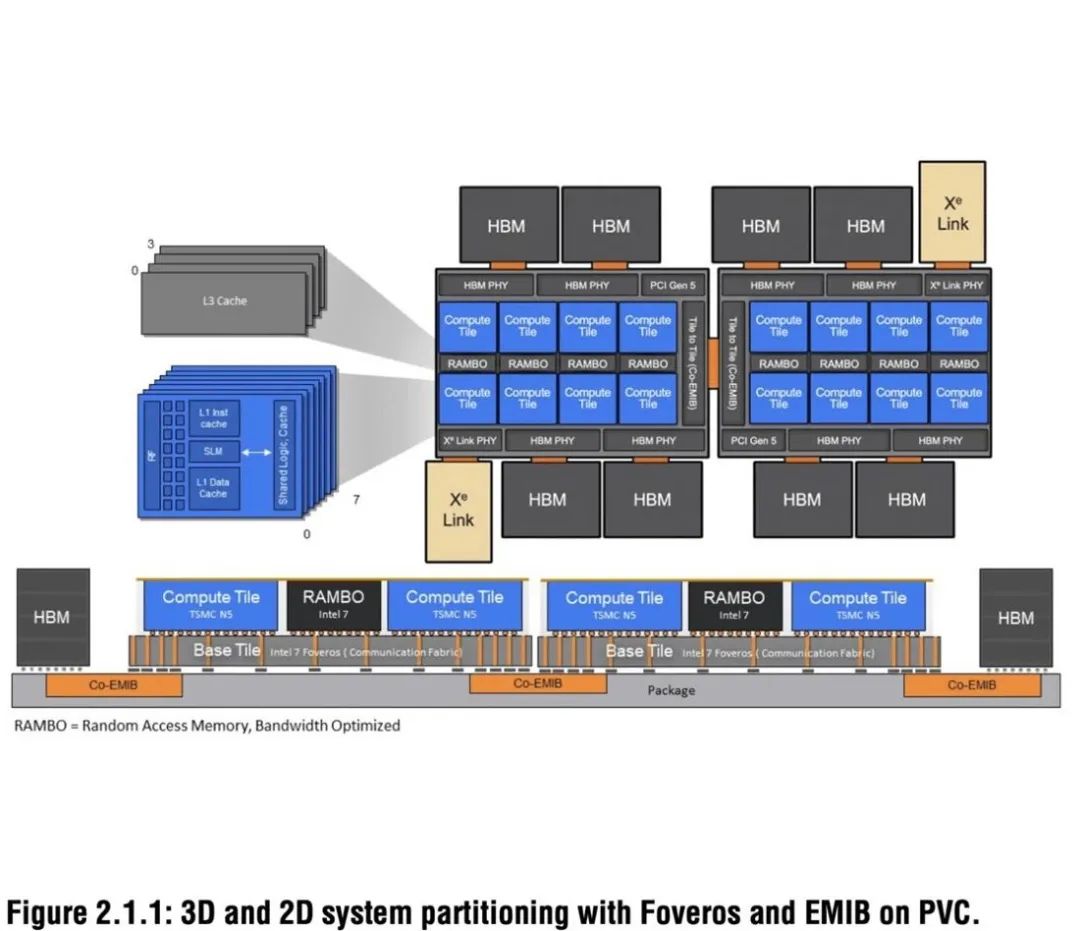
典型案例如Intel的Ponte Vecchio。由于使用chiplet设计,Intel得以在良率可控的情况下加入了大量的Xe核和海量缓存:包括128个Xe核,64MB的register file,64MB的L1 cache和408MB的L2 cache,共63颗chiplet(47个功能单元)。Ponte Vecchio系统可以实现839 TFLOPS的峰值浮点数算力以及1678 TOPS的峰值整数算力。
从Intel Lakefield/Ponte Vecchio到AMD MI300再到Nvidia的GRACE+HOPPER,在实现如此高算力的超大规模芯片系统中,chiplet模块化技术可谓居功至伟。与此同时,模块化架构也催生了互联设计方式的变革。
高速互连芯粒 IO Die
高速互联芯粒IO Die,是一种独立于CPU核心芯片的dielet。IO Die中通常包含各种负责互连的功能模块,负责进行其他功能单元的互连。在AMD的Zen 2架构中,首次采用了分离的IO Die设计,这是Chiplet架构中的一大里程碑事件。
AMD实现chiplet设计的方式是将CPU与IO单元分离,分别称为CCD(Core Chiplet Die)、IOD(IO die)。在一代Zen架构中,每颗CCD都包含IO部分,1-4组CCD单元实现了8-32核的并行,通过 IFOP(Infinity Fabric on Package)互连技术相连;Zen 2架构中,IO核心被剥离了出来,用IO Die连接所有CPU core。CCD中包括CPU核心、缓存,后者包括各类控制器和输入输出。IO die在AMD的Zen系列里一直沿用至今。
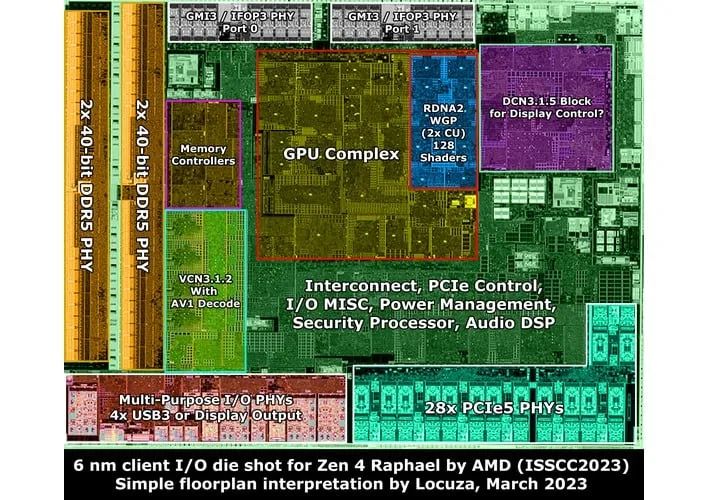
AMD's Zen 4 IO die shot isolated by Li Jae-Yeon.
总的来说,IO die设计可以提高系统的性能、可靠性和可扩展性,且可以降低制造成本和电源消耗。此外,IO die可以选择最适合的工艺节点,不必紧跟CPU Core采用最先进的工艺节点,可以每两三代处理器更新的时候再做一次大的迭代。
作为IO die技术的开拓者,AMD采用IO Die分离互连单元,打造高性能服务器芯片的策略,已经形成了正向的反馈。虽然在chiplet诞生初期,IO die主要由AMD等大厂根据自身产品需求自行研发,但随着CPU、GPU和其他高性能芯片领域厂商的崛起,加大了对通用IO die的需求。应市场需求,国内也出现了一些技术能力强、业务快速增长的第三方通用IO die供应商,如奇异摩尔。
奇异摩尔的IO Die方案主要面向高端服务器、自动驾驶、DPU、Edge AI、5G等高性能场景。通过在IO Die中集成超高速D2D接口,全集成高速接口以及超高速互联网络等模块,产品适用于计算密集的场景,并支持多场景设计复用,能助力高性能计算客户实现产品性能的成倍提升,研发成本和量产时间的下降。
高性能互连底座 Base Die
随着超高规模和异构计算的快速发展,3DIC正成为一股重要的技术方向。在3D Chiplet架构中,互连芯粒IO die逐渐演成变为3DIC的高性能互联底座 “Base die”。
Base die较IO die面积更大,除了IO die中的互联模块,还可以把原本集成在SoC中的Power、SRAM、I/O等非数字功能模块拆分并拼搭进去,从而构成一个高度集成并节能的多核异构计算架构,同时实现上层的逻辑芯片面积最大化和芯片单位面积的最小化。
在互联方面,Base die支持水平方向和垂直方向的异构芯片互连。垂直方向,通过TSV、microbump等3D互连技术与顶层逻辑芯粒、substrate垂直通信,从而以最小限度实现die与die之间的互连、片外连接,显著提高芯粒集成密度。Base die适用于数据中心CPU/GPU/AI,智能汽车等工作负载居高不下的领域。
以Intel lakefield为例,设计为3D立体模块化堆叠,由 3 层 die 组成。其中,底层的Base die 以Intel 22节点制造,主要包含各种协议的 IO 功 能,如USB,PCIe等,将中间层基于10nm制造的computing die(计算单元、图形单元和显示单元)堆叠在其上,并通过High current TSVs 与上层的功能单元互连。通过这种设计,Lakefield得以把更多的面积留给computing die,最终实现了10倍的SoC功率提升,2倍的图形性能提升和2倍PCB面积下降。同类Base die设计还有AMD的旗舰级芯片MI300等。
AMD Instinct MI300 HPC accelerator. (Image Source: AMD)
随着高性能芯片需求的增长,Base die市场不断扩张,国内也崛起了一些相关的产品研发企业,如奇异摩尔,国内首批专注于chiplet的研发企业,面向数据中心、自动驾驶、下一代个人计算平台等高性能算力场景提供3D chiplet架构的IO Die 和 Base die 解决方案。致力于以数据存储和传输为中心,通过互联芯粒连接和调度不同类型计算单元,成为大规模分布式异构计算平台的基石。
行业生态格局转变
Chiplet 生态发展至今,我们看到了它作为一种全新的技术,从内部自研到开放的发展过程:
内部自研:
Chiplet技术发展早期,如AMD等大型芯片制造商开始试水chiplet,但往往局限于企业内部独立研发和应用,且仅应用于一些高端产品,如服务器和高性能计算等,组装和测试等方面仍存在技术瓶颈。
半开放期:
目前,随着chiplet技术的不断成熟和商业化的推广,越来越多的芯片厂商、设计公司和封装测试厂商开始关注和使用chiplet技术。Chiplet应用范围日益扩大,如各类处理器、加速器、芯片组和存储器,从高性能服务器直至小型化电子产品;组装和测试技术也得到了进一步的改进和完善;此外,市场上关于chiplet技术相关的产品和服务不断涌现,chiplet作为一种芯片技术,其商业化应用趋势也促进了整个芯片生态系统的升级和发展。
全面开放:
随着chiplet技术的发展,未来会出现越来越多的产业链公司,专注于chiplet产业链各环节,即由chiplet系统级设计、EDA/IP、芯粒(核心、非核心、IO Die、Base Die)、制造、封测组成的完整chiplet生态链。
在我国,目前具备3D异构芯片整体能力的芯片厂商极少,大多数芯片厂商还是依赖IP厂商提供并行物理层或者串行物理层IP,Fab厂商提供先进封装能力,一个完整的、面向 chiplet芯片的社会分工体系亟待形成。
作为国内第一批专注于2.5D-3D Chiplet服务的公司,奇异摩尔集合了一个全球大厂具有chiplet量产经验的核心团队,在Base die和IO Die方面具有先发优势。奇异摩尔拥有多项芯片互联关键基础技术,包括高性能互连底座Base die、高速互联芯粒IO die等,这些技术作为高密度、低延迟互连实现的关键,在chiplet系统运行方面起着关键作用。
基于Chiplet架构、通用互连芯粒、设计工具,及海量第三方芯粒库,奇异摩尔致力于打造全球领先的chiplet通用产品解决方案。客户只需自研部分核心芯粒,复用其他通用单元进行设计组合,即可快速构建所需专属高性能芯片,极大降低研发成本和设计周期。同时,经由Chiplet超高速互联形成超大规模系统级芯片(M-SOC), 助力提升芯片性能和能效,共同突破摩尔定律边界。
除Base die、IO die等芯粒产品之外,奇异摩尔还有更多的软硬件产品和解决方案,如die-to-die 接口IP,chiplet软件设计平台等,全面覆盖2.xD、2.5D到3D的chiplet架构,为客户提供从chiplet组合方案设计、芯粒打样封测到量产管理服务的全链路解决方案。
作为半导体领域最为热门的技术路线,chiplet已被许多头部公司纳入实践。但这场基于制程与生态圈的革命,绝非仅靠一两家行业巨头的努力就可以实现,它需要一个成熟生态体系的群策群力,全产业链每一个环节的深度参与、合作。在这个生态圈中,从前端的EDA、设计公司,代工厂、封装企业,每一环的意义都非同寻常且不可替代。
-
嵌入式ARM开发的前世今生,看完你就懂了2021-04-20 0
-
芯片开源架构RISC-V的前世今生2020-05-21 0
-
芯片春秋——ARM前世今生2020-05-25 0
-
关于汽车操作系统的前世今生看完你就懂了2021-09-26 0
-
汽车总线前世今生2017-01-24 828
-
六张图看懂人工智能的前世今生2018-08-25 4413
-
初探工业互联网的前世今生2018-12-13 3151
-
聊聊MSP和CMP的前世今生2018-12-30 1663
-
MiniLED背光的前世今生2019-07-08 9700
-
人工智能的前世今生2020-12-10 3637
-
高压电源创新:前世今生2022-11-03 424
-
电池管理技术的前世今生2022-11-04 404
-
蓝牙技术的前世今生2023-05-09 2433
-
带你探索吹风筒的前世今生【其利天下高速风筒方案开发】2023-11-02 2084
-
二极管的前世今生2023-12-14 1139
全部0条评论

快来发表一下你的评论吧 !
