

一个通用的自适应prompt方法,突破了零样本学习的瓶颈
描述
今天要给大家介绍一篇Google的研究,解决了大语言模型(LLMs)在零样本学习方面的困境。相比于少样本学习,LLMs在零样本学习上常常表现得比较弱,这主要是因为缺乏指导。而且,目前的研究对零样本学习的改进也不多,因为在没有真实标签的任务中设计prompt方法还比较困难。
为了解决这个问题,这篇研究提出了一种Universal Self-adaptive Prompting (USP)方法,对LLMs的零样本学习进行了优化,同时也适用于少样本学习任务。USP只需要少量未标记的数据,就能大幅提升LLMs在20多个自然语言理解和生成任务上的表现。实际上,它的结果比起少样本基线方法甚至更好!
接下来就让我们一起揭开USP方法的神秘面纱,看看它是如何做到这一切的吧!

论文:Universal Self-adaptive Prompting
地址:https://arxiv.org/pdf/2305.14926.pdf
前言
在介绍USP方法之前,让我们先了解一下三种主流方法,分别是:Chain of Thought (CoT)、Self-Consistency (SC)和Consistency-based Self-adaptive Prompting (COSP)。这些方法是目前LLMs推理研究的主要方向,而COSP方法也是这篇研究的主要灵感来源。
首先,CoT方法将一个具体的推理问题拆分成多个步骤,并将每个步骤的解释信息输入LLMs,从而得出最终的答案。这种方法已经被证明可以解决具有较大推理难度的问题,并且当训练数据足够时,大模型会表现出出色的推理能力。很快,SC方法应运而生,对CoT方法进行了改进。SC方法认为,通过对多个CoT推理路径进行采样,并将它们的结果进行投票,选择一致性最高的输出作为最终答案,可以进一步提高LLMs的推理准确性。
而COSP方法采用了双阶段策略,以进一步增强LLMs的零样本学习能力。在第一阶段,COSP类似于SC,采用多路径解码进行零样本推理。它对同一查询在不同解码路径上进行预测,并计算出归一化熵,用于量化模型在不同解码路径下的自信程度和预测之间的差异。基于熵值(以及其他指标如多样性和重复性),COSP对第一阶段的输出进行排名,并选择自信的输出作为伪演示数据。在第二阶段,COSP再次将这些伪演示数据与查询结合,以类似于少样本推理的方式进行处理。最终的预测结果是通过两个阶段的输出进行多数投票得出的。
这些方法为LLMs的推理能力带来了显著提升。然而,它们对于不同类型的任务可能存在一些局限性和挑战。比如,针对一些分类NLP问题,模型的逻辑回归结果对于不确定性的量化很有用,但在COSP的设计中却忽视了这一信息。此外,对于那些涉及创造性和生成性任务的任务,多数投票的概念可能并不存在,因为有很多合理的解决方案存在。
因此,这篇研究的目标是提出一种通用的、适用于各种任务的方法,而不仅仅局限于COSP所考虑的狭窄领域。然而,要实现这个目标并不容易,因为通用的提示策略需要适应众多且差异巨大的任务,这些任务在目标、提示、评估以及置信度/不确定性量化方面都存在显著的差异。
接下来,我们将详细介绍Universal Self-adaptive Prompting(USP)方法,看看它是如何解决这些挑战的!
USP方法
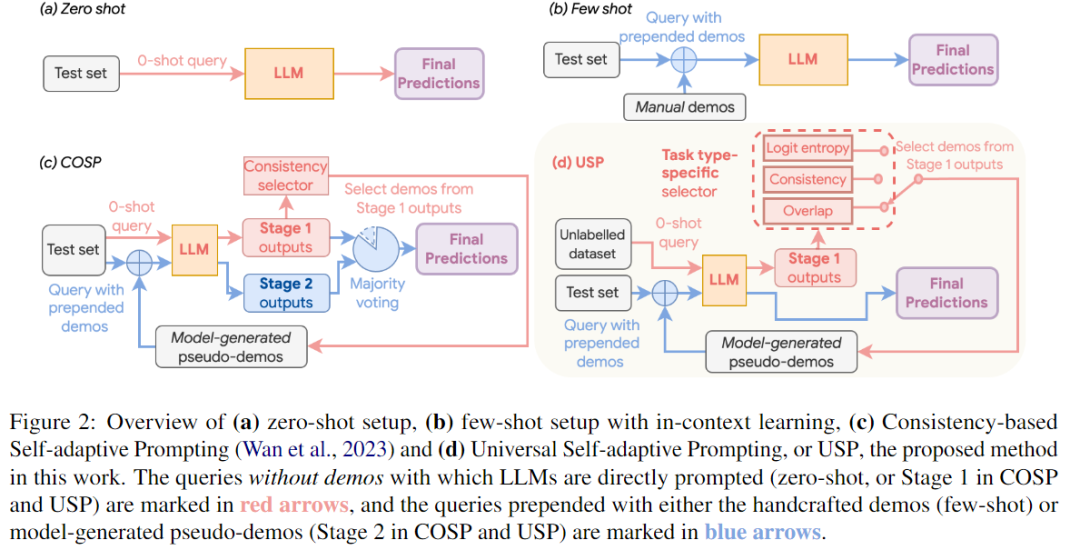
如上图所示,USP总体上与COSP方法有一些相似之处:同样采用两阶段的过程。在第一阶段,LLMs以零样本的方式进行提示,生成一组候选回答,然后从中选择一些模型生成的伪演示数据。在第二阶段,这些伪演示数据以少样本的方式添加到测试查询之前,再次提示LLMs以获得最终的预测结果。
然而,USP引入了几个关键的设计决策,使其与COSP有所区别,有效地提高了其泛化能力:
任务特定的伪演示数据选择器:在USP中,从零样本输出中选择适合的查询-回答对是至关重要的,这就是伪演示数据选择器。COSP使用基于一致性的选择器,只适用于一部分特定任务,而USP则设计了一个选择器,针对不同任务,选择不同的伪演示数据集,增强了其灵活性。
测试集和生成伪演示数据集的分离:与COSP默认使用完整的测试集T在第一阶段生成伪演示数据不同,USP需要一个通用的无标签数据集D。该数据集可以是完整的测试集T其中的一个子集,或者是一个不同的无标签集合。D的唯一目的是生成伪演示数据,即使事先不知道完整的测试集,或者只有少量无标签的查询可用。
减少对多数投票的依赖:虽然多数投票对于COSP至关重要(如图中c所示),但它计算上较为昂贵,并且在多数本身无法明确定义的情况下不适用。相比之下,USP默认在第二阶段只进行一次解码,使用贪婪解码(即temperature=0),将最大似然估计(MLE)的输出作为最终预测结果。USP仍然支持对多次解码进行多数投票,以进一步提高性能,但不再依赖这种方式来运行。
任务特定的伪演示数据选择器
选择器的目标是为了构建候选伪演示数据集P(通过将数据集查询和LLMs的零样本预测连接而成),并从中选择一些伪演示数据S来添加到测试查询中。作者使用一个函数F来对每个候选伪演示数据进行评分。首先,找到在P中使得F最大的伪演示数据作为第一个被选中的伪演示数据。对于接下来的伪演示数据,作者使用一个带有多样性促进项的F来选择,同时惩罚那些与已选中的伪演示数据过于相似的候选项。
作者设计F函数的目的是根据任务的特性,将可能的任务分为三种通用类型(如下表所示),并对每种类型设计不同的评分函数。这样做可以实现通用提示,在不同的任务上取得良好的效果。在设计F函数时,作者考虑了可能的响应数量和正确响应的数量,并使用了一些技巧来确保评分的准确性和可比性。
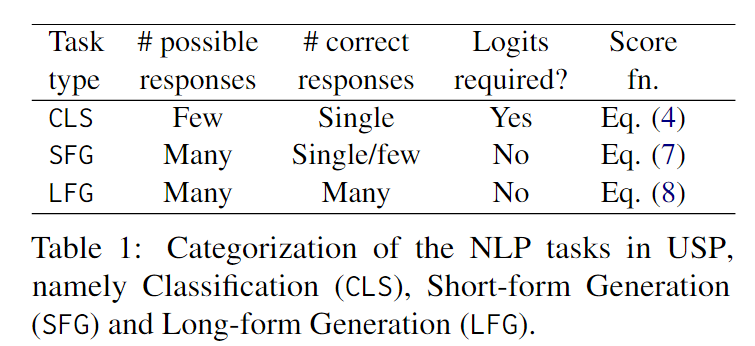
下面我们详细介绍一下这三种任务的划分标准及选择方法的差异。
针对分类(CLS)问题,LLMs需要从几个可能选项中选择一个正确答案。这种情况下,标签空间很小,模型的逻辑回归结果对于不确定性的量化很有用。我们不需要使用SC方法来估计预测的置信度。对于伪演示数据集,我们只需查询LLM一次,并使用类别的负熵作为CLS情况下评分函数F的度量指标。
Short-form generation(SFG)问题是指这样一类生成问题:通常有很多可能的回答,但只有一个到几个是正确的短回答。例如问答任务,其中可能的回答涵盖整个词汇表V。与CLS情况不同,我们假设只能访问模型的输出,而没有对数概率分布。这种情况包括了COSP中的问题(例如COSP中考虑的算术推理问题),我们可以使用归一化熵来衡量模型的置信度,不过对于非CoT提示的任务,我们跳过了生成理由的步骤,直接询问答案。
最后一类是Long-form generation(LFG)问题,通常需要生成较长的回答,并有许多合理的可能回答,典型的例子包括总结和翻译。在这种情况下,如果对同一个查询进行m次温度采样解码,即使对于置信的预测,生成的文本也不可能完全相同,这是因为生成的文本长度较长。为了衡量这种情况下的置信度,我们首先按照SFG问题的设置,对每个回答进行m次温度采样查询,得到m个预测结果。随后,我们计算所有m个响应对之间的平均ROUGE分数。注意我们也可以采用其他指标例如如pairwise BLEU或句子的余弦相似度。我们使用FLFG来对D中的查询进行置信度排序,并确定要在S中使用哪些查询。对于伪演示的响应部分,我们再次对LLM进行一次解码,使用argmax或贪婪解码,以获得所选查询上的MLE预测结果。然后将这些预测结果与查询连接起来构建S。最后,鉴于零样本文本生成完全由提示驱动,我们观察到LLM有时会生成极具自信的文本补全,而不是实际完成指定的任务,选择这些输出作为伪演示会严重降低性能。考虑到这些输出通常具有异常高的平均ROUGE得分,我们采用了一种简单有效的异常值过滤方法,即移除得分大于上四分位数加1.5倍四分位距(IQR)的查询。这是一种经典的用于定义异常值的方法。
实验设置
作者在PaLM-540B和PaLM-62B上进行了实验,并考虑了各种常见的自然语言处理任务:对于CLS任务,包括常识推理、阅读理解、填空完成、自然语言推理等;对于SFG任务,包括开放域问答、阅读理解问答和词语预测;对于LFG任务,包括摘要任务。作者没有考虑CoT推理任务,因为先前的研究已经证明了COSP方法在这些任务上的有效性。
作者将USP与四个baseline进行比较,分别是:zero-shot、AutoCoT、Random demo(按照USP的步骤进行操作,但是在选择伪演示时不使用评分函数,而是从P中随机选择K个伪演示)、5-shot(few-shot, k=5)。为了公平比较,AutoCoT、Random demo和USP都会为每个样本生成5个伪演示,从每个任务中随机选择64个未标记的测试查询。
结果分析
下面3个表分别展示了CLS、SFG和LFG任务上的实验结果。
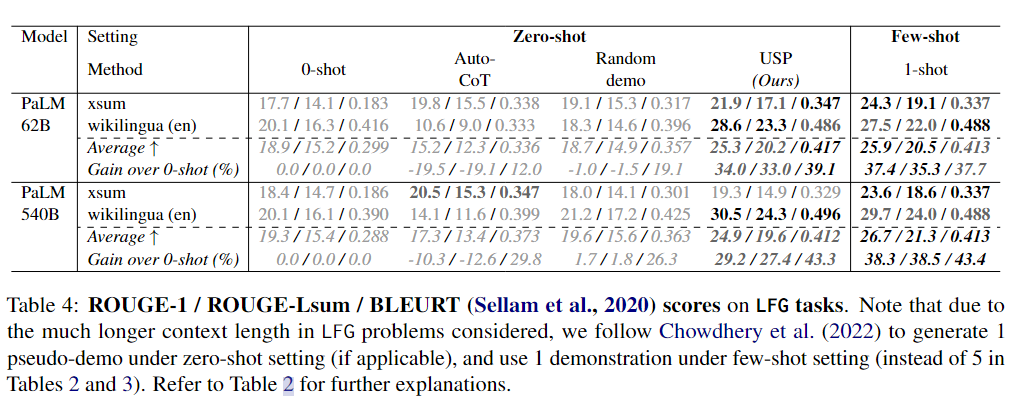
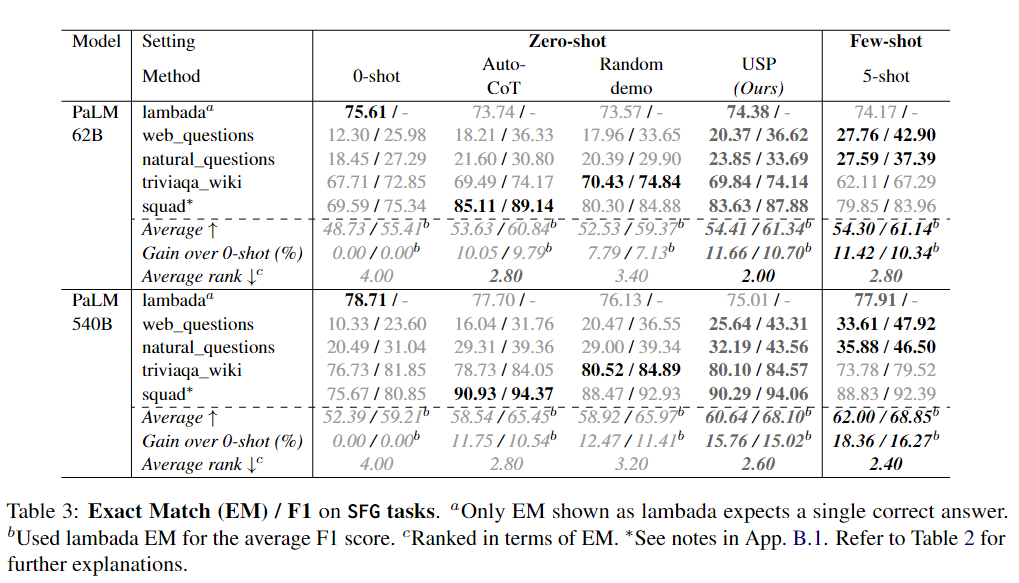
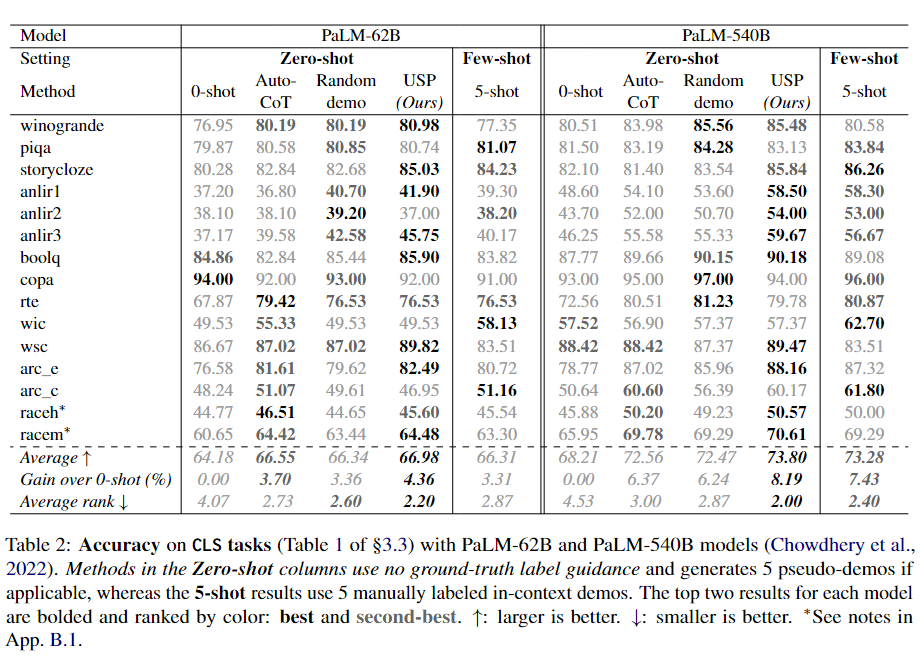
可以看到,在CLS、SFG和LFG任务中,USP显著改善了标准的zero-shot性能,优于其他zero-shot提示方法,并且在许多情况下接近甚至优于标准的few-shot提示方法,而这才仅使用了每个任务64个未标记样本。
无论是在不同的数据集还是不同的模型上,USP在SFG和LFG任务上的改进幅度比在CLS任务上要大,而在PaLM-540B上的改进幅度也比PaLM-62B更大。作者推测前一观察结果的原因是在生成任务中,LLMs更需要来自示例的指导,因为这些任务涉及到无限的动作选择,而在CLS任务中,LLM只需要从几个选项中选择一个回答。至于后一观察结果,作者认为较大的模型具有更强的能力从示例中学习,能够更好地利用更准确/更好的示例(5-shot结果在PaLM-540B中更强的事实也支持这一观点)。在这种情况下,USP生成的更准确/更高质量的伪示例导致了对基线方法的更大优势,而基线方法的伪示例质量仅取决于模型的平均表现。
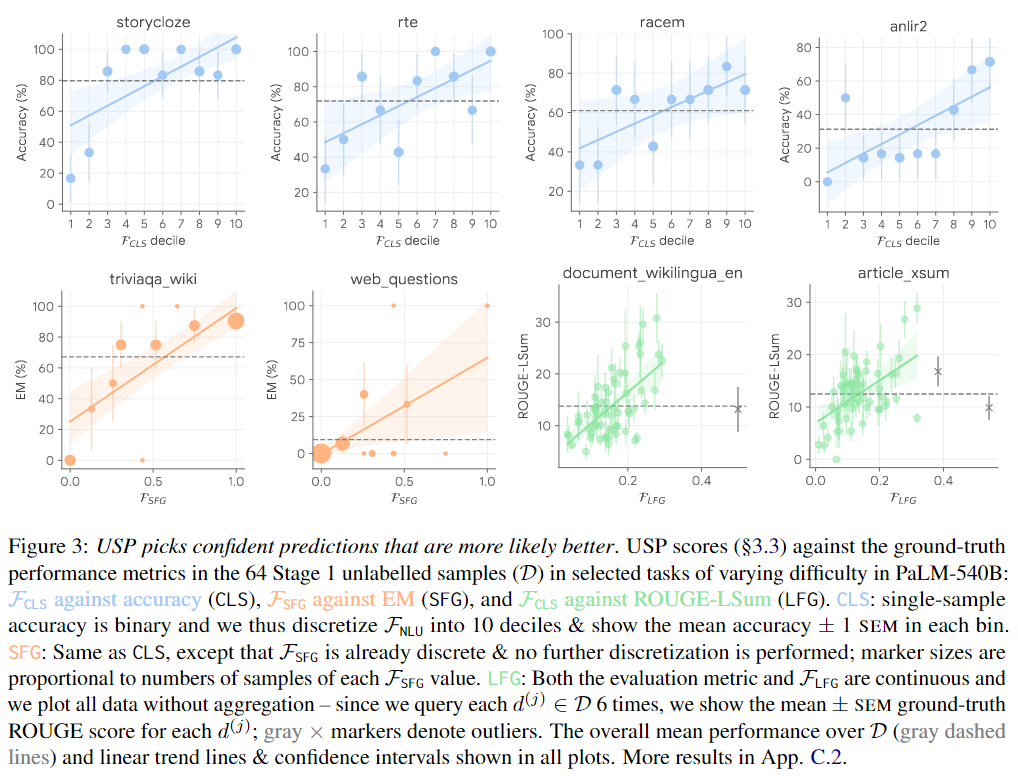
为了分析伪演示选择器如何选择高质量的伪演示,作者分析了所有任务的未标记数据集D中查询的USP得分与ground-truth性能(准确性、EM或ROUGE,取决于任务类型)之间的关系。下图展示了一些代表性结果,在各种任务类型和不同难度的任务中(如图中由灰色虚线标记的平均性能),USP得分通常与ground-truth性能呈良好的相关性。最近的研究结果表明,更大的LLMs确实通过在上下文中学习信息(而不仅仅是遵循提示格式)并从正确示例中受益,这与USP的结果一致。
总结
本研究提出了USP方法,它是一种专为零样本学习而设计的自适应prompt方法,适用于各种自然语言理解和生成任务。通过精心选择零样本模型生成的输出作为示例进行上下文学习,取得了显著的改进效果。在本研究中,作者们展示了USP在两个LLM模型上超过标准零样本提示和其他基线方法的优势。
未来的改进空间也很大。首先,目前的工作主要集中在上下文演示方面,还没有尝试优化其他提示组件。进一步的研究可以将USP与自动提示设计相结合,实现更灵活的提示方式。其次,随着LLM能力的不断提升,我们可以将USP的思想应用于更多的创新设置中,例如规划任务以及多模态问题领域的拓展。
审核编辑 :李倩
-
模糊自适应PID控制方法2012-08-18 0
-
什么是自适应算术编码?2019-10-23 0
-
基于神经网络自适应谐波电流抑制方法2011-08-22 651
-
一种超声测距的鲁棒自适应建模方法2016-03-23 709
-
基于自适应正弦滤波的零序电流互感器在线检测方法_杨浩2017-03-15 820
-
基于自适应图像分类方法2017-12-04 682
-
基于模型的自适应方法综述2017-12-19 1105
-
基于直推判别字典学习的零样本分类方法2017-12-25 639
-
分层学习的自适应动态规划2018-01-05 1060
-
模糊时序自适应预测方法2018-02-23 717
-
区块链将成为自适应学习的催化剂2019-02-12 750
-
融合零样本学习和小样本学习的弱监督学习方法综述2022-02-09 2306
-
基于深度学习的零样本SAR图像目标识别2022-12-29 661
-
形状感知零样本语义分割2023-04-28 818
-
什么是零样本学习?为什么要搞零样本学习?2023-09-22 2189
全部0条评论

快来发表一下你的评论吧 !
