

优化指南-Ampere® Altra®系列处理器的锁和内存序
处理器/DSP
描述
AMPERE ALTRA 和 AMPERE ALTRA MAX 的锁机制
让我们先来了解一些基本的问题。Arm 在 Arm v8.2-A 架构中引入了大型系统扩展(Large System Extensions, LSE),它用单个原子指令取代了锁操作的指令序列。
一个非常不错的总结。虽然旧的 Arm 版本在功能上可以很好地工作,但随着核心数量的增加和锁的争用更加频繁,预计性能会受到影响。
Ampere Altra 和 Ampere Altra Max 支持 LSE,并配备了可扩展的锁性能。
为了说明使用的指令之间的差异,让我们看看 gcc 的处理方式
__atomic_fetch_add()。在本例中,将锁值减 1:
__atomic_fetch_add(&lockptr->lockval, -1, __ATOMIC_ACQ_REL);
使用* -march =armv8.2-a*选项编译,编译器生成带有原子指令的代码:
998: f8f60280 ldaddal x22, x0, [x20]
另一方面,设置* -march =armv8-a*(不支持LSE),生成一个不同的序列:
9a4: c85ffe60 ldaxr x0, [x19] 9a8: d1000400 sub x0, x0, #0x1 9ac: c801fe60 stlxr w1, x0, [x19] 9b0: 35ffffa1 cbnz w1, 9a4
为了使序列具有原子性,需要一个单独的监视器。ldaxr 获得一个地址标记,在本例中为 [x19]。然后执行减法,然后存储回内存位置。
但是,只有当存储(store)时的标记与加载(Load)中的标记匹配时,存储才会成功。stlxr 之后的条件分支 cbnz 检查存储是否成功,这意味着 load 和 store 中的标记匹配。
如果不是,则跳回序列的开头,在本例中是地址 0x9a4。
这里值得注意的是,如果没有 LSE 指令,这个指令序列可能要执行几次才能被认为成功。使用 LSE, ldaddal 指令可以保证以一条指令完成,不需要循环。
图 1 显示了当线程数从 1 增加到 80 时,使用 LSE 和不使用 LSE 时每秒获得排他锁的性能差异。
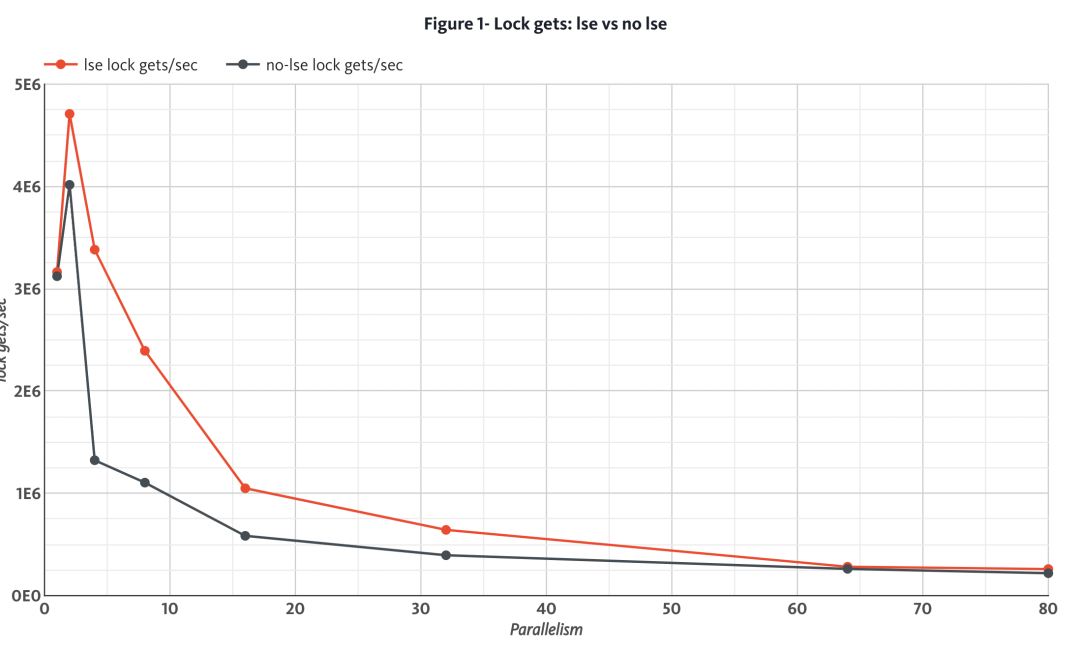
图 1
通常,Compare 和 Exchange 硬件指令用于在软件中实现锁。需要注意的是,这些指令必须是原子指令。
原子在这里是什么意思呢?这些指令首先获得包含锁的缓存行(Cache Line)的所有权,并将其加载到 CPU 的本地缓存中。然后将当前值与随指令提交的比较值进行比较。
如果相等,作为指令一部分提交的新值将替换当前值。如果不相等,则保持当前值。这方面的原子性意味着整个序列由一个线程执行,而没有其他线程访问缓存行,由硬件保证。
锁的种类
在软件中可以实现不同类型的锁,如互斥锁(mutexes)、票据锁(ticket)和自旋锁(spinlocks)。如前所述,不同的锁类型在软件中实现,硬件提供类似 cmpxchg 或 fetchadd 的指令。相同的锁类型在不同的硬件上运行,只有使用的指令不同。
如何实现锁机制
这是一个非常重要的问题。让我们把它分解成两个选项:1) 使用可用的库和 2) 使用原子指令来实现专有的锁定算法。
选项1有几个优点。库已经存在,不需要自定义实现,而且经过了充分测试,通常将会在未来的库版本中进行维护。例如 pthread_mutex_lock 和pthread_rwlock。
听起来不错,那么有什么缺点呢? 缺乏统计数据可能是一个问题。没有向应用程序返回任何信息,报告旋转(spins)或线程被调度出多少次。此外,库实现可能不太适合某些应用程序,因为库更通用。
选项 2 更复杂。它需要实现锁定函数并维护它们。但是,它可以获得一些好处,因为它是专门为应用程序设计的。锁定原语和原子指令可以通过内联汇编(inline assembly)或利用编译器的支持来实现。同样,使用内联程序集编写代码需要应用程序维护该段代码。
对于编译器,gcc提供了atomic built-in function,它允许应用程序使用低级函数,这些函数将被编译成 Arm 原子指令。这些内置函数为应用程序提供了原子指令和内存序指令的不同方法。代码也更易于移植。但是,使用*-mcpu或-march*的正确设置来编译应用程序来生成 Arm LSE 指令是很重要的。Ampere Altra 和 Ampere Altra Max 使用 Neoverse-n1 架构,其中就包括LSE。
然而,使用原子指令实现锁需要设计决策。如果锁被持有,旋转(spinning)是否合理?转几圈?线程在旋转一定次数后如果不成功,是否应该放弃?在旋转环中需要后退,还是直线旋转? 这些只是需要解决的问题中的一部分。
其他的设计决策
1
锁的数据类型和大小
通常,应用程序使用 int 或long 作为锁。用于原子操作的内置函数(Built-in functions)从内存中读取锁值。如果应用程序也直接读取锁值,锁类型应该有“volatile”前缀,例如 volatile long。使用 volatile,编译器生成从内存中读取数据的指令。否则,该值可能在寄存器中而没有更新,从而错过对锁位置的更新。
2
锁的粒度
由于竞争,粗粒度锁有可能成为性能瓶颈。另一方面,如果每个资源都有自己的锁来保护,那么将需要大量内存来存储锁。必须是一种折衷设计,以避免任何不利因素。
3
锁对齐
编译器对结构进行正确对齐。如果应用程序管理自己的内存,那么锁的位置可能与锁的大小不一致。在最坏的情况下,锁可能跨越两条缓存行。在 AArch64 上,对未对齐锁的原子操作会导致 SIGBUS (硬件向操作系统发出信号,表明 CPU 不能寻址内存地址的总线错误,在这种情况下是由于未对齐访问)。从积极的方面来看,获得 SIGBUS 需要固定对齐,而不是隐藏很少被发现的性能问题。
4
假共享
虚假分享是什么意思?即同一高速缓存行上的独立数据对性能有不良影响,锁数组就属于这一类。这些锁保护不同的关键区域。但是,对同一缓存行上锁的原子操作会影响该缓存行上的所有锁。重要的是,原子性不是针对锁本身,而是针对包含锁的整个缓存行。
5
在 cmpxchg 之前做测试
在执行 cmpxchg 指令之前读取自旋循环(spinloop)中的锁值可能对争用锁有利。Cmpxchg 需要缓存行的所有权,而test将以共享模式获取缓存行,从而避免失效。然而,这可能会增加执行的 spin 数量。
6
如果可能的话,在无锁时
使用 fetchadd 而不是 cmpxchg
释放锁需要返回线程为获取锁而执行的操作。Cmpxchg,特别是对于共享锁或读写锁,需要一个循环,并且由于锁值的变化而可能会重试操作。然而,fetchadd 不需要循环,没有比较,因此它会成功。
7
锁定持有时间
通常指临界区域内的指令数或在临界区域内花费的时间。时间是一个更好的度量标准,因为临界区域可能只有很少的指令。然而,所有的指令都可以从内存中读取。嵌套锁属于同一类别。无法获得内部锁以及 spinning 或 sleeping 会影响外部锁的保持时间。减少关键区域的保持时间总是好的,如果数据在本地缓存而不是内存中就更好了。
8
抢占
不幸的是,线程在持有锁时可能会被重新调度。如果锁处于独占模式,这意味着没有其他线程能够获得锁。在考虑性能问题时,要记住这一点。较短的保持时间将降低抢占的可能性。
内存序
如前所述,正确的内存排序指令对于正确性很重要。AArch64 遵循一种宽松的内存模型。使用 LSE, AArch64 指令强制执行特定的内存顺序。例如,cmpxchg 指令集有获取(CASA 指令)、释放(CASL 指令)以及获取和释放(CASAL 指令)的版本。硬件保证这些指令遵循其特定指令的内存模型。这取决于软件使用适当的指令。
通常,acquire 用于锁获取,Release 用于锁释放。但是,如果应用程序在无锁之后读取数据(例如,如果该锁有任何等待程序),那么空闲程序的 release 语义可能会导致问题,因为对等待程序结构的读取可能会提升到空闲程序之上,因此在空闲程序之后,寄存器中就会出现陈旧的数据。在这些情况下,最好使用 acquire 和 release 语义。同样,这取决于应用程序实现。gcc 编译器直接在内置函数中使用这些指令。
总结
Ampere 系列处理器正以其持续增加的核心数量不断挑战性能极限,并具备使用锁的多线程应用程序可扩展性的所有要素。使用 LSE,在硬件中提供原子指令以获得更好的锁性能。正如我们在本文所看到的,应用程序开发人员可以通过锁库或正确实现锁定算法来充分利用这些指令。
审核编辑:刘清
-
Ampere发布AmpereOne系列处理器,单颗处理器支持最高192个物理核心2023-06-02 637
-
业界首款!Ampere发布有80个核心的ARM处理器2020-03-04 2607
-
Ampere发布业内首款80核ARM架构64位处理器Altra 并已开始向云服务和边缘计算客户出样2020-03-04 1345
-
Ampere全新推出业界首款80核服务器处理器Ampere Altra™处理器2020-03-05 1332
-
安晟培半导体Ampere Altra处理器推出,应用于云和边缘计算数据中心中2020-03-04 3161
-
Ampere推出业内首款拥有最多内核数量的云原生处理器系列2020-06-28 1531
-
详细解说Ampere Altra性能测试与结果对比2021-03-24 7366
-
Ampere Altra处理器实现Arm架构运行虚拟机2022-04-10 3454
-
HPE正式发布搭载Ampere云原生处理器的HPE ProLiant RL300 Gen11平台2022-07-13 2214
-
Ampere Computing发布全新AmpereOne系列处理器,192个自研核2023-05-19 1282
-
Ampere全新AmpereOne系列处理器,多达192个单线程Ampere核2023-05-23 499
-
Ampere Altra系列处理器的锁和内存序2023-06-07 1480
-
全新AmpereOne系列处理器,一款192核的云原生CPU2023-06-08 954
-
针对Ampere Altra系列处理器的Memcached优化指南2023-08-08 701
-
基于Ampere Altra 系列处理器的一系列平台为 AI 高效赋能2023-09-21 890
全部0条评论

快来发表一下你的评论吧 !
