

目标检测多模型集成方法总结
描述
本文转载自AI公园。
作者:Vikas S Shetty
编译:ronghuaiyang
导读
模型集成是一种提升模型能力的常用方法,但通常也会带来推理时间的增加,在物体检测上效果如何,可以看看。
介绍
集成机器学习模型是一种常见的提升模型能力的方式,并已在多个场景中使用,因为它们结合了多个模型的决策,以提高整体性能,但当涉及到基于DNN(深度神经网络)的目标检测模型时,它并不仅仅是合并结果那么简单。
集成的需求
为了在任何模型中获得良好的结果,都需要满足某些标准(数据、超参数)。但在真实场景中,你可能会得到糟糕的训练数据,或者很难找到合适的超参数。在这些情况下,综合多个性能较差的模型可以帮助你获得所需的结果。在某种意义上,集成学习可以被认为是一种通过执行大量额外计算来弥补学习算法不足的方法。另一方面,另一种选择是在一个非集成系统上做更多的学习。对于计算、存储或通信资源的相同增加,集成系统使用两种或两种以上的方法可能会比使用单一方法增加资源的方法更有效地提高整体精度。
看起来挺好,有没有缺点呢?
更难调试或理解预测,因为预测框是根据多个模型绘制的。
推理时间根据模型和使用的模型数量而增加。
尝试不同的模型以获得合适的模型集合是一件耗时的事情。
不同的模型集成
OR方法:如果一个框是由至少一个模型生成的,就会考虑它。
AND方法:如果所有模型产生相同的框,则认为是一个框(如果IOU >0.5)。
一致性方法:如果大多数模型产生相同的框,则认为是一个框,即如果有m个模型,(m/2 +1)个模型产生相同的框,则认为这个框有效。
加权融合:这是一种替代NMS的新方法,并指出了其不足之处。
在上面的例子中,OR方法的预测得到了所有需要的对象框,但也得到了一个假阳性结果,一致性的方法漏掉了马,AND方法同时漏掉了马和狗。
验证
为了计算不同的集成方法,我们将跟踪以下参数:
True positive:预测框与gt匹配
False Positives:预测框是错误的
False Negatives:没有预测,但是存在gt。
Precision:度量你的预测有多准确。也就是说,你的预测正确的百分比[TP/ (TP + FP)]
Recall:度量gt被预测的百分比[TP/ (TP + FN)]
Average Precision:precision-recall图的曲线下面积
使用的模型
为了理解集成是如何起作用的,我们提供了用于实验的独立模型的结果。
1. YoloV3:

2. Faster R-CNN — ResNeXt 101 [X101-FPN]:

集成实验
1. OR — [YoloV3, X101-FPN]

如果你仔细观察,FPs的数量增加了,这反过来降低了精度。与此同时,TPs数量的增加反过来又增加了召回。这是使用OR方法时可以观察到的一般趋势。
2. AND — [YoloV3, X101-FPN]

与我们使用OR方法观察到的情况相反,在AND方法中,我们最终获得了较高的精度和较低的召回率,因为几乎所有的假阳性都被删除了,因为YoloV3和X101的大多数FPs是不同的。
检测框加权融合
在NMS方法中,如果框的IoU大于某个阈值,则认为框属于单个物体。因此,框的过滤过程取决于这个单一IoU阈值的选择,这影响了模型的性能。然而,设置这个阈值很棘手:如果有多个物体并排存在,那么其中一个就会被删除。NMS丢弃了冗余框,因此不能有效地从不同的模型中产生平均的局部预测。
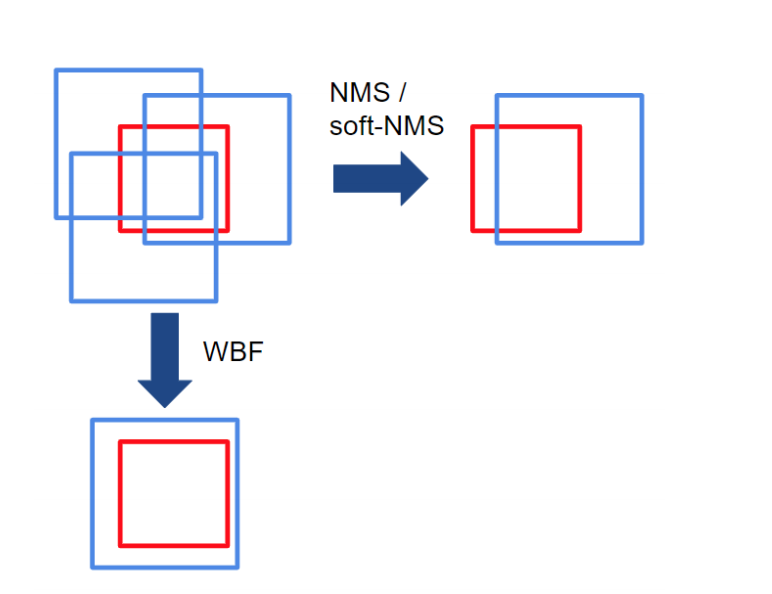
NMS和WBF之间的主要区别是,WBF利用所有的框,而不是丢弃它们。在上面的例子中,红框是ground truth,蓝框是多个模型做出的预测。请注意,NMS是如何删除冗余框的,但WBF通过考虑所有预测框创建了一个全新的框(融合框)。
3. Weighted Boxes Fusion — [Yolov3, X101-FPN]

YoloV3和X101-FPN的权重比分别为2:1。我们也试着增加有利于X101-FPN的比重(因为它的性能更好),但在性能上没有看到任何显著的差异。从我们读过的加权融合论文中,作者注意到了AP的增加,但如你所见,WBF YoloV3和X101-FPN并不比OR方法好很多。我们注意到的是,大部分的实验涉及至少3个或更多模型。
4. Weighted Boxes Fusion — [Yolov3, X101, R101, R50]

在最后的实验中,我们使用了YoloV3以及我们在Detectron2中训练的3个模型[ResNeXt101-FPN, ResNet101-FPN, ResNet50-FPN]。显然,召回率有一个跳跃(约为传统方法的0.3),但AP的跳跃并不大。另外,需要注意的是,当你向WF方法添加更多模型时,误报的数量会激增。
总结
当使用相互补充的模型时,集成是提高性能的一种很好的方法,但它也会以速度为代价来完成推理。根据需求,可以决定有多少个模型,采用哪种方法,等等。但从我们进行的实验来看,性能提升的数量似乎与一起运行这些模型所需的资源和推断时间不成比例。
审核编辑:汤梓红
-
AI模型部署边缘设备的奇妙之旅:目标检测模型2024-12-19 0
-
基于多传感器的多模型机动目标跟踪算法设计2018-12-05 0
-
目标检测模型和Objectness的基础知识2021-02-04 0
-
如何提升模型能力?2021-02-24 0
-
基于形状统计模型的多类目标自动识别方法2010-02-10 917
-
一种多尺度多视点特性视图生成方法的研究和应用_谢冰2017-03-15 661
-
基于强监督部件模型的遥感图像目标检测2017-12-18 907
-
Deep Web数据源选择和集成方法2018-02-09 880
-
目标检测的模型集成方法及实验2021-01-26 617
-
基于图集成模型的自动摘要生产方法2021-03-22 672
-
一种脱离预训练的多尺度目标检测网络模型2021-04-02 737
-
解析在目标检测中怎么解决小目标的问题?2021-04-26 6259
-
多尺度卷积特征融合的SSD目标检测2021-06-11 709
-
智能制造系统集成方法有哪些2023-04-25 3178
-
电流检测放大器威廉希尔官方网站 设计集成方案2023-11-19 841
全部0条评论

快来发表一下你的评论吧 !
