

基于FPGA的DDR3多端口读写存储管理系统设计
描述

点击上方蓝字关注我们
机载视频图形显示系统主要实现2D图形的绘制,构成各种飞行参数画面,同时叠加实时的外景视频。由于FPGA具有强大逻辑资源、丰富IP核等优点,基于FPGA的嵌入式系统架构是机载视频图形显示系统理想的架构选择。视频处理和图形生成需要存储海量数据,FPGA内部的存储资源无法满足存储需求,因此需要配置外部存储器。
与DDR2 SDRAM相比,DDR3 SDRAM带宽更好高、传输速率更快且更省电,能够满足吞吐量大、功耗低的需求,因此选择DDR3 SDRAM作为机载视频图形显示系统的外部存储器。
本文以Kintex-7系列XC7K410T FPGA芯片和两片MT41J128M16 DDR3 SDRAM芯片为硬件平台,设计并实现了基于FPGA的视频图形显示系统的DDR3多端口存储管理。

1 总体架构设计

机载视频图形显示系统中,为了实现多端口对DDR3的读写访问,设计的DDR3存储管理系统如图 1所示。主要包括DDR3存储器控制模块、DDR3用户接口仲裁控制模块和帧地址控制模块。
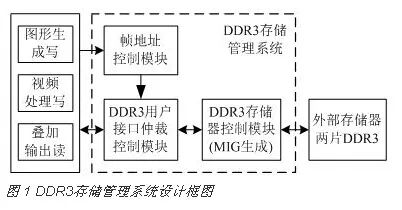
DDR3存储器控制模块采用MIG(Memory Interface Generator)方案,通过用户接口建立FPGA内部控制逻辑到DDR3的连接,用户不需要管理DDR3初始化、寄存器配置等复杂的控制逻辑,只需要控制用户接口的读写操作。
DDR3用户接口仲裁控制模块将每一个数据读写请求设置成中断,借鉴中断处理思想来进行仲裁控制,从而解决数据存储的冲突。
帧地址控制模块控制帧地址的切换。为了提高并行处理的速度,简化数据读写冲突,将图形数据和视频数据分别存储在不同的DDR3中。
2 DDR3存储器控制模块设计
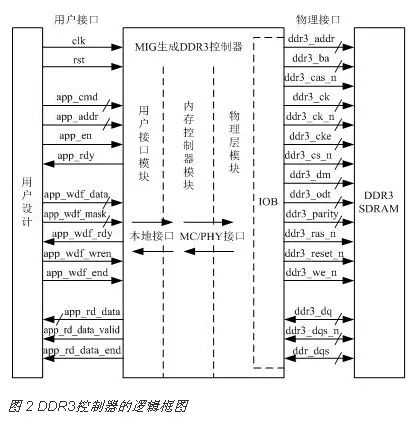
MIG生成的DDR3控制器的逻辑框图如图 2所示,只需要通过用户接口信号就能完成DDR3读写操作,大大简化了DDR3的设计复杂度。
2.1 DDR3控制模块用户接口写操作设计
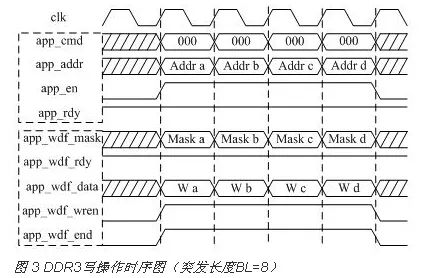
DDR3存储器控制模块用户接口写操作有两套系统,一套是地址系统,一套是数据系统。用户接口写操作信号说明如表 1所示。
地址系统的内容是app_addr和app_cmd,两者对齐绑定,app_cmd为000时为写命令,当app_rdy(DDR3控制)和app_en(用户控制)同时拉高时,将app_addr和app_cmd写到相应FIFO中。数据系统的内容是app_wdf_data,它在app_wdf_rdy(DDR3控制)和app_wdf_wren(用户控制)同时拉高时,将写数据存到写FIFO。
为了简化设计,本文设计的用户接口写操作时序如图 3所示,使两套系统在时序上完全对齐。
2.2 DDR3控制模块用户接口读操作设计
用户接口读操作也分为地址系统和数据系统。用户接口读操作信号说明如表 2所示。
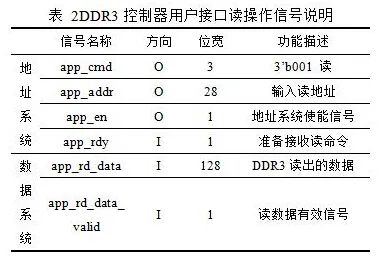
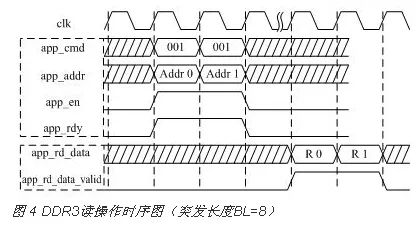
地址系统与写操作相同,在时钟上升沿且app_rdy为高电平时,用户端口同时发出读命令(app_cmd=001)和读地址,并将app_en拉高,将读命令和地址写到FIFO中。对于数据系统,当app_rd_data_valid有效,则读数据有效,读回的数据顺序与地址/控制总线请求命令的顺序相同。
读操作地址系统和数据系统一般是不对齐的,因为地址系统发送到DDR3后,DDR3需要一定的反应时间,读操作时序如图 4所示。
3 DDR3用户接口仲裁控制模块设计
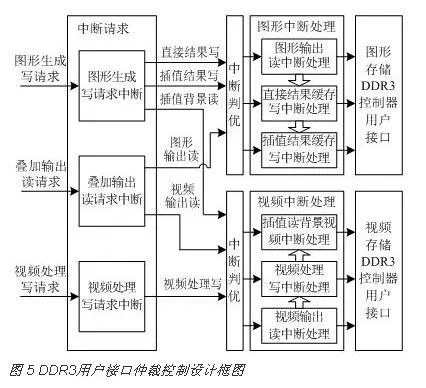
每片DDR3只有一组控制、地址和数据总线,因此同一时刻只能有一个设备在访问。常见的总线切换方式有两种:一种是轮询机制,软件实现简单,但实时性不高;一种是仲裁机制,设备发送中断请求,从而进行总线切换。由于视频图形显示系统对实时性要求高,因此选择仲裁机制。
DDR3用户接口仲裁控制框图如图 5所示。为了提高并行速度,将图形和视频分别进行中断处理。将设备中断请求解析成多个子请求,进行优先级判断,每个子请求对应一个中断处理逻辑。
3.1 视频处理写请求中断处理器设计
由于视频处理写请求不涉及到图形中断处理,所以对应一个子请求:视频处理写子请求。
视频处理模块将采集到的视频经过缩放、旋转等操作后存储在缓存区中,当缓存区满时发送视频处理模块写请求。视频处理写中断处理主要是从视频处理模块的缓存区中将地址和数据取出,写入到视频存储DDR3中。
视频处理写请求中断处理流程图如图 6所示。当视频处理模块写请求信号有效时,生成子中断请求信号,若总线空闲则响应该中断。当命令接收就绪(app_rdy=1)且数据接收就绪(app_wdf_rdy=1)时,从视频处理缓存区中读取地址和数据,同时发送写命令、写地址和写数据。若缓存区为空,说明全部写完,视频处理写中断结束。
3.2 叠加输出读请求中断处理器设计
叠加输出模块需要从DDR3中将待输出的图形数据和视频数据存储到行缓存中,因此分为两个子请求:视频输出读请求和图形输出读请求。由于两者分别在图形中断处理和视频中断处理中完成,因此可以同时进行。
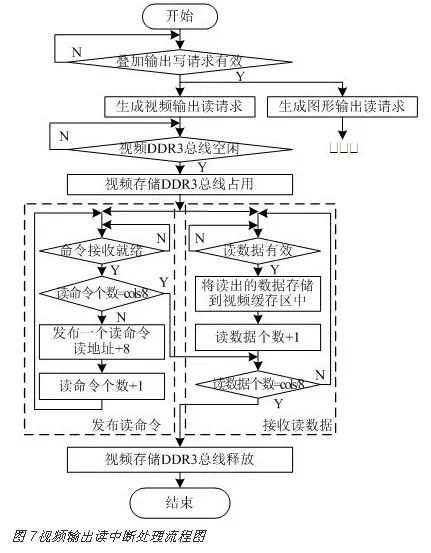
视频输出读中断处理主要从视频存储DDR3中读取1行视频数据写入到叠加输出模块的视频缓存区中,流程图如图 7所示。本系统中突发长度为BL=8,即每个用户时钟周期对应接收同一行地址中相邻的8个存储单元的连续数据。输出视频分辨率为cols×rows,则地址系统需要发送cols/8个突发读命令。数据系统接收读数据时,若读数据有效(app_rd_data_valid=1),则将读到的数据存储到叠加输出模块的视频缓存区中,同时读数据个数加1。当读数据个数为cols/8时,所有读命令对应的读数据全部接收,视频输出读中断处理结束。
图形输出读中断处理包含两个步骤:从图形存储DDR3中读取1行图形数据写到叠加输出模块的图形缓存区中;将刚刚搬移数据到图形缓存区的DDR3存储空间清零。前者与视频输出读中断的处理过程类似。
图形数据写入DDR3时只写入有图形的位置,而不是全屏扫描,如果不进行清屏操作会导致下一帧图形画面上残留上一帧的图形数据。清屏操作指图形输出后将DDR3中对应地址的存储空间全部写入数值0,从而将当前图形数据清除。
3.3 图形生成写请求中断处理器设计
图形生成是接收CPU的图形命令并进行光栅化,将结果先存储在直接结果缓存区和插值结果缓存区中,从而存入到DDR3中。当一帧图形全部绘制完成后发送图形生成模块写请求。图形生成写请求分为三个子请求:直接结果写中断请求、插值背景读中断请求、插值结果写中断请求。
直接结果缓存区存放直接输出的与背景颜色无关的像素值数据;插值结果缓存区存放需要读回对应位置的背景视频进行插值修正的像素点的数据。插值结果写到DDR3时,首先从视频存储DDR3中读出需要修正的像素点对应位置的视频像素值作为背景,然后用流水线处理实现插值修正,将修正结果写到图形存储DDR3中。
为了提高读写速度,图形中断处理器中先进行直接结果写中断处理;同时视频中断处理器中进行插值背景视频读中断处理。同时完成后再进行插值结果写中断处理。流程与图 6和图 7相似。
4 帧地址控制模块设计
帧地址控制模块主要是将DDR3空间进行划分,同时控制帧地址的切换。为了简化设计,将存储器划分为若干块,每块存储一帧数据,在用户仲裁控制模块读写缓存区时只生成帧内地址,帧地址的切换由帧读写控制模块实现,帧内地址结合帧地址组合成对应DDR3的内部地址值。DDR3的帧地址划分如图 8所示。
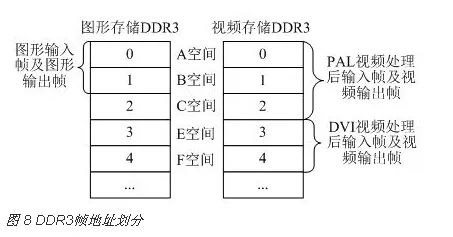
图形的读写和DVI视频的读写不涉及帧速率的转换,因此图形存储DDR3中的第0~1帧和视频存储DDR3中的第3~4帧地址控制方式相同,都是其中一帧用于将生成数据写入到DDR3中,另一帧用于读出数据叠加输出,两帧交替使用,通过乒乓操作来实现图形数据的存储与读取。
视频存储DDR3中,第0~2帧(又称A空间、B空间和C空间)用于PAL视频处理后输入帧及视频输出帧。由于PAL视频帧速率为25Hz,而终输出DVI的帧速率为60Hz,因此需要实现帧速率转换。常见的帧速率转换算法[8]包括:帧复制法、帧平均法、运动补偿法等,由于机载系统对实时性要求比较高,因此选用帧复制法。
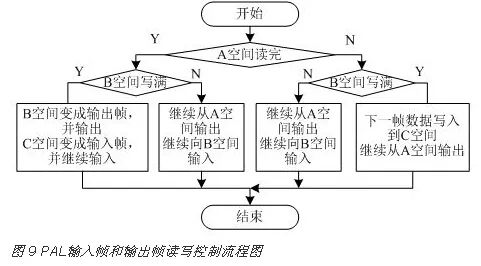
设置三个帧存储空间,其中一帧用于读出,一帧用于写入,还有一帧空闲,分别称作输入帧、输出帧和空闲帧。用三者的切换来实现帧速率的转换,确保输出帧相对于当前输入帧的延迟,即当前输出帧输出的是写满的帧。当写入的帧存储空间已经写满,而读存储空间还没读完,将下一帧的图像数据写到当前空闲的帧存储空间。图 9为PAL输入帧和输出帧读写控制流程图。以A空间为输出帧,B空间为输入帧,C空间为空闲帧为例。若A空间读完,B空间写满,则将B空间变成输出帧并输出,将C空间变成输入帧并继续输入;若A空间还没有读完,B空间已经写满,则将下一帧数据写入到C空间,并继续从A空间输出。
5 验证结果与分析
图形生成写中断处理仿真图如图 10所示。由于图形生成数据不是从左往右连续进行的,因此每次突发写操作发送的128位数据(BL=8),有效的数据只有低16位,高112位直接用掩码屏蔽(app_wdf_mask=16’hfffc)。当一帧图形全部绘制完成后发送图形生成模块写请求(graphics_done=1)。此时图形中断处理器执行直接结果写中断(graphics_wr_interrupt=1),视频中断处理器执行插值背景读中断(graphics_wr_interrupt_rd_bk=1)。当两者同时完成(rd_bk_video_finish=1)时,图形中断处理器执行插值结果写请求中断。其中,c0_app_XXX表示图形存储DDR3的用户接口,写图形数据时,用户接口地址系统和数据系统是对齐的;c1_app_XXX表示视频存储DDR3的用户接口,读视频背景时,数据系统比地址系统稍有延迟。

用本文设计的DDR3存储管理系统对文献[9]中图6.1进行中断处理。视频分辨率为1600×1200;绘制字符等直接结果点共812个像素(矩形填充忽略不算);绘制斜线等插值结果点共有4762个像素。用本文算法测试各中断处理时间如表 3所示。
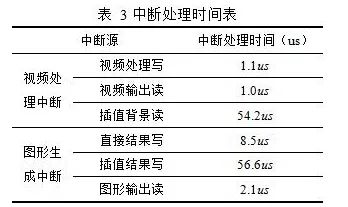
视频中断处理器中,视频处理写中断将一行视频处理数据顺序写入到DDR3中耗时1.1us,则将一帧视频处理数据写入DDR3中耗时1.32ms;视频输出读中断从DDR3读出1行视频数据耗时1us,则将一帧视频读出需要1.2ms;插值背景读耗时54.2us。视频处理中断共耗时2.5742ms。图形处理中断中,图形输出读中断读出1行图形数据,并将其内存空间清零,共需要2.1us,即将一帧图形读出需要2.52ms,则图形处理中断共耗时2.5851ms。
与文献[9]结果相比,本文设计的系统对图形生成读写中断速度有了明显提高。因为文献[9]中断类型较多,且图形生成中断的优先级,在实现的过程中会多次被打断,导致图形生成执行时间较长;而本文算法中,插值背景读操作与直接结果写操作同时在视频中断处理和图形中断处理中进行,利用并行操作减少时间,并大大降低了复杂度。
结论
本文设计并实现了基于FPGA的DDR3多端口存储管理,主要包括DDR3存储器控制模块、DDR3用户接口仲裁控制模块和帧地址控制模块。DDR3存储器控制模块采用Xilinx公司的MIG方案,简化DDR3的逻辑控制;DDR3用户接口仲裁控制模块将图形和视频分别进行中断处理,提高了并行速度,同时简化仲裁控制;帧地址控制模块将DDR3空间进行划分,同时控制帧地址的切换。
经过分析,本文将图形和视频中断分开处理,简化多端口读写DDR3的复杂度,提高并行处理速度。



欢迎加入至芯科技FPGA微信学习交流群,这里有一群优秀的FPGA工程师、学生、老师、这里FPGA技术交流学习氛围浓厚、相互分享、相互帮助、叫上小伙伴一起加入吧!
点个在看你最好看
原文标题:基于FPGA的DDR3多端口读写存储管理系统设计
文章出处:【微信公众号:FPGA设计william hill官网 】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- FPGA
-
基于FPGA的DDR3多端口读写存储管理设计2024-06-26 0
-
基于FPGA的DDR3六通道读写防冲突设计2018-08-02 0
-
基于FPGA的视频图形显示系统的DDR3多端口存储管理设计2019-06-24 0
-
如何用中档FPGA实现高速DDR3存储器控制器?2019-08-09 0
-
关于FPGA外部的DDR3 DRAM怎么回事2020-05-20 0
-
基于FPGA的DDR3多端口读写存储管理系统设计2015-04-07 13072
-
ddr3的读写分离方法有哪些?2017-11-06 8856
-
基于FPGA的DDR3多端口读写存储管理的设计与实现2017-11-18 7134
-
Stratix III FPGA的特点及如何实现和高速DDR3存储器的接口2018-06-22 3777
-
关于期货行情数据加速处理中基于FPGA的DDR3六通道读写防冲突设计详解2018-08-01 3423
-
【紫光同创国产FPGA教程】【第十章】DDR3读写测试实验2021-02-05 9465
-
基于AXI总线的DDR3读写测试2023-09-01 4509
-
基于FPGA的DDR3读写测试2023-09-01 1655
-
阐述DDR3读写分离的方法2023-10-18 1070
全部0条评论

快来发表一下你的评论吧 !
