
资料下载


使用Tensil和PYNQ在PYNQ Z1 FPGA板上运行机器学习
王芳
分享资料个
描述
介绍
本教程将使用PYNQ Z1开发板和Tensil 的开源推理加速器来展示如何在 FPGA 上运行机器学习 (ML) 模型。我们将使用在 CIFAR 数据集上训练的 ResNet-20。这些步骤应该适用于任何受支持的 ML 模型——目前支持所有常见的最先进的卷积神经网络。用你的模型试试吧!
我们将提供易于理解的详细端到端报道。此外,我们还提供了深入的解释,以便更好地了解其背后的技术,包括 Tensil 和Xilinx Vivado工具链和PYNQ 框架。
如果您遇到问题或发现错误,您可以在我们的Discord上提问或发送电子邮件至support@tensil.ai。

概述
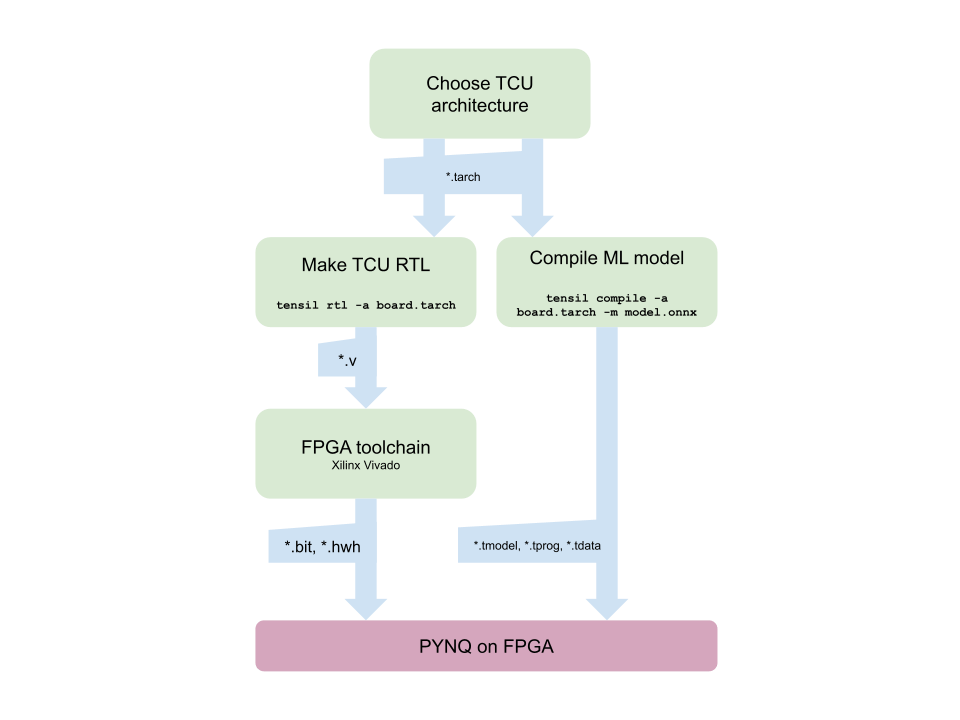
在开始之前,让我们看一下 Tensil 工具链流程,以鸟瞰我们想要完成的任务。我们将按照以下步骤操作:
- 获取张力
- 选择架构
- 生成 TCU 加速器设计(RTL 代码)
- 为 PYNQ Z1 合成
- 为 TCU 编译 ML 模型
- 使用 PYNQ 执行
1.获取张力
首先,我们需要获取 Tensil 工具链。最简单的方法是从 Docker Hub 中拉出 Tensil docker 容器。以下命令将拉取映像,然后运行容器。
docker pull tensilai/tensil
docker run -v $(pwd):/work -w /work -it tensilai/tensil bash
2.选择架构
Tensil 的优势在于可定制性,使其适用于非常广泛的应用。Tensil 架构定义文件 (.tarch) 指定要实现的架构的参数。这些参数使 Tensil 足够灵活,可以用于小型嵌入式 FPGA 以及大型数据中心 FPGA。我们的示例将选择在 PYNQ Z1 板核心的 XC7Z020 FPGA 部件上提供最高资源利用率的参数。容器映像方便地包含 PYNQ Z1 开发板的架构文件,位于/demo/arch/pynqz1.tarch. 让我们来看看里面有什么。
{
"data_type": "FP16BP8",
"array_size": 8,
"dram0_depth": 1048576,
"dram1_depth": 1048576,
"local_depth": 8192,
"accumulator_depth": 2048,
"simd_registers_depth": 1,
"stride0_depth": 8,
"stride1_depth": 8
}
该文件包含一个带有多个参数的 JSON 对象。第一个data_type定义了整个张量计算单元 (TCU) 中使用的数据类型,包括脉动数组、SIMD ALU、累加器和本地内存。我们将使用 16 位定点和 8 位基点 ( FP16BP8),这在大多数情况下允许对 32 位浮点模型进行简单舍入,而无需量化。接下来,array_size定义一个 8x8 的脉动阵列大小,这会产生 64 个并行乘法累加 (MAC) 单元。选择此数字是为了平衡 XC7Z020 上可用的 DSP 单元的利用率,以防您需要将一些 DSP 并行用于另一个应用程序,但您可以增加它以获得更高的 TCU 性能。
使用dram0_depth和dram1_depth,我们定义主机端 DRAM0 和 DRAM1 内存缓冲区的大小。这些缓冲区为 TCU 提供模型的权重和输入,并存储中间结果和输出。请注意,这些内存大小是向量的数量,这意味着数组大小 (8) 乘以数据类型大小(16 位),每个向量总共 128 位。
接下来,我们定义将在 FPGA 架构本身上实现的内存local的大小。accumulator累加器和本地存储器之间的区别在于,累加器可以执行写累加操作,其中输入被添加到已经存储的数据中,而不是简单地覆盖它。再次选择累加器加上本地内存的总大小来平衡 XC7Z020 上 BRAM 资源的利用率,以防其他地方需要资源。
使用simd_registers_depth,我们指定每个 SIMD ALU 中包含的寄存器数量,它可以对用于 ML 操作(如 ReLU 激活)的存储向量执行 SIMD 操作。很少需要增加这个数字,以帮助计算特殊的激活函数。最后,stride0_depth指定stride1_depth用于启用“跨步”内存读取和写入的位数。您不太可能需要更改此参数。
3.生成TCU加速器设计(RTL代码)
现在我们已经选择了我们的架构,是时候运行 Tensil RTL 生成器了。RTL 代表“寄存器传输级别”——它是一种代码类型,用于指定数字逻辑内容,如线路、寄存器和低级逻辑。Xilinx Vivado 或yosys等特殊工具可以为 FPGA 甚至 ASIC 合成 RTL。
要使用我们选择的架构生成设计,请在 Tensil 工具链 docker 容器中运行以下命令:
tensil rtl -a /demo/arch/pynqz1.tarch -s true
ARTIFACTS该命令将生成最后打印出来的表格中列出的几个 Verilog 文件。它还RTL SUMMARY使用生成的 RTL 的一些基本参数打印表格。
----------------------------------------------------------------------
RTL SUMMARY
----------------------------------------------------------------------
Data type: FP16BP8
Array size: 8
Consts memory size (vectors/scalars/bits): 1,048,576 8,388,608 20
Vars memory size (vectors/scalars/bits): 1,048,576 8,388,608 20
Local memory size (vectors/scalars/bits): 8,192 65,536 13
Accumulator memory size (vectors/scalars/bits): 2,048 16,384 11
Stride #0 size (bits): 3
Stride #1 size (bits): 3
Operand #0 size (bits): 16
Operand #1 size (bits): 24
Operand #2 size (bits): 16
Instruction size (bytes): 8
----------------------------------------------------------------------
4. 为 PYNQ Z1 合成
现在是启动 Xilinx Vivado 的时候了。我将使用版本 2021.2,您可以在Xilinx 网站上免费下载(用于原型制作) 。
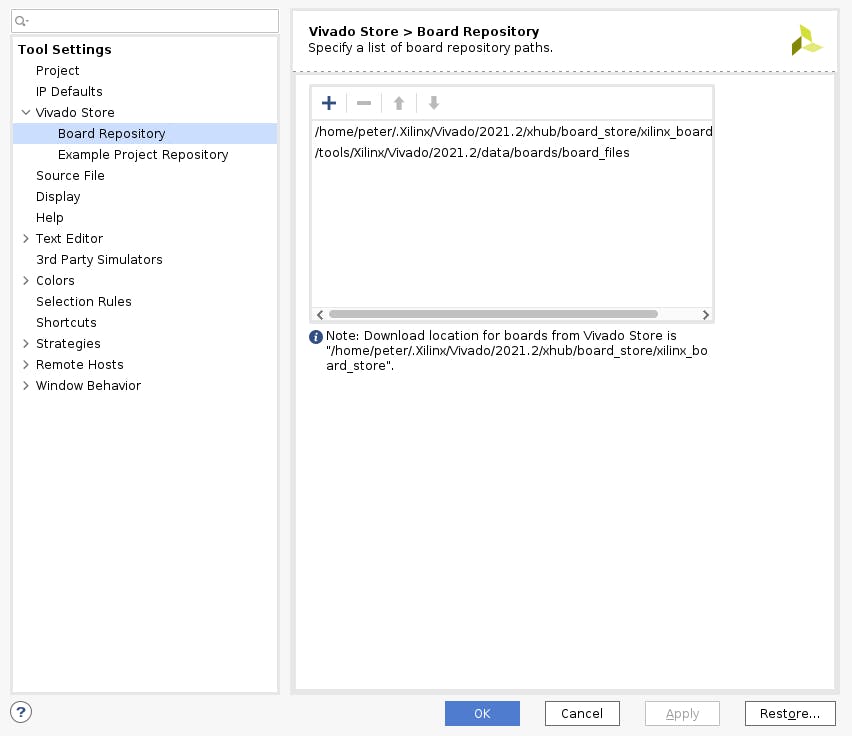
在创建新的 Vivado 项目之前,您需要从此处下载 PYNQ Z1 威廉希尔官方网站
板定义文件。打开包装并将它们放入/tools/Xilinx/Vivado/2021.2/data/boards/board_files/. (请注意,此路径包括 Vivado 版本。)解压后,您需要在工具 -> 设置 -> 威廉希尔官方网站
板存储库中添加威廉希尔官方网站
板文件路径。
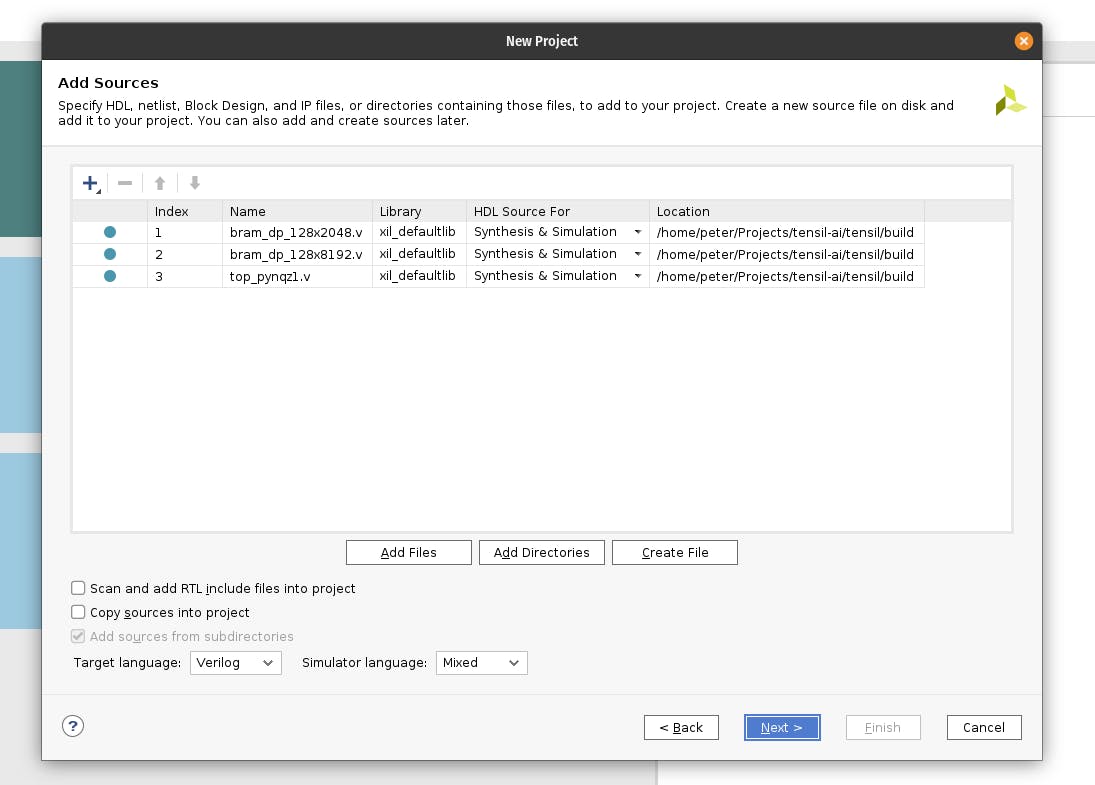
首先,创建一个名为的新 RTL 项目tensil-pynqz1并添加由 Tensil RTL 工具生成的 Verilog 文件。
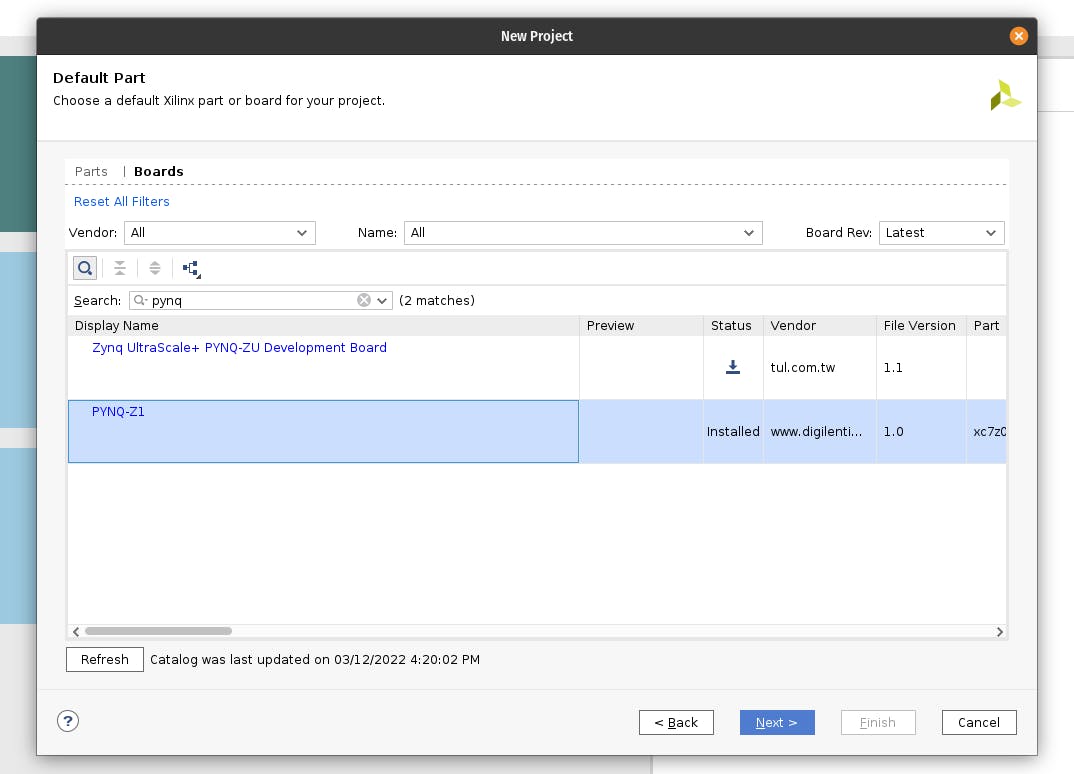
选择板并搜索 PYNQ。选择文件版本为 1.0 的 PYNQ-Z1。
在 IP INTEGRATOR 下,单击创建模块设计。
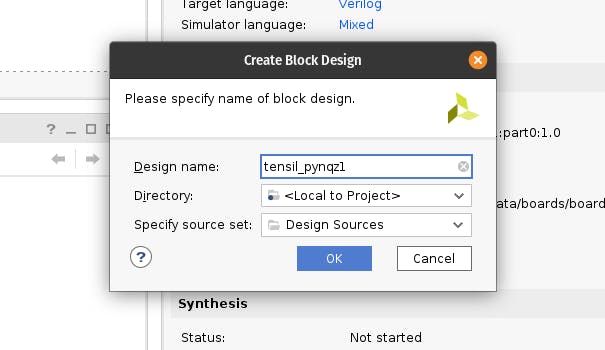
从 Sources 选项卡拖到模块设计图上。top_pynqz1您应该会看到 Tensil RTL 块及其接口。

接下来,单击框图工具栏(左上角)中的加号按钮并选择“ZYNQ7 处理系统”(您可能需要使用搜索框)。+对“处理器系统重置”执行相同操作。Zynq 模块代表赛灵思平台的“硬”部分,包括 ARM 处理器、DDR 接口等等。Processor System Reset 是一个实用工具箱,可为设计提供正确同步的复位信号。
单击“运行块自动化”和“运行连接自动化”。检查“所有自动化”。
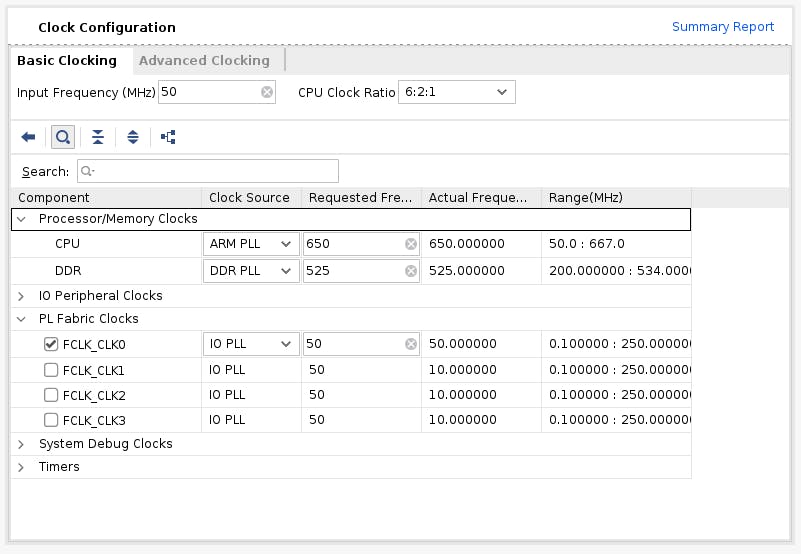
双击 ZYNQ7 处理系统。首先,进入时钟配置并确保 PL Fabric Clocks 已检查 FCLK_CLK0 并将其设置为 50MHz。
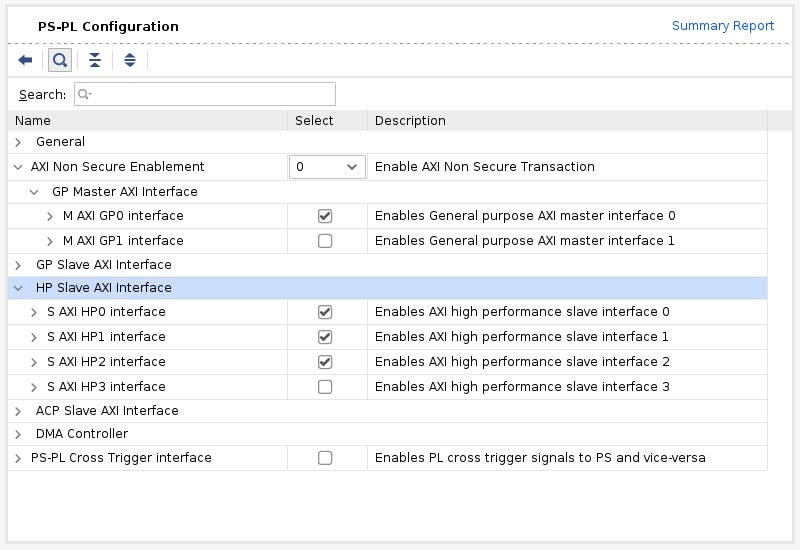
然后,进入 PS-PL 配置。检查S AXI HP0 FPD、S AXI HP1 FPD和S AXI HP2 FPD。这些更改将配置我们设计所需的处理系统 (PS) 和可编程逻辑 (PL) 之间的所有必要接口。
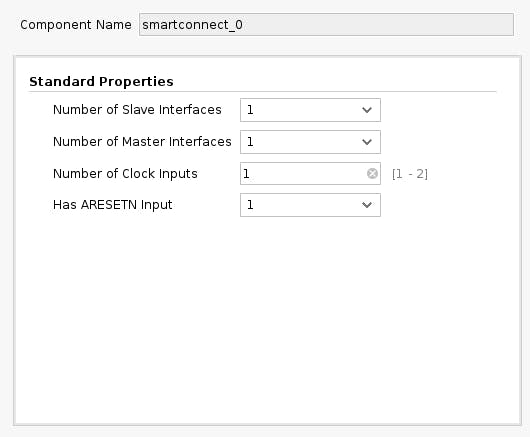
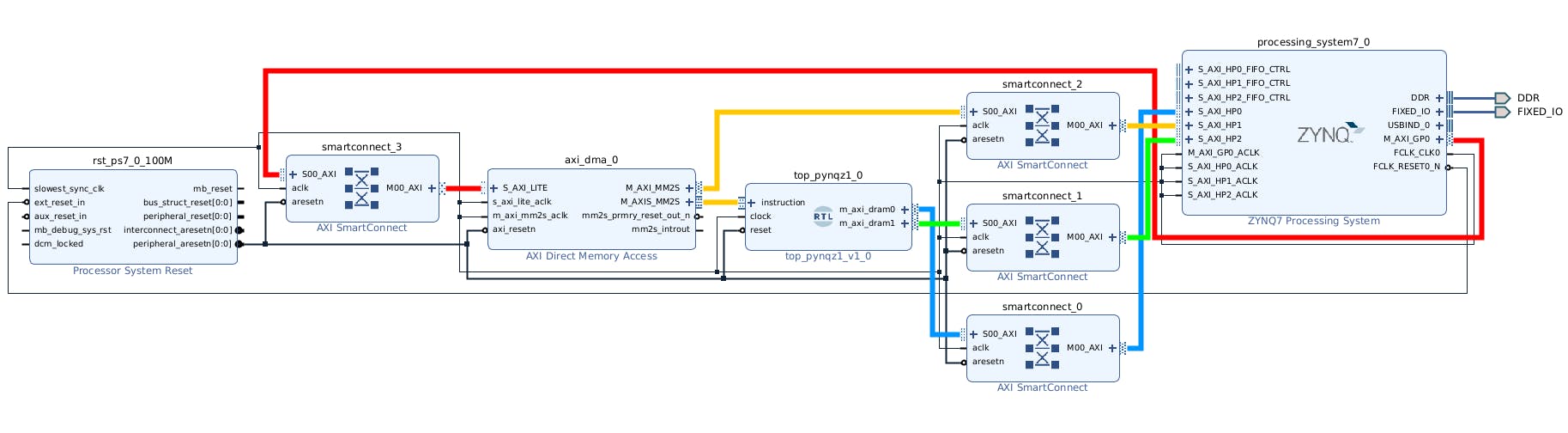
再次单击 Block Diagram 工具栏中的加号+按钮并选择“AXI SmartConnect”。我们需要 4 个 SmartConnect 实例。前 3 个实例 ( smartconnect_0to smartconnect_2) 是在 PS 上将 TCU 的 AXI 版本 4 接口和指令 DMA 块转换为 AXI 版本 3 所必需的。将smartconnect_3DMA 控制寄存器暴露给 Zynq CPU 是必要的,这将使软件能够控制 DMA 事务。双击每一个并将“从属和主接口数”设置为 1。
现在,将Tensil 块上的和对应地连接m_axi_dram0到on 上。然后将 SmartConnect端口相应地连接到Zynq 模块和Zynq 模块上。TCU 有两个 DRAM 组,通过使用具有专用连接到内存的 PS 端口来实现它们的并行操作。m_axi_dram1 portsS00_AXIsmartconnect_0smartconnect_1M00_AXIS_AXI_HP0S_AXI_HP2
接下来,单击 Block Diagram 工具栏中的加号+按钮并选择“AXI Direct Memory Access”(DMA)。DMA 块用于组织 Tensil 程序到 TCU 的馈送,而不会使 PS ARM 处理器保持忙碌。
双击它。禁用“Scatter Gather Engine”和“Write Channel”。将“缓冲区长度寄存器的宽度”更改为 26 位。选择“Memory Map Data Width”和“Stream Data Width”为64位。将“最大突发大小”更改为 256。
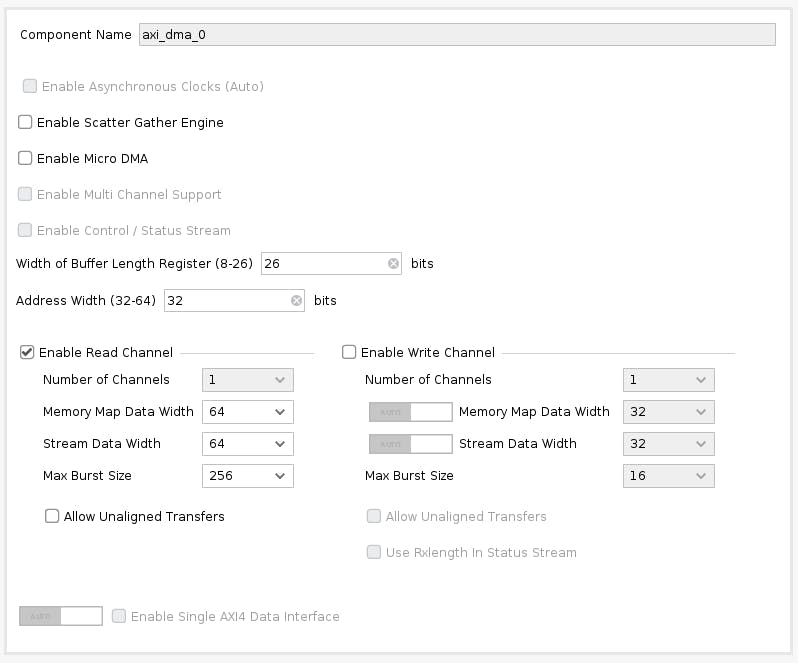
instruction将Tensiltop模块上的端口连接到M_AXIS_MM2SAXI DMA 模块上的端口。然后,将M_AXI_MM2SAXI DMA 模块连接到S00_AXIon smartconnect_2,最后,将smartconnect_2M00_AXI端口连接到S_AXI_HP1Zynq。
连接M00_AXI到AXI DMA 块上smartconnect_3。将AXI SmartConnectS_AXI_LITE连接到Zynq 模块。S00_AXIM_AXI_GP0
最后,单击“运行连接自动化”并选中“所有自动化”。通过这样做,我们连接了所有的时钟和复位。单击 Block Diagram 工具栏中的“Regenerate Layout”按钮,使图表看起来更漂亮。
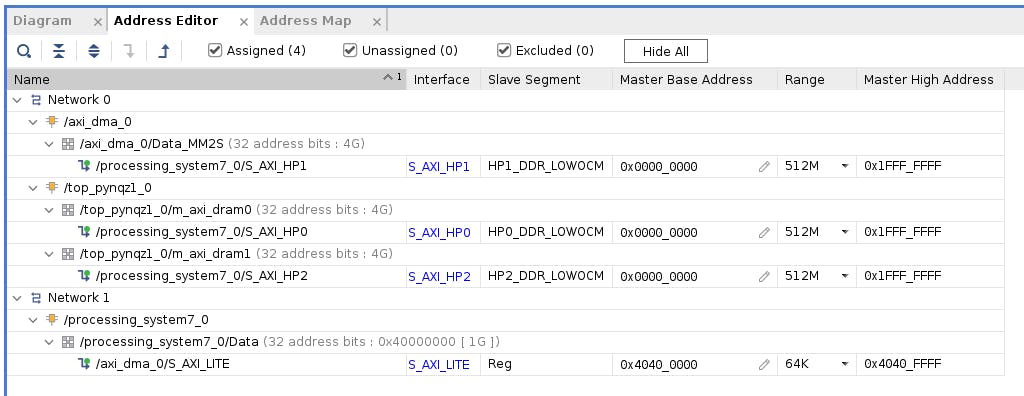
接下来,切换到“地址编辑器”选项卡。单击工具栏中的“全部分配”按钮。通过这样做,我们将地址空间分配给各种 AXI 接口。例如,指令 DMA ( axi_dma_0) 和 Tensil ( m_axi_dram0and m_axi_dram1) 可以访问 PYNQ Z1 板上的整个地址空间。PS 可以访问指令 DMA 的控制寄存器。
返回“框图”选项卡,单击“验证设计”(或 F6)按钮。您应该会看到通知您验证成功的消息!您现在可以通过单击x右上角的来关闭 Block Design。
最后一步是为我们的设计创建 HDL 包装器,它将把所有东西联系在一起并支持综合和实现。右键单击tensil_pynqz1Sources 选项卡中的项目并选择“Create HDL Wrapper”。保持选中“让 Vivado 管理包装器和自动更新”。等待 Sources 树完全更新并右键单击tensil_pynqz1_wrapper. 选择设置为顶部。
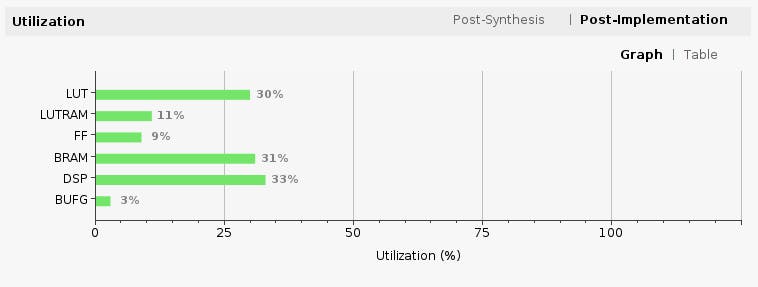
现在是时候让 Vivado 执行综合和实现并写入生成的比特流了。在 Flow Navigator 侧边栏中,单击“Generate Bitstream”并点击 OK。Vivado 将开始合成我们的 Tensil 设计——这可能需要大约 15 分钟。完成后,您可以在项目摘要中观察一些重要的统计数据。首先,查看利用率,它显示了我们的设计正在使用的每个 FPGA 资源的百分比。请注意我们如何将 BRAM 和 DSP 利用率保持在相当低的水平。
第二个是时序,它告诉我们信号在我们的可编程逻辑 (PL) 中传播需要多长时间。“Worst Negative Slack”是一个正数是个好消息——我们的设计在指定时钟速度下满足所有网络的传播约束!

5. 为 TCU 编译 ML 模型
Tensil 工具链流程的第二个分支是将 ML 模型编译为由 TCU 指令组成的 Tensil 二进制文件,这些指令由 TCU 硬件直接执行。在本教程中,我们将使用在 CIFAR 数据集上训练的 ResNet20。该模型包含在 Tensil 泊坞窗图像中,位于/demo/models/resnet20v2_cifar.onnx. 在 Tensil docker 容器中,运行以下命令。
tensil compile -a /demo/arch/pynqz1.tarch -m /demo/models/resnet20v2_cifar.onnx -o "Identity:0" -s true
我们使用的是模型的 ONNX 版本,但 Tensil 编译器也支持 TensorFlow,您可以通过在 TensorFlow 冻结图形式编译相同的模型来尝试/demo/models/resnet20v2_cifar.pb。
tensil compile -a /demo/arch/pynqz1.tarch -m /demo/models/resnet20v2_cifar.pb -o "Identity" -s true
生成的编译文件列在ARTIFACTS表中。清单 ( tmodel) 是已编译模型的纯文本 JSON 描述。Tensil 程序 ( tprog) 和权重数据 ( tdata) 都是 TCU 在执行期间使用的二进制文件。Tensil 编译器还会打印一个COMPILER SUMMARY表格,其中包含 TCU 架构和模型的有趣统计数据。
------------------------------------------------------------------------------------------
COMPILER SUMMARY
------------------------------------------------------------------------------------------
Model: resnet20v2_cifar_onnx_pynqz1
Data type: FP16BP8
Array size: 8
Consts memory size (vectors/scalars/bits): 1,048,576 8,388,608 20
Vars memory size (vectors/scalars/bits): 1,048,576 8,388,608 20
Local memory size (vectors/scalars/bits): 8,192 65,536 13
Accumulator memory size (vectors/scalars/bits): 2,048 16,384 11
Stride #0 size (bits): 3
Stride #1 size (bits): 3
Operand #0 size (bits): 16
Operand #1 size (bits): 24
Operand #2 size (bits): 16
Instruction size (bytes): 8
Consts memory maximum usage (vectors/scalars): 71,341 570,728
Vars memory maximum usage (vectors/scalars): 26,624 212,992
Consts memory aggregate usage (vectors/scalars): 71,341 570,728
Vars memory aggregate usage (vectors/scalars): 91,170 729,360
Number of layers: 23
Total number of instructions: 258,037
Compilation time (seconds): 25.487
True consts scalar size: 568,466
Consts utilization (%): 97.545
True MACs (M): 61.476
MAC efficiency (%): 0.000
------------------------------------------------------------------------------------------
6.使用PYNQ执行
现在是时候将所有东西放在我们的开发板上了。为此,我们首先需要设置 PYNQ 环境。这个过程从为我们的开发板下载 SD 卡映像开始。PYNQ 文档网站上有设置板连接的详细说明。您应该能够打开 Jupyter 笔记本并运行一些示例。
现在 PYNQ 已经启动并运行了,下一步是scpPYNQ 的 Tensil 驱动程序。首先将Tensil GitHub 存储库克隆到您的工作站,然后复制drivers/tcu_pynq到/home/xilinx/tcu_pynq您的板上。
git clone git@github.com:tensil-ai/tensil.git
scp -r tensil/drivers/tcu_pynq xilinx@192.168.2.99:
我们还需要scp比特流和编译器工件。
接下来,我们将复制比特流,其中包含由 Vivado 综合和实现产生的 FPGA 配置。PYNQ 还需要一个硬件切换文件,该文件描述主机可访问的 FPGA 组件,例如 DMA。将两个文件都/home/xilinx放在开发板上。假设您位于 Vivado 项目目录中,请运行以下命令复制文件。
scp tensil-pynqz1.runs/impl_1/tensil_pynqz1_wrapper.bit xilinx@192.168.2.99:tensil_pynqz1.bit
scp tensil-pynqz1.gen/sources_1/bd/tensil_pynqz1/hw_handoff/tensil_pynqz1.hwh xilinx@192.168.2.99:
请注意,我们重命名了比特流以匹配硬件切换文件名。
.tmodel现在,将编译器生成的、.tprog和.tdata工件复制到/home/xilinx板上。
scp resnet20v2_cifar_onnx_pynqz1.t* xilinx@192.168.2.99:
运行我们的 ResNet 模型的最后一件事是 CIFAR 数据集。您可以从Kaggle获取它或运行以下命令(由于我们只需要测试批次,因此我们删除了训练批次以减小文件大小)。把这些文件/home/xilinx/cifar-10-batches-py/放在你的开发板上。
wget http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
tar xfvz cifar-10-python.tar.gz
rm cifar-10-batches-py/data_batch_*
scp -r cifar-10-batches-py xilinx@192.168.2.99:
我们终于准备好启动 PYNQ Jupyter notebook 并在 TCU 上运行 ResNet 模型。
Jupyter 笔记本
首先,我们导入 Tensil PYNQ 驱动程序和其他必需的实用程序。
import sys
sys.path.append('/home/xilinx')
# Needed to run inference on TCU
import time
import numpy as np
import pynq
from pynq import Overlay
from tcu_pynq.driver import Driver
from tcu_pynq.architecture import pynqz1
# Needed for unpacking and displaying image data
%matplotlib inline
import matplotlib.pyplot as plt
import pickle
现在,从比特流初始化 PYNQ 覆盖并使用 TCU 架构和覆盖的 DMA 配置实例化 Tensil 驱动程序。请注意,我们axi_dma_0从叠加层传递对象——名称与 Vivado 设计中的 DMA 模块匹配。
overlay = Overlay('/home/xilinx/tensil_pynqz1.bit')
tcu = Driver(pynqz1, overlay.axi_dma_0)
Tensil PYNQ 驱动程序包括 PYNQ Z1 架构定义。这里是摘录自architecture.py:您可以看到它与我们之前使用的架构相匹配。
pynqz1 = Architecture(
data_type=DataType.FP16BP8,
array_size=8,
dram0_depth=1048576,
dram1_depth=1048576,
local_depth=8192,
accumulator_depth=2048,
simd_registers_depth=1,
stride0_depth=8,
stride1_depth=8,
)
接下来,让我们从test_batch.
def unpickle(file):
with open(file, 'rb') as fo:
d = pickle.load(fo, encoding='bytes')
return d
cifar = unpickle('/home/xilinx/cifar-10-batches-py/test_batch')
data = cifar[b'data']
labels = cifar[b'labels']
data = data[10:20]
labels = labels[10:20]
data_norm = data.astype('float32') / 255
data_mean = np.mean(data_norm, axis=0)
data_norm -= data_mean
cifar_meta = unpickle('/home/xilinx/cifar-10-batches-py/batches.meta')
label_names = [b.decode() for b in cifar_meta[b'label_names']]
def show_img(data, n):
plt.imshow(np.transpose(data[n].reshape((3, 32, 32)), axes=[1, 2, 0]))
def get_img(data, n):
img = np.transpose(data_norm[n].reshape((3, 32, 32)), axes=[1, 2, 0])
img = np.pad(img, [(0, 0), (0, 0), (0, tcu.arch.array_size - 3)], 'constant', constant_values=0)
return img.reshape((-1, tcu.arch.array_size))
def get_label(labels, label_names, n):
label_idx = labels[n]
name = label_names[label_idx]
return (label_idx, name)
要进行测试,请提取其中一张图像。
n = 7
img = get_img(data, n)
label_idx, label = get_label(labels, label_names, n)
show_img(data, n)
你应该看到图像。
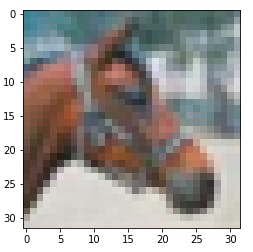
接下来,tmodel将模型的清单加载到驱动程序中。清单告诉驱动程序在哪里可以找到其他两个二进制文件(程序和权重数据)。
tcu.load_model('/home/xilinx/resnet20v2_cifar_onnx_pynqz1.tmodel')
最后,运行模型并打印结果!调用tcu.run(inputs)是魔法发生的地方。我们将 ResNet 分类结果向量转换为 CIFAR 标签。请注意,如果您使用的是 ONNX 模型,则输入和输出分别命名为x:0和Identity:0。对于 TensorFlow 模型,它们被命名为x和Identity。
inputs = {'x:0': img}
start = time.time()
outputs = tcu.run(inputs)
end = time.time()
print("Ran inference in {:.4}s".format(end - start))
print()
classes = outputs['Identity:0'][:10]
result_idx = np.argmax(classes)
result = label_names[result_idx]
print("Output activations:")
print(classes)
print()
print("Result: {} (idx = {})".format(result, result_idx))
print("Actual: {} (idx = {})".format(label, label_idx))
这是预期的结果:
Ran inference in 0.1513s
Output activations:
[-19.49609375 -12.37890625 -8.01953125 -6.01953125 -6.609375
-4.921875 -7.71875 2.0859375 -9.640625 -7.85546875]
Result: horse (idx = 7)
Actual: horse (idx = 7)
恭喜!您运行了一个机器学习模型,一个您在自己的工作站上构建的自定义 ML 加速器!想象一下你可以用它做的事情......
包起来
在本教程中,我们使用 Tensil 展示了如何在 FPGA 上运行机器学习 (ML) 模型。我们经历了许多步骤,包括安装 Tensil、选择架构、生成 RTL 设计、综合设计、编译 ML 模型,最后使用 PYNQ 执行模型。
如果你一路走来,那么恭喜你!通过尝试自己的模型和架构,您已准备好将事情提升到一个新的水平。加入我们的Discord打个招呼并提出问题,或发送电子邮件至support@tensil.ai。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





