

复旦和Meta提出Open-VCLIP:兼顾时序建模与开集识别的视频理解模型
描述
导读:
CLIP[1]是一个强大的开放词汇模型,在图像领域表现出强大的零样本识别能力,但如何将该能力迁移到视频领域是一个较难的问题,主要存在两大挑战:一是如何为图像CLIP模型注入时序建模能力;二是在视频领域迁移的过程中如何保持其对开放词汇理解能力。
许多工作通过在视频数据集上进行微调以实现CLIP向视频领域的迁移,然而由于微调时使用的数据集规模相对较小,导致模型发生过拟合,使得CLIP模型原有的零样本识别能力有所丢失。
本文提出了一种新的CLIP向视频领域的迁移方法,找到模型泛化和专用化之间的平衡,让模型既能识别微调时已经见过的动作和事件,又能够借助CLIP的零样本识别能力泛化到新的视频动作和事件。
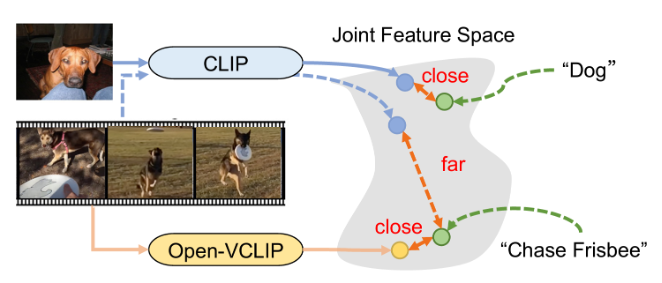
问题归纳:将开放词汇视频模型构建问题近似于持续学习问题
假设存在一个包含所有的“视频-文本”对的数据集,那么可以通过在上最小化”视频-文本“对比损失来获得最佳开放视频词汇模型:
然而,现实中如此理想的数据集不可能存在,人们只能通过尽可能大规模、多样化的视频文本数据集来近似。视频动作识别是视频内容理解中一类重要任务,本文选取了视频动作识别数据集作为近似。此时,由于动作类别数量的限制(例如Kinetics-400只包含了400个类别),模型在微调过程中容易发生过拟合。
另一方面,本文发现CLIP的训练数据包含大规模“图像-文本”对,且图像可以容易地扩展为静态视频,因此可以认为原始CLIP的权重在大规模“静态视频-文本”(记作上已经达到最优。如果将数据集结合作为的近似,那么优化目标将转化为:
此处数据集是私有数据集,在CLIP迁移学习的过程中完全无法触碰,而已知CLIP权重是数据集上的最优解,因此本文目标是利用和构建开放词汇视频模型。自然地,开放词汇视频模型构建问题转变为一个持续学习的过程:在保持对历史任务()性能的同时,不断地在新的视频-文本数据集()上训练模型,提升模型的泛化能力。
Open-VCLIP方法介绍:
为了解决上述问题,本文提出Open-VCLIP方法,包括模型架构和算法改进两部分。在架构设计方面,通过修改自注意层将时序建模能力注入到CLIP模型中;在算法改进方面,提出了插值权重优化的新方法,取得更好的闭集性能与零样本识别性能的权衡。
(1)注入CLIP时序建模能力
本文参考了Space-Time Mixing[2],通过修改自注意层的信息关注范围,让自注意力操作过程中的每个块关注到所属视频帧以及相邻视频帧中的图像块信息来实现局部时序信息聚合,并随着自注意力层的堆叠完成全局时间信息聚合,从而实现时序建模能力的注入。该过程不需要增加额外参数,适配于后文引入的权重插值优化方法。
(2)权重插值优化算法
本文解决的是一个零历史信息的持续学习问题,即以为模型初始化参数,通过优化将模型迁移到数据集上,同时需要尽可能保持最小。然而,标准的微调训练方式往往容易使模型过拟合到,导致CLIP原始的开放词汇能力流失严重,进而影响模型的泛化能力,这将是本文着重想要解决的问题。
受到[3]的启发,本文首先引入了一个无需优化的权重插值策略:通过加权系数对CLIP原始参数和在数据集上完成微调后的参数进行加权平均操作,防止迁移学习后的模型在原始数据集上的过度遗忘。具体形式如下:
但这种做法由于不存在显示的优化约束,导致插值得到的模型可能会在上有较为严重的欠拟合。针对此问题,本文提出在训练过程中对于插值模型在数据集上添加正则化约束,从而缓解插值得到的模型在新数据上欠拟合严重的问题。具体来说,本文提出在训练过程中对插值权重系数进行随机采样,针对一系列取值下的插值模型在上进行优化约束,最终的优化目标如下:
其中,插值系数在区间区间均匀采样,该范围对应了期望构建的低损失区域。是正则化损失的权重系数,本篇文章实现时将其取值为。对应的梯度计算如下:
最后,本文在训练过程中对插值权重应用随机权重平均(SWA)[4]来进一步提高方法稳定性和泛化性。在实践中,只需要维护模型权重的移动平均值,并在最后进行权重插值即可,形式化描述如下。
实验
本文实验采用Kinetics-400视频动作识别数据集作为微调CLIP的训练数据,并将UCF、HMDB以及Kinetics-600子集作为测试视频模型的零样本识别能力的数据集。
(1)零样本识别性能
与CLIP基线和标准微调模型进行对比,可以看出,相比于标准微调方法容易出现较为严重的遗忘现象,本文所提的Open-VCLIP方法能够显著提升模型的零样本识别能力,在不同主干网络、不同数据集上都取得了最佳的零样本识别准确率。
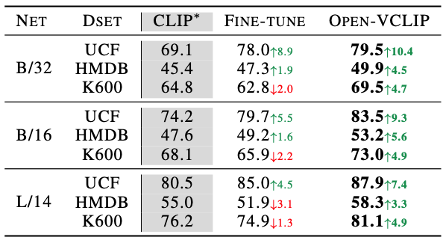
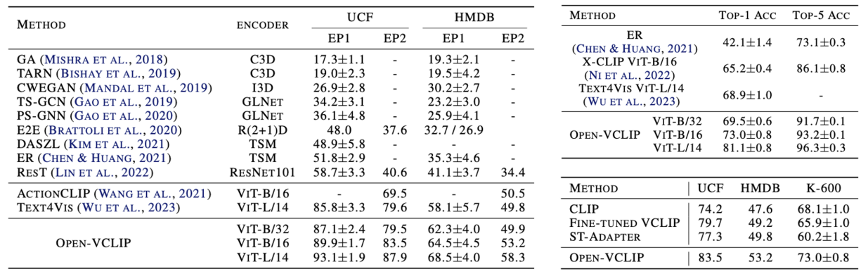
此外,本文同当前先进零样本识别性能的方法进行了对比。可以看到,Open-VCLIP方法在不同数据集上均取得最佳零样本准确率。除此之外,文章还对比了冻结原始CLIP模型参数下微调Adapter模块的高效参数微调方法,结果表明,高效参数微调方法无法有效提升零样本识别准确率。
(2)零样本识别性能与闭集性能的权衡
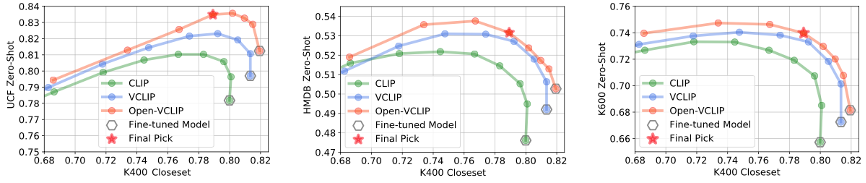
文章对不同方法应用权重插值修复算法[3]进行探究,并将不同的加权系数下的性能用折线图的方式展现,横坐标表示闭集性能,纵坐标为零样本识别性能。结果表明:(i)具有时序建模能力的模型具备更强的零样本识别性能,显示出时序建模能力对于CLIP模型向视频领域的迁移是必要的;(ii)Open-VCLIP曲线高于标准微调方法,反映出本文所提出的优化策略不仅能提升模型的零样本视频识别能力,而且能够在零样本识别性能和闭集性能中取得最佳权衡;(iii)同时,图中红色五角星对应同一个插值模型,可以看到单个模型能够在多个数据集中取得接近最优的零样本识别性能,且保持较高的闭集准确率,显示出方法无需针对特定数据集专门调整插值权重。
(3)零样本视频文本检索性能

评估文本到视频/视频到文本的检索性能可以进一步了解模型的泛化能力。实验遵循了在Kinetics-400数据集上训练模型,并在MSR-VTT数据集上测试的范式。结果展示了Open-VCLIP方法提升了模型的视频检索文本的性能和文本检索视频的性能,且在视频检索文本任务上,Open-VCLIP方法明显高于CLIP基线,进一步验证了本文方法有效性。
总结
本篇工作提出了Open-VCLIP方法,通过微调于视频识别数据集有效将CLIP转变为开放词汇的视频模型。文章主题包含三个部分:将问题归纳为无历史数据的持续学习问题;为模型添加轻量化时序建模能力;设计正则化插值优化策略提升模型泛化能力,减轻遗忘现象发生。实验表明,Open-VCLIP在零样本动作识别任务明显优于最先进的方法,并在闭集性能和零样本视频动作识别性能之间实现了最佳的权衡,所提方法也为大模型微调提供了新思路。
-
关于功能验证、时序验证、形式验证、时序建模的论文2011-12-07 0
-
高阶API构建模型和数据集使用2020-11-04 0
-
多片段时序数据建模预测实践资料分享2021-06-30 0
-
分享一种comsol磁场与结构场耦合模型建模2021-07-09 0
-
结合码本和运行期均值法的双层背景建模方法2017-11-29 845
-
面向人体动作识别的随机增量型混合学习机模型2018-01-03 863
-
基于视频的人脸识别转换为图像集识别2018-01-21 669
-
基于视频深度学习的时空双流人物动作识别模型2018-04-17 1604
-
可高效识别视频不同内容的视频摘要算法2021-04-29 882
-
面向人脸识别的FusNet网络模型2021-06-09 649
-
模型在Close set和在Open set的表现是否存在一定的相关性呢2022-09-09 1000
-
基于实体和动作时空建模的视频文本预训练2023-05-25 772
-
Meta发布新型无监督视频预测模型“V-JEPA”2024-02-19 1015
-
Meta发布新AI模型Meta Motivo,旨在提升元宇宙体验2024-12-16 270
全部0条评论

快来发表一下你的评论吧 !
