

英特尔加速虚拟蜂窝基站路由器解决方案助力5G服务商提升服务创收能力
描述
当前,网络连接与联网设备的数量均呈指数级增长,使得通信服务提供商对于灵活的无线接入网 (RAN) 架构的需求也持续高涨。开放式 RAN (O-RAN) 是RAN 的非专有实现,能够使不同供应商提供的蜂窝网络设备之间实现互操作性。为了支持 O-RAN 概念的推广,RAN行业的移动网络运营商、供应商以及研究和学术机构组成了名为 O-RAN 联盟1的全球社区。
第三代合作伙伴计划 (3GPP)2 是一组制定移动电信协议的标准组织的总称。5G NR(New Radio,即新空口)是 3GPP 针对 5G 开发的一种新的无线接入技术 (RAT),旨在成为5G网络空中接口的全球标准。
通信服务提供商正在积极推进 RAN 的虚拟化,以实现类似云的敏捷性和经济性。在他们当中,寻求通过虚拟 RAN (vRAN) 和 O-RAN 协作为 5G 部署带来可扩展性和运营效率已成大势所趋。这其中就涉及到网络切片的概念。通过使用网络切片,通信服务提供商可提供性能和质量水平皆有保证的5G服务,进而增加收入。据预计,2020至2030年,RAN 网络虚拟化市场的复合年增长率 (CAGR)将达到19%3。
作为 O-RAN 解决方案的关键部分,蜂窝基站路由器(CSR)会聚合来自 1 个或多个无线电塔的移动数据流量,然后再将其传输回通信服务提供商的核心网。实施 RAN 虚拟化的环节之一即是对蜂窝基站路由器进行虚拟化处理。英特尔的加速虚拟蜂窝基站路由器(vCSR)解决方案,采用基于英特尔 Agilex 7 FPGA 的 N6000-PL 平台以及符合 O-RAN 标准的精确时间协议,可助力通信服务提供商提高服务创收能力。
从 4G LTE 向 5G NR 演进
用于 4G LTE 与 5G NR RAN 的无线网络设备之间存在着诸多差异。例如,无线网络天线和基站通常使用不同的前传链路协议。
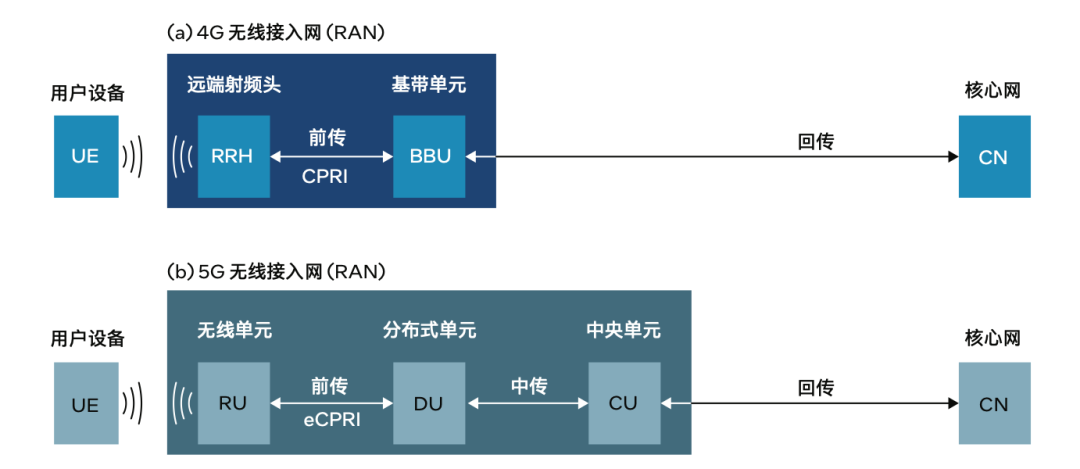
图 1 (a) 和 (b). 4G 和 5G RAN 架构差异的概括性表示。在 5G RAN 中,基站拆分为三个逻辑节点:RU、DU 和 CU
在 4G RAN 中,蜂窝基站的无线收发器称为“远端射频头(RRH)”。这些收发器连接至又称“基带单元(BBU)”的基站,而基带单元本身则连接到核心网。就 4G RAN 而言,术语“前传”是指 RRH与 BBU 之间基于光纤的连接,而术语“回传”是指 BBU 与核心网之间的连接。如图 1a 所示,4G 前传部署通常使用通用公共无线接口(CPRI)。
5G RAN 架构则设有 3 个逻辑节点,且这 3 个逻辑节点通常作为3 个独立设备来实现。下层 1 (L1) 功能中有些向上移入无线单元(RU),其余功能则在分布式单元(DU)和中央单元(CU)之间进行划分。就 5G 而言,“前传”指的是 RU 和 DU 之间基于光纤的连接,“回传”指的是 CU 与核心网之间的连接。另外,为了描述DU 和 CU 之间的连接,还使用了一个新的术语“中传”。
众多 5G(以及部分新部署的 4G )用例均要求大大增加前传带宽。为解决高带宽前传成本增加的问题,架构师建议在 BBU和 RRU 之间使用新的功能分区。减少前传带宽的一种方法是将功能从 BBU 转移到 RRU 中;另一种方法是使用数据压缩技术。3GPP 标准组织对大多数移动通信网元、测试和互操作性进行了定义,但却未定义前传接口。此前,这一空白一直由通用公共无线接口(CPRI) 填补。但对于 5G 和基于以太网的传输而言,已有部分工作组迈出重要一步,填补了这一规范上的空白。
CPRI 接口要求使用专用“暗”光纤并承载着“基本帧(basic frame)”信息。这些基本帧封装用户平面流量(时域数字化无线电流量)、控制平面信息和时间信息。时间信息易于提取且具有高度确定性。使用时间信息可相当轻松地使无线电同步精度达到所需的 ±8 纳秒左右。 如图 1b 所示,5G 通常使用基于增强型 CPRI (eCPRI) 传输协议的O-RAN 进行前传。O-RAN/eCPRI 通过以太网进行传输。使用以太网这种很常见的传输类型,可获得多种技术和成本优势。
然而,以太网最初并非为传输时间敏感型信息而设计,因此这样做存在着巨大挑战。以太网数据包在网络中可以采用不同路径进行传输,它们有可能会经过路由器,而且大多数网元会产生约10 微秒的非确定性时延。为解决这一问题,O-RAN 接口支持多种同步机制。这些同步机制主要利用的是时间敏感网络 (TSN)方面的 IEEE 标准,例如IEEE1588v2 “Standard for PrecisionClock Synchronization Protocol for Network Measurementand Control Systems”(网络测量和控制系统的精确时钟同步协议标准)。而通过在同一个以太网接口/路径使用一系列精确时间协议 (PTP) 报文,两端可实现“time of day” (ToD) 的准确交换。锁定至主参考时钟 (PRTC) 源[例如,全球卫星导航系统(GNSS)] 的主时钟,会将 ToD 分配给作为从属时钟的其他网络实体。在 O-RAN 网络拓扑结构中,这些网络实体通常为无线单元 (RU)。从属时钟在对比内部 ToD 后将调整自身时钟以跟踪主参考时钟的ToD。主参考时钟可能会与CU、DU或核心网混布。虽然不强制要求保持端到端时间精度,但应保持网络中交换机和路由器的同步。
就前传而言,典型的 5G RU 通常使用 eCPRI 和 3GPP 定义的功能拆分选项 7.2,而 4G RU 通常使用 CPRI 和功能拆分选项 8。如果 RAN 必须同时容纳 4G 和 5G 基础设施,往往会使用称为“前传网关 (FHGW)”的设备来执行 CPRI 到 eCPRI 的转换,包括位于功能拆分选项 7.2 和功能拆分选项 8 之间的 L1 信号处理(FFT 和 PRACH)。 RAN 部署分为两大主要架构。在 C-RAN(云 RAN)部署中,DU 采用集中部署方式,可位于距离 RU 20 公里或更远的地点。这是一种适用于都市密集场景的典型部署,支持可优化处理需求的基带池化技术。在 D-RAN(分布式 RAN)部署中,DU 分布于各个蜂窝基站。这是一种适用于偏远地区场景的典型部署。
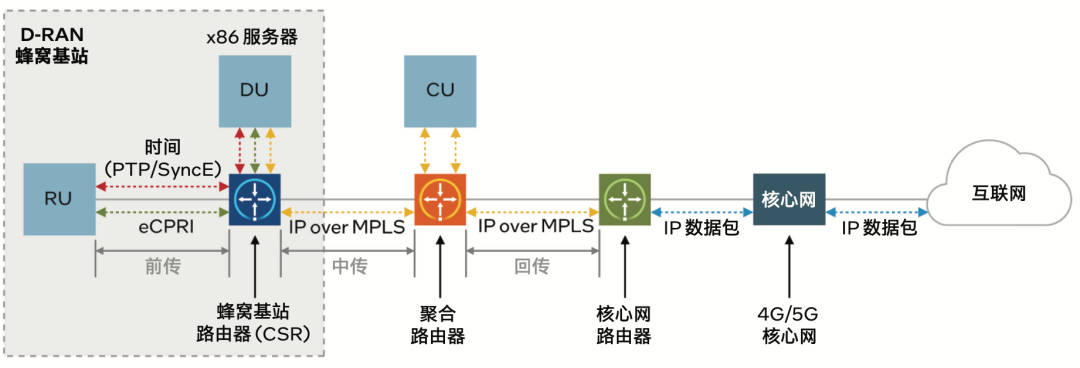
图 2. 5G RAN 场景中蜂窝基站的概括性表示
5G D-RAN 需对 RU(无线收发器和天线)、DU 和辅助设备(见图 2 )进行组合设计。该场景下,蜂窝基站路由器 (CSR)会将 RU 与 DU,以及 DU 与 CU 所在的移动基础设施的其余部分连接起来。RU 和 CSR/DU 间的前传连接通常由光纤承载。DU/CSR 和聚合路由器/CU之间的中传连接可通过光纤、微波或卫星链路来实现,其中卫星链路使用的是经由多协议标签交换(MPLS) 技术传输的 IP 协议(下称“IP over MPLS”)。
多个 RU 可连接至单个 CSR,一个网状网络或环形网络中的多个CSR 可连接至单个聚合路由器。在编写本文档之时,大多数CSR 通常作为 DU 的外部独立设备来实现。不过,随着行业从4G 转向 5G,在同一个商用现货 (COTS) 平台中实现 CSR 功能、面向 4G 无线网络的可选 FHGW 功能、面向未来的可选 6GNumerology 前向纠错 (FEC) 加速功能以及 DU 的融合已成为可能。
分布式基站(CU 和 DU)与集成 vCSR 相结合的理念对运营商来说有着诸多优势。以 D-RAN 为例,前传网络的距离可能很短,因此可以减少时间敏感交换机的用量或可以将其完全移除。而降低前传的复杂性也会不可避免地限制时钟同步区域。这些均有助于简化硬件设计并降低成本。例如,现在可以使用来自Supermicro、启碁科技(WNC)和控创的 COTS 服务器来实现 DU 功能,该服务器包含了利用英特尔 FPGA SmartNICN6000-PL 平台加速卡实现的 vCSR(下文将进行阐述)。由于前传要求具备高数据速率,因此终止靠近 DU 端天线的链路,就可以在既不需要时钟同步,也不需要纠错的中传部分使用低得多的数据速率。与此同时,基站拆分还有助于通过多个中传路径实现多种网络切片方案,或方便在多个运营商之间共享移动基础设施。
英特尔 加速 vCSR 解决方案概览
基于英特尔 FPGA 的加速 vCSR 解决方案采用一体化架构。该架构采用集成的 vRouter 功能 (vCSR),以及 FHGW(可选择集成)和基带加速功能(可选择集成)。如图 3 所示,所有这些功能均混布于同一个基于英特尔 Agilex 7 FPGA 的SmartNIC(即英特尔 FPGA SmartNIC N6000-PL 平台)上。该卡可插入 x86 服务器,充当虚拟 DU (vDU)。
此外,由于基于英特尔 FPGA SmartNIC N6000-PL 平台的加速卡可作为配备 SR-IOV 接口的基础网卡(即运行应用时,无论是否使用英特尔 FPGA SmartNIC N6000-PL 平台,都不会带来功能上的变化),因此也可以增加诸如层次化服务质量(HQoS) 等额外的用户服务。

图 3. 使用 FPGA SmartNIC 加速卡,实现 CSR 功能虚拟化
第四代英特尔 至强 可扩展处理器 (SPR-EE) 内置名为英特尔vRAN Boost 的专用片上硬件加速器。当 vDU 运行在这款处理器上时,英特尔 vRAN Boost 即可从主 CPU 内核上卸载 4G(Turbo) 和/或 5G (LDPC) 的 FEC 任务。对于没有内置英特尔vRAN Boost 的处理器而言,FEC 可在运行 vCSR 的同一个基于英特尔 FPGA SmartNIC N6000-PL 平台的加速卡上实施。
集成的 vRouter 功能将处理层 2 (L2) 流量管理和层 3 (L3) 路由任务,并提供 IEEE 1588 精准时间协议支持。这一解决方案旨在支持瞻博网络云原生路由器堆栈,该堆栈具备高性能、可扩展的商业级路由功能,可为与 MPLS 数据平面集成的路由平面提供先进的解决方案。另外,还有 FRRouting (FRR)项目等开源方案可供使用。这些 vCSR 任务在英特尔 Agilex 7 SoC FPGA 的硬核处理器子系统 (HPS) 内核上运行,因而可释放主机服务器的处理器内核,用于执行那些创收功能。
英特尔 加速 vCSR解决方案可支持 MPLS 或 SR-MPLS 协议下的中传(F1接口),同时还能够凭借特有的可编程性,以相同的硬件为未来的基础设施(如 SRv6)提供支持。另外,该解决方案还支持自动预配,这是一项通信服务提供商所需的关键功能,可简化网络切片任务。自动预配可避免对每个 MPLS 标签进行手动编程(要知道,手动编程会延缓部署进程)。通信服务提供商在手动输入用于网络切片的 MPLS 标签时,每个标签必须乘以切片数。这可能导致他们需要手动输入数以万计的条目,不仅耗时且容易出错,而所有这些都可以通过自动预配加以避免。 英特尔 FPGA SmartNIC N6000-PL 平台支持各种 O-RANWG-4 规范定义的同步配置文件,包括 LLS-C1(其中 vCSR为 GM/T-BC,RU 通过光纤同步),LLS-C2(其中 vCSR 为GM/T-BC,RU 通过网络同步),LLS-C3(其中 vCSR 和RU 均通过网络同步)和 LLS-C4 (其中 vCSR 和 RU 各自进行同步)。概括而言,英特尔 加速 vCSR 解决方案将前传到中传的转换与同步结合起来,将中传传输功能与网络切片支持以及服务器管理和遥测管理结合起来,满足了网络运营商的关键要求。此外,英特尔 加速 vCSR 解决方案还支持 5G Class B 和 Class C 系统要求的时钟精度。
作为英特尔 FPGA N6000-PL 平台的备选方案,英特尔 加速 vCSR 解决方案也可在集成了外形规格符合特定配置要求的英特尔 Agilex 7 FPGA 的定制板卡上实施。例如,英特尔 FPGA N6000-PL 平台支持 6 个前传或中传端口(每种 3 个),定制板卡可以在此基础上增加端口数量。其他自定义功能还包括安全功能,例如互联网安全协议 (IPsec) 或在硬件中实施的媒体接入控制安全协议 (MACsec)。与此同时,路由和控制堆栈可以使用嵌入英特尔 Agilex 7 SoC FPGA 的硬核化 Arm 处理器内核来实施,进而使这些功能对运行在主机上的软件应用始终 处于不可见的状态。 英特尔 Agilex 7 FPGA 和 SoC FPGA 具备硬核化的安全设备管理器 (SDM) 功能,使 FPGA 在现场即可进行安全更新。这能够支持多种高级功能,例如防止 Day-0/Day-1/Day-2 漏洞攻击的安全预配功能,这是实施系统管理,实现自动远程更新的关键要素。
在同一基于 FPGA 的加速卡中实现上述虚拟功能(以往,这些虚拟功能是通过独立的外部组件或加速卡来实现的)所带来的价值、能力和可管理性不言而喻。原本涉及多个供应商的不同应用编程接口(API)的组件管理也在很大程度上得到简化。与此同时,这也大幅减少了连接大型蜂窝基站各个设备所需的电缆和光纤数量。
网络切片支持
在边缘计算位置实现低时延服务通常需要修改该位置的硬件和软件要求。以 4G/LTE 安装场景为例,由于不需要专门针对特定用户的功能,因此硬件和软件可以作为专有设备来实施部署。相比之下,为提升 5G 服务的创收能力,使用 DU、CU 和 5G 用户平面功能 (UPF) 运行低时延用户服务是一种标准部署模式。
理想的实施方式是使用 COTS 服务器,并配置基于 FPGA 的硬件加速卡,进而充分利用服务器 CPU 内核来运行用户服务。很多时候,用户服务将与 UPF 处于同一位置,这样可以判定哪些流量应作为由边缘计算资源处理的低时延流量,而非由核心网服务处理的普通流量。图 4 所示为上文提到的这类可能。

图 4. 网络切片示例
根据网络切片要求,UPF 和多接入边缘计算 (MEC) 的位置应尽可能靠近前传,置于接入网或 5G 核心网中。COTS 服务器可用于所有这些位置。这意味着移动基础设施可由单独的 COTS服务器构成,其中 DU、CU 和 UPF 功能均作为应用来运行,使用的是 CPU 内核。我们可以使用一个或一套服务器来运行规模较大的 DU,或者也可以将此类 DU 与其他功能混布。在所有这些情况下,功能虽然相同,但流量的处理能力将根据部署模式进行扩展。
如今的电信运营商都希望找到能够联通边缘服务与移动基础设施的理想方式。从传统的标签分发协议 (LDP) MPLS 到多种通过 IPsec 增强的分段路由协议选择方案,再到带内操作、管理和维护 (iOAM) 功能,可供考虑的技术有很多,但各家运营商都希望部署更为强大的解决方案,以便为客户提供更合适的连接选择。FPGA提供了一种经济高效的方式来实施硬件加速的高性能解决方案。
英特尔 FPGA SmartNIC N6000-PL
平台概述
英特尔 FPGA SmartNIC N6000-PL 平台(图 5)是第三代基于英特尔 Agilex 7 FPGA 家族系列的 SmartNIC 产品, 主要用于网络加速。它支持 2 路 100 Gbps 以太网连接,与前几代产品相比,性能更加出色,总体拥有成本 (TCO) 更低,并具有可扩展性。

图 5. 英特尔 FPGA SmartNIC N6000-PL 平台示意图
英特尔 Agilex 7 FPGA 采用英特尔先进的 10 纳米 SuperFin 技术和第二代英特尔 Hyperflex FPGA 架构构建。与 7 纳米 FPGA 其他产品相比,英特尔 Agilex 7 FPGA 逻辑结构的每瓦性能提升大约 2 倍。本文探讨的基于 FPGA 的高性能 SmartNIC 平台功能全面, 可支持通信工作负载 [如 4G/5G vRAN、vCSR、5G UPF、Contrail2 (CN2) 以及 SMPTE ST2110 通过托管 IP 网络传输的专业媒体等]的硬件可编程加速。
如图 6 所示,英特尔 FPGA SmartNIC N6000-PL 平台通常以 2 种方式呈现:
作为可量产解决方案:希望按产品原始设计部署基于 N6000 的商用现货 SmartNIC 的客户可自英特尔合作伙伴处购买基于 N6000 的量产网卡和面向不同工作负载的应用。开放式 FPGA 堆栈 (OFS) 和基板管理控制器 (BMC) 设计文件可在合作伙伴处获得,用以加速自定义工作负载的开发。
作为平台设计:希望通过利用 N6000 板卡设计进行自定义设置以提升产品差异化,进而加速自身自定义板卡设计的客户,可以使用英特尔 FPGA N6000-PL 平台。平台包括板卡设计文件、开放式 FPGA 堆栈、BMC 设计、工作负载、文档和非量产板卡(请联系当地的英特尔销售代表,了解更多信息)。
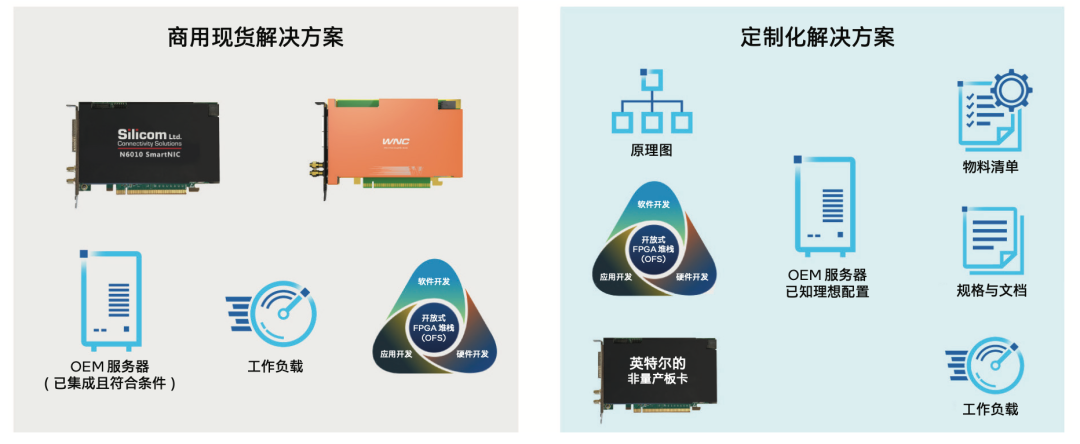
图 6. 英特尔 FPGA N6000-PL 平台既可作为英特尔合作伙伴的 COTS 解决方案,也可作为英特尔的平台设计提供,用于定制化解决方案
英特尔 FPGA SmartNIC N6000-PL
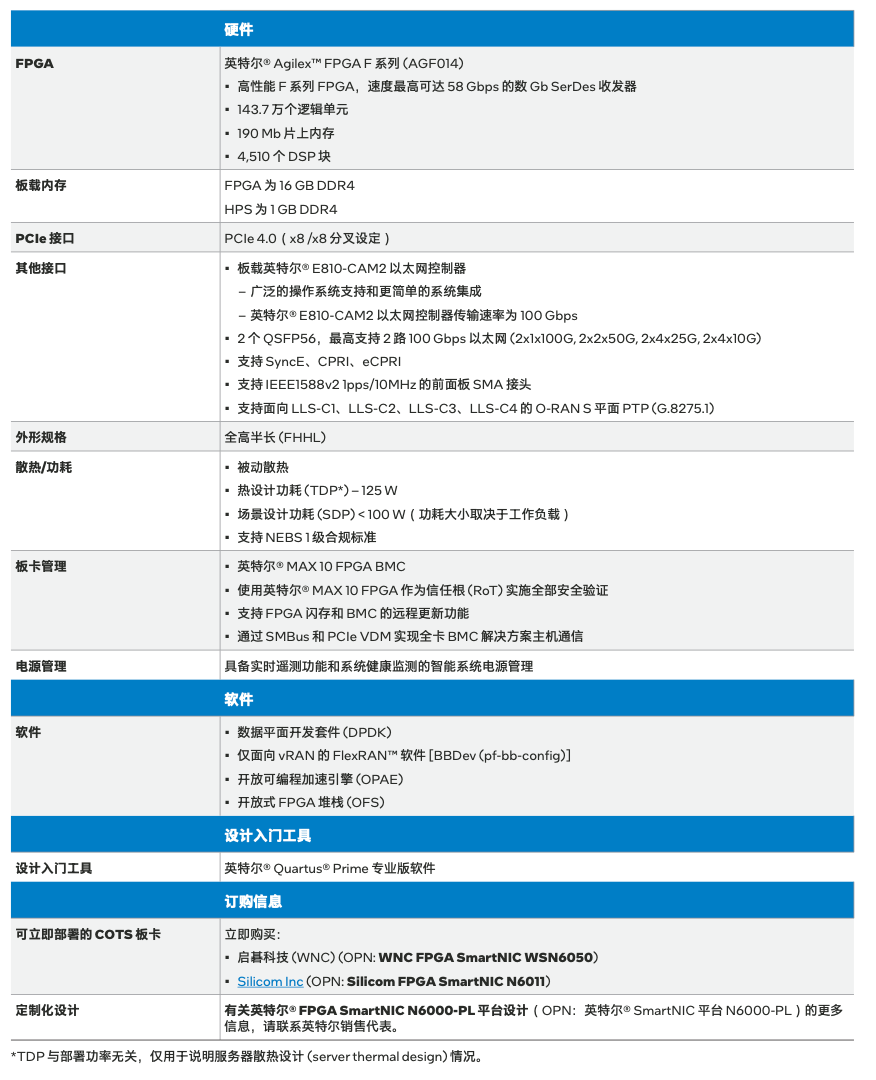
平台规格与订购信息
结 论
越来越多的通信服务提供商在寻求通过虚拟无线接入网为 5G 部署带来可扩展性和运营效率。实施 RAN 虚拟化的环节之一即是对蜂窝基站路由器进行虚拟化处理,这有助于通信服务提供商提升服务创收能力。英特尔 加速 vCSR 解决方案采用基于英特尔Agilex 7 FPGA 的 N6000-PL 平台以及符合 O-RAN 标准的精确时间协议。目前,SuperMicro、控创和启碁科技等多家英特尔合作伙伴的 COTS 服务器均可提供这一 vCSR 解决方案。
由于这一硬件加速的 vCSR 解决方案符合 O-RAN 的 LLS-C1、LLS-C2、LLS-C3 和 LLS-C4 同步配置文件要求,因此可在提升互操作性的同时,提供 5G Class B 和 Class C 系统要求的时间同步精度。CSR 路由和控制堆栈运行于英特尔 Agilex 7 SoC FPGA的硬核处理器系统,无需在主机上预配 CPU 内核。
由于该 vCSR 解决方案采用的是常见软件并且基于标准的开源 API 构建,因此可避免供应商绑定风险,为客户提供更多选择,同时还可简化网络部署和故障排除工作。此外,英特尔 vCSR 解决方案还支持网络切片,可助力运营商提高自身服务创收能力。
审核编辑:汤梓红
-
英特尔FPGA 支持阿里云的加速即服务2017-10-17 8314
-
MWC上海2018:英特尔助力合作伙伴加速5G部署2018-06-28 5641
-
高效率网络服务器解决方案2013-12-04 0
-
5G芯片市场,你看好英特尔还是高通?2017-03-01 0
-
阿里巴巴携手英特尔开发一款基于FPGA的解决方案,以帮助客户提升业务应用的性能2017-03-15 0
-
聚合路由器2020-03-03 0
-
5G工业网关和5G工业路由器对比分析2020-09-01 0
-
5G基站智慧用电解决方案2020-11-09 0
-
苹果放弃未来在iPhone上使用英特尔5G基带芯片 精选资料推荐2021-07-23 0
-
4G路由器与家用WiFi路由器有什么区别2023-04-11 0
-
英特尔致力多接取边缘运算解决方案 为5G布局2017-12-20 460
-
英特尔发布全新网络设施参考设计,加速通信服务提供商5G商业化进程2018-06-23 3627
-
中国联通携手英特尔和中兴共同发布了5G新媒体云服务解决方案2019-03-07 752
-
英特尔正式进入5G小基站领域将引领未来5G变革2019-08-14 3263
-
英特尔和谷歌云共同在多个网络和边缘位置加速5G部署2021-02-25 525
全部0条评论

快来发表一下你的评论吧 !
