

CVPR 2023 | 华科&MSRA新作:基于CLIP的轻量级开放词汇语义分割架构
描述
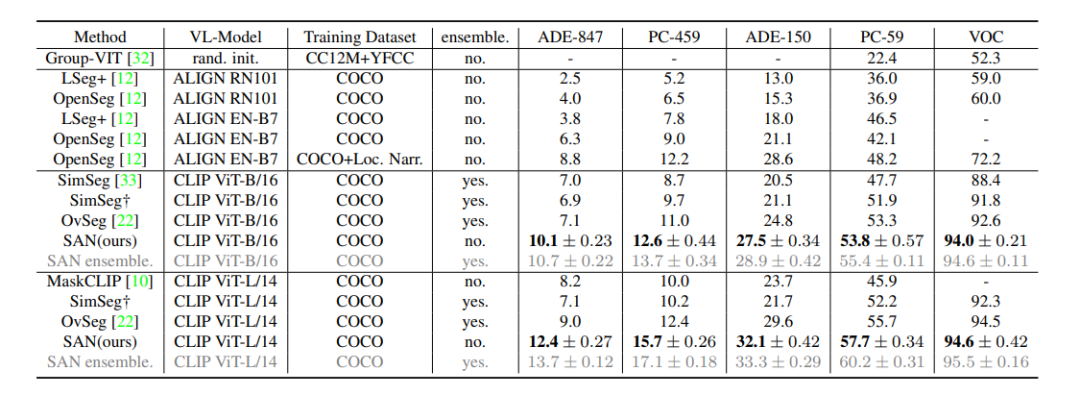
本文提出了 SAN 框架,用于开放词汇语义分割。该框架成功地利用了冻结的 CLIP 模型的特征以及端到端的流程,并最大化地采用冻结的 CLIP 模型。

简介本文介绍了一种名为Side Adapter Network (SAN)的新框架,用于基于预训练的视觉语言模型进行开放式语义分割。该方法将语义分割任务建模为区域识别问题,并通过附加一个侧面的可学习网络来实现。该网络可以重用CLIP(Contrastive Language-Image Pre-Training)模型的特征,从而使其非常轻便。整个网络可以进行端到端的训练,使侧面网络适应冻结的CLIP模型,从而使预测的掩码提案具有CLIP感知能力。作者在多个语义分割基准测试上评估了该方法,并表明其速度快、准确度高,只增加了少量可训练参数,在一系列数据集上相较于之前的SOTA模型取得了大幅的性能提升(如下表所示)最后,作者希望该方法能够成为一个baseline,并帮助未来的开放式语义分割研究。

论文链接:
https://arxiv.org/abs/2211.08073

Introduction
作者首先讨论了语义分割的概念和现代语义分割方法的限制,以及如何将大规模视觉语言模型应用于开放式语义分割。现代语义分割方法通常依赖于大量标记数据,但数据集通常只包含数十到数百个类别,昂贵的数据收集和注释限制了我们进一步扩展类别的可能性。最近,大规模视觉语言模型(如CLIP)的出现促进了零样本学习的发展,这也鼓励我们探索其在语义分割中的应用。然而,将CLIP模型应用于开放式语义分割十分困难,因为CLIP模型是通过图像级对比学习训练的,其学习到的表示缺乏像素级别的识别能力,而这种能力在语义分割中是必需的。解决这个问题的一个方法是在分割数据集上微调模型,但是分割数据集的数据规模远远小于视觉语言预训练数据集,因此微调模型在开放式识别方面的能力通常会受到影响。
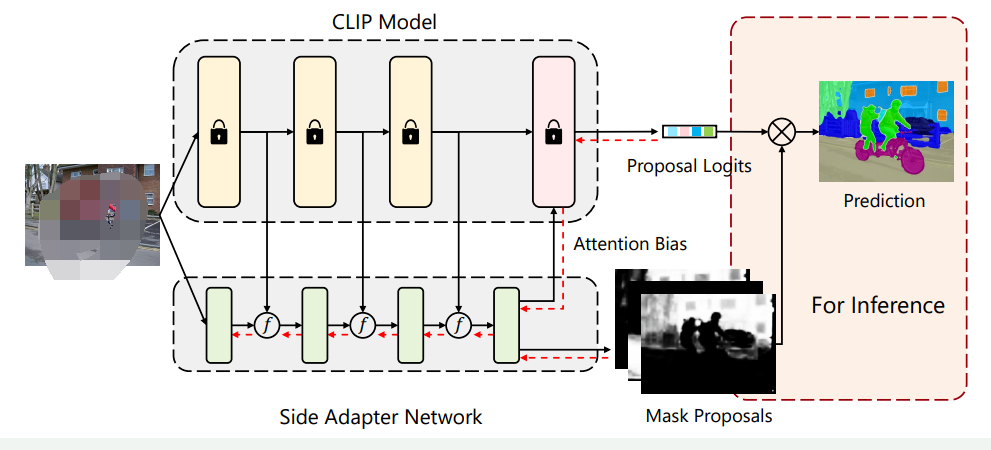
为了充分发挥视觉-语言预训练模型在开放词汇语义分割中的能力。作者提出了一种名为Side Adapter Network(SAN)的新框架。由于端到端训练,SAN的掩膜预测和分类是基于CLIP辅助的。整个模型十分轻量化。SAN有两个分支:一个用于预测掩膜,另一个用于预测应用于CLIP的注意力偏好,以进行掩膜类别识别。作者表明,这种分离的设计可以提高分割性能。此外,作者还提出了一种单向前设计,以最小化CLIP的成本:将浅层CLIP块的特征融合到SAN中,将其他更深层次的块与注意偏置结合以进行掩膜识别。由于训练是端到端的,SAN可以最大程度地适应冻结的CLIP模型。作者的研究基于官方发布的ViT CLIP模型,采用Visual Transformer实现。准确的语义分割需要高分辨率图像,但发布的ViT CLIP模型设计用于低分辨率图像(如),直接应用于高分辨率图像会导致性能下降。为了缓解输入分辨率的冲突,作者在CLIP模型中使用低分辨率图像,在SAN中使用高分辨率图像。作者表明,这种不对称的输入分辨率非常有效。此外,作者还探讨了仅微调ViT模型的位置嵌入,并取得了改进。作者在各种基准测试中评估了他们的方法。与之前的方法相比,作者的方法在所有基准测试中都取得了最好的性能。作者的方法只有8.4M可训练参数和64.3 GFLOPs。
 Method
Method
3.1 基础架构
SAN的详细架构如下图所示。输入图像被分成个patch。首先通过一个线性层将图片转化为Visual Tokens。这些Visual Tokens会与个可学习的Query Tokens拼接起来,并送到后续的Transformer Layer中。每个Transformer Layer的Visual Tokens和Query Tokens都添加了position embedding。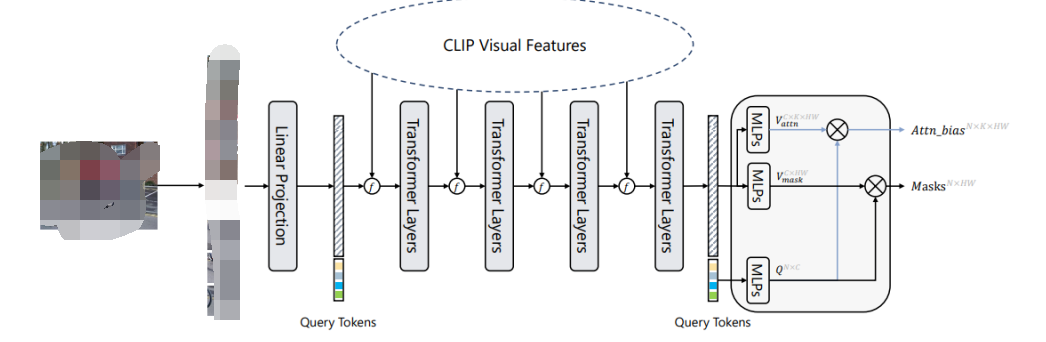 示例图片SAN的输出由两部分构成:掩膜提议(Mask Proposals)和注意力偏好(Attention Biases)。在掩膜提议中,Query Tokens和Visual Tokens首先通过两个单独的3层MLP,投影成256维,我们将投影的Query Tokens表示为 ,其中是Query Tokens的数量,投影的Visual Tokens表示为,其中和是输入图像的高度和宽度。然后,通过和的内积生成掩膜:
其中 。生成注意力偏好的过程类似于掩膜提议。Query Tokens和Visual Tokens也通过3层MLP进行投影,表示为和,其中是CLIP模型的注意头数。通过对和进行内积,我们得到注意力偏好:
其中。此外,如果需要,注意力偏好还将进一步调整为,其中和是CLIP中注意力映射的高度和宽度。在实践中,和可以共享,并且注意力偏好将应用于CLIP的多个自注意层,即偏好将在不同的自注意层中使用。这样的双输出设计的动机很直观:作者认为用于在CLIP中识别掩模的感兴趣区域可能与掩模区域本身不同。作者在后文的对比实验中也证实了这个想法。
示例图片SAN的输出由两部分构成:掩膜提议(Mask Proposals)和注意力偏好(Attention Biases)。在掩膜提议中,Query Tokens和Visual Tokens首先通过两个单独的3层MLP,投影成256维,我们将投影的Query Tokens表示为 ,其中是Query Tokens的数量,投影的Visual Tokens表示为,其中和是输入图像的高度和宽度。然后,通过和的内积生成掩膜:
其中 。生成注意力偏好的过程类似于掩膜提议。Query Tokens和Visual Tokens也通过3层MLP进行投影,表示为和,其中是CLIP模型的注意头数。通过对和进行内积,我们得到注意力偏好:
其中。此外,如果需要,注意力偏好还将进一步调整为,其中和是CLIP中注意力映射的高度和宽度。在实践中,和可以共享,并且注意力偏好将应用于CLIP的多个自注意层,即偏好将在不同的自注意层中使用。这样的双输出设计的动机很直观:作者认为用于在CLIP中识别掩模的感兴趣区域可能与掩模区域本身不同。作者在后文的对比实验中也证实了这个想法。3.2 掩膜预测
原始的CLIP模型只能通过标记进行图像级别的识别。作者工作在不改变CLIP模型参数的情况下,尝试通过指导标记的注意力图在感兴趣区域上实现精确的掩膜识别。为了实现这个目标,作者创建了一组名为标记(仿照Maskclip,如下图)。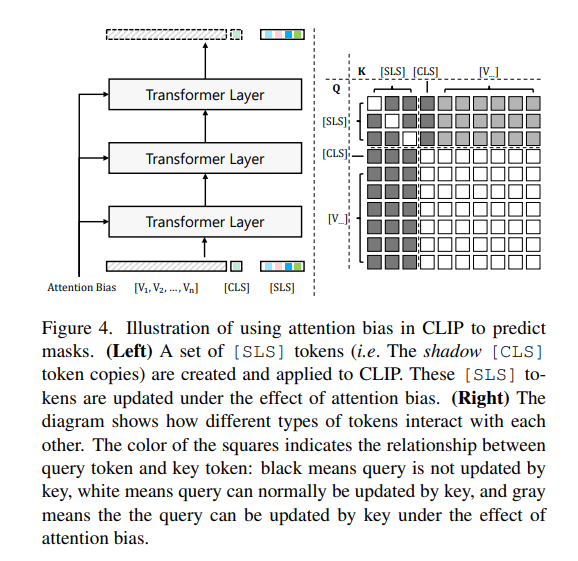 这些标记单向地通过Visual Tokens进行更新,但是Visual Tokens和标记都不受的影响。在更新标记时,预测的注意力偏差被添加到注意力矩阵中:
其中表示层编号,表示第个注意力头,和是 的Query 和Key,是Visual Tokens 的Key。,和分别是Query、Key和Value的编码权重。通过注意力偏好,标记的特征逐渐演变以适应掩膜预测,并且可以通过比较标记和类名CLIP文本编码之间的距离/相似性来轻松获得掩膜的类别预测,表示为,其中是类别数。
这些标记单向地通过Visual Tokens进行更新,但是Visual Tokens和标记都不受的影响。在更新标记时,预测的注意力偏差被添加到注意力矩阵中:
其中表示层编号,表示第个注意力头,和是 的Query 和Key,是Visual Tokens 的Key。,和分别是Query、Key和Value的编码权重。通过注意力偏好,标记的特征逐渐演变以适应掩膜预测,并且可以通过比较标记和类名CLIP文本编码之间的距离/相似性来轻松获得掩膜的类别预测,表示为,其中是类别数。3.3 分割结果生成
使用上文提到的掩膜和类别预测,我们可以计算语义分割图: 其中。这是标准的语义分割输出,因此与主流的语义分割评估兼容。在训练,我们通过Dice Loss 和binary cross-entropy loss 来监督掩膜生成,通过cross-entropy loss 来监督掩膜识别。总损失为: 其中作者使用的损失权重,,分别为5.0,5.0和2.0。通过端到端的训练,SAN可以最大程度地适应冻结的CLIP模型,并得到很好的结果。
讨论
具体来说,作者提出了一种全新的端到端架构,以极小的参数量在多个数据集上取得了SOTA效果。SAN的主要特点如下:
-
SAN中沿用了MaskCLIP得出的结论:在下游数据集上微调会破坏CLIP优秀的特征空间。因此在SAN的设计中,无需微调(fine-tune)CLIP模型,以便最大程度的保持CLIP模型的开放词汇能力。
-
在冻结CLIP模型的同时,引入了额外的可编码网络,能够根据下游任务数据集学习分割所需要的特征,弥补了CLIP模型对于位置信息的缺失。
- 将语义分割任务分解为掩膜预测与类别预测两个子任务。CLIP模型的开放识别能力不仅仅依赖于物体区域本身,也依赖于物体的上下文信息(Context Information)。这促使作者提出掩膜预测与类别预测解耦的双输出设计,下表显示该设计可以进一步提升模型的预测精度。
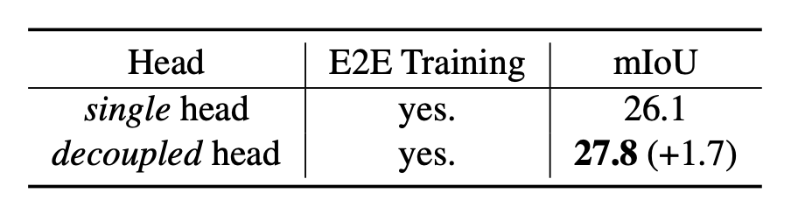
-
充分复用了CLIP模型的特征,大幅度降低所需的额外参数量的同时获得最佳性能。下表展示了复用CLIP特征带来的性能增益。
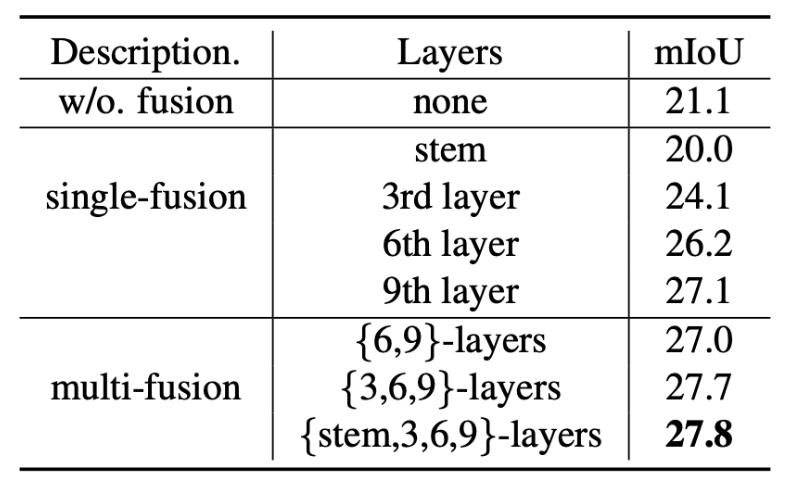
 结论作者在这项工作中提出了SAN框架,用于开放词汇语义分割。该框架成功地利用了冻结的CLIP模型的特征以及端到端的流程,并最大化地采用冻结的CLIP模型。所提出的框架在五个语义分割基准测试中显著优于以往的最先进方法,而且具有更少的可训练参数和更少的计算成本。
·
结论作者在这项工作中提出了SAN框架,用于开放词汇语义分割。该框架成功地利用了冻结的CLIP模型的特征以及端到端的流程,并最大化地采用冻结的CLIP模型。所提出的框架在五个语义分割基准测试中显著优于以往的最先进方法,而且具有更少的可训练参数和更少的计算成本。
·
原文标题:CVPR 2023 | 华科&MSRA新作:基于CLIP的轻量级开放词汇语义分割架构
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- �
-
深度剖析OpenHarmony轻量级数据存储2022-03-31 0
-
轻量级工作流引擎架构设计2011-04-12 850
-
基于MVC架构的轻量级工作流引擎设计2011-05-24 824
-
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?2018-09-17 565
-
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割2019-04-22 2883
-
CVPR2020 | 即插即用!将双边超分辨率用于语义分割网络,提升图像分辨率的有效策略2022-01-26 578
-
CVPR 2023 中的领域适应: 一种免反向传播的TTA语义分割方法2023-06-30 950
-
CVPR 2023 | 完全无监督的视频物体分割 RCF2023-07-16 593
-
介绍一种自动驾驶汽车中可行驶区域和车道分割的高效轻量级模型2023-08-03 1275
-
NeurlPS'23开源 | 首个!开放词汇3D实例分割!2023-11-14 647
-
森木磊石CPEEC&CPSSC 2023 展会圆满收官!2023-11-16 530
-
三项SOTA!MasQCLIP:开放词汇通用图像分割新网络2023-12-12 812
-
图像分割与语义分割中的CNN模型综述2024-07-09 862
-
图像语义分割的实用性是什么2024-07-17 423
-
新品 | 可拼接灯板矩阵 Puzzle Unit & 创意固定套件CLIP-A/CLIP-B2024-11-16 141
全部0条评论

快来发表一下你的评论吧 !
