

SMP是什么?多核芯片(SMP)的启动方法
电子说
描述
前言
看这篇文章,你必备的一些前置知识有如下
1、ATF启动流程 2、PSCI电源管理的概念 3、设备树
如果没有,想要我发布什么方面的内容?记得点赞、分享、评论三连。哈哈哈
昨天有个朋友在问多核启动,于是今天就整理一篇多核启动的文章,内容大多数参考与网上前辈们的优秀博客,感激。
1、SMP是什么?
SMP 英文为Symmetric Multi-Processing ,是对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构,一个服务器系统可以同时运行多个处理器,并共享内存和其他的主机资源。
CMP 英文为Chip multiprocessors,指的是单芯片多处理器,也指多核心。其思想是将大规模并行处理器中的SMP集成到同一芯片内,各个处理器并行执行不同的进程。
(1)CPU数:独立的中央处理单元,体现在主板上就是有多少个CPU槽位
(2)CPU核心数(CPU cores):在每一个CPU上,都可能有多核(core),每个核中都有独立的ALU,FPU,Cache等组件,可以理解为CPU的物理核数。(我们常说4核8线程中的核),指物理上存在的物体。
(3)CPU线程数(processor逻辑核):一种逻辑上的概念,并非真实存在的物体,只是为了更好地描述CPU的运作能力。简单地说,就是模拟出的CPU核心数。
不过在这里我们这里指的是多个单核CPU组合到一起,每个核都有自己的一套寄存器。
一个系统存在多个CPU,成本会更高和管理也更困难。多核算是轻量级的SMP,物理上多核CPU还是封装成一个CPU,但是在CPU内部具有多个CPU的核心部件,可以同时运行多个线程/进程。但是需要CPU核心之间要共享资源,比如缓存。
对程序员来说,它们之间的区别很小,大多数情况可以不做区分。我们在嵌入式开发中,大部分都是用的多核CPU。
这里我们就把这个SMP启动转换成多核CPU启动。
2、启动方式
程序为何可以在多个cpu上并发执行:他们有各自独立的一套寄存器,如:程序计数器pc,栈指针寄存器sp,通用寄存器等,可以独自 取指、译码、执行,当然内存和外设资源是共享的,多核环境下当访问临界区 资源一般 自旋锁来防止竞态发生。
soc启动的一般会从片内的rom, 也叫bootrom开始执行第一条指令,这个地址是系统默认的启动地址,会在bootrom中由芯片厂家固化一段启动代码来加载启动bootloader到片内的sram,启动完成后的bootloader除了做一些硬件初始化之外做的最重要的事情是初始化ddr,因为sram的空间比较小所以需要初始化拥有大内存 ddr,最后会从网络/usb下载 或从存储设备分区上加载内核到ddr某个地址,为内核传递参数之后,然后bootloader就完成了它的使命,跳转到内核,就进入了操作系统内核的世界。
bootloader将系统的控制权交给内核之后,他首先会进行处理器架构相关初始化部分,如设置异常向量表,初始化mmu(之后内核就从物理地址空间进入了虚拟地址空间的世界,一切是那么的虚无缥缈,又是那么的恰到好处)等等,然后会清bss段,设置sp之后跳转到C语言部分进行更加复杂通用的初始化,其中会进行内存方面的初始化,调度器初始化,文件系统等内核基础组件 初始化工作,随后会进行关键的从处理器的引导过程,然后是各种实质性的设备驱动的初始化,最后 创建系统的第一个用户进程init后进入用户空间执行用户进程宣誓内核初始化完成,可以进程正常的调度执行。
系统初始化阶段大多数都是主处理器做初始化工作,所有不用考虑处理器并发情况,一旦从处理器被bingup起来,调度器和各自的运行队列准备就绪,多个任务就会均衡到各个处理器,开始了并发的世界,一切是那么的神奇。
soc在启动阶段除了一些特殊情况外(如为了加快启动速度,在bl2阶段通过并行加载方式同时加载bl31、bl32和bl33镜像),一般都没有并行化需求。因此只需要一个cpu执行启动流程即可,这个cpu被称为primary cpu,而其它的cpu则统一被称为secondary cpu。为了防止secondary cpu在启动阶段的执行,它们在启动时必须要被设置为一个特定的状态。(有时候为了增加启动速度,必须对时间敏感的设备,就可能启动的时候整个从核并行跑一些任务)
当primary cpu完成操作系统初始化,调度系统开始工作后,就可以通过一定的机制启动secondary cpu。显然secondary cpu不再需要执行启动流程代码,而只需直接跳转到内核中执行即可。
主流程启动初始化一般来说都是主核在干的,当系统完成了初始化后就开始启动从核。 这就像在启动的大门,只有主核让你过了,其他的先在门外等着。当cpu0启动到kernel后,就会去门口,把它们的门禁卡给它们,卡上就写的它们的目的地班级是哪里。如果没有这个门禁卡的cpu,说明地址为0,就继续在原地等着。
故其启动的关键是如何将内核入口地址告知secondary cpu,以使其能跳转到正确的执行位置。
aarch64架构实现了两种不同的启动方式,spin-table和psci。
其中spin-table方式非常简单,但其只能被用于secondary cpu启动,功能比较单一。
随着aarch64架构电源管理需求的增加(如cpu热插拔、cpu idle等),arm设计了一套标准的电源管理接口协议psci。该协议可以支持所有cpu相关的电源管理接口,而且由于电源相关操作是系统的关键功能,为了防止其被攻击,该协议将底层相关的实现都放到了secure空间,从而可提高系统的安全性。
2.1 spin-table
spin-table启动流程的示意图如下:
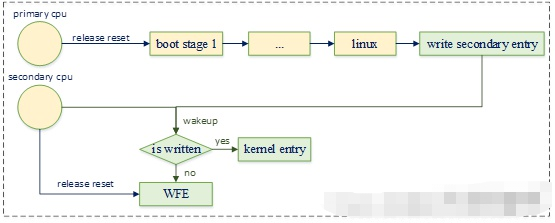 在这里插入图片描述
在这里插入图片描述
芯片上电后primary cpu开始执行启动流程,而secondary cpu则将自身设置为WFE睡眠状态,并且为内核准备了一块内存,用于填写secondary cpu的入口地址。
uboot负责将这块内存的地址写入devicetree中,当内核初始化完成,需要启动secondary cpu时,就将其内核入口地址写到那块内存中,然后唤醒cpu。
secondary cpu被唤醒后,检查该内存的内容,确认内核已经向其写入了启动地址,就跳转到该地址执行启动流程。
2.1.1 secondary cpu初始化状态设置
uboot启动时,secondary cpu会通过以下流程进入wfe状态(arch/arm/cpu/armv8/start.S):
#if defined(CONFIG_ARMV8_SPIN_TABLE) && !defined(CONFIG_SPL_BUILD) branch_if_master x0, x1, master_cpu (1) b spin_table_secondary_jump (2) … master_cpu: (3) bl _main
(1)若当前cpu为primary cpu,则跳转到step 3,继续执行启动流程。其中cpu id是通过mpidr区分的,而启动流程中哪个cpu作为primary cpu可以任意指定。当指定完成后,此处就可以根据其身份确定相应的执行流程
(2)若当前cpu为slave cpu,则执行spin流程。它是由spin_table_secondary_jump函数实现的(arch/arm/cpu/armv8/start.S)。以下为其代码实现:
ENTRY(spin_table_secondary_jump) .globl spin_table_reserve_begin spin_table_reserve_begin: 0: wfe (1) ldr x0, spin_table_cpu_release_addr (2) cbz x0, 0b (3) br x0 (4) .globl spin_table_cpu_release_addr (5) .align 3 spin_table_cpu_release_addr: .quad 0 .globl spin_table_reserve_end spin_table_reserve_end: ENDPROC(spin_table_secondary_jump)
(1)secondary cpu当前没有事情要做,因此执行wfe指令进入睡眠模式,以降低功耗
(2)spin_table_cpu_release_addr将由uboot传递给内核,根据step 5的定义可知,其长度为8个字节,在64位系统中正好可以保存一个指针。而它的内容在启动时会被初始化为0,当内核初始化完成后,在启动secondary cpu之前,会在uboot中将其入口地址写到该位置,并唤醒它
(3)当secondary cpu从wfe状态唤醒后,会校验内核是否在spin_table_cpu_release_addr处填写了它的启动入口。若未填写,则其会继续进入wfe状态
(4)若内核填入了启动地址,则其直接跳转到该地址开始执行内核初始化流程
2.1.2 spin_table_cpu_release_addr的传递
由于在armv8架构下,uboot只能通过devicetree向内核传递参数信息,因此当其开启了CONFIG_ARMV8_SPIN_TABLE配置选项后,就需要在适当的时候将该值写入devicetree中。
我们知道uboot一般通过bootm命令启动操作系统(aarch64支持的booti命令,其底层实现与bootm相同),因此在bootm中会执行一系列启动前的准备工作,其中就包括将spin-table地写入devicetree的工作。以下其执行流程图:
 在这里插入图片描述
在这里插入图片描述
spin_table_update_dt的代码实现如下:
int spin_table_update_dt(void *fdt)
{
…
unsigned long rsv_addr = (unsigned long)&spin_table_reserve_begin;
unsigned long rsv_size = &spin_table_reserve_end -
&spin_table_reserve_begin; (1)
cpus_offset = fdt_path_offset(fdt, "/cpus"); (2)
if (cpus_offset < 0)
return -ENODEV;
for (offset = fdt_first_subnode(fdt, cpus_offset);
offset >= 0;
offset = fdt_next_subnode(fdt, offset)) {
prop = fdt_getprop(fdt, offset, "device_type", NULL);
if (!prop || strcmp(prop, "cpu"))
continue;
prop = fdt_getprop(fdt, offset, "enable-method", NULL); (3)
if (!prop || strcmp(prop, "spin-table"))
return 0;
}
for (offset = fdt_first_subnode(fdt, cpus_offset);
offset >= 0;
offset = fdt_next_subnode(fdt, offset)) {
prop = fdt_getprop(fdt, offset, "device_type", NULL);
if (!prop || strcmp(prop, "cpu"))
continue;
ret = fdt_setprop_u64(fdt, offset, "cpu-release-addr",
(unsigned long)&spin_table_cpu_release_addr); (4)
if (ret)
return -ENOSPC;
}
ret = fdt_add_mem_rsv(fdt, rsv_addr, rsv_size); (5)
…
}
(1)获取其起始地址和长度
(2)从devicetree中获取cpus节点
(3)遍历该节点的所有cpu子节点,并校验其enable-method是否为spin-table。若不是所有cpu的都该类型,则不设置
(4)若所有cpu的enable-method都为spin-table,则将该参数设置到cpu-release-addr属性中
(5)由于这段地址有特殊用途,内核的内存管理系统不能将其分配给其它模块。因此,需要将其添加到保留内存中
2.1.3 启动secondary cpu
内核在启动secondary cpu之前当然需要为其准备好执行环境,因为内核中cpu最终都将由调度器管理,故此时调度子系统应该要初始化完成。
同时cpu启动完成转交给调度器之前,并没有实际的业务进程,而我们知道内核中cpu在空闲时会执行idle进程。因此,在其启动之前需要为每个cpu初始化一个idle进程。
另外,由于将一个cpu通过热插拔方式移除后,再次启动该cpu的流程,与secondary cpu的启动流程是相同的,因此内核复用了cpu hotplug框架用于启动secondary cpu。
而内核为每个cpu都分配了一个独立的hotplug线程,用于执行本cpu相关的热插拔流程。为此,内核通过以下流程执行secondary cpu启动操作:
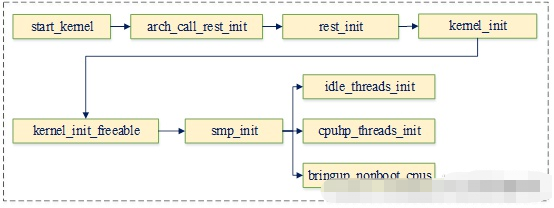 在这里插入图片描述
在这里插入图片描述
idle进程初始化
以下代码为每个非boot cpu分配一个idle进程
void __init idle_threads_init(void)
{
…
boot_cpu = smp_processor_id();
for_each_possible_cpu(cpu) { (1)
if (cpu != boot_cpu)
idle_init(cpu); (2)
}
}
(1)遍历系统中所有的possible cpu
(2)若该cpu为secondary cpu,则为其初始化一个idle进程
hotplug线程初始化
以下代码为每个cpu初始化一个hotplug线程
void __init cpuhp_threads_init(void)
{
BUG_ON(smpboot_register_percpu_thread(&cpuhp_threads));
kthread_unpark(this_cpu_read(cpuhp_state.thread));
}
其中线程的描述结构体定义如下:
static struct smp_hotplug_thread cpuhp_threads = {
.store = &cpuhp_state.thread, (1)
.create = &cpuhp_create, (2)
.thread_should_run = cpuhp_should_run, (3)
.thread_fn = cpuhp_thread_fun, (4)
.thread_comm = "cpuhp/%u", (5)
.selfparking = true, (6)
}
(1)用于保存cpu上的task struct指针
(2)线程创建时调用的回调
(3)该回调用于获取线程是否需要退出标志
(4)cpu hotplug主函数,执行实际的hotplug操作
(5)该线程的线程名
(6)用于设置线程创建完成后,是否将其设置为park状态
hotplug回调线程唤醒
内核使用以下流程唤醒特定cpu的hotplug线程,用于执行实际的cpu启动流程:
 在这里插入图片描述
在这里插入图片描述
由于cpu启动时需要与一系列模块交互以执行相应的准备工作,为此内核为其定义了一组hotplug状态,用于表示cpu在启动或关闭时分别需要执行的流程。以下为个阶段状态定义示例(由于该数组较长,故只截了一小段):
static struct cpuhp_step cpuhp_hp_states[] = {
[CPUHP_OFFLINE] = {
.name = "offline",
.startup.single = NULL,
.teardown.single = NULL,
},
…
[CPUHP_BRINGUP_CPU] = {
.name = "cpu:bringup",
.startup.single = bringup_cpu,
.teardown.single = finish_cpu,
.cant_stop = true,
}
…
[CPUHP_ONLINE] = {
.name = "online",
.startup.single = NULL,
.teardown.single = NULL,
},
}
以上每个阶段都可包含startup.single和teardown.single两个回调函数,分别表示cpu启动和关闭时需要执行的流程。其中在cpu启动时,将会从CPUHP_OFFLINE状态开始,依次执行各个阶段的startup.single回调函数。其中CPUHP_BRINGUP_CPU及之前的阶段都在secondary cpu启动之前执行。
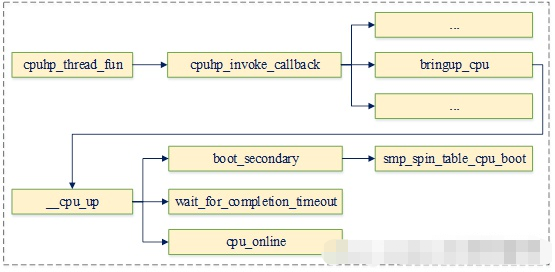
而CPUHP_BRINGUP_CPU阶段的回调函数bringup_cpu,会实际触发secondary cpu的启动流程。它将通过cpu_ops接口调用spin-table函数,启动secondary cpu,并等待其启动完成。
当secondary cpu启动完成后,将唤醒hotplug线程,其将继续执行CPUHP_BRINGUP_CPU之后阶段相关的回调函数。
cpu操作函数
cpu_ops函数由bringup_cpu调用,以触发secondary cpu启动。它是根据设备树中解析出的enable-method属性确定的。
int __init init_cpu_ops(int cpu)
{
const char *enable_method = cpu_read_enable_method(cpu); (1)
…
cpu_ops[cpu] = cpu_get_ops(enable_method); (2)
…
}
(1)获取该cpu enable-method属性的值
(2)根据其enable-method获取其对应的cpu_ops回调
其中spin-table启动方式的回调如下:
const struct cpu_operations smp_spin_table_ops = {
.name = "spin-table",
.cpu_init = smp_spin_table_cpu_init,
.cpu_prepare = smp_spin_table_cpu_prepare,
.cpu_boot = smp_spin_table_cpu_boot,
}
触发secondary cpu启动
以上流程都准备完成后,触发secondary cpu启动就非常简单了。只需调用其cpu_ops回调函数,向其对应的spin_table_cpu_release_addr位置写入secondary cpu入口地址即可。以下为其调用流程:
 在这里插入图片描述
在这里插入图片描述
其中smp_spin_table_cpu_boot的实现如下:
static int smp_spin_table_cpu_boot(unsigned int cpu)
{
write_pen_release(cpu_logical_map(cpu)); (1)
sev(); (2)
return 0;
}
(1)向给定地址写入内核entry
(2)通过sev指令唤醒secondary cpu启动
此后,该线程将等待cpu启动完成,并在完成后将其设置为online状态
secondary cpu执行流程
aarch64架构secondary cpu的内核入口函数为secondary_entry(arch/arm64/kernel/head.S),以下为其执行主流程:
 在这里插入图片描述
在这里插入图片描述
由于其底层相关初始化流程与primary cpu类似,因此此处不再介绍。我们这里主要看一下它是如何通过secondary_start_kernel启动idle线程的:
asmlinkage notrace void secondary_start_kernel(void)
{
struct mm_struct *mm = &init_mm;
…
current->active_mm = mm; (1)
cpu_uninstall_idmap(); (2)
…
ops = get_cpu_ops(cpu);
if (ops->cpu_postboot)
ops->cpu_postboot(); (3)
…
set_cpu_online(cpu, true); (4)
complete(&cpu_running); (5)
…
cpu_startup_entry(CPUHP_AP_ONLINE_IDLE); (6)
}
(1)由于内核线程并没有用于地址空间,因此其active_mm通常指向上一个用户进程的地址空间。而cpu初始化时,由于之前并没有运行过用户进程,因此将其初始化为init_mm
(2)idmap地址映射仅仅是用于mmu使能时地址空间的平滑切换,在mmu使能完成后已经没有作用。更进一步,由于idmap页表所使用的ttbr0_elx页表基地址寄存器,正常情况下是用于用户空间页表的,在调度器接管该cpu之前也必须要将其归还给用户空间
(3)执行cpu_postboot回调
(4)由secondary cpu已经启动成功,故将其设置为online状态
(5)唤醒cpu hotplug线程
(6)让cpu执行idle线程,其代码实现如下:
void cpu_startup_entry(enum cpuhp_state state)
{
arch_cpu_idle_prepare();
cpuhp_online_idle(state);
while (1)
do_idle();
}
至此,cpu已经启动完成,并开始执行idle线程了。最后当然是要通知调度器,将该cpu的管理权限移交给调度器了。它是通过cpu hotplug的以下回调实现的:
static struct cpuhp_step cpuhp_hp_states[] = {
…
[CPUHP_AP_SCHED_STARTING] = {
.name = "sched:starting",
.startup.single = sched_cpu_starting,
.teardown.single = sched_cpu_dying,
}
…
}
以下为该函数的实现:
int sched_cpu_starting(unsigned int cpu)
{
…
sched_rq_cpu_starting(cpu); (1)
sched_tick_start(cpu); (2)
…
}
(1)用于初始化负载均衡相关参数,此后该cpu就可以在其后的负载均衡流程中拉取进程
(2)tick时钟是内核调度器的脉搏,启动了该时钟之后,cpu就会在时钟中断中执行调度操作,从而让cpu参与到系统的调度流程中
到这里我们就知道了spin-table这个流程。不得不说前辈对这个逻辑理解很清楚,这个内容的参考链接在文末,欢迎大家点击原文链接点赞。
小结
整个图来看看
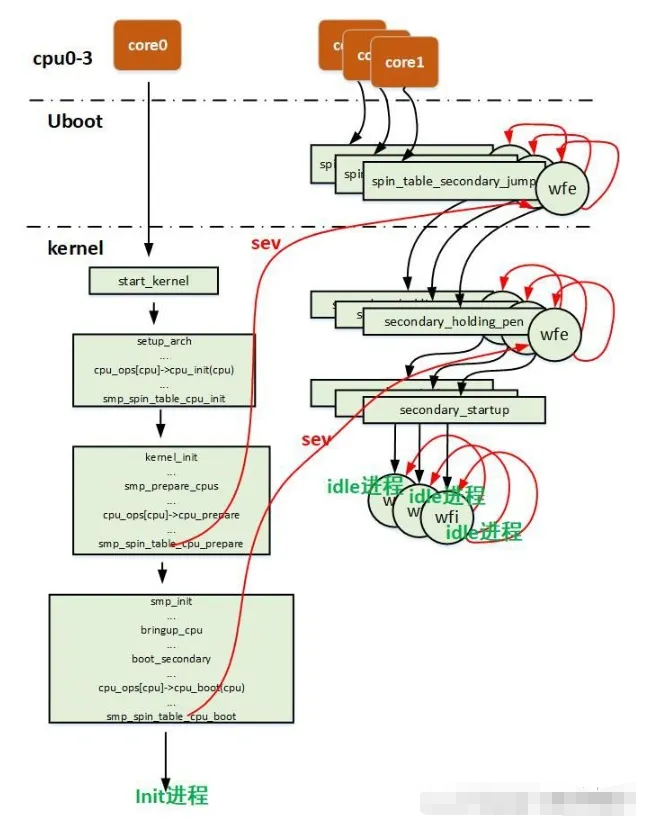 在这里插入图片描述
在这里插入图片描述
最后这里补充一下一个使用自旋表作为启动方式的平台设备树cpu节点:
arch/arm64/boot/dts/xxx.dtsi:
cpu@0 {
device_type = "cpu";
compatible = "arm,armv8";
reg = <0x0 0x000>;
enable-method = "spin-table";
cpu-release-addr = <0x1 0x0000fff8>;
};
spin-table方式的多核启动方式,顾名思义在于自旋,主处理器和从处理器上电都会启动,主处理器执行uboot畅通无阻,从处理器在spin_table_secondary_jump处wfe睡眠,主处理器通过修改设备树的cpu节点的cpu-release-addr属性为spin_table_cpu_release_addr,这是从处理器的释放地址所在的地方。
主处理器进入内核后,会通过smp_prepare_cpus函数调用spin-table 对应的cpu操作集的cpu_prepare方法从而在smp_spin_table_cpu_prepare函数中设置从处理器的释放地址为secondary_holding_pen这个内核函数,然后通过sev指令唤醒从处理器,从处理器继续从secondary_holding_pen开始执行(从处理器来到了内核的世界),发现secondary_holding_pen_release不是自己的处理编号,然后通过wfe继续睡眠。
当主处理器完成了大多数的内核组件的初始化之后,调用smp_init来来开始真正的启动从处理器,最终调用spin-table 对应的cpu操作集的cpu_boot方法从而在smp_spin_table_cpu_boot将需要启动的处理器的编号写入secondary_holding_pen_release中,然后再次sev指令唤醒从处理器,从处理器得以继续执行(设置自己异常向量表,初始化mmu等)。
最终在idle线程中执行wfi睡眠。其他从处理器也是同样的方式启动起来,同样最后进入各种idle进程执行wfi睡眠,主处理器继续往下进行内核初始化,直到启动init进程,后面多个处理器都被启动起来,都可以调度进程,多进程还会被均衡到多核。
下面介绍另外一种启动 PSCI。
2.2 psci
psci是arm提供的一套电源管理接口,当前一共包含0.1、0.2和1.0三个版本。它可被用于以下场景:(1)cpu的idle管理
(2)cpu hotplug以及secondary cpu启动
(3)系统shutdown和reset
首先,我们先来看下设备树cpu节点对psci的支持:
arch/arm64/boot/dts/xxx.dtsi:
cpu0: cpu@0 {
device_type = "cpu";
compatible = "arm,armv8";
reg = <0x0>;
enable-method = "psci";
};
psci {
compatible = "arm,psci";
method = "smc";
cpu_suspend = <0xC4000001>;
cpu_off = <0x84000002>;
cpu_on = <0xC4000003>;
};
psci节点的详细说明可以参考内核文档:Documentation/devicetree/bindings/arm/psci.txt
从这个我们可以获得什么信息呢?
可以看到现在enable-method 属性已经是psci,说明使用的多核启动方式是psci,
下面还有psci节点,用于psci驱动使用,method用于说明调用psci功能使用什么指令,可选有两个smc和hvc。
其实smc, hvc和svc都是从低运行级别向高运行级别请求服务的指令,我们最常用的就是svc指令了,这是实现系统调用的指令。
高级别的运行级别会根据传递过来的参数来决定提供什么样的服务。
smc是用于陷入el3(安全),
hvc用于陷入el2(虚拟化, 虚拟化场景中一般通过hvc指令陷入el2来请求唤醒vcpu), svc用于陷入el1(系统)。
这里只讲解smc陷入el3启动多核的情况。
2.2.1 psci 基础概念知识
下面我们将按照电源管理拓扑结构(power domain)、电源状态(power state)以及armv8安全扩展几个方面介绍psci的一些基础知识
2.2.1.1 power domain
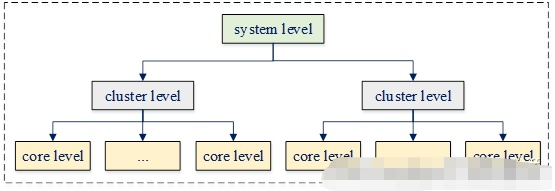
我们前面已经介绍过cpu的拓扑结构,如aarch64架构下每块soc可能会包含多个cluster,而每个cluster又包含多个core,它们共同组成了层次化的拓扑结构。如以下为一块包含2个cluster,每个cluster包含四个core的soc:
 在这里插入图片描述
在这里插入图片描述
由于其中每个core以及每个cluster的电源都可以独立地执行开关操作,因此若core0 – core3的电源都关闭了,则cluster 0的电源也可以被关闭以降低功耗。
若core0 – core3中的任一个core需要上电,则显然cluster 0需要先上电。为了更好地进行层次化电源管理,psci在电源管理流程中将以上这些组件都抽象为power domain。如以下为上例的power domain层次结构:
 在这里插入图片描述
在这里插入图片描述
其中system level用于管理整个系统的电源,cluster level用于管理某个特定cluster的电源,而core level用于管理一个单独core的电源。
2.2.1.2 power state
由于aarch64架构有多种不用的电源状态,不同电源状态的功耗和唤醒延迟不同。
如standby状态会关闭power domain的clock,但并不关闭电源。因此它虽然消除了门威廉希尔官方网站 翻转引起的动态功耗,但依然存在漏电流等引起的静态功耗。故其功耗相对较大,但相应地唤醒延迟就比较低。
而对于power down状态,会断开对应power domain的电源,因此其不仅消除了动态功耗,还消除了静态功耗,相应地其唤醒延迟就比较高了。
psci一共为power domain定义了四种power state:
• (1)run:电源和时钟都打开,该domain正常工作
• (2)standby:关闭时钟,但电源处于打开状态。其寄存器状态得到保存,打开时钟后就可继续运行。功耗相对较大,但唤醒延迟较低。arm执行wfi或wfe指令会进入该状态。
• (3)retention:它将core的状态,包括调试设置都保存在低功耗结构中,并使其部分关闭。其状态在从低功耗变为运行时能自动恢复。从操作系统角度看,除了进入方法、延迟等有区别外,其它都与standby相同。它的功耗和唤醒延迟都介于standby和power down之间。
• (4)power down:关闭时钟和电源。power domain掉电后,所有状态都丢失,上电以后软件必须重新恢复其状态。它的功耗最低,但唤醒延迟也相应地最高。
(这里我很好奇怎么和linux的s3、s4对应的。当时测试s3的时候,对应的是suspend。这里的对于cpu的有off、on、suspend三种,我觉得这里应该就是对于的standby,因为有wfi或wfe这些指令。那s4就是CPU off了?可以看一下这个有点认识,突然想到psci里面的状态是对于的cpu为对象,但是linux的电源管理应该是对整个设备。)
可以看一下这个文章: s1s2s3S4S5的含义待机、休眠、睡眠的区别
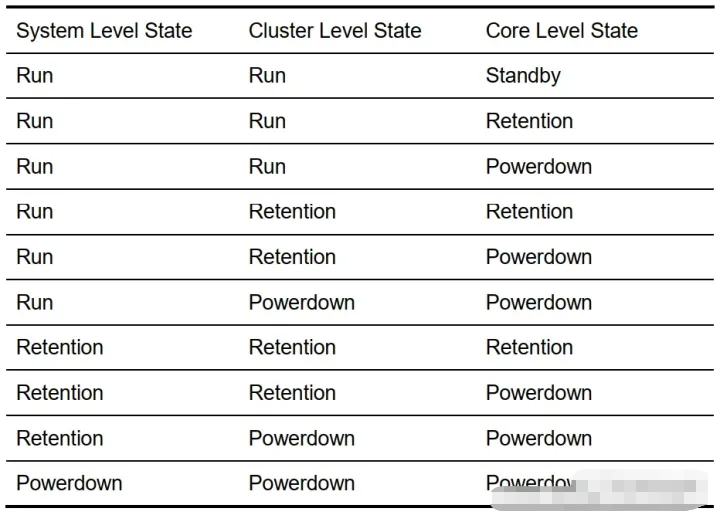
显然,power state的睡眠程度从run到power down逐步加深。而高层级power domain的power state不应低于低层级power domain。
如以上例子中core 0 – core 2都为power down状态,而core 3为standby状态,则cluster 0不能为retention或power down状态。同样若cluster 0为standby状态,而cluster 1为run状态,则整个系统必须为run状态。
为了达到上述约束,不同power domain之间的power state具有以下关系:
 在这里插入图片描述
在这里插入图片描述
这里解释了psci那个源码文档里电源树的概念。
psci实现了父leve与子level之间的电源关系协调,如cluster 0中最后一个core被设置为power down状态后,psci就会将该cluster也设置为power donw状态。若其某一个core被设置为run状态,则psci会先将其对应cluster的状态设置为run,然后再设置对应core的电源状态,这也是psci名字的由来(power state coordinate interface)
2.2.1.3 armv8的安全扩展
为了增强arm架构的安全性,aarch64一共实现了secure和non-secure两种安全状态。通过一系列硬件扩展,在cpu执行状态、总线、内存、外设、中断、tlb、cache等方面都实现了两种状态之间的隔离。
在这种机制下,secure空间的程序可以访问所有secure和non-secure的资源,而non-secure空间的程序只能访问non-secure资源,却不能访问secure资源。从而可以将一些安全关键的资源放到secure空间,以增强其安全性。
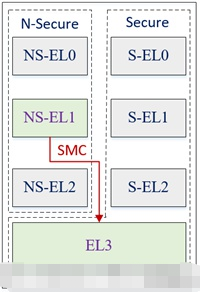
为此aarch64实现了4个异常等级,其中EL3工作在secure空间,而EL0 – EL2既可以工作于secure空间,又可以工作于non-secure空间。不同异常等级及不同secure状态的模式下可运行不同类型软件。
如secure EL1和El0用于运行trust os内核及其用户态程序,non-secure EL1和El0用于运行普通操作系统内核(如linux)及其用户态程序,EL2用于运行虚拟机的hypervisor。而EL3运行secure monitor程序(通常为bl31),其功能为执行secure和non secure状态切换、消息转发以及提供类似psci等secure空间服务。以下为其示意图:
 在这里插入图片描述
在这里插入图片描述
psci是工作于non secure EL1(linux内核)和EL3(bl31)之间的一组电源管理接口,其目的是让linux实现具体的电源管理策略,而由bl31管理底层硬件相关的操作。从而将cpu电源控制这种影响系统安全的控制权限放到安全等级更高的层级中,从而提升系统的整体安全性。
那么psci如何从EL1调用EL3的服务呢?其实它和系统调用是类似的,只是系统调用是用户态程序陷入操作系统内核,而psci是从操作系统内核陷入secure monitor。armv8提供了一条smc异常指令,内核只需要提供合适的参数后,触发该指令即可通过异常的方式进入secure monitor。(SMC调用,这个在ATF专栏有介绍)
2.2.2 psci软件架构
由于psci是由linux内核调用bl31中的安全服务,实现cpu电源管理功能的。因此其软件架构包含三个部分:(1)内核与bl31之间的调用接口规范
(2)内核中的架构
(3)bl31中的架构
2.2.3 psci接口规范
psci规定了linux内核调用bl31中电源管理相关服务的接口规范,它包含实现以下功能所需的接口:(1)cpu idle管理
(2)向系统动态添加或从系统动态移除cpu,通常称为hotplug
(3)secondary cpu启动
(4)系统的shutdown和reset
psci接口规定了命令对应的function_id、接口的输入参数以及返回值。其中输入参数可通过x0 – x7寄存器传递,而返回值通过x0 – x4寄存器传递。
如secondary cpu启动或cpu hotplug时可调用cpu_on接口,为一个cpu执行上电操作。该接口的格式如下:(1)function_id:0xc400 0003
(2)输入参数:使用mpidr值表示的target cpu id
cpu启动入口的物理地址
context id,该值用于表示本次调用上下文相关的信息
(3)返回值:可以为success、invalid_parameter、invalid_address、already_on、on_pending或internal_failure
有了以下这些接口的详细定义,内核和bl31就只需按照该接口的规定,独立开发psci相关功能。从而避免了它们之间的耦合,简化了开发复杂度。
2.2.4 内核中的psci架构
内核psci软件架构包含psci驱动和每个cpu的cpu_ops回调函数实现两部分。
其中psci驱动实现了驱动初始化和psci相关接口实现功能,而cpu_ops回调函数最终也会调用psci驱动的接口。
2.2.4.1 psci驱动
首先我们看一下devicetree中的配置:
psci {
compatible = "arm,psci-0.2"; (1)
method = "smc"; (2)
}
(1)用于指定psci版本
(2)根据该psci由bl31处理还是hypervisor处理,可以指定其对应的陷入方式。若由bl31处理为smc,若由hypervisor处理则为hvc
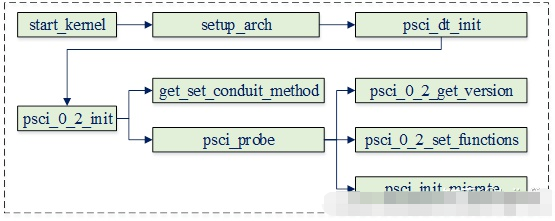
驱动流程主要是与bl31通信,以确认其是否支持给定的psci版本,以及相关psci操作函数的实现,其流程如下:
 在这里插入图片描述
在这里插入图片描述
其主要工作即为psci设置相关的回调函数,该函数定义如下:
static void __init psci_0_2_set_functions(void)
{
…
psci_ops = (struct psci_operations){
.get_version = psci_0_2_get_version,
.cpu_suspend = psci_0_2_cpu_suspend,
.cpu_off = psci_0_2_cpu_off,
.cpu_on = psci_0_2_cpu_on,
.migrate = psci_0_2_migrate,
.affinity_info = psci_affinity_info,
.migrate_info_type = psci_migrate_info_type,
}; (1)
register_restart_handler(&psci_sys_reset_nb); (2)
pm_power_off = psci_sys_poweroff; (3)
}
(1)为psci_ops设置相应的回调函数
(2)为psci模块设置系统重启时的通知函数
(3)将系统的power_off函数指向相应的psci接口
2.2.4.2 cpu_ops接口
驱动初始化完成后,cpu的cpu_ops就可以调用这些回调实现psci功能的调用。如下所示,当devicetree中cpu的enable-method设置为psci时,该cpu的cpu_ops将指向cpu_psci_ops。
cpu0: cpu@0 {
...
enable-method = "psci";
…
}
其中cpu_psci_ops的定义如下:
const struct cpu_operations cpu_psci_ops = {
.name = "psci",
.cpu_init = cpu_psci_cpu_init,
.cpu_prepare = cpu_psci_cpu_prepare,
.cpu_boot = cpu_psci_cpu_boot,
#ifdef CONFIG_HOTPLUG_CPU
.cpu_can_disable = cpu_psci_cpu_can_disable,
.cpu_disable = cpu_psci_cpu_disable,
.cpu_die = cpu_psci_cpu_die,
.cpu_kill = cpu_psci_cpu_kill,
#endif
}
如启动cpu的接口为cpu_psci_cpu_boot,它会通过以下流程最终调用psci驱动中的psci_ops函数:
static int cpu_psci_cpu_boot(unsigned int cpu)
{
phys_addr_t pa_secondary_entry = __pa_symbol(function_nocfi(secondary_entry));
int err = psci_ops.cpu_on(cpu_logical_map(cpu), pa_secondary_entry);
if (err)
pr_err("failed to boot CPU%d (%d)
", cpu, err);
return err;
}
2.2.5 bl31中的psci架构
bl31为内核提供了一系列运行时服务,psci作为其标准运行时服务的一部分,通过宏DECLARE_RT_SVC注册到系统中。其相应的定义如下:
DECLARE_RT_SVC( std_svc, OEN_STD_START, OEN_STD_END, SMC_TYPE_FAST, std_svc_setup, std_svc_smc_handler )
其中std_svc_setup会在bl31启动流程中被调用,以用于初始化该服务相关的配置。而std_svc_smc_handler为其smc异常处理函数,当内核通过psci接口调用相关服务时,最终将由该函数执行实际的处理流程。
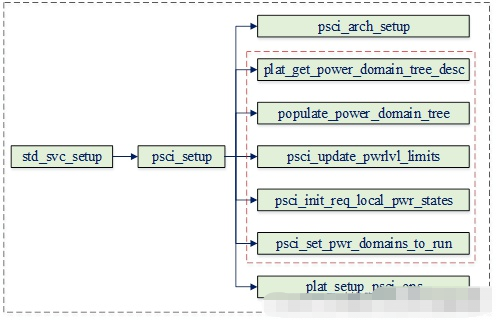 在这里插入图片描述
在这里插入图片描述
上图为psci初始化相关的流程,它主要包含内容:(1)前面我们已经介绍过power domain相关的背景,即psci需要协调不同层级的power domain状态,因此其必须要了解系统的power domain配置情况。以上流程中红色虚线框的部分主要就是用于初始化系统的power domain拓扑及其状态
(2)由于psci在执行电源相关接口时,最终需要操作实际的硬件。而它们是与架构相关的,因此其操作函数最终需要注册到平台相关的回调中。plat_setup_psci_ops即用于注册特定平台的psci_ops回调,其格式如下:
typedef struct plat_psci_ops {
void (*cpu_standby)(plat_local_state_t cpu_state);
int (*pwr_domain_on)(u_register_t mpidr);
void (*pwr_domain_off)(const psci_power_state_t *target_state);
void (*pwr_domain_suspend_pwrdown_early)(
const psci_power_state_t *target_state);
void (*pwr_domain_suspend)(const psci_power_state_t *target_state);
void (*pwr_domain_on_finish)(const psci_power_state_t *target_state);
void (*pwr_domain_on_finish_late)(
const psci_power_state_t *target_state);
void (*pwr_domain_suspend_finish)(
const psci_power_state_t *target_state);
void __dead2 (*pwr_domain_pwr_down_wfi)(
const psci_power_state_t *target_state);
void __dead2 (*system_off)(void);
void __dead2 (*system_reset)(void);
int (*validate_power_state)(unsigned int power_state,
psci_power_state_t *req_state);
int (*validate_ns_entrypoint)(uintptr_t ns_entrypoint);
void (*get_sys_suspend_power_state)(
psci_power_state_t *req_state);
int (*get_pwr_lvl_state_idx)(plat_local_state_t pwr_domain_state,
int pwrlvl);
int (*translate_power_state_by_mpidr)(u_register_t mpidr,
unsigned int power_state,
psci_power_state_t *output_state);
int (*get_node_hw_state)(u_register_t mpidr, unsigned int power_level);
int (*mem_protect_chk)(uintptr_t base, u_register_t length);
int (*read_mem_protect)(int *val);
int (*write_mem_protect)(int val);
int (*system_reset2)(int is_vendor,
int reset_type, u_register_t cookie);
}
最后我们再看一下psci操作相应的异常处理流程:
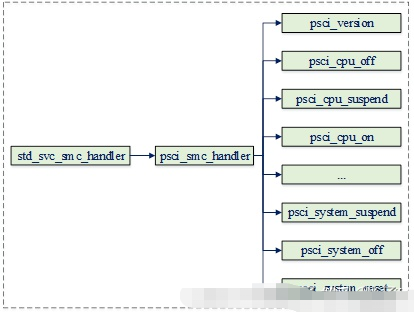 在这里插入图片描述
在这里插入图片描述
即其会根据function id的值,分别执行相应的电源管理服务,如启动cpu时会调用psci_cpu_on函数,重启系统时会调用psci_system_rest函数等。
2.2.6 secondary cpu启动
由于psci方式启动secondary cpu的流程,除了其所执行的cpu_ops不同之外,其它流程与spin-table方式是相同的,因此我们这里只给出执行流程图,详细分析可以参考上篇博文。其中以下流程执行secondary cpu启动相关的一些初始化工作:
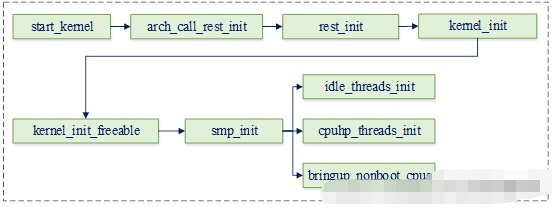 在这里插入图片描述
在这里插入图片描述
在初始化完成且hotplug线程创建完成后,就可通过以下流程唤醒cpu hotplug线程:
 在这里插入图片描述
在这里插入图片描述
此后hotplug线程将调用psci回调函数,并最终触发smc异常进入bl31:
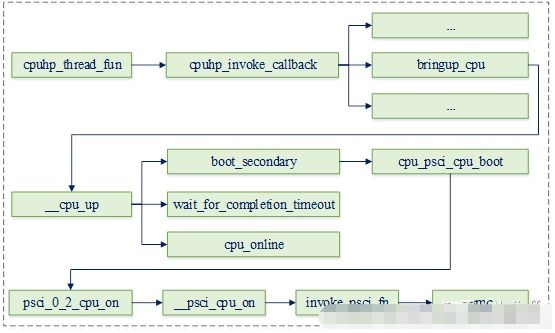 在这里插入图片描述
在这里插入图片描述
bl31接收到该异常后执行std_svc_smc_handler处理函数,并最终调用平台相关的电源管理接口,完成cpu的上电工作,以下为其执行流程:
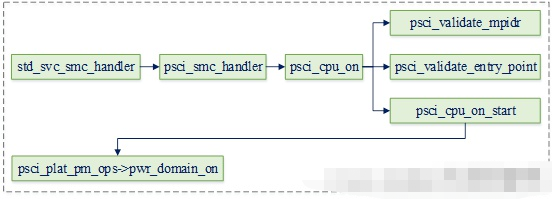 在这里插入图片描述
在这里插入图片描述
平台相关回调函数pwr_domain_on将为secondary cpu设置入口函数,然后为其上电使该cpu跳转到内核入口secondary_entry处开始执行。以下为其内核启动流程:
 在这里插入图片描述
在这里插入图片描述
到这里其实就结束了,不得不说这个前辈的文章是真的写的逻辑清晰,收获颇多。
小结
最后结合代码再走一遍
1、std_svc_setup (主要关注设置psci操作集)--有服务
std_svc_setup //services/std_svc/std_svc_setup.c
->psci_setup //lib/psci/psci_setup.c
->plat_setup_psci_ops //设置平台的psci操作 调用平台的plat_setup_psci_ops函数去设置psci操作 eg:qemu平台
->*psci_ops = &plat_qemu_psci_pm_ops;
208 static const plat_psci_ops_t plat_qemu_psci_pm_ops = {
209 .cpu_standby = qemu_cpu_standby,
210 .pwr_domain_on = qemu_pwr_domain_on,
211 .pwr_domain_off = qemu_pwr_domain_off,
212 .pwr_domain_suspend = qemu_pwr_domain_suspend,
213 .pwr_domain_on_finish = qemu_pwr_domain_on_finish,
214 .pwr_domain_suspend_finish = qemu_pwr_domain_suspend_finish,
215 .system_off = qemu_system_off,
216 .system_reset = qemu_system_reset,
217 .validate_power_state = qemu_validate_power_state,
218 .validate_ns_entrypoint = qemu_validate_ns_entrypoint
219 };
在遍历每一个注册的运行时服务的时候,会导致std_svc_setup调用,其中会做psci操作集的设置,操作集中我们可以看到对核电源的管理的接口如:核上电,下电,挂起等,我们主要关注上电 .pwr_domain_on = qemu_pwr_domain_on,这个接口当我们主处理器boot从处理器的时候会用到。
2、运行时服务触发和处理--来请求
smc指令触发进入el3异常向量表:
runtime_exceptions //el3的异常向量表 ->sync_exception_aarch64 ->handle_sync_exception ->smc_handler64 -> ¦* Populate the parameters for the SMC handler. ¦* We already have x0-x4 in place. x5 will point to a cookie (not used ¦* now). x6 will point to the context structure (SP_EL3) and x7 will ¦* contain flags we need to pass to the handler Hence save x5-x7. ¦* ¦* Note: x4 only needs to be preserved for AArch32 callers but we do it ¦* for AArch64 callers as well for convenience ¦*/ stp x4, x5, [sp, #CTX_GPREGS_OFFSET + CTX_GPREG_X4] //保存x4-x7到栈 stp x6, x7, [sp, #CTX_GPREGS_OFFSET + CTX_GPREG_X6] /* Save rest of the gpregs and sp_el0*/ save_x18_to_x29_sp_el0 mov x5, xzr //x5清零 mov x6, sp //sp保存在x6 /* Get the unique owning entity number */ //获得唯一的入口编号 ubfx x16, x0, #FUNCID_OEN_SHIFT, #FUNCID_OEN_WIDTH ubfx x15, x0, #FUNCID_TYPE_SHIFT, #FUNCID_TYPE_WIDTH orr x16, x16, x15, lsl #FUNCID_OEN_WIDTH adr x11, (__RT_SVC_DESCS_START__ + RT_SVC_DESC_HANDLE) /* Load descriptor index from array of indices */ adr x14, rt_svc_descs_indices //获得服务描述 标识数组 ldrb w15, [x14, x16] //根据唯一的入口编号 找到处理函数的 地址 /* ¦* Restore the saved C runtime stack value which will become the new ¦* SP_EL0 i.e. EL3 runtime stack. It was saved in the 'cpu_context' ¦* structure prior to the last ERET from EL3. ¦*/ ldr x12, [x6, #CTX_EL3STATE_OFFSET + CTX_RUNTIME_SP] /* ¦* Any index greater than 127 is invalid. Check bit 7 for ¦* a valid index ¦*/ tbnz w15, 7, smc_unknown /* Switch to SP_EL0 */ msr spsel, #0 /* ¦* Get the descriptor using the index ¦* x11 = (base + off), x15 = index ¦* ¦* handler = (base + off) + (index << log2(size)) ¦*/ lsl w10, w15, #RT_SVC_SIZE_LOG2 ldr x15, [x11, w10, uxtw] /* ¦* Save the SPSR_EL3, ELR_EL3, & SCR_EL3 in case there is a world ¦* switch during SMC handling. ¦* TODO: Revisit if all system registers can be saved later. ¦*/ mrs x16, spsr_el3 //spsr_el3保存在x16 mrs x17, elr_el3 //elr_el3保存在x17 mrs x18, scr_el3 //scr_el3保存在x18 stp x16, x17, [x6, #CTX_EL3STATE_OFFSET + CTX_SPSR_EL3] / x16, x17/保存在栈 str x18, [x6, #CTX_EL3STATE_OFFSET + CTX_SCR_EL3] //x18保存到栈 /* Copy SCR_EL3.NS bit to the flag to indicate caller's security */ bfi x7, x18, #0, #1 mov sp, x12 /* ¦* Call the Secure Monitor Call handler and then drop directly into ¦* el3_exit() which will program any remaining architectural state ¦* prior to issuing the ERET to the desired lower EL. ¦*/ #if DEBUG cbz x15, rt_svc_fw_critical_error #endif blr x15 //跳转到处理函数 b el3_exit //从el3退出 会eret 回到el1 (后面会讲到)
3、找到对应handler--请求匹配处理函数
上面其实主要的是找到服务例程,然后跳转执行 下面是跳转的处理函数:
std_svc_smc_handler //services/std_svc/std_svc_setup.c
->ret = psci_smc_handler(smc_fid, x1, x2, x3, x4,
¦ cookie, handle, flags)
...
480 } else {
481 /* 64-bit PSCI function */
482
483 switch (smc_fid) {
484 case PSCI_CPU_SUSPEND_AARCH64:
485 ret = (u_register_t)
486 psci_cpu_suspend((unsigned int)x1, x2, x3);
487 break;
488
489 case PSCI_CPU_ON_AARCH64:
490 ret = (u_register_t)psci_cpu_on(x1, x2, x3);
491 break;
492
...
}
4、处理函数干活
处理函数根据funid来决定服务,可以看到PSCI_CPU_ON_AARCH64为0xc4000003,这正是设备树中填写的cpu_on属性的id,会委托psci_cpu_on来执行核上电任务。下面分析是重点:!!!
->psci_cpu_on() //lib/psci/psci_main.c ->psci_validate_entry_point() //验证入口地址有效性并 保存入口点到一个结构ep中 ->psci_cpu_on_start(target_cpu, &ep) //ep入口地址 ->psci_plat_pm_ops->pwr_domain_on(target_cpu) ->qemu_pwr_domain_on //实现核上电(平台实现) /* Store the re-entry information for the non-secure world. */ ->cm_init_context_by_index() //重点: 会通过cpu的编号找到 cpu上下文(cpu_context_t),存在cpu寄存器的值,异常返回的时候写写到对应的寄存器中,然后eret,旧返回到了el1!!! ->cm_setup_context() //设置cpu上下文 -> write_ctx_reg(state, CTX_SCR_EL3, scr_el3); //lib/el3_runtime/aarch64/context_mgmt.c write_ctx_reg(state, CTX_ELR_EL3, ep->pc); //注: 异常返回时执行此地址 于是完成了cpu的启动!!! write_ctx_reg(state, CTX_SPSR_EL3, ep->spsr);
psci_cpu_on主要完成开核的工作,然后会设置一些异常返回后寄存器的值(eg:从el1 -> el3 -> el1),重点关注 ep->pc写到cpu_context结构的CTX_ELR_EL3偏移处(从处理器启动后会从这个地址取指执行)。
实际上,所有的从处理器启动后都会从bl31_warm_entrypoint开始执行,在plat_setup_psci_ops中会设置(每个平台都有自己的启动地址寄存器,通过写这个寄存器来获得上电后执行的指令地址)。
大致说一下:主处理器通过smc进入el3请求开核服务,atf中会响应这种请求,通过平台的开核操作来启动从处理器并且设置从处理的一些寄存器eg:scr_el3、spsr_el3、elr_el3,然后主处理器,恢复现场,eret再次回到el1,
而处理器开核之后会从bl31_warm_entrypoint开始执行,最后通过el3_exit返回到el1的elr_el3设置的地址。
分析到这atf的分析到此为止,atf中主要是响应内核的snc的请求,然后做开核处理,也就是实际的开核动作,但是从处理器最后还是要回到内核中执行,下面分析内核的处理:注意流程如下:
5、开核返回-EL1 启动从处理器
init/main.c start_kernel ->boot_cpu_init //引导cpu初始化 设置引导cpu的位掩码 online active present possible都为true ->setup_arch // arch/arm64/kernel/setup.c -> if (acpi_disabled) //不支持acpi psci_dt_init(); //drivers/firmware/psci.c(psci主要文件) psci初始化 解析设备树 寻找psci匹配的节点 else psci_acpi_init(); //acpi中允许使用psci情况 ->rest_init ->kernel_init ->kernel_init_freeable ->smp_prepare_cpus //准备cpu 对于每个可能的cpu 1. cpu_ops[cpu]->cpu_prepare(cpu) 2.set_cpu_present(cpu, true) cpu处于present状态 ->do_pre_smp_initcalls //多核启动之前的调用initcall回调 ->smp_init //smp初始化 kernel/smp.c 会启动其他从处理器
我们主要关注两个函数:psci_dt_init和smp_init psci_dt_init是解析设备树,设置操作函数,smp_init用于启动从处理器。
->psci_dt_init() //drivers/firmware/psci.c:
->init_fn()
->psci_0_1_init() //设备树中compatible = "arm,psci"为例
->get_set_conduit_method() //根据设备树method属性设置 invoke_psci_fn = __invoke_psci_fn_smc; (method="smc")
-> invoke_psci_fn = __invoke_psci_fn_smc
-> if (!of_property_read_u32(np, "cpu_on", &id)) {
651 psci_function_id[PSCI_FN_CPU_ON] = id;
652 psci_ops.cpu_on = psci_cpu_on; //设置psci操作的开核接口
653 }
->psci_cpu_on()
->invoke_psci_fn()
->__invoke_psci_fn_smc()
-> arm_smccc_smc(function_id, arg0, arg1, arg2, 0, 0, 0, 0, &res) //这个时候x0=function_id x1=arg0, x2=arg1, x3arg2,...
->__arm_smccc_smc()
->SMCCC smc //arch/arm64/kernel/smccc-call.S
-> 20 .macro SMCCC instr
21 .cfi_startproc
22 instr #0 //即是smc #0 陷入到el3
23 ldr x4, [sp]
24 stp x0, x1, [x4, #ARM_SMCCC_RES_X0_OFFS]
25 stp x2, x3, [x4, #ARM_SMCCC_RES_X2_OFFS]
26 ldr x4, [sp, #8]
27 cbz x4, 1f /* no quirk structure */
28 ldr x9, [x4, #ARM_SMCCC_QUIRK_ID_OFFS]
29 cmp x9, #ARM_SMCCC_QUIRK_QCOM_A6
30 b.ne 1f
31 str x6, [x4, ARM_SMCCC_QUIRK_STATE_OFFS]
32 1: ret
33 .cfi_endproc
34 .endm
最终通过22行 陷入了el3中。(这是因为安全所以还需要到ATF中启动) smp_init函数做从处理器启动:
start_kernel
->arch_call_rest_init
->rest_init
->kernel_init,
->kernel_init_freeable
->smp_prepare_cpus //arch/arm64/kernel/smp.c
->smp_init //kernel/smp.c (这是从处理器启动的函数)
->cpu_up
->do_cpu_up
->_cpu_up
->cpuhp_up_callbacks
->cpuhp_invoke_callback
->cpuhp_hp_states[CPUHP_BRINGUP_CPU]
->bringup_cpu
->__cpu_up //arch/arm64/kernel/smp.c
->boot_secondary
->cpu_ops[cpu]->cpu_boot(cpu)
->cpu_psci_ops.cpu_boot
->cpu_psci_cpu_boot //arch/arm64/kernel/psci.c
46 static int cpu_psci_cpu_boot(unsigned int cpu)
47 {
48 int err = psci_ops.cpu_on(cpu_logical_map(cpu), __pa_symbol(secondary_entry));
49 if (err)
50 pr_err("failed to boot CPU%d (%d)
", cpu, err);
51
52 return err;
53 }
启动从处理的时候最终调用到psci的cpu操作集的cpu_psci_cpu_boot函数,会调用上面的psci_cpu_on,最终调用smc,传递第一个参数为cpu的id标识启动哪个cpu,第二个参数为从处理器启动后进入内核执行的地址secondary_entry(这是个物理地址)。
所以综上,最后smc调用时传递的参数为arm_smccc_smc(0xC4000003, cpuid, secondary_entry, arg2, 0, 0, 0, 0, &res)。这样陷入el3之后,就可以启动对应的从处理器,最终从处理器回到内核(el3->el1),执行secondary_entry处指令,从处理器启动完成。
可以发现psci的方式启动从处理器的方式相当复杂,这里面涉及到了el1到安全的el3的跳转,而且涉及到大量的函数回调,很容易绕晕。
(其实为了安全,所以启动从核开核这个操作必须在EL3,开了以后,就可以会EL1,因为已经在EL3给你了准确安全的启动位置了。)
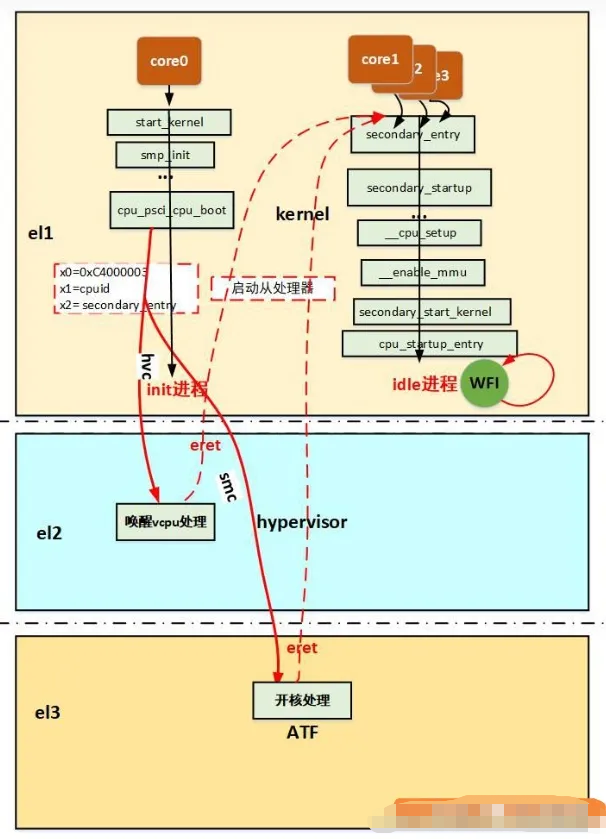 在这里插入图片描述
在这里插入图片描述
6、从处理器启动EL1做了什么?
其实这里就和spin-table比较相似了
无论是spin-table还是psci,从处理器启动进入内核之后都会执行secondary_startup:
719 secondary_startup: 720 /* 721 ¦* Common entry point for secondary CPUs. 722 ¦*/ 723 bl __cpu_secondary_check52bitva 724 bl __cpu_setup // initialise processor 725 adrp x1, swapper_pg_dir //设置内核主页表 726 bl __enable_mmu //使能mmu 727 ldr x8, =__secondary_switched 728 br x8 729 ENDPROC(secondary_startup) || / 731 __secondary_switched: --732 adr_l x5, vectors //设置从处理器的异常向量表 --733 msr vbar_el1, x5 --734 isb //指令同步屏障 保证屏障前面的指令执行完 735 --736 adr_l x0, secondary_data //获得主处理器传递过来的从处理器数据 --737 ldr x1, [x0, #CPU_BOOT_STACK] // get secondary_data.stack 获得栈地址 738 mov sp, x1 //设置到从处理器的sp --739 ldr x2, [x0, #CPU_BOOT_TASK] //获得从处理器的tsk idle进程的tsk结构, --740 msr sp_el0, x2 //保存在sp_el0 arm64使用sp_el0保存当前进程的tsk结构 741 mov x29, #0 //fp清0 742 mov x30, #0 //lr清0 --743 b secondary_start_kernel //跳转到c程序 继续执行从处理器初始化 744 ENDPROC(__secondary_switched)
__cpu_up中设置了secondary_data结构中的一些成员:
arch/arm64/kernel/smp.c:
112 int __cpu_up(unsigned int cpu, struct task_struct *idle)
113 {
114 int ret;
115 long status;
116
117 /*
118 ¦* We need to tell the secondary core where to find its stack and the
119 ¦* page tables.
120 ¦*/
121 secondary_data.task = idle; //执行的进程描述符
122 secondary_data.stack = task_stack_page(idle) + THREAD_SIZE; //栈地址 THREAD_SIZE=16k
123 update_cpu_boot_status(CPU_MMU_OFF);
124 __flush_dcache_area(&secondary_data, sizeof(secondary_data));
125
126 /*
127 ¦* Now bring the CPU into our world.
128 ¦*/
129 ret = boot_secondary(cpu, idle);
跳转到secondary_start_kernel这个C函数继续执行初始化:
183 /*
184 * This is the secondary CPU boot entry. We're using this CPUs
185 * idle thread stack, but a set of temporary page tables.
186 */
187 asmlinkage notrace void secondary_start_kernel(void)
188 {
189 u64 mpidr = read_cpuid_mpidr() & MPIDR_HWID_BITMASK;
190 struct mm_struct *mm = &init_mm;
191 unsigned int cpu;
192
193 cpu = task_cpu(current);
194 set_my_cpu_offset(per_cpu_offset(cpu));
195
196 /*
197 ¦* All kernel threads share the same mm context; grab a
198 ¦* reference and switch to it.
199 ¦*/
200 mmgrab(mm); //init_mm的引用计数加1
201 current->active_mm = mm; //设置idle借用的mm结构
202
203 /*
204 ¦* TTBR0 is only used for the identity mapping at this stage. Make it
205 ¦* point to zero page to avoid speculatively fetching new entries.
206 ¦*/
207 cpu_uninstall_idmap();
208
209 preempt_disable(); //禁止内核抢占
210 trace_hardirqs_off();
211
212 /*
213 ¦* If the system has established the capabilities, make sure
214 ¦* this CPU ticks all of those. If it doesn't, the CPU will
215 ¦* fail to come online.
216 ¦*/
217 check_local_cpu_capabilities();
218
219 if (cpu_ops[cpu]->cpu_postboot)
220 cpu_ops[cpu]->cpu_postboot();
221
222 /*
223 ¦* Log the CPU info before it is marked online and might get read.
224 ¦*/
225 cpuinfo_store_cpu(); //存储cpu信息
226
227 /*
228 ¦* Enable GIC and timers.
229 ¦*/
230 notify_cpu_starting(cpu); //使能gic和timer
231
232 store_cpu_topology(cpu); //保存cpu拓扑
233 numa_add_cpu(cpu); ///numa添加cpu
234
235 /*
236 ¦* OK, now it's safe to let the boot CPU continue. Wait for
237 ¦* the CPU migration code to notice that the CPU is online
238 ¦* before we continue.
239 ¦*/
240 pr_info("CPU%u: Booted secondary processor 0x%010lx [0x%08x]
",
241 ¦cpu, (unsigned long)mpidr,
242 ¦read_cpuid_id()); //打印内核log
243 update_cpu_boot_status(CPU_BOOT_SUCCESS);
244 set_cpu_online(cpu, true); //设置cpu状态为online
245 complete(&cpu_running); //唤醒主处理器的 完成等待函数,继续启动下一个从处理器
246
247 local_daif_restore(DAIF_PROCCTX); //从处理器继续往下执行
248
249 /*
250 ¦* OK, it's off to the idle thread for us
251 ¦*/
252 cpu_startup_entry(CPUHP_AP_ONLINE_IDLE); //idle进程进入idle状态
253 }
实际上,可以看的当从处理器启动到内核的时候,他们也需要设置异常向量表,设置mmu等,然后执行各自的idle进程(这些都是一些处理器强相关的初始化代码,一些通用的初始化都已经被主处理器初始化完),当cpu负载均衡的时候会放置一些进程到这些从处理器,然后进程就可以再这些从处理器上欢快的运行。
写到这里,关于arm64平台的多核启动已经介绍完成,可以发现里面还是会涉及到很多细节,源码散落在uboot,atf,kernel等源码目录中,多核启动并不是很神秘,都是需要告诉从处理器从那个地方开始取值执行,然后从处理器进入内核后需要自身做一些必要的初始化,就进入idle状态等待有任务来调度.
arm64平台使用psci更为广泛。
审核编辑:汤梓红
-
Linux在SMP系统上的移植研究2017-11-14 1116
-
【深圳SMP03,SMP03】2018-02-01 0
-
AliOS Things SMP系统及其在esp32上实现示例2018-05-15 0
-
SMP04|SMP22|信号源|SMP04 现金回收2021-12-31 0
-
多核处理器分类之SMP与NUMA简析2022-06-07 0
-
RT-Thread SMP和AMP初体验简介2023-02-03 0
-
RT-Thread框架下的SMP支持2023-02-13 0
-
如何启用SMP?2023-05-16 0
-
SMP-04采样保持四放大器和SMP-08 SMP-18采样2009-06-03 615
-
什么是SMP(对称多处理)2009-12-17 2331
-
SMP技术2009-12-17 4566
-
对称多处理 (SMP) 的应用优势2010-09-03 2804
-
ARM64 SMP多核启动(上)—spin-table2023-06-09 992
-
SMP是什么 启动方式介绍2023-12-05 1826
-
SMP多核启动cpu操作函数2023-12-05 777
全部0条评论

快来发表一下你的评论吧 !
