

CPU缓存那些事儿
电子说
描述
CPU高速缓存集成于CPU的内部,其是CPU可以高效运行的成分之一,本文围绕下面三个话题来讲解CPU缓存的作用:
-
为什么需要高速缓存?
-
高速缓存的内部结构是怎样的?
-
如何利用好cache,优化代码执行效率?
为什么需要高速缓存?
在现代计算机的体系架构中,为了存储数据,引入了下面一些元件
-
1.CPU寄存器
-
2.CPU高速缓存
-
3.内存
-
4.硬盘
从1->4,速度越来越慢,价格越来越低,容量越来越大。这样的设计使得一台计算机的价格会处于一个合理的区间,使得计算机可以走进千家万户。
由于硬盘的速度比内存访问慢,因此我们在开发应用软件时,经常会使用redis/memcached这样的组件来加快速度。
而由于CPU和内存速度的不同,于是产生了CPU高速缓存。
下面这张表反应了CPU高速缓存和内存的速度差距。
|
存储器类型 |
时钟周期 |
|
L1 cache |
4 |
|
L2 cache |
11 |
|
L3 cache |
24 |
|
内存 |
167 |
通常cpu内有3级缓存,即L1、L2、L3缓存。其中L1缓存分为数据缓存和指令缓存,cpu先从L1缓存中获取指令和数据,如果L1缓存中不存在,那就从L2缓存中获取。每个cpu核心都拥有属于自己的L1缓存和L2缓存。如果数据不在L2缓存中,那就从L3缓存中获取。而L3缓存就是所有cpu核心共用的。如果数据也不在L3缓存中,那就从内存中获取了。当然,如果内存中也没有那就只能从硬盘中获取了。
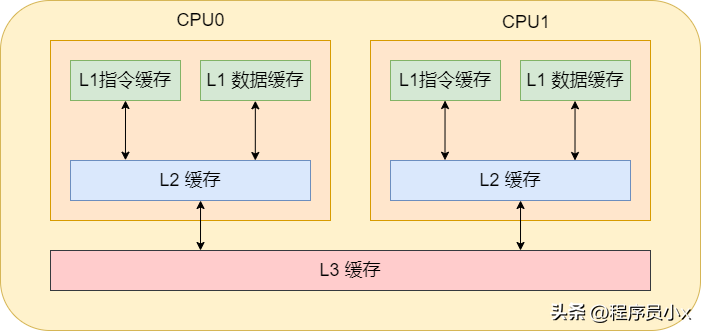
对这样的分层概念有了了解之后,就可以进一步的了解高速缓存的内部细节。
高速缓存的内部结构
CPU Cache 在读取内存数据时,每次不会只读一个字或一个字节,而是一块块地读取,这每一小块数据也叫CPU 缓存行(CPU Cache Line)。这也是对局部性原理的运用,当一个指令或数据被拜访过之后,与它相邻地址的数据有很大概率也会被拜访,将更多或许被拜访的数据存入缓存,可以进步缓存命中率。
cache line 又分为多种类型,分别为直接映射缓存,多路组相连缓存,全相连缓存。
下面依次介绍。
直接映射缓存
直接映射缓存会将一个内存地址固定映射到某一行的cache line。
其思想是将一个内存地址划分为三块,分别是Tag, Index,Offset(这里的内存地址指的是虚拟内存)。将cacheline理解为一个数组,那么通过Index则是数组的下标,通过Index就可以获取对应的cache-line。再获取cache-line的数据后,获取其中的Tag值,将其与地址中的Tag值进行对比,如果相同,则代表该内存地址位于该cache line中,即cache命中了。最后根据Offset的值去data数组中获取对应的数据。整个流程大概如下图所示:
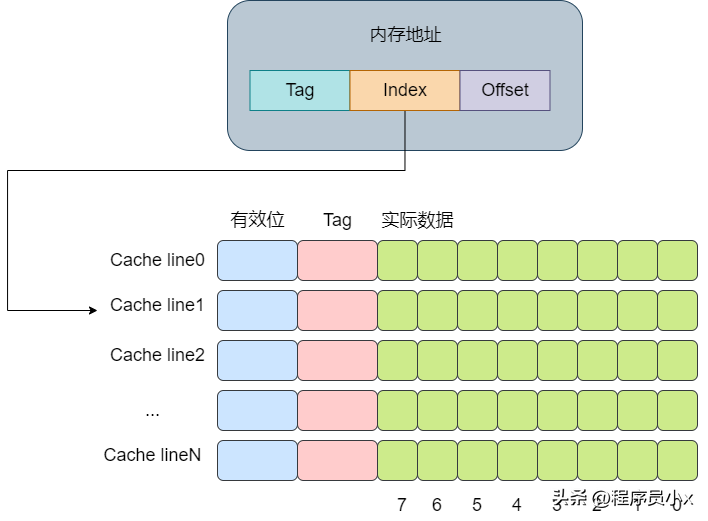
下面是一个例子,假设cache中有8个cache line,
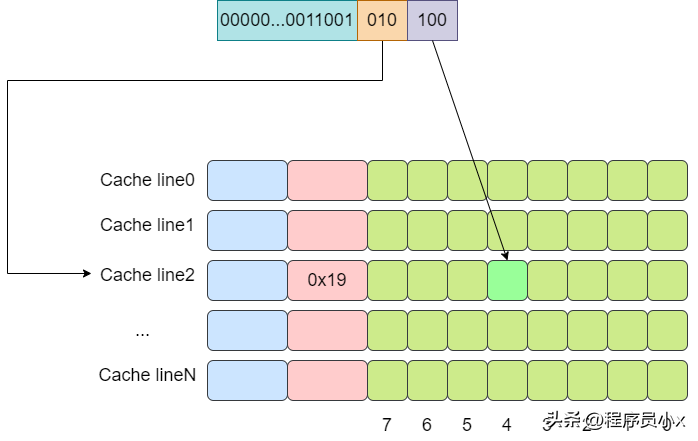
对于直接映射缓存而言,其内存和缓存的映射关系如下所示:
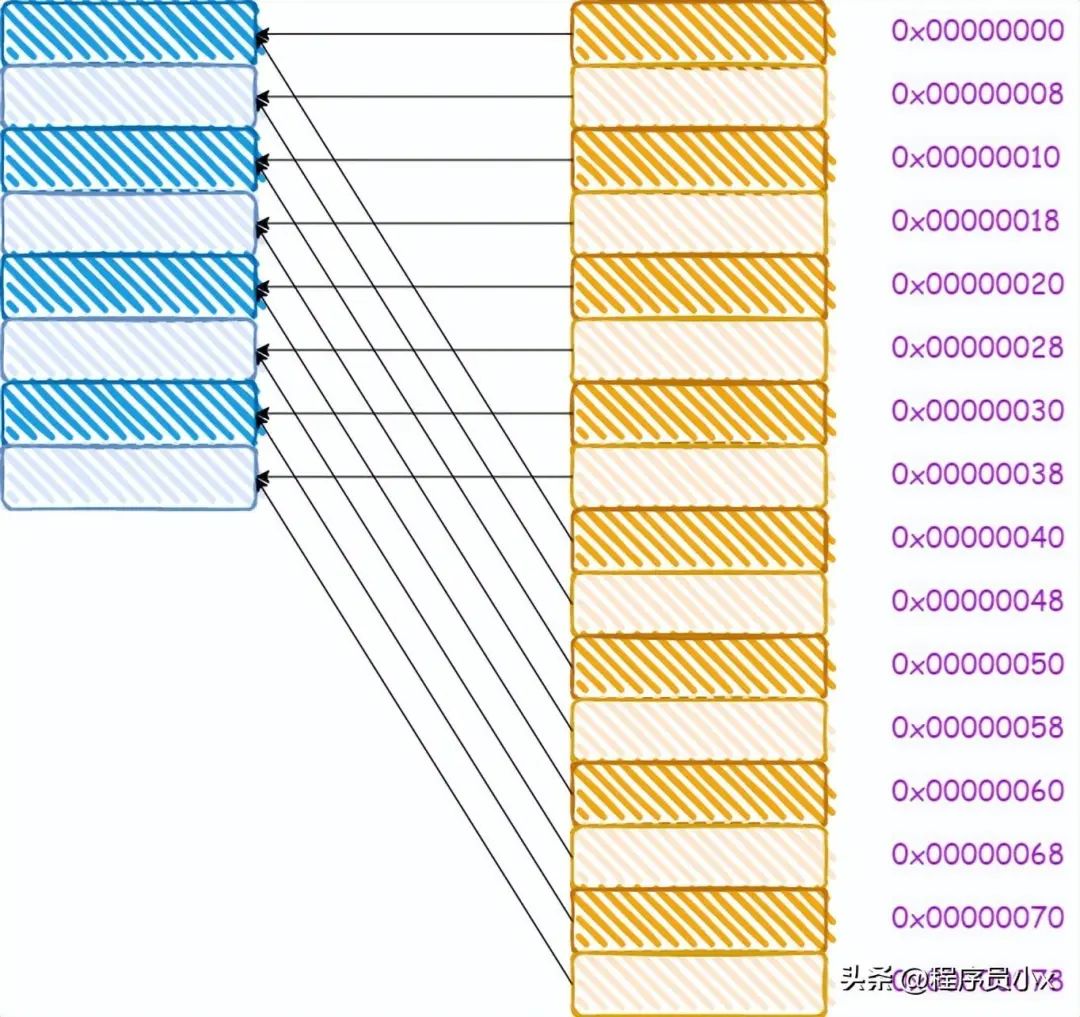
从图中我们可以看出,0x00,0x40,0x80这三个地址,其地址中的index成分的值是相同的,因此将会被加载进同一个cache line。
试想一下如果我们依次访问了0x00,0x40,0x00会发生什么?
当我们访问0x00时,cache miss,于是从内存中加载到第0行cache line中。当访问0x40时,第0行cache line中的tag与地址中的tag成分不一致,因此又需要再次从内存中加载数据到第0行cache line中。最后再次访问0x00时,由于cache line中存放的是0x40地址的数据,因此cache再次miss。可以看出在这个过程中,cache并没有起什么作用,访问了相同的内存地址时,cache line并没有对应的内容,而都是从内存中进行加载。
这种现象叫做cache颠簸(cache thrashing)。针对这个问题,引入多路组相连缓存。下面一节将讲解多路组相连缓存的工作原理。
多路组相连缓存
多路组相连缓存的原理相比于直接映射缓存复杂一些,这里将以两路组相连这种场景来进行讲解。
所谓多路就是指原来根据虚拟的地址中的index可以唯一确定一个cache line,而现在根据index可以找到多行cache line。而两路的意思就是指通过index可以找到2个cache line。在找到这个两个cache line后,遍历这两个cache line,比较其中的tag值,如果相等则代表命中了。
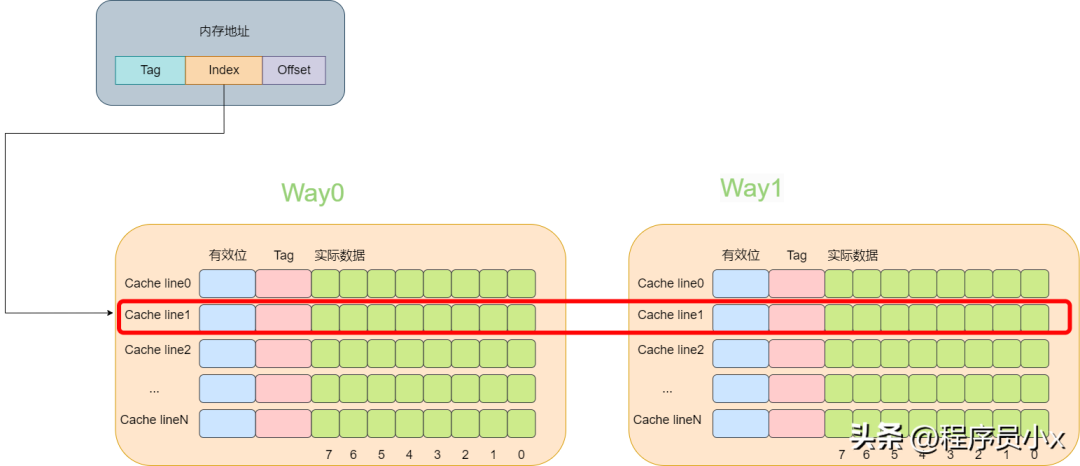
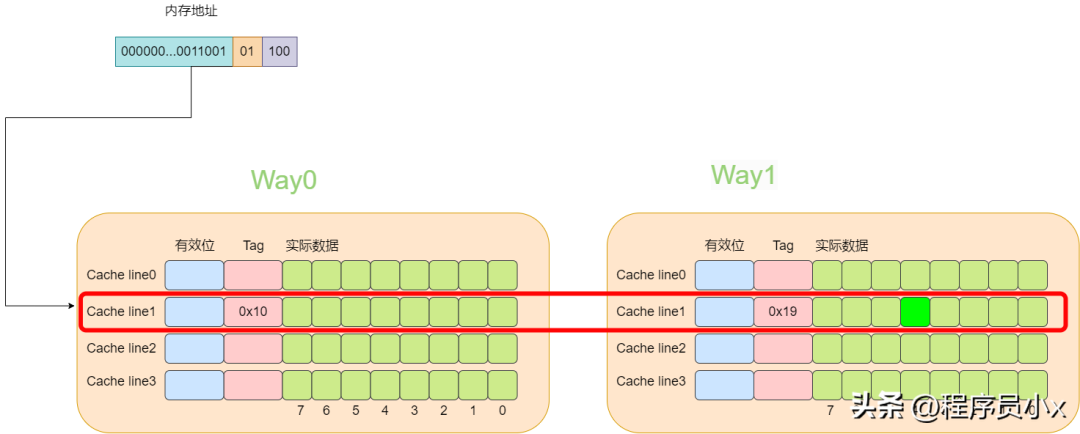
下面还是以8个cache line的两路缓存为例,假设现在有一个虚拟地址是0000001100101100,其tag值为0x19,其index为1,offset为4。那么根据index为1可以找到两个cache line,由于第一个cache line的tag为0x10,因此没有命中,而第二个cache line的tag为0x19,值相等,于是cache命中。
对于多路组相连缓存而言,其内存和缓存的映射关系如下所示:
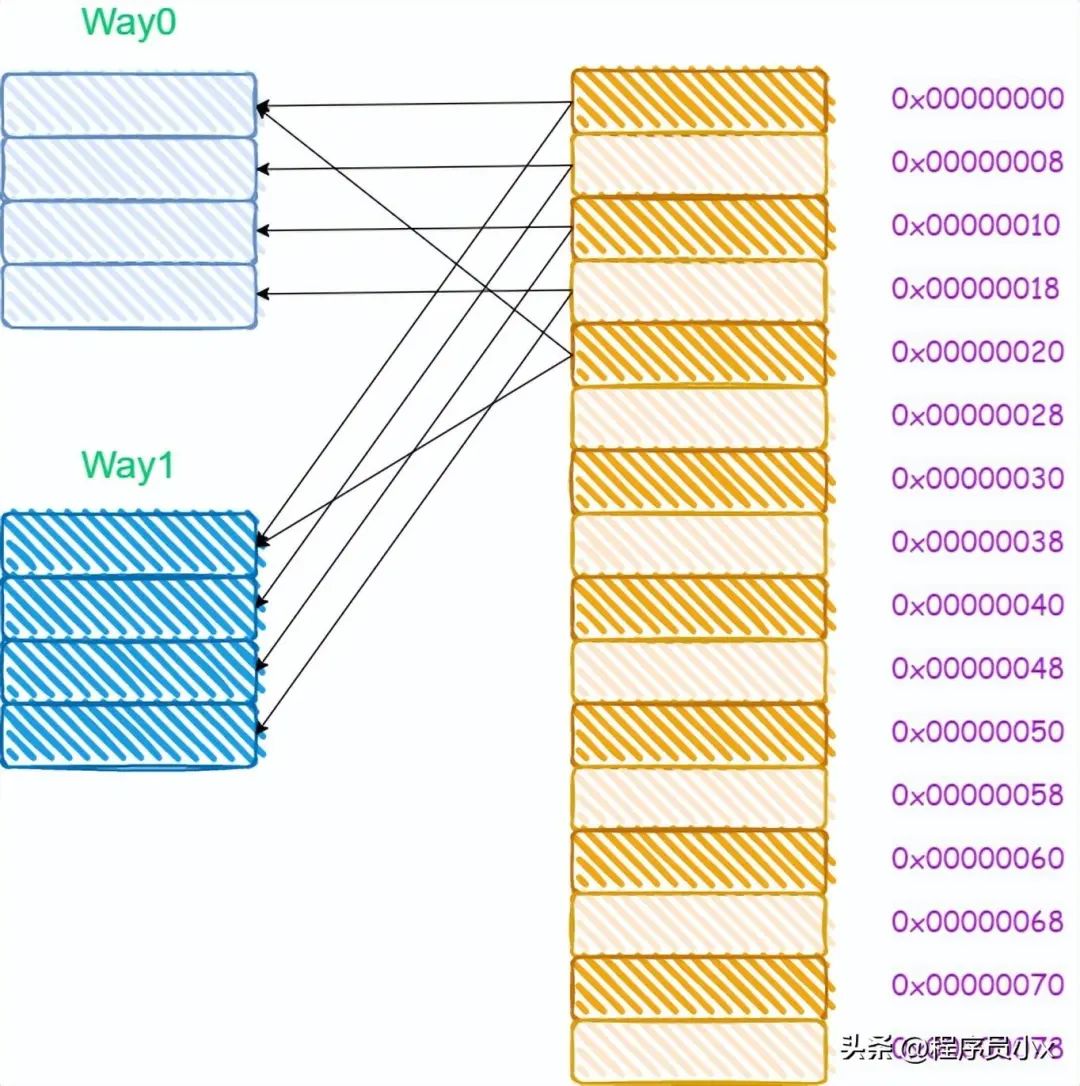
由于多路组相连的缓存需要进行多次tag的比较,对于比直接映射缓存,其硬件成本更高,因为为了提高效率,可能会需要进行并行比较,这就需要更复杂的硬件设计。
另外,如何cache没有命中,那么该如何处理呢?
以两路为例,通过index可以找到两个cache line,如果此时这两个cache line都是处于空闲状态,那么cache miss时可以选择其中一个cache line加载数据。如果两个cache line有一个处于空闲状态,可以选择空闲状态的cache line 加载数据。如果两个cache line都是有效的,那么则需要一定的淘汰算法,例如PLRU/NRU/fifo/round-robin等等。
这个时候如果我们依次访问了0x00,0x40,0x00会发生什么?
当我们访问0x00时,cache miss,于是从内存中加载到第0路的第0行cache line中。当访问0x40时,第0路第0行cache line中的tag与地址中的tag成分不一致,于是从内存中加载数据到第1路第0行cache line中。最后再次访问0x00时,此时会访问到第0路第0行的cache line中,因此cache就生效了。由此可以看出,由于多路组相连的缓存可以改善cache颠簸的问题。
全相连缓存
从多路组相连,我们了解到其可以降低cache颠簸的问题,并且路数量越多,降低cache颠簸的效果就越好。那么是不是可以这样设想,如果路数无限大,大到所有的cache line都在一个组内,是不是效果就最好?基于这样的思想,全相连缓存相应而生。
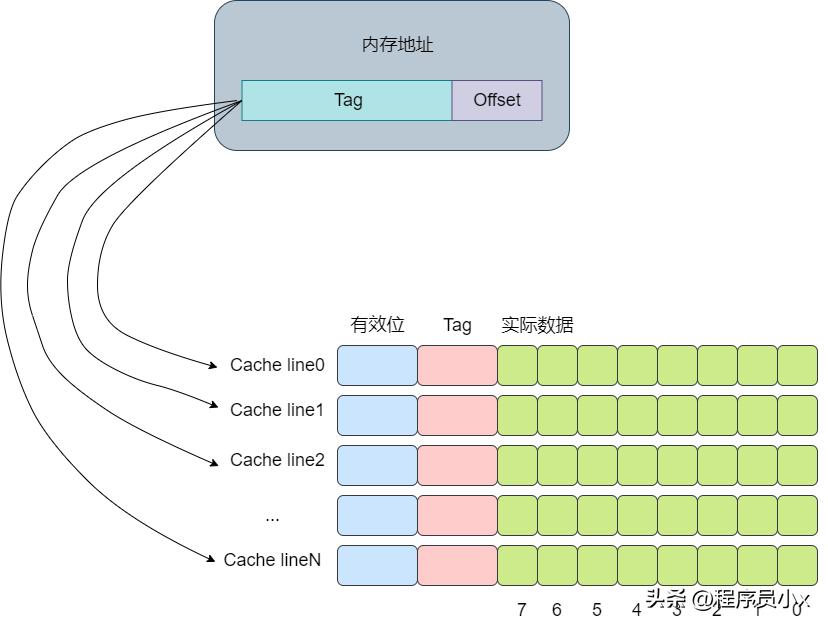
下面还是以8个cache line的全相连缓存为例,假设现在有一个虚拟地址是0000001100101100,其tag值为0x19,offset为4。依次遍历,直到遍历到第4行cache line时,tag匹配上。
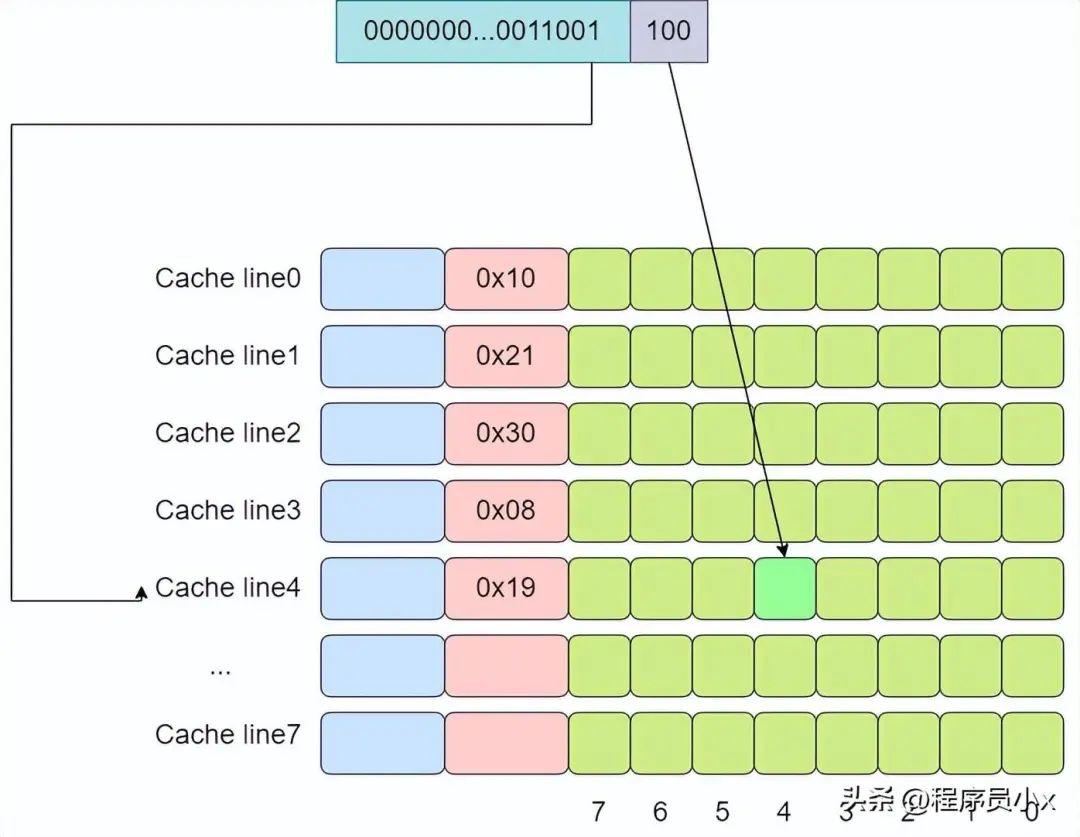
全连接缓存中所有的cache line都位于一个组(set)内,因此地址中将不会划出一部分作为index。在判断cache line是否命中时,需要遍历所有的cache line,将其与虚拟地址中的tag成分进行对比,如果相等,则意味着匹配上了。因此对于全连接缓存而言,任意地址的数据可以缓存在任意的cache line中,这可以避免缓存的颠簸,但是与此同时,硬件上的成本也是最高。
如何利用缓存写出高效率的代码?
看下面这个例子,对一个二维数组求和时,可以进行按行遍历和按列遍历,那么哪一种速度会比较快呢?
const int row = 1024;
const int col = 1024;
int matrix[row][col];
//按行遍历
int sum_row = 0;
for (int r = 0; r < row; r++) {
for (int c = 0; c < col; c++) {
sum_row += matrix[r][c];
}
}
//按列遍历
int sum_col = 0;
for (int c = 0; c < col; c++) {
for (int r = 0; r < row; r++) {
sum_col += matrix[r][c];
}
}
我们分别编写下面的测试代码,首先是按行遍历的时间:
#include
标准输出打印了:2ms
接着是按列遍历的测试代码:
#include
标准输出打印了:8ms
答案很明显了,按行遍历速度比按列遍历快很多。
原因就是按行遍历时, 在访问matrix[r][c]时,会将后面的一些元素一并加载到cache line中,那么后面访问matrix[r][c+1]和matrix[r][c+2]时就可以命中缓存,这样就可以极大的提高缓存访问的速度。
如下图所示,在访问matrix[0][0]时,matrix[0][1],matrix[0][2],matrix[0][2]也被加载进了高速缓存中,因此随后遍历时就可以用到缓存。
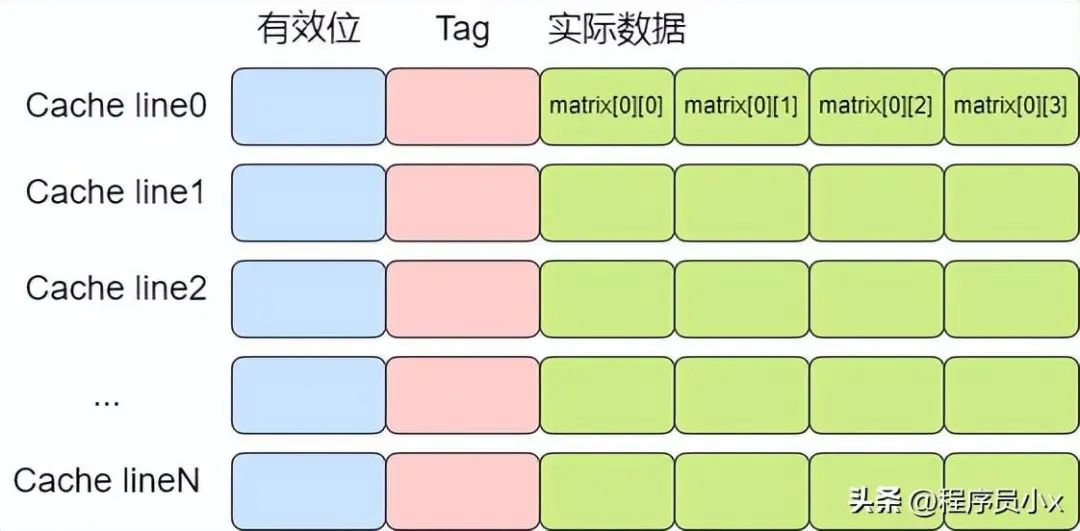
而按列遍历时,访问完matrix[0][0]之后,下一个要访问的数据是matrix[1][0],不在高速缓存中,于是需要再次访问内存,这就使得程序的访问速度相较于按行缓存会慢很多。
-
NIOSII那些事儿REV7.02013-03-07 0
-
mos管的那些事儿分享!2019-08-28 0
-
CPU缓存对性能的影响2010-11-13 2483
-
电源选型的那些事儿2016-10-10 785
-
Linux那些事儿linux的入门介绍2017-05-02 1007
-
Linux的那些事儿之我是Sysfs2017-10-29 954
-
Linux的那些事儿之我是SCSI硬盘2017-10-29 1077
-
Linux的那些事儿之我是PCI2017-10-29 990
-
Linux的那些事儿之我是Hub2017-10-29 971
-
Linux的那些事儿之我是Block层2017-10-29 1072
-
CPU缓存是什么意思_CPU缓存有什么作用2020-05-19 7639
-
缓存如何工作,如何设计CPU缓存2020-11-19 2747
-
CPU缓存的作用及原理有哪些2021-08-27 10794
-
MOS管的那些事儿.课件下载2021-12-06 1008
-
Linux内存的那些事儿2022-09-08 759
全部0条评论

快来发表一下你的评论吧 !
