

Pensando:AMD在数据中心网络领域的野望
电子说
描述
01. Pensando的前世
Pensando创立于2016年,创始人为从Cisco离职的4位大佬级人物:Mario Mazzola、Prem Jain、Luca Cafiero和Soni Jiandani。他们的名字可能你不熟悉,但是他们提出的协议MPLS你一定不陌生(MPLS一说是取自他们的名字首字母),对这4位大神有兴趣的话后台私信我。这4位大佬在Cisco离职之后,创办了Pensando。可以说这是一家小而精的公司,其客户覆盖了高盛、NetApp、Equinix、HPE,从国际投行,到存储和数据中心巨头,明显看得出来,客户都是精挑细选,非常有针对性。
“它是一个软件定义的分布式服务平台,针对边缘进行加速,始终安全,并面向云、企业以及服务提供商客户”。
2019年10月,Pensando宣布Chambers担任董事会主席,而这位Chambers,历任Cisco,JC2 Ventures投资机构CEO,圈内地位可见一斑。
02. Pensando的今生
2022年4月,AMD宣布以19亿美元收购DPU初创公司Pensando。如果说ZEN架构让AMD翻身成功,那么收购Pensando,可以说是AMD在技术方面补齐了数据中心拼图的最后一块短板,个人认为,此举不亚于NVIDIA在2019年收购互连芯片独角兽厂商Mellanox。如果说Mellanox是打通了NVIDIA的GPU在数据中心中集群互连的任督二脉,那么AMD收购Pensando,也彰显了其在加深计算(X86+Radeon)与数据处理(DPU)壁垒的野望。
Pensando产品上线之前的资料非常少,非常低调。目前根据AMD官网等网站资料显示,最新的Pensando产品为“Giglio ”DPU。Giglio,是基于第二代AMD Pensando “Elba” DPU的一个功耗和性能优化芯片。它与其前身源代码兼容,方便客户替换和扩展。
03. Pensando的特性
Pensando可以在2 x 200Gb/s线速下提供了卸载各种数据中心网络、存储和安全服务的高级功能。它采用了一个由144个自定义匹配处理单元(MPU)组成的可编程P4流水线,与一个16x A72 ARM内核的组合,以及专用的数据加密和存储卸载引擎,所有这些都通过专有的快速网络芯片互连在一起。Giglio独特的体系结构允许客户以虚拟化、分布式且集中管理的方式创建高效、可扩展的解决方案,以部署丰富的软件定义的网络、存储和安全功能集。
Giglio DPU允许实现复杂的流量处理和转发算法,包括网络虚拟化和安全性、数据包封装/解封装、内联加密/解密和网络地址转换。
Giglio DPU架构支持状态处理,可用于流监控、数据流感知安全策略实现、抵御DDoS攻击等。
专用的卸载引擎可以无缝高效地处理各种加密和存储算法中使用的计算繁重的操作,包括压缩/解压缩、校验和、RAID和重复数据删除哈希。
AMD Pensando DPU使用行业标准P4语言进行编程,有助于实现各种系统解决方案。它支持软件定义的网络和存储协议,包括NVMe虚拟化和传输,并且其设计使开发人员能够开发和部署新功能及修改以满足产品生命周期中不断变化的客户需求。
Giglio DPU的形式因素和功耗配置旨在支持多种系统级实现,范围从半高半长PCIe卡(可适合任何标准服务器的功率和制冷配置文件)到网络和安全设备及智能交换机。P4可编程设计使这些应用程序能够动态重新配置DPU内的数据处理。
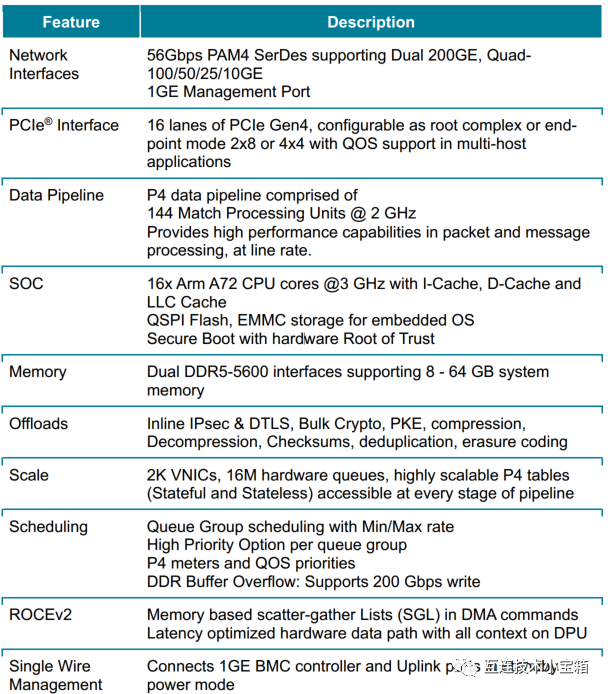
Giglio DPU提供以下可配选项

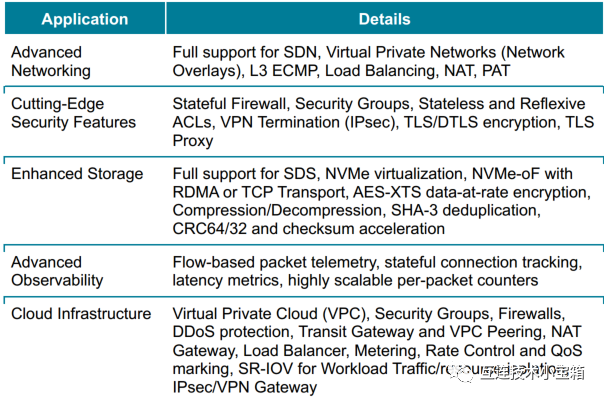
Giglio DPU一些典型使用场景
04. Pensando的细节
根据目前可查到的比较详细资料是来自Hot chips21的一篇paper,我们可以通过这篇paper来探讨一下Pensando的内部架构细节
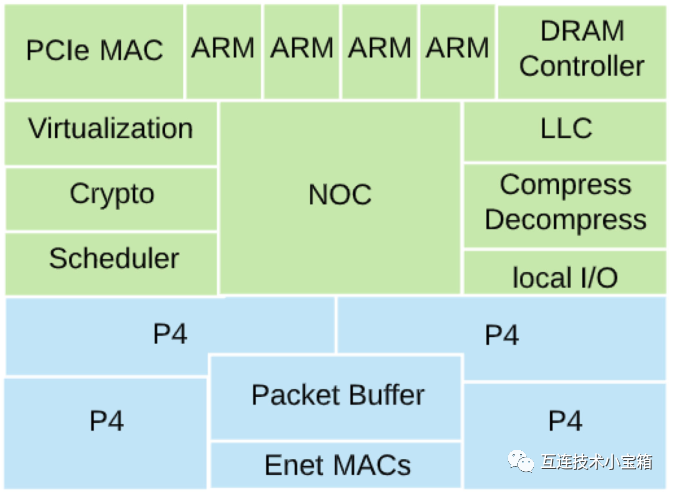
Asic block diagram
如上图所示,Pensando架构可以大体上分为两个部分,绿色的是内存事务层面,蓝色的可以认为是网络数据层面。
数据路径
从网络进入的数据包会在一个以太网MAC接口上被接收,并根据L2或L3服务类型(COS)被放入数据包缓冲区。数据包缓冲区提供“暂停吸收缓冲”和面向COS的仲裁,为P4入口流水线服务。与P4模型一致,数据包首先通过P4入口流水线进行流分类;如有组播或SPAN复制则返回数据包缓冲区;然后进入P4出口流水线应用例如网络地址转换、遥测等。完成网络处理任务后,数据包可以被发送回以太网MAC端口,或者传递到ARM子系统或本地主机。
如果数据包被发送到ARM或本地主机,它必须根据ARM上运行的内核或用户态驱动程序的需要进行处理。数据包通过第三个P4流水线,在那里它根据数据包的协议类型(以太网、RDMA、NVMe或新协议)运行另一个程序。与面向特定内核或用户驱动程序的协议特定P4程序相关联的一个重要优势是能够根据目标驱动程序的需求自定义描述符格式、完成事件、中断方案和数据格式。
总之,网络数据包进入ASIC,通过P4入口和出口流水线应用安全性和网络服务,与目标接口和设备类型相关联,并通过P4驱动程序接口程序传递。最终的数据包或数据缓冲区被传递到连接的主机、嵌入式ARM或集成的卸载引擎。主机发送的数据包通过PCIe MAC进入,由P4驱动程序接口程序处理,然后由P4入口和出口流水线处理以应用安全和网络服务,之后通过以太网MAC发送出去。
硬件队列管理
从网络进入P4流水线的数据包或来自内部事件的数据包被放入硬件队列。硬件队列用于管理接口、数据流、连接和任何其他需要有序跟踪和调度的对象。软件可以配置高达1600万个硬件队列。每个队列在基于DRAM的qstate记录中存储其当前状态,包括已入队对象的计数、指向入队对象数组或链接列表的指针、连接状态和对等信息,以及用于内存保护的进程ID。
使用doorbell机制触发通知入队新对象的事件,允许使用单个门铃动作将一个或多个对象添加到任何队列。队列调度器将所有1600万个队列组织到一个DRAM数组中,提供优先级调度、最小/最大数据速率和加权轮询调度可跨调度组使用。当调度一个队列时,一个带有已调度队列ID和COS的PHV令牌被插入到分配的P4流水线进行处理。然后,TE访问qstate数组,根据队列类型和状态启动程序,这反过来从P4程序中的表中获取排队的对象和描述符。
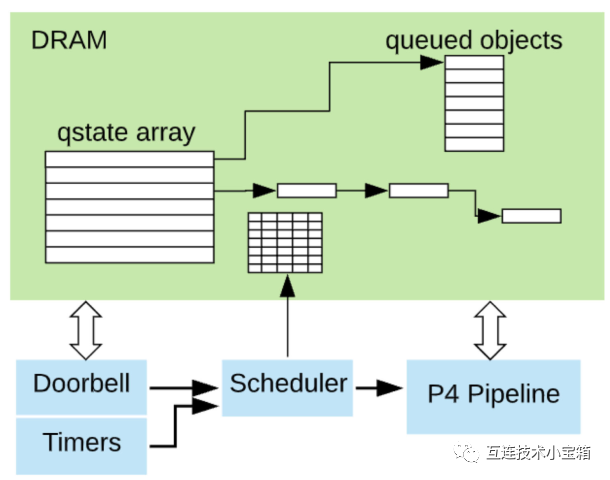
Sixteen million queues
中心数据包缓冲区
多个独立的P4流水线通过一个中心数据包缓冲区相互连接。数据包缓冲区是一个共享内存式交换架构,对多个服务等级具有虚拟输出队列以及增强的传输选择调度。组播复制、SPAN(交换机端口分析器)队列和网络暂停缓冲由中心数据包缓冲区提供。此外,入口数据包突发溢出特性允许短期突发写入DRAM内存的溢出区域。中心数据包缓冲区在数据包域中运行,而系统级芯片(SOC)在内存事务域中运行。P4 DMA引擎桥接这两个域,将数据包转换为内存事务。
PCIe端口和虚拟化
PCIe虚拟化硬件允许在SOC上运行的软件配置呈现给主机的设备数量和类型,包括配置空间、BAR范围和虚拟功能计数。这允许向不同进程呈现和附加多个网络、存储和主机可见的卸载设备。PCIe通道可以分叉为多个端口,每个端口可以作为虚拟端点交换机或root complex运行。如果配置了多个虚拟交换机端口,则多个主机可以通过单独的PCIe通道附加并共享网络服务,就像它们属于每个主机本地一样。内部ASIC COS缓冲资源在主机之间实施公平的隔离,防止影响相邻主机。另一方面,如果将PCIe端口配置为root complex,则存储设备(如NVMe驱动器)由SOC控制并虚拟化到本地和远程主机。其他PCIe设备包括GPU和机器学习加速器也可以由ASIC控制。
。
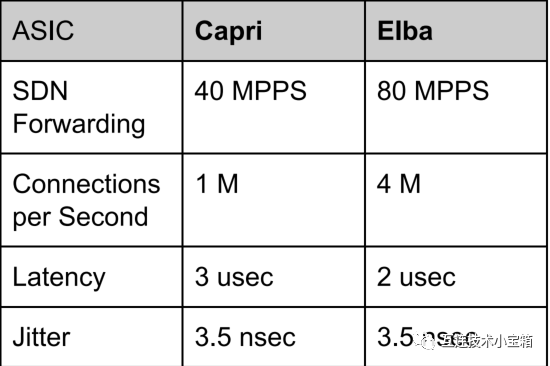
前两代ASIC的性能
性能
上表展示了前两代Pensando的性能,场景包括每个连接的状态防火墙、每个流的遥测收集,以及ARM CPU管理连接建立/拆除而数据通路操作在P4流水线中处理。延迟和抖动是通过实验室测试设备在线路上测量的。
与可用解决方案进行比较很困难,因为很少有发布具有相同服务特征的结果,但提供这些功能子集的解决方案显示其交付的百万数据包/秒 (MPPS) 仅为Pensando的一小部分。Pensando的每秒连接建立和跟踪性能比可用解决方案高一个数量级,并接近大型多端口服务设备。
05. CONCLUSION
现代数据中心正面临着在安全性、网络、遥测、存储和规模方面的需求,这些需求当前设备无法解决。Pensando开发了一个分布式服务架构来解决这些数据中心需求,同时基于针对特定领域的、开源的、许可宽松的P4语言提供了用户可编程性。第一个两代架构以16nm和7nm工艺实现为ASIC。
-
锐捷网络中标中国联通数据中心集采项目2017-01-24 0
-
易天重点解析监控系统在数据中心机房的重要性2018-10-09 0
-
在数据中心应用MPO/MTP光缆的七大优势2021-01-05 0
-
数据中心太耗电怎么办2021-06-30 0
-
数据中心是什么2021-07-12 0
-
AMD斥资19亿美元收购云计算企业Pensando2022-04-06 1548
-
再下一城,AMD收购DPU厂商,补齐数据中心业务拼图2022-04-07 2785
-
AMD宣布将收购DPU芯片厂商Pensando2022-04-08 1414
-
智能照明控制系统在数据中心的应用2022-05-19 1021
-
数字孪生在数据中心的应用场景2023-08-28 1722
-
集中电源控制器在数据中心的应用2024-01-30 521
-
多业务光端机在数据中心的应用:提升网络效率的关键2024-02-23 678
-
AMD数据中心业务收入超越Intel2024-11-07 408
-
史上首次,AMD在数据中心市场的销售额超过了英特尔!2024-11-19 262
全部0条评论

快来发表一下你的评论吧 !
